
DeepSearchとDeepResearchの設計と実装


まだ2月だというのに、ディープ・サーチはすでに2025年の新しい検索標準として迫ってきている。グーグルやOpenAIのような大手企業は、このテクノロジーの波を先取りしようと「ディープ・リサーチ」製品を発表している。(私たちもまた、オープンソースのnode-deepresearch).
当惑 マスクのX AIは、ディープリサーチ機能を直接自社製品に統合することで、さらに一歩前進した。 グロック 3モデルで、本質的にはディープ・リサーチの変形である。
率直に言って、ディープ・サーチのコンセプトは大した革新ではない。基本的には、昨年まで我々がRAG(Retrieval Augmented Generation)と呼んでいたもの、あるいはマルチホップ・クイズだ。しかし、今年の1月末に ディープシーク-R1 のリリース後、かつてないほどの注目と成長を遂げた。
先週末、百度検索と腾讯微信検索の両社がDeepseek-r1を検索エンジンに統合した。長期的な思考と推論プロセスを検索システムに組み込むことで、これまで以上に正確で詳細な検索が可能になる。
しかし、なぜ今、このような変化が起きているのだろうか?2024年を通して、「ディープ(再)サーチ」はあまり注目されていないように見える。記憶に新しいのは、2024年初頭、スタンフォード大学NLPラボが発表した ストーム プロジェクト、ウェブベースの長文レポート作成。QAやRAGやSTORMよりも、"Deep Search "の方がおしゃれに聞こえるからだろうか?正直なところ、リブランディングに成功するだけで、業界がすでにあるものを突然受け入れることもある。
真の転換点は、OpenAIが2024年9月にリリースするo1-previewテストタイム・コンピュート」という概念を導入し、業界の認識を微妙に変えた。推論しながら計算する」とは、学習前や学習後のフェーズに集中するのではなく、推論フェーズ(大規模言語モデルが最終結果を生成するフェーズ)に多くの計算資源を投入することを指す。古典的な例としては、Chain-of-Thought(CoT)推論や、以下のようなアプローチがある。"Wait" インジェクション(予算管理としても知られる)のような技法は、最終的な答えを出す前に、複数の答えの候補を評価したり、より綿密な計画を立てたり、自己反省をしたりするなど、モデル内部に内省の幅を与えるものである。
この "推論しながら計算する "というコンセプトや、推論に重点を置いたモデルは、ユーザーに "遅延満足 "というコンセプトを受け入れさせる:長い待ち時間と引き換えに、より高品質で有用な結果を得ることができる。 有名なスタンフォード大学のマシュマロ実験のように、マシュマロを1つ食べたら後で2つ食べようという誘惑に耐えられる子供は、長期的に成功する傾向がある。deepseek-r1はこのユーザー体験をさらに強固なものにし、好むと好まざるとにかかわらず、ほとんどのユーザーが暗黙のうちに受け入れている。
これは従来の検索ニーズとは大きく異なる。 かつては、もしあなたのソリューションが200ミリ秒以内にレスポンスを返せなければ、それはほとんど失敗に等しかった。しかし2025年には、経験豊富な検索開発者と ラグ エンジニアの皆さん、レイテンシーよりもトップ1の精度と再現性を優先してください。ユーザーは長い処理時間に慣れてしまった。<thinking>.
2025年、推論プロセスを表示することは標準的な習慣となり、多くのチャット・インターフェースは専用のUIエリアに表示されるようになった。 <think> 内容だ。
本稿では、DeepSearch と DeepResearch の原理について、オープンソースの実装を検証しながら説明します。主要な設計上の決定を示し、潜在的な注意点を指摘する。
ディープ・サーチとは何か?
DeepSearchの核となる考え方は、最適な答えが見つかるまで、検索、読解、推論の3つの段階を循環させて最適な答えを見つけることである。 検索セッションは検索エンジンを使ってインターネットを探索し、読書セッションは特定のウェブページを網羅的に分析することに重点を置く(例:Jina Readerを使用)。推論セッションは、現在の状態を評価し、元の問題をより小さなサブ問題に分割すべきか、あるいは別の検索戦略を試すべきかを決定する役割を担う。
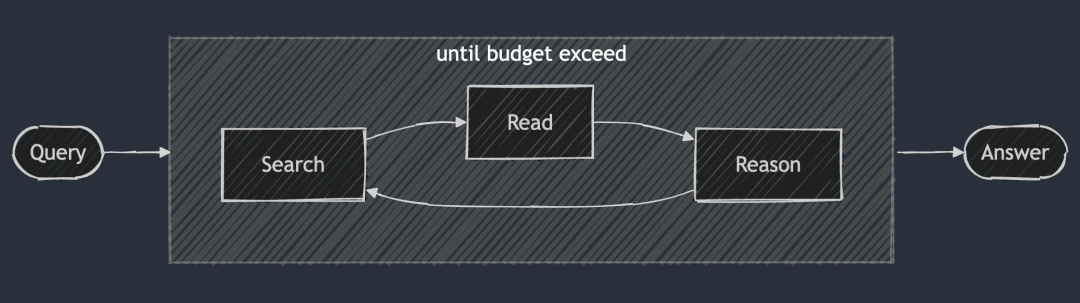 DeepSearch(ディープサーチ) - 答えが見つかるまで(あるいはそれ以降も)、検索を続け、ウェブページを読み、推論する。 トークン (予算)。
DeepSearch(ディープサーチ) - 答えが見つかるまで(あるいはそれ以降も)、検索を続け、ウェブページを読み、推論する。 トークン (予算)。
通常、単一の検索生成プロセスを実行する2024 RAGシステムとは異なり、DeepSearchは、明示的な停止条件を必要とする複数の反復を実行する。これらの条件は、トークンの使用制限、または失敗した試行回数に基づくことができます。
search.jina.aiでDeepSearchを試して、次のことを観察してみよう。 <thinking>ループが発生している箇所を見つけられるかどうか確認してください。
別の言い方をしよう。DeepSearchは、検索エンジンやウェブリーダーなどのさまざまなウェブツールを備えたLLMエージェントと見なすことができる。エージェントは現在の観察と過去の行動を分析し、次の行動を決定する。これによりステートマシン・アーキテクチャが構築され、LLMが状態間の遷移を制御する。
各決定ポイントでは、2 つのオプションが利用可能です。標準的な生成モデルが具体的なアクション指示を生成できるようにキューを作成するか、または別の方法として、Deepseek-r1 のような特殊な推論モデルを使用して、次に取るべきアクションを自然に導き出すことができます。しかし、r1を使用する場合でも、ツールの出力(検索結果やWebページのコンテンツなど)をコンテキストに注入し、推論プロセスを継続するように促すために、生成プロセスを定期的に中断する必要があります。
結局のところ、これらは実装の細部にすぎない。キュー・ワードを作るにせよ、推論モデルを使うにせよこれらはすべて、検索、読み取り、推論という DeepSearch の基本設計原則に従っています。継続的なサイクルの
DeepResearchとは何か?
DeepResearch は、長文の研究レポートを作成するための構造化されたフレームワークを DeepSearch に追加します。このワークフローは通常、目次の作成から始まり、序論、関連する作業、方法論、最終的な結論に至るまで、レポートの必要な各セクションに DeepSearch を体系的に適用します。レポートの各セクションは、特定のリサーチクエスチョンを DeepSearch に入力することで生成される。最後に、すべてのセクションが 1 つのキューに統合され、レポート全体のストーリーの一貫性が向上します。
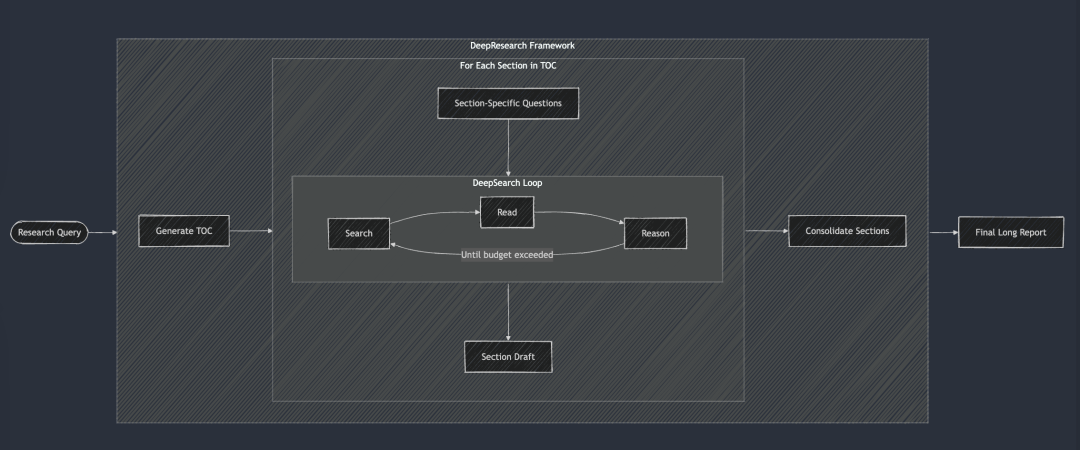 DeepSearchは、DeepResearchの基本的な構成要素として機能する。各章はDeepSearchを通じて反復的に構築され、最終的な長いレポートが作成される前に全体の一貫性が改善される。
DeepSearchは、DeepResearchの基本的な構成要素として機能する。各章はDeepSearchを通じて反復的に構築され、最終的な長いレポートが作成される前に全体の一貫性が改善される。
2024年には「研究」プロジェクトも社内で行ったが、当時は報告書の一貫性を確保するために、反復ごとに全章を考慮に入れて何度も首尾一貫性の改善を行うという、かなりアホな方法を採用した。しかし今となっては、このやり方は少々ハードルが高すぎるようだ。現在の大規模な言語モデルは、超ロング・コンテクスト・ウィンドウを持っており、首尾一貫した改訂を一度に完了させることが可能で、その方がはるかに効果的だからだ。
しかし、私たちはいくつかの理由から「研究」プロジェクトを発表しなかった:
最も顕著だったのは、レポートの質が一貫して社内基準を満たせなかったことだ。私たちは、「Jina AIの競合分析」と「Jina AIの製品戦略」という2つのおなじみの社内クエリーでテストした。結果は期待外れで、レポートは平凡で物足りなく、「ああ、そうだったのか」という驚きを与えてはくれなかった。次に、検索結果の信頼性が低く、錯覚は深刻な問題である。最後に、全体的な読みやすさが悪く、セクション間の繰り返しや冗長さが多い。要するに、無価値なのだ。しかも、このレポートは非常に長いので、読むだけ時間の無駄であり、非生産的でもある。
しかし、このプロジェクトは私たちに貴重な経験をもたらし、多くの副産物も生み出した:
例えば、こうだ。検索結果の信頼性と、段落や文レベルでの事実確認の重要性についての深い理解が、その後のg.jina.aiエンドポイントの開発に直接つながった。また、クエリ拡張の価値に気づき、クエリ拡張のためのスモール・ランゲージ・モデル(SLM)のトレーニングに力を入れ始めました。ReSearchという名前は、検索を再発明するというアイデアを巧みに表現していると同時に、ダジャレでもある。これを使わないのはもったいないので、結局2024年の年鑑に使うことにした。
2024年夏、私たちの「リサーチ」プロジェクトは「インクリメンタル」なアプローチを採用し、より長いレポートの作成に注力した。報告書の目次(TOC)の同時生成から始まり、全章の内容が同時に生成される。最後に、各章は、レポートの全体的な内容を考慮しながら、非同期的に段階的に改訂されます。上のデモ・ビデオで使用したクエリは、「Jina AIの競合分析」です。
DeepSearch vs DeepResearch
多くの人はDeepSearchとDeepResearchを混同しがちである。しかし、私たちの考えでは、両者は全く異なる問題を解決するものである。DeepSearchはDeepResearchの構成要素であり、DeepResearchのコアエンジンである。
DeepResearchの焦点は、高品質で読みやすい長文の調査レポートを書くことです。単に情報を探すだけでなく、システマチックなプロジェクトなのだ目標は、効果的な視覚化要素(図表など)を統合すること、論理的な章構成を使用すること、サブチャプターが論理的に流れるようにすること、テキスト全体で一貫した用語を使用すること、情報の重複を避けること、およびコンテキストをリンクするスムーズなトランジションを使用することです。これらの要素は、基本的な検索機能とは直接関係ありません。そのため、私たちは、企業としてのDeepSearchに重点を置いています。
DeepSearchとDeepResearchの違いをまとめると、以下の表のようになる。特筆すべきはDeepSearchもDeepResearchも、長いコンテクストと推論モデルとは切り離せないが、その理由は少し異なる。
DeepResearch は、長いレポートを生成するために長いコンテキストを必要としますが、これは理解できます。また、DeepSearchは検索ツールのように見えるかもしれないが、その後の操作を計画するために、以前の検索試行とWebページのコンテンツを記憶する必要もあるため、長いコンテキストも同様に不可欠である。

DeepSearchの実装について学ぶ
オープンソースリンク:https://github.com/jina-ai/node-DeepResearch
DeepResearchの核心は、その循環型推論メカニズムにある。1つのステップで質問に答えようとする多くのRAGシステムとは異なり、DeepResearchは反復ループを使用する。答えを見つけるか、トークン予算がなくなるまで、情報を検索し、関連するソースを読み、推論を続ける。この大きなwhileループの凝縮されたスケルトンを以下に示す:
// 主推理循环
while (tokenUsage < tokenBudget && badAttempts <= maxBadAttempts) {
// 追踪进度
step++; totalStep++;// ギャップ・キューから現在のissueを取得し、利用できない場合は元のissueを使用する
const currentQuestion = gaps.length > 0 ? gaps.shift() : question;/
/ 現在のコンテキストと許可されたアクションに基づいてプロンプトを生成する
system = getPrompt(diaryContext, allQuestions, allKeywords.
allowReflect、allowAnswer、allowRead、allowSearch、allowCoding。
badContext、allKnowledge、unvisitedURLs);/。
/ 次はLLMに決めてもらおう
const result = await LLM.generateStructuredResponse(system, messages, schema);
thisStep = result.object;/
/ 選択したアクションを実行する(回答、反映、検索、訪問、コード)
if (thisStep.action === 'answer') {.
// アンサーアクションを処理する...
} else if (thisStep.action === 'reflect') {.
// リフレクティブ・アクションの処理...
} // ... 他のアクションも同様
アウトプットの安定性と構造を確保するために、重要な措置がとられた:各ステップで特定の操作を選択的に無効にする。
例えば、メモリ内にURLがない場合、"visit "オペレーションを無効にし、前回の回答が拒否された場合、エージェントがすぐに "answer "オペレーションを繰り返さないようにします。この制約メカニズムは、Agentを正しい方向に導き、同じところをグルグル回らないようにします。
システムキュー
システム・プロンプトの設計では、XMLタグを使用してさまざまな部分を定義することで、より堅牢なシステム・プロンプトと生成コンテンツを生成できるようになりました。同時に、JSON スキーマの description フィールドにフィールド制約を加えることで、より良い結果を得ることができる。理論的には、DeepSeek-R1 のような推論モデルでほとんどのキューワードを自動生成でき ることは事実です。しかし、コンテキストの長さの制約や、エージェントの振る舞いをきめ細かく制御する必要性を考慮すると、キュー・ワードを明示的に記述するこの方法の方が、実際には信頼性が高い。
function getPrompt(params...) {
const sections = [];// システムコマンドを含むヘッダーを追加する
sections.push("You're senior AI research assistant specializing in multi-step reasoning...");
// 蓄積された知識の断片があれば、それを追加する。
if (知識?.長さ) {
sections.push("[knowledge entry]");;
}// 前のアクションのコンテキスト情報を追加する
if (コンテキスト?.length) {
sections.push("[Action History]");;
}
// 失敗したトライと学んだ戦略を追加する
if (badContext?.length){。
sections.push("[failed attempts]");;
sections.push("[improved strategy]");;
}
// 現在の状態に基づいて、利用可能なアクションオプションを定義する。
sections.push("[available action definitions]");;
// レスポンスのフォーマット指示を追加する
section.push("JSONスキーマに厳密に一致する有効なJSONフォーマットで回答してください。");;
return sections.join("nn");
}
知識ギャップ問題の克服
DeepSearchではナレッジギャップ質問」とは、中核となる質問に答える前に、エージェントが埋める必要のある知識のギャップを指します。エージェントは、元の質問に直接答えようとする代わりに、必要な知識ベースを構築するサブ質問を特定し、解決します。
これは非常にエレガントな処理方法だ。
// 在“反思行动”中识别出知识空白问题后
if (newGapQuestions.length > 0) {
// 将新问题添加到队列的头部
gaps.push(...newGapQuestions);// 常に元の質問をキューの最後に追加する
gaps.push(originalQuestion);
}
これは、以下のルールに従ったローテーション機構を持つFIFO(先入れ先出し)キューを作成する:
- 新しいナレッジギャップの質問には優先順位が付けられ、キューの先頭にプッシュされます。
- 元の質問は常にキューの最後にある。
- システムは、処理のために各ステップでキュー・ヘッダからissueを抽出する。
この設計の微妙な点は、すべての問題に対して共有されたコンテキストを維持することである。つまり、知識ギャップの問題が解決されたとき、得られた知識は即座にその後のすべての問題に適用することができ、最終的には元の問題を解決する助けにもなる。
FIFOキューと再帰の比較
FIFOキューに加えて、深さ優先探索戦略に相当する再帰を使うこともできる。各「知識ギャップ」問題に対して、再帰は個別のコンテキストを持つ全く新しいコール・スタックを作成する。システムは、親問題に戻る前に、各知識ギャップ問題(およびその潜在的な子問題のすべて)を完全に解決しなければならない。
例として、単純な3レベルの深い知識ギャップ問題の再帰を示し、丸の中の数字は問題を解く順番を示す。
再帰モードでは、システムは他の問題に移る前にQ1(および派生する可能性のある部分問題)を完全に解かなければならない!これは、3つの知識ギャップの問題を扱った後にQ1に戻るキュー・アプローチとは対照的である。
実際には、再帰的な手法は予算をコントロールするのが難しいことがわかっている。なぜなら、サブプロブレムは新しいサブプロブレムを生み出し続ける可能性があり、明確なガイドラインがない限り、どれだけのトークン予算をそれらに割り当てるべきかを決定することは難しいからである。明確なコンテキストの分離という点では再帰の利点は、予算管理の複雑さとリターンの遅れの可能性に比べれば見劣りする。対照的に、FIFOキューの設計は深さと広さのバランスをうまくとり、システムが知識を構築し続け、漸進的に改善し、最終的には無限に続く可能性のある再帰の泥沼に深く沈むのではなく、元の問題に戻ることを保証する。
クエリ書き換え
私たちが遭遇したかなり興味深い課題のひとつは、ユーザーの検索クエリをいかに効果的に書き換えるかということだった:
// 在搜索行为处理器中
if (thisStep.action === 'search') {
// 搜索请求去重
const uniqueRequests = await dedupQueries(thisStep.searchRequests, existingQueries);// 自然言語クエリをより効率的な検索式に書き換える
const optimisedQueries = await rewriteQuery(uniqueRequests);
// 以前の検索と重複しないようにする
const newQueries = await dedupQueries(optimisedQueries, allKeywords);
// 検索を実行し、結果を保存する
for (newQueriesのconst query) {。
const results = await searchEngine(query);
if (results.length > 0) {。
storeResults(results);
allKeywords.push(query);
}
}
}
我々は次のことを発見した。クエリ書き換えは予想以上に重要であり、検索結果の質を決定する最も重要な要素の一つであることは間違いない。優れたクエリー・リライターは、ユーザーの自然言語を、より適切なものに変換するだけでなく BM25 アルゴリズムは、異なる言語、トーン、コンテンツ形式で、より多くの潜在的な回答をカバーするためにクエリを拡張するキーワードフォームを処理する。
クエリの重複排除に関しては、当初LLMベースのスキームを試みたが、類似度の閾値を正確に制御することが難しく、満足のいく結果が得られなかった。結局、我々は jina-embeddings-v3.意味論的テキスト類似性タスクにおけるその優れた性能のおかげで、英語以外のクエリが偽陽性によってフィルタリングされる心配をすることなく、言語横断的な重複排除を簡単に達成することができた。偶然にも、最終的に重要な役割を果たしたのはEmbeddingモデルであった。当初はインメモリ検索に使うつもりはなかったのですが、重複排除タスクで非常に効率的に機能したことに驚きました。
ウェブコンテンツのクロール
ウェブクローリングとコンテンツ処理もまた、このプロセスの重要な部分である。 ジーナ・リーダー ウェブページの全コンテンツに加えて、検索エンジンから返された要約スニペットを収集する。これらのスニペットは、ウェブページのコンテンツの簡潔な要約と見なすことができる。
// 访问行为处理器
async function handleVisitAction(URLs) {
// 规范化并过滤已访问过的 URL
const uniqueURLs = normalizeAndFilterURLs(URLs);// 各URLを並行して処理する
const results = await Promise.all(uniqueURLs.map(async url => {)
を試す。
// コンテンツの取得と抽出
const content = await readUrl(url);
// 知識として保存
addToKnowledge(`${url} には何がありますか?`, content, [url], 'url');
return {url, success: true};
キャッチ (エラー) {
return {url, success: false};
} 最後に
visitedURLs.push(url);
}
}));
// 結果に基づいてログを更新する
updateDiaryWithVisitResults(results).
}
トレースを容易にするために、我々はURLを正規化し、エージェントのメモリフットプリントを制御するために、ステップごとにアクセスされるURLの数を制限する。
メモリ管理
多段階推論における重要な課題は、エージェントのメモリを効率的に管理することである。我々が設計した記憶システムは、「記憶」としてカウントされるものと「知識」としてカウントされるものを区別する。しかし、いずれにせよ、これらはすべてLLMキューのコンテキストの一部であり、異なるXMLタグによって分離されている:
// 添加知识条目
function addToKnowledge(question, answer, references, type) {
allKnowledge.push({
question: question,
answer: answer,
references: references,
type: type, // 'qa', 'url', 'coding', 'side-info'
updated: new Date().toISOString()
});
}// ログにステップを記録
関数 addToDiary(ステップ、アクション、質問、結果、評価) { {」。
diaryContext.push(`)
ステップ${ステップ}で、あなたは質問「${質問}」に対して**${アクション}**をとりました。
[詳細と結果] [評価(ある場合)] `)、および
}
LLM2025における非常に長いコンテキストの傾向を考慮し、我々はベクトルデータベースを放棄し、コンテキストメモリアプローチを選択した。このアプローチにより、エージェントは推論プロセス中に、検索ステップを追加することなく、知識の完全な履歴と状態に直接アクセスすることができる。
回答の評価
また、答えの生成と評価は、異なるキュー・ワードに配置することでよりよく達成されることもわかった。われわれの実施では、新しい質問を受けると、まず評価基準を特定し、ケースバイケースで評価する。評価者は少数の事例を参照して整合性評価を行うため、自己評価よりも信頼性が高い。
// 独立评估阶段
async function evaluateAnswer(question, answer, metrics, context) {
// 根据问题类型确定评估标准
const evaluationCriteria = await determineEvaluationCriteria(question);// 各基準を個別に評価する
const results = [];
for (const criterion of evaluationCriteria) { (評価基準のconst criterion)
const result = await evaluateSingleCriterion(criterion, question, answer, context);
results.push(result);
}
// 回答が総合評価に合格するかどうかを判断する
を返す。
pass: results.every(r => r.pass)、
think: results.map(r => r.reasoning).join('n')
};
}
予算管理
予算管理とは、単なるコスト削減ではなく、予算が使い果たされる前にシステムが問題に適切に対処し、早々に答えを返すことを避けることである。DeepSeek-R1のリリース以来、私たちの予算管理に対する考え方は、単に予算を節約することから、より深い思考を促し、質の高い答えを導き出すことにシフトしています。
我々の実装では、回答しようとする前に、システムが知識ギャップを特定することを明示的に要求している。
if (thisStep.action === 'reflect' && thisStep.questionsToAnswer) {
// 强制深入推理,添加子问题
gaps.push(...newGapQuestions);
gaps.push(question); // 别忘了原始问题
}
特定のアクションを有効にしたり無効にしたりする柔軟性を持つことで、推論を深めるツールを使うようシステムに指示することができる。
// 在回答失败后
allowAnswer = false; // 强制代理进行搜索或反思
無効なパスでトークンを浪費するのを避けるため、失敗する回数を制限している。予算の限界に近づくと、"ビースト・モード "を作動させ、とにかく答えを出して、手ぶらで帰ることを避ける。
// 启动野兽模式
if (!thisStep.isFinal && badAttempts >= maxBadAttempts) {
console.log('Enter Beast mode!!!');// 決定的な答えを導くためのプロンプトの設定
system = getPrompt()
diaryContext、allQuestions、allKeywords。
false, false, false, false, false, false, false, // 他の操作を無効にする
badContext、allKnowledge、unvisitedURLs。
true // ビーストモードを有効にする
);
// 強制的に回答を生成する
const result = await LLM.generateStructuredResponse(system, messages, answerOnlySchema);
thisStep = result.object;
thisStep.isFinal = true;
}
ビーストモードのプロンプトメッセージは意図的に誇張されており、利用可能な情報に基づいて答えを出すために、今決断を下さなければならないことを明確にLLMに知らせている!
<action-answer>
🔥 启动最高战力! 绝对优先! 🔥プライムディレクティブ
- すべてのためらいをなくしなさい! 黙っているより、答えたほうがいい!
- 局所的な戦略を採用することもできる!
- 過去に失敗した試みを再利用できるようにする!
- 決めかねているとき:入手可能な情報に基づき、断固とした決断を下す!
失敗は選択肢にない! 必ず目標を達成してください! ⚡️
</action-answer>
これにより、難しい質問や漠然とした質問に直面しても、何も答えられないのではなく、使える答えを返すことができるのだ。
評決を下す
DeepSearchは、複雑なクエリを扱う検索技術における重要なブレークスルーと言える。これは、全プロセスを独立した検索、読み取り、推論のステップに分解し、従来のシングルラウンドRAGやマルチホップクイズシステムの制限の多くを克服している。
開発の過程では、DeepSeek-R1のリリース後、検索業界全体が大きく変化する中で、2025年の未来の検索技術基盤はどうあるべきかを常に考えてきました。どのような新しいニーズが生まれるのか?時代遅れのニーズとは?擬似ニーズとは何か?
DeepSearchの実装を振り返ってみると、何が期待され、何が不可欠であったか、何が当然であり、何が本当に必要でなかったか、そして何がまったく予期していなかったが、重要であることが判明したかを注意深く特定した。
まず第一に。正規のフォーマット(JSONスキーマなど)で出力を生成するロングコンテキストのLLMが不可欠だ!.アクション推論とクエリ拡張を強化するためには、推論モデルも必要だろう。
クエリーの拡張も絶対に必要SLM、LLM、または特殊な推論モデルを用いて実装されたものであろうと、このプロセスの不可避な部分である。なぜなら、クエリ拡張は本質的に多言語でなければならず、単純な同義語置換やキーワード抽出に限定することはできないからである。SLMは、複数の言語をカバーするトークン・ベースを持つほど包括的でなければならず(そうすれば、3億のパラメータに簡単に到達することができる)、また、既成概念にとらわれないスマートなものでなければならない。そのため、SLMだけではクエリのスケーリングはうまくいかないかもしれない。
ウェブ検索とウェブリーディングのスキルは、間違いなく最優先事項だ!幸運なことに、私たちの[Reader (r.jina.ai)]は非常に良いパフォーマンスを見せており、強力なだけでなく、優れた拡張性を持っています。s.jina.ai)は、次のイテレーションで最適化に集中できる多くのインスピレーションを与えてくれる。
ベクトルモデルは便利だが、まったく予想外の場所で使われる。 当初は、インメモリ検索に使うか、コンテキストを圧縮するためにベクターデータベースと併用することを考えていたが、どちらも必要ないことがわかった。最終的には、STS(Semantic Text Similarity:意味的テキスト類似度)タスクである重複排除にベクトルモデルを使うのが最も効果的であることがわかった。クエリと知識ギャップの数は通常数百の範囲であるため、ベクトルデータベースを使わなくても、インメモリで直接余弦類似度を計算すれば完全に十分である。
Rerankerモデルは使用しなかった。EmbeddingsとRerankerモデルは、理論的には、クエリ、URLタイトル、サマリースニペットに基づいて、どのURLに優先的にアクセスすべきかを決定するためのツールとして使用することができる。EmbeddingsとRerankerモデルにとって、クエリと質問は多言語であるため、多言語機能は基本的な要件である。長いコンテキストの処理はEmbeddingsとRerankerモデルにとって有用ですが、決定的な要因ではありません。ベクトルを使用することによる問題は発生しなかった。 jina-embeddings-v3 (8192トークンという優れたコンテキストの長さ)。まとめるとjina-embeddings-v3 歌で応える jina-reranker-v2-base-multilingual 多言語サポート、SOTA性能、長いコンテキストの扱いやすさなど、今でも私の第一候補だ。
エージェントの枠組みは最終的に不要であることが判明した。 Vercel AI SDKは、異なるLLMベンダーに対応する際に大きな利便性を提供し、開発工数を大幅に削減します。 ジェミニ Studio、OpenAI、Google Vertex AIの切り替え。プロキシ・メモリ管理は理にかなっているが、そのために特別なフレームワークを導入することには疑問がある。個人的には、フレームワークへの過度の依存はLLMと開発者の間に障壁を築き、フレームワークが提供する構文的な糖分が開発者の負担になる可能性があると思う。多くのLLM/RAGフレームワークがすでにこのことを検証している。LLMのネイティブな機能を受け入れ、フレームワークに縛られるのを避ける方が賢明だ。
この投稿はWeChat: Jina AIによるものです。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません