
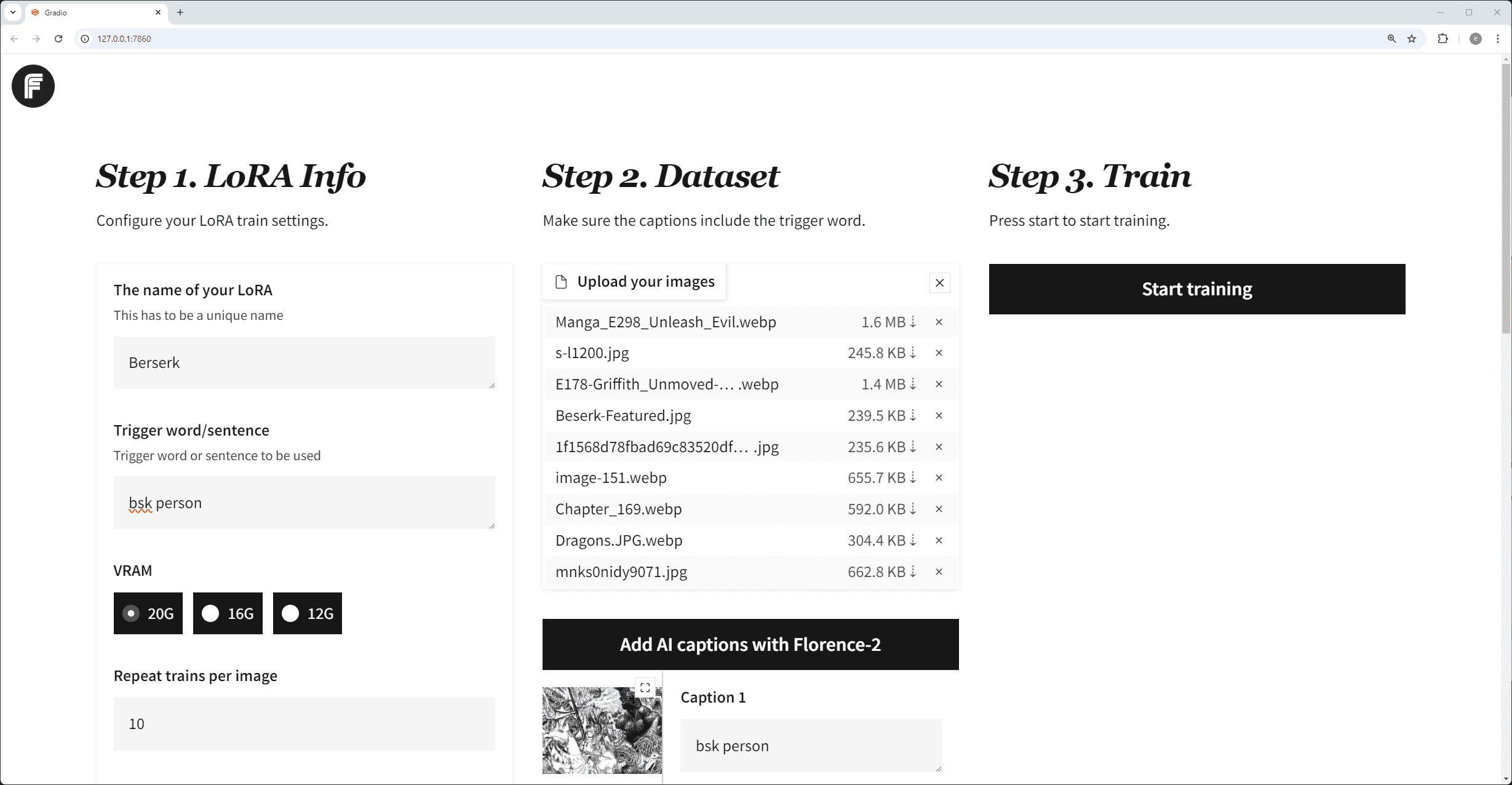
DreamTalk:1枚のアバター画像で表情豊かなトーキングビデオを生成!

ドリームトーク総論
DreamTalkは、清華大学、アリババグループ、華中科技大学が共同開発した拡散モデル駆動型の表現力豊かなトーキングヘッド生成フレームワークです。ノイズ除去ネットワーク、スタイル認識リップエキスパート、スタイル予測器という3つの主要コンポーネントで構成され、音声入力に基づいて多様でリアルなトーキングヘッドを生成することができる。このフレームワークは、多言語やノイズの多い音声を扱うことができ、高品質な顔の動きと正確な口の同期を提供する。

ドリームトーク機能一覧
音声に基づいてリアルなトーキングヘッドビデオを生成する
多言語および音声入力に対応
複数のスタイルと表現の出力をサポート
カスタムキャラクターアバターとスタイルリファレンスのサポート
オンラインデモとコードダウンロードをサポート
ドリームトーク・ヘルプ
詳細とデモビデオはプロジェクトのホームページをご覧ください。
技術的な詳細と実験結果については、論文のアドレスを参照されたい。
GitHubのアドレスにアクセスして、コードと事前学習済みモデルをダウンロードする。
インストールガイドに従って、環境と依存関係を設定する。
inference_for_demo_video.pyを実行して推論し、ビデオを生成する。
パラメータの説明に従って入出力オプションを調整する
ドリームトーク・オンライン体験アドレス
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません