低価格パソコン向け個人向け "小型 "モデルチャットツールの展開

プライベートな "ミニ "モデルのチャットツールを導入する理由は?
多くの人がChatGPT、Wisdom Spectrum、Beanbag、Claudeや他の優れた大規模な言語モデルを使用しており、綿密な使用の必要性を持っているまた、サードパーティの有料サービスを購入します、結局のところ、彼らは非常に優れたパフォーマンスです。例えば、私の主な作業シナリオは記事を書くことで、私はクロードを選択します。
クロードを使うのは好きだが、本当に日常的に高頻度で使っているのだろうか?答えはもちろんノーだ!
使用量の制限、価格要因、ネットワークの問題などの閾値は、不必要な状況での使用頻度を自然に減少させる。--どんな環境でも "手に取って使う "ことができないツールは、何か問題がある。
この場合、"小型 "モデルを使う方が良い選択かもしれない。

「小型 "モデルの特徴
Gemma2、llama3.1:8b、qwen2:7bは日常的に使うには十分な大きさで、32kの長い文脈に沿った入出力が可能で、ほとんどのコマンドに従うことができ、中国語の表現、質問への回答、すべて良好で、"文心易 "タイプの製品には2,000語の制限はない。限界は...日常的に使うには十分で、特殊な作業に特化したものを検討する。ミニチュアの利点は以下の通り:
- 大きなモデルよりも小さい(あるいはさらに大きい)コンテクストサイズをサポートする。
- 低品質な出力を伴わない日常的なライティング・タスク
- 使い放題
- 複数のミニチュアが同時に答えを出力できるので、簡単に比較できる。
- より速い実行
プライベート・デプロイメントとは何か?
カスタマイズが簡単で、"スモール "モデルに自由にアクセスできるプライベートチャットWEBインターフェース。
最も古典的なソリューションは、Ollama+Open WebUIをローカルに配備することです。前者はローカルコンピュータ上でミニチュアを実行する役割を担い、後者はチャットインターフェースをホストします。いつでもどこでもOllama+Open WebUIを利用できるエクストラネットを考えてみよう。クラウドフレアもしかしたらcpolarアドレスを外部ネットワークにマップする(チュートリアルを自分で検索してください)。
バンテージ
- チャットデータはローカルでプライベート
- ローカルモデルをカスタマイズする柔軟性
欠点
- 永続的な運用が難しい(いつもコンピュータの電源を切る必要があるでしょ?)エクストラネットへの公開が難しい
- コンピュータ・ハードウェアへの高い要求
取り組むべき課題
私たちが対処しようとしているのは欠点だ:
1.配備されたAIチャット・インターフェースは、いつでもどこでも利用できるように、安定したアクセスURLでエクストラネットに公開する必要がある。
2.コンピュータのハードウェアのしきい値は、主にローカルにモデルを実行するOllamaの使用は、APIサービスのよく知られているメーカーに変更することができ、プライバシー保護は比較的良好であり、無料です。(一般的なコンピュータは、ローカルに小さなモデルを実行することができます、ネットワークは無料のAPIを持っている)
最適プログラム
1.ローカル/クラウドでの無料ドセカー展開 オープンWebUI + "スモール "モデルAPIへのアクセス
ローカルでの使用に限り、コンピュータのハードウェアはdocekerが動作すればよい。
2.自社展開/トライパーティNextChatの利用+"スモール "モデルAPIへのアクセス
NextChatの自己展開には独自ドメインが必要であり、3者間NextChatを利用することで鍵が漏洩する危険性があります。
この配置計画は、経験豊富な人々だけが動作するように、経験の浅い白はお勧めしません、成熟した製品の良い使用、または異常な問題が発生した遅延は価値がありません。
最適配置オプション1
1.ドシーカーの配備
ローカル: チュートリアルのローカル展開。
クラウド:クラウド上の無料のドイスカー・リソースは、各自で検索してください。 コイェブ.(イントラネットには直接アクセスできません。)
2.OpenWebUIをdocekerにデプロイする
ローカル:詳細文書を読む以下のインストールコマンドを推奨します(常に最新の状態にしておいてください)。
docker run --rm --volume /var/run/docker.sock:/var/run/docker.sock containrrr/watchtower --run-once open-webui
クラウド:登録コイェブその後、Create Serviceをクリックし、以下のコマンドを入力する。
ghcr.io/open-webui/open-webui:main

3.WebUIを開く
ローカルスタートアップ、デフォルトアクセスアドレス:http://localhost:3000/

Koyebのデプロイ完了後のクラウド立ち上げは、ここをクリックします(このドメイン名はイントラネットから直接アクセスできないのが欠点で、ドメイン名をバインドするには有料アカウントの開設が必要です)。

起動後、アカウントを登録し、デフォルトでは、最初に登録されたアカウントは、管理者アカウントです。すでに登録されているので、ログイン画面のみ、最初の訪問は、 "登録 "ポータルを見ることができます

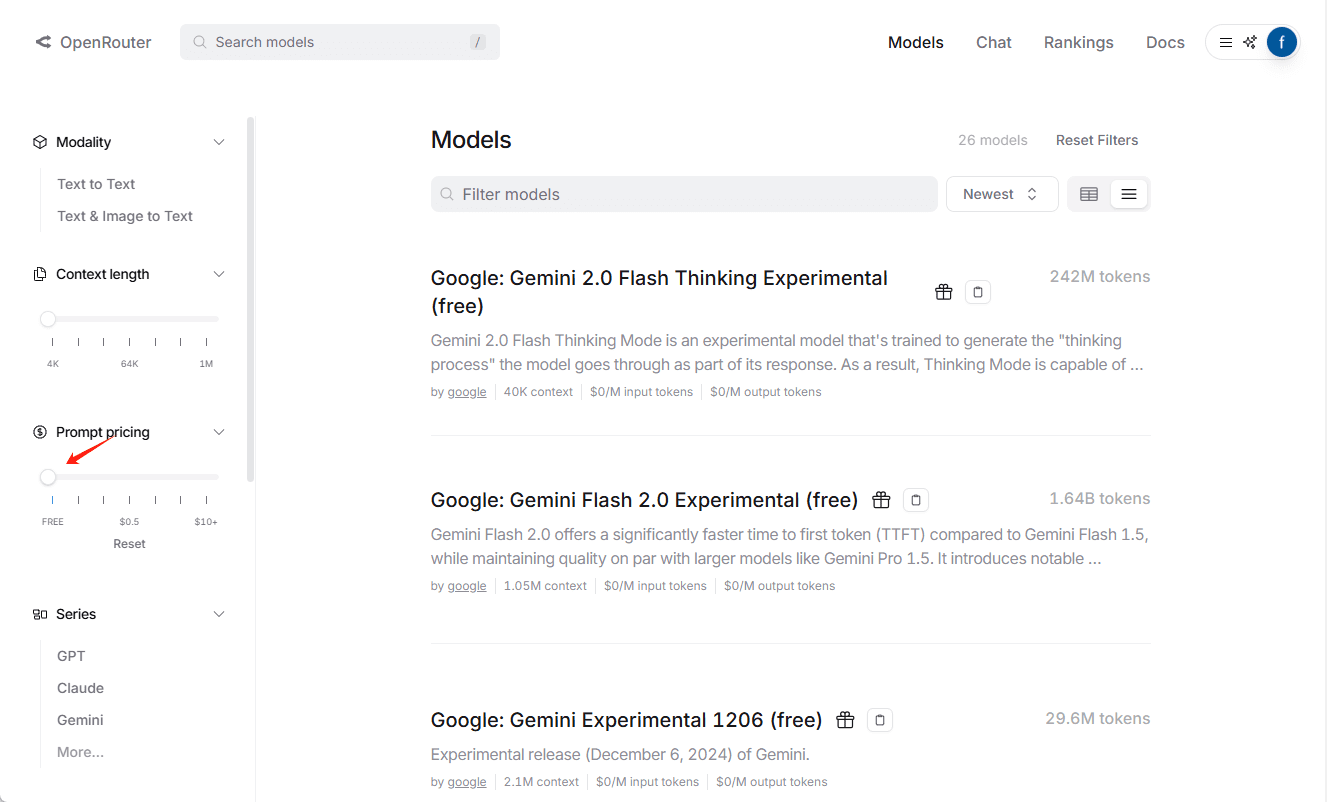
4.無料の「スモール」モデルAPIを申請する
OpenRouterを推奨し、その無料のモデルを使って1年間小説を書いてきました。OpenRouterのモデルAPIを入手する方法を説明します。
追記:国内無料小型APIベンダー:シリコンフロー
4.1 KEYの作成


sk-で始まる文字列が表示されます。これがKEYですので、コピーしてローカルに保存してください。
4.2 フリーモデル一覧の確認

4.3 APIリクエストURLの取得属
どのモデルのページでも、一般的にはhttps://openrouter.ai/api/v1/chat/completions。

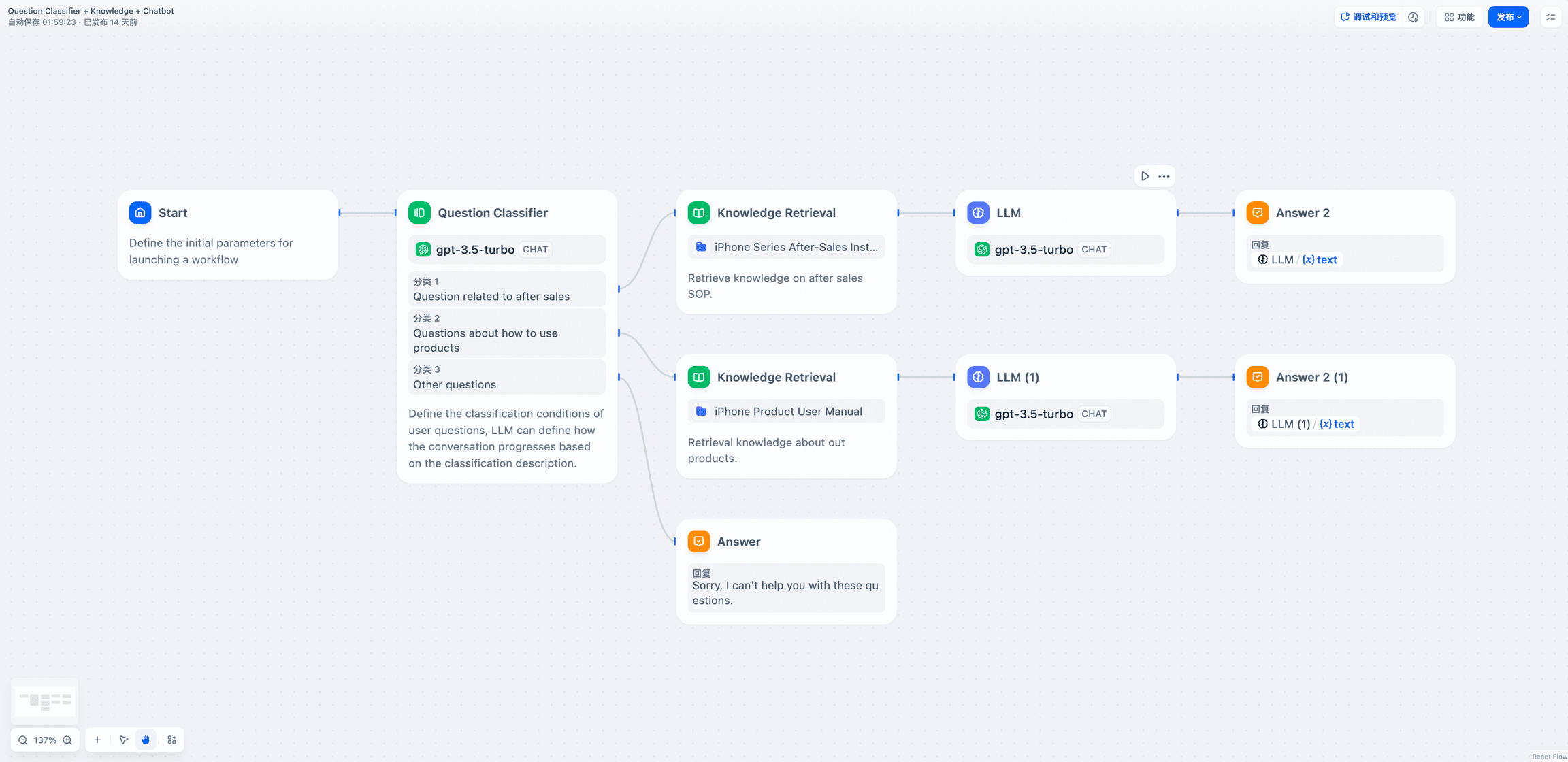
5.オープンWebUIの設定モデルに入る
4 "をクリックすると、Saveをクリックする前に、インターフェイスに正常にアクセスされたことを確認することに注意してください。

6.デフォルトモデルの設定
複数の無料モデルを選択可能
有料モデルの使用はアカウントの停止につながります。

よく使うモデルを保存するにはプリセットをクリック

7.最初の対話を試みる

最適配置オプション2
1.NextChatのクラウド展開
ワンクリックでクラウド展開できる無料ヘルプをご覧ください: https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web

2.ここでは、最初のデプロイ(vercel)を使用する。
そのプロセスに従うだけでいい。以下に3つの留意点を挙げる:
- ヘルプドキュメントをよく読み、チュートリアルに従って、プロジェクトが自動的にアップデートされるように設定してください。
- KEY変数とアクセスパスワードは、ヴェルセルのインストールプロセス中に設定する。
- 独自ドメイン名をバインドすることで、国内ネットワークへの直接アクセスが可能になる。
3.構成変数
オプション1のように自動的にモデルリストを読み込むことはできませんので、自分で自由なモデルリストを定義する必要があります。
BASE_URL または OpenAI Endpoint: https://openrouter.ai/api に設定します。
OPENAI_API_KEY または OpenAI API Key: あなたのAPIキーを入力します。 オープンルーター APIキーはこちら
CUSTOM_MODELS またはカスタムモデル: OpenRouter 内でリストされているモデル名を指定します。
4.展開完了画面

5.ドメイン名の結合
国内アクセス問題の解決

4.モデルのAPI KEYは設定で個別に設定できます。

を設定することができます。OhMyGPT1日あたり少量のGPT4無料クレジット、API KEYへの安定したアクセスのための別のアドレス(不正な隠蔽を防ぐため):
もう一つの無料API KEYプロジェクト:https://github.com/chatanywhere/GPT_API_free
展開されたNextChatのアドレス(機密情報を入力しないように注意してください、独自のAPI KEYを入力することができます): https://chat.tchepai.com/
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません