
dsRAG: 非構造化データと複雑なクエリのための検索エンジン

はじめに
dsRAGは、非構造化データに対する複雑なクエリを処理するために設計された高性能検索エンジンである。dsRAGは、セマンティックセグメンテーション、文脈自動生成、関連セグメント抽出という3つの主要なアプローチを用いて性能を向上させている。これらのアプローチにより、dsRAGは複雑なオープンブッククイズタスクにおいて、従来のRAGベースラインを大幅に上回る精度を達成することができる。さらに、dsRAGはユーザーのニーズに応じてカスタマイズ可能な幅広い設定オプションをサポートしている。そのモジュール設計により、ユーザはベクトルデータベース、埋め込みモデル、再検索器などの異なるコンポーネントを簡単に統合し、最適な検索結果を得ることができる。
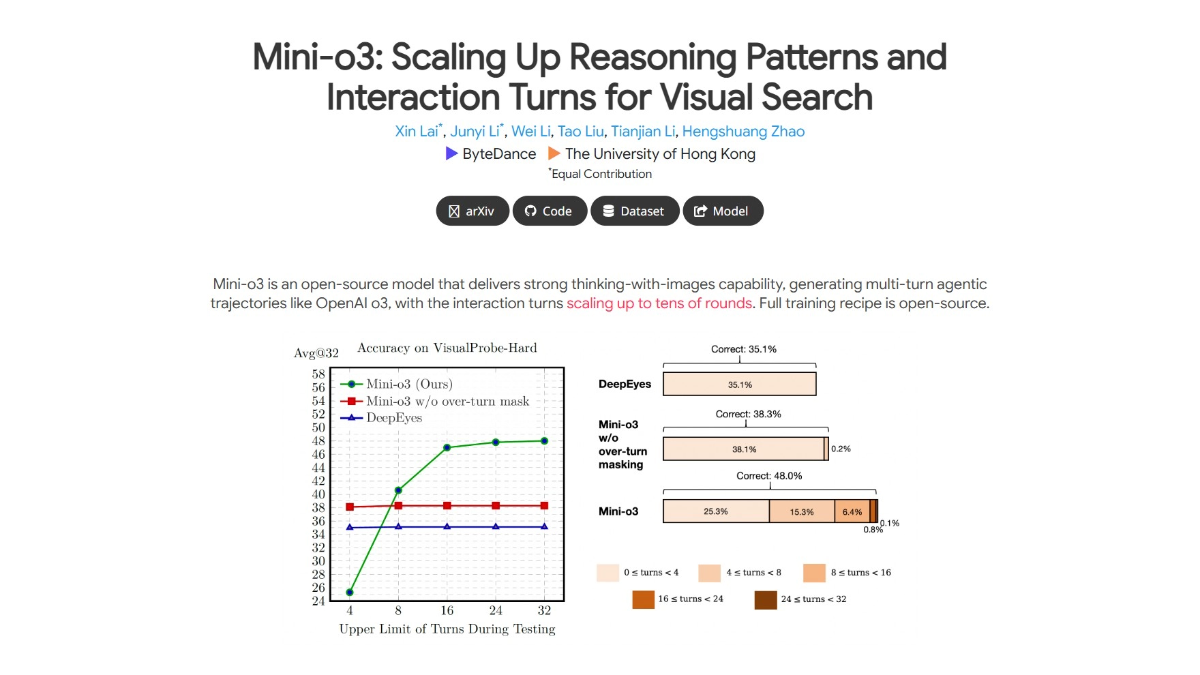
従来のRAG(Retrieval-Augmented Generation)ベースラインと比較して、dsRAGは複雑なオープンブッククイズタスクにおいて有意に高い精度を達成している。例えば、FinanceBenchベンチマークテストにおいて、dsRAGは従来のRAGベースラインの321 TP3Tに対し、96.61 TP3Tの精度を達成している。dsRAGは、セマンティックセグメンテーション、自動コンテキスト、関連セグメント抽出などの主要な手法により、検索性能を大幅に向上させている。

機能一覧
- セマンティックセグメンテーションLLMを使って文書をセグメント化し、検索精度を向上させる。
- コンテキストの自動生成埋め込み品質を向上させるために、文書と段落レベルのコンテキストを含むブロックヘッダを生成します。
- 関連セグメント抽出クエリ時に関連するテキストブロックをインテリジェントに組み合わせ、より長い段落を生成します。
- 複数のベクトルデータベースをサポート例:BasicVectorDB、WeaviateVectorDB、ChromaDBなど。
- 複数の組み込みモデルをサポート例:OpenAIEmbedding、CohereEmbeddingなど。
- 複数のリコーダーのサポート例:CohereReranker、VoyageRerankerなど。
- 永続的ナレッジ・ベースナレッジ・ベース・オブジェクトをディスクに永続化し、その後のロードやクエリーをサポート。
- 複数文書フォーマットのサポートPDF、Markdown、その他の文書フォーマットの解析や処理に対応。
ヘルプの使用
取り付け
dsRAG用のPythonパッケージをインストールするには、以下のコマンドを実行する:
pip install dsrag
OpenAIとCohereのAPIキーがあることを確認し、環境変数として設定する。
クイックスタート
を使用することができます。create_kb_from_file関数はファイルから直接新しい知識ベースを作成します:
from dsrag.create_kb import create_kb_from_file
file_path = "dsRAG/tests/data/levels_of_agi.pdf"
kb_id = "levels_of_agi"
kb = create_kb_from_file(kb_id, file_path)
知識ベース・オブジェクトは自動的にディスクに永続化されるため、明示的に保存する必要はありません。
今、何が起こっているのかをよりよく知ることができる。kb_idナレッジ・ベースをロードしてqueryメソッドが照会される:
from dsrag.knowledge_base import KnowledgeBase
kb = KnowledgeBase("levels_of_agi")
search_queries = ["What are the levels of AGI?", "What is the highest level of AGI?"]
results = kb.query(search_queries)
for segment in results:
print(segment)
基本的なカスタマイズ
例えば、OpenAIだけを使うなど、ナレッジベースの構成をカスタマイズすることができます:
from dsrag.llm import OpenAIChatAPI
from dsrag.reranker import NoReranker
llm = OpenAIChatAPI(model='gpt-4o-mini')
reranker = NoReranker()
kb = KnowledgeBase(kb_id="levels_of_agi", reranker=reranker, auto_context_model=llm)
そして、次のようにする。add_documentメソッドを使って文書を追加します:
file_path = "dsRAG/tests/data/levels_of_agi.pdf"
kb.add_document(doc_id=file_path, file_path=file_path)
ビルド
知識ベース・オブジェクトは(生のテキストの形で)文書を受け入れ、それに対してチャンキングや埋め込み、その他の前処理を行う。クエリが入力されると、システムはベクトルデータベース検索、並べ替え、関連セグメント抽出を行い、最後に結果を返す。
知識ベースオブジェクトはデフォルトで永続的であり、その完全な設定はJSONファイルとして保存されるため、再構築や更新が容易です。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません