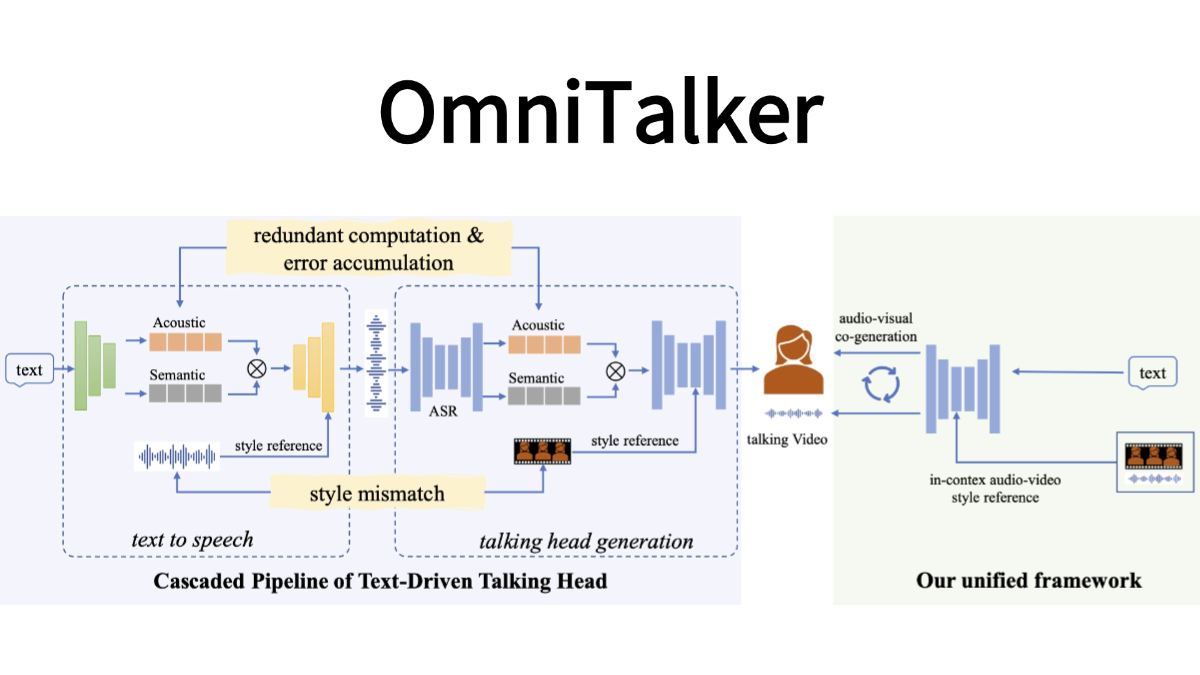
DeepCoder-14B-Preview:コード生成に優れたオープンソースモデル

はじめに
DeepCoder-14B-Previewは、Agenticaチームによって開発され、Hugging Faceプラットフォームでリリースされたオープンソースのコード生成モデルです。DeepSeek-R1-Distilled-Qwen-14Bをベースに、分散強化学習(RL)技術によって最適化されており、最大64Kまでの処理が可能です。 トークン 非常に長いコンテキストのこのモデルは140億個のパラメータを持ち、LiveCodeBench v5のテスト(2024年8月1日から2025年2月1日)で60.6%のPass@1精度を達成し、ベースモデルより8%向上し、OpenAIのo3-miniに近い性能を実現した。モデルの重み、トレーニングデータ、スクリプトを含め、完全にオープンソースである。DeepCoderの目標は、開発者が複雑なコードを効率的に書けるようにすることであり、特にプログラミングコンテストや大規模プロジェクトに適している。

機能一覧
- 長いコードの生成:64Kトークンまでのコンテキストをサポートし、非常に長いコードを生成して扱うことができる。
- 高精度出力:LiveCodeBench v5で60.6% Pass@1、信頼性の高いコード品質を実現。
- オープンソース:モデルファイル、データセット、トレーニングスクリプトを無料でダウンロードし、カスタマイズすることができます。
- 幅広いプログラミング作業をサポート:競技会の質問回答、コードのデバッグ、プロジェクト開発に適しています。
- 長い文脈推論:GRPO+とDAPO技術によって最適化され、長いコード生成能力を確保。
ヘルプの使用
DeepCoder-14B-Previewは、コードを生成したり、複雑なプログラミング作業を処理したりするのに役立つ強力なツールです。以下は、詳細なインストールおよび使用ガイドです。
設置プロセス
DeepCoder-14B-Preview をローカルで使用するには、環境を準備し、モデルをダウンロードする必要があります。手順は以下の通りです:
- ハードウェアとソフトウェアの準備
- GPUを搭載したコンピュータが必要で、NVIDIA H100または24GB以上のRAMを搭載したグラフィックカードを推奨。
- Python 3.10のインストール:実行
conda create -n deepcoder python=3.10 -y次に環境をアクティブにする。conda activate deepcoder. - 依存ライブラリのインストール: run
pip install transformers torch huggingface_hub vllm.
- ダウンロードモデル
- 公式ページはhttps://huggingface.co/agentica-org/DeepCoder-14B-Preview。
- ファイルとバージョン "で、モデルファイル(例えば
model-00001-of-00012.safetensors). - downloadコマンドを使う:
huggingface-cli download agentica-org/DeepCoder-14B-Preview --local-dir ./DeepCoder-14B - ダウンロード後、モデルファイルはローカルに保存されます。
./DeepCoder-14Bフォルダー
- 積載モデル
- Pythonでモデルを読み込む:
from transformers import AutoModelForCausalLM, AutoTokenizer model_path = "./DeepCoder-14B" model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype="auto", device_map="auto") tokenizer = AutoTokenizer.from_pretrained(model_path) - これでモデルがGPUにロードされ、使用できるようになります。
- Pythonでモデルを読み込む:
主な機能の使い方
DeepCoderの中核は、コードの生成と長いコンテキストの処理である。その仕組みはこうだ:
コードの生成
- 入力プログラムの要件
- 配列の最大値を求めるPython関数を書きなさい」というような問題を用意する。
- 要件をテキストに変換する:
prompt = "写一个 Python 函数,找出数组中的最大值"
- コードの生成
- 次のコードを使って答えを生成してください:
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_new_tokens=512, temperature=0.6, top_p=0.95) result = tokenizer.decode(outputs[0], skip_special_tokens=True) print(result) - 可能な出力:
def find_max(arr): if not arr: return None max_value = arr[0] for num in arr: if num > max_value: max_value = num return max_value
- 次のコードを使って答えを生成してください:
- 最適化された発電
- より長いコードが必要な場合は
max_new_tokensは1024以上である。 - セットアップ
max_tokens=64000最適なロングコンテキストパフォーマンスを達成。
- より長いコードが必要な場合は
長いコンテキストの処理
- ロングコードを入力
- 例えば、32Kトークンの長さのコードを持っていて、それをモデルに更新させたいとしよう:
long_code = "def process_data(data):\n # 几千行代码...\n return processed_data" prompt = long_code + "\n请为这个函数添加异常处理"
- 例えば、32Kトークンの長さのコードを持っていて、それをモデルに更新させたいとしよう:
- 続きを生成する
- 入力して生成する:
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_new_tokens=512, temperature=0.6, top_p=0.95) result = tokenizer.decode(outputs[0], skip_special_tokens=True) print(result) - 出力は次のようになる:
def process_data(data): try: # 几千行代码... return processed_data except Exception as e: print(f"错误: {e}") return None
- 入力して生成する:
- 検証結果
- コードが要件を満たしているかチェックする。そうでない場合は、要件をより明確に記述する。
注目機能 操作手順
DeepCoderの長大なコード生成能力はそのハイライトであり、コンペや大規模プロジェクトに適している。
コンテストを解く
- タイトル取得
- Codeforcesから、「配列が与えられたら、可能なサブセットをすべて返す」といったトピックを探す。
- トピックの説明を入力します:
prompt = "给定一个数组,返回所有可能的子集。例如,输入 [1,2,3],输出 [[],[1],[2],[3],[1,2],[1,3],[2,3],[1,2,3]]"
- コードの生成
- generateコマンドを実行する:
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_new_tokens=512, temperature=0.6, top_p=0.95) result = tokenizer.decode(outputs[0], skip_special_tokens=True) print(result) - 出力は次のようになる:
def subsets(nums): result = [[]] for num in nums: result += [curr + [num] for curr in result] return result
- generateコマンドを実行する:
- テスト結果
- Pythonでコードを実行するには、次のようにタイプする。
[1,2,3]出力が正しいことを確認する。
- Pythonでコードを実行するには、次のようにタイプする。
デバッグコード
- 質問コードを入力
- バグだらけのコードがあったとしよう:
buggy_code = "def sum_numbers(n):\n total = 0\n for i in range(n)\n total += i\n return total" prompt = buggy_code + "\n这段代码有语法错误,请修复"
- バグだらけのコードがあったとしよう:
- 修正の生成
- 入力して生成する:
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_new_tokens=512, temperature=0.6, top_p=0.95) result = tokenizer.decode(outputs[0], skip_special_tokens=True) print(result) - 出力は次のようになる:
def sum_numbers(n): total = 0 for i in range(n): total += i return total
- 入力して生成する:
- 検証の修正
- 構文が正しいかチェックし、コードを実行して結果を確認する。
使用上の推奨事項
- システムプロンプトを追加せず、ユーザープロンプトに直接要件を記述する。
- セットアップ
temperature=0.6歌で応えるtop_p=0.95最適な結果を得るために。 - そうしれいかん
max_tokens長いコンテクストを利用するために64000に設定する。
アプリケーションシナリオ
- プログラミング・コンペティション
DeepCoderはコンテストの質問に対する答えを素早く生成し、LiveCodeBenchやCodeforcesでの複雑なタスクに適しています。 - 大規模プロジェクト開発
開発者が大規模なプロジェクトを完了できるように、長いコードモジュールを生成することができる。 - 教育と学習
学生はサンプルコードの生成、アルゴリズムの学習、課題のデバッグに利用できる。
品質保証
- DeepCoder-14B-Previewは無料ですか?
そう、MITライセンスの完全なオープンソースで、誰でも無料で使えるのだ。 - そのために必要なハードウェアは?
GPUと24GB以上のビデオメモリを搭載したコンピュータを使用することを推奨します。CPUを使用すると、かなり遅くなります。 - サポートしているプログラミング言語は?
主にPythonに特化しているが、プロンプトの明確さに応じて、Java、C++、その他の言語のコードも生成できる。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません