
ビッグモデルはいかにして "賢く "なるのか?スタンフォード大学が自己改善のカギを明かす:4つの認知行動

人工知能の分野は近年、特に大規模言語モデリング(LLM)の分野で目覚ましい進歩を遂げている。 Qwenのような多くのモデルは、答えを自己チェックして誤りを修正する驚くべき能力を示している。 しかし、すべてのモデルが同じように自己改善できるわけではない。 同じ計算資源と「考える」時間が与えられた場合、これらの資源を最大限に活用して飛躍的に性能を向上させることができるモデルもあれば、ほとんど成功しないモデルもある。 この現象は、「この不一致の原因は何か?
人間が困難な問題に直面したときに、より深く考えることに時間を費やすように、大規模言語の高度なモデルの中には、強化学習によって自己改善のための訓練を受けると、同様の推論行動を示すようになるものがある。 しかし、同じ強化学習で訓練したモデルでも、自己改善には大きな違いがある。 例えば、カウントダウンゲームでは、Qwen-2.5-3BがLlama-3.2-3Bを大きく上回る。 両モデルとも初期段階では比較的弱いが、強化学習トレーニング終了時には、Qwenが約60%の精度を達成するのに対し、Llamaは約30%に過ぎない。 この大きな差の背景には、どのようなメカニズムが隠されているのだろうか?
スタンフォード大学の最近の研究は、大規模なモデルが自己改善する能力の背後にあるメカニズムを深く掘り下げ、その根底にある重要な言語モデルが、「自己改善」であることを明らかにした。 認知行動 AIの重要性 この研究は、AIシステムの自己改善能力を理解し、強化するための新たな視点を提供する。
この研究は発表されるや否や、広く議論されている。 シンセラボのCEOは、この発見はエキサイティングで、どんなモデルにも組み込んでパフォーマンスを向上させることができると考えている。

4つの重要な認知行動
自己改善の違いの理由を調べるため、研究者たちはQwen-2.5-3BとLlama-3.2-3Bという2つのベースモデルに注目した。 Qwenの問題解決能力が著しく向上したのに対し、Llama-3は同じ訓練過程で比較的限定的な向上しか示さなかったのだ。 では、この違いはどのようなモデルの特性によるものなのだろうか?

この問題を体系的に検討するために、研究チームは問題解決に不可欠な認知行動を分析するためのフレームワークを開発した。 このフレームワークでは、4つの重要な認知行動を説明している:
- 検証:: システム的なエラーチェック。
- バックトラック:: 失敗したアプローチを捨て、新しい道を試す。
- サブゴールの設定複雑な問題を扱いやすいステップに分解する。
- 逆転の発想(2)逆導入: 望む結果から初期入力への逆導入。
これらの行動パターンは、専門的な問題解決者が複雑なタスクに取り組む方法と非常によく似ている。 例えば、数学者は導出の各ステップを注意深く検証し、矛盾に遭遇したらバックトラックで前のステップをチェックし、複雑な定理をより単純なレンマに分解してステップバイステップの証明を行う。

予備的な分析によると、Qwenモデルは、特に検証やバックトラックの分野で、このような推論行動を自然に示すが、Llama-3モデルにはこのような行動が顕著に欠けている。 これらの観察に基づき、研究者たちは核となる仮説を立てた: 増加したテスト時間をモデルが有効に活用するためには、初期戦略における特定の推論行動が重要である。 言い換えれば、AIモデルが「考える」時間が増えたときに「より賢く」なるには、まず基本的な思考スキル、例えばエラーをチェックしたり結果を検証したりする習慣を身につけなければならない。 このような基本的な思考スキルが最初から欠如しているモデルでは、思考時間や計算資源を増やしても、効果的にパフォーマンスを向上させることはできない。 これは人間の学習プロセスとよく似ている。もし生徒に基本的な自己チェックやエラー訂正のスキルがない場合、単に試験を長く受けるだけでは、成績が大幅に向上する可能性は低い。
実験的検証:認知行動の重要性
上記の仮説を検証するため、研究者たちは一連の巧妙な介入実験を行った。
まず、特定の認知行動(特に回顧)を含む合成推論軌跡を用いて、Llama-3モデルのブートストラップを試みた。 その結果、こうして導かれたLlama-3モデルは、強化学習において有意な改善を示し、Qwen-2.5-3Bに匹敵する性能の向上さえ示した。
第二に、ブートストラップに使用した推論の軌跡に不正解が含まれていたとしても、これらの軌跡が正しい推論パターンを示す限り、Llama-3モデルは進歩することができた。 この発見は モデルの自己改善を促す重要な要素は、推論行動の有無であり、答えそのものの正しさではない。
最後に、研究者たちはOpenWebMathデータセットをフィルタリングして、これらの推論行動を強調し、このデータをLlama-3モデルの事前学習に使用した。 実験結果は、この事前学習データの適応が、モデルが計算資源を効率的に利用するために必要な推論行動を誘導するのに有効であることを示している。 チューニングされた事前訓練Llama-3モデルの性能向上の軌跡は、驚くことにQwen-2.5-3Bモデルのそれと一致している。
これらの実験結果は、モデルの初期推論動作と、モデル自身を改善する能力との間に強い関連性があることを強く明らかにしている。 この関連性は、ある言語モデルが追加の計算資源を効率的に利用できる一方で、他の言語モデルが停滞している理由を説明するのに役立つ。 これらのダイナミクスをより深く理解することは、問題解決を大幅に改善できるAIシステムを開発するために不可欠である。
モデル選択によるカウントダウンゲーム
この研究の冒頭では、同じような大きさの言語モデルでも、モデルファミリーが異なると、強化学習で訓練したときの性能向上が大きく異なるという驚くべき見解が示されている。 この現象を詳しく調べるため、研究者たちは主なテストベッドとしてゲーム「カウントダウン」を選んだ。
カウントダウンは、足し算、引き算、掛け算、割り算の4つの基本操作を使って、与えられた数字を組み合わせて目標の数字に到達する算数パズルです。 例えば、25、30、3、4という数字と32という目標数字が与えられた場合、プレイヤーは(30 - 25 + 3) × 4 = 32というように、一連の操作を通して32という正確な数字を導き出す必要がある。
この研究にカウントダウンゲームが選ばれたのは、モデルの数学的推論、計画、探索戦略能力を調べると同時に、研究者が詳細な分析を行うことができる比較的制限された探索空間を提供するためである。 より複雑な領域と比較して、カウントダウンゲームは分析の難易度を下げながらも、複雑な推論を効果的に調べることができる。 さらに、カウントダウンの成功は、純粋な数学的知識よりも、他の数学的課題よりも問題解決能力に依存している。
研究者たちは、モデルファミリーの違いによる学習の違いを比較するために、Qwen-2.5-3BとLlama-3.2-3Bという2つのベースモデルを選んだ。 強化学習実験は、VERLライブラリに基づき、TinyZeroを使って実装されている。 彼らはPPO(Proximal Policy Optimization)アルゴリズムを用いて、250ステップのモデル学習を行い、キューごとに4つの軌跡をサンプリングした。 PPOアルゴリズムを選択した理由は グルポ やREINFORCEのような他の強化学習アルゴリズムと比較して、PPOは様々なハイパーパラメータ設定下でより優れた安定性を示すが、アルゴリズム間の全体的な性能差は大きくない。 (編集部注:原文の「GRPO」は事務的な誤りであり、「PPO」と読むべきであると思われる。)
実験結果から、2つのモデルの学習軌跡が大きく異なることが明らかになった。 タスクの初期段階では両者とも低いスコアで同様のパフォーマンスを示すが、Qwen-2.5-3Bはトレーニングの30ステップ目あたりで「質的な飛躍」を示し、モデルによって生成される応答が著しく長くなり、精度が大幅に向上していることがわかる。 トレーニング終了時、Qwen-2.5-3Bは約601 TP3Tの精度を達成し、これはLlama-3.2-3Bの301 TP3Tを大きく上回る。
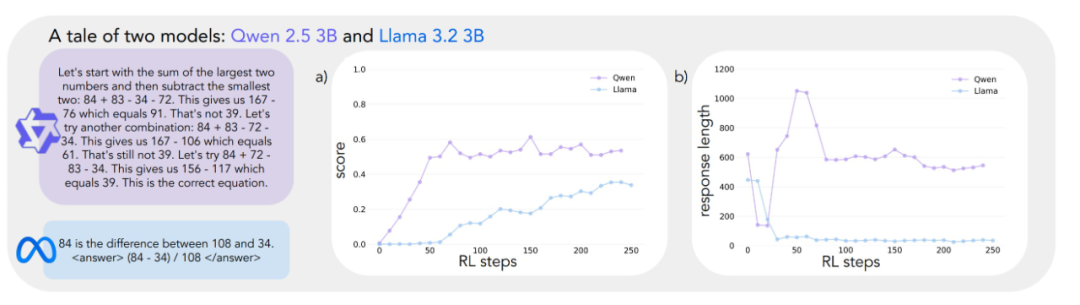
トレーニングの後半になると、研究者たちはQwen-2.5-3Bの挙動に興味深い変化を観察した。モデルは徐々に、明示的な検証文(例えば「8*35は280、高すぎる」)の使用から、暗黙的な解のチェックへと移行していったのだ。 モデルはпоследовательно(ロシア語では "последовательно land "または "逐次的 "と訳される)を使って、自分自身の仕事を言葉で評価する代わりに、正しい解を見つけるまでさまざまな解を試してみる。このコントラストは印象的だ。 この対比は、「推論に基づく自己改善をモデルが成功させるための基礎的な能力とは何か」という中心的な問いにつながる。 この問いに答えるには、認知行動を分析するための体系的な枠組みが必要である。
認知行動分析のフレームワーク
2つのモデルの全く異なる学習軌跡をより深く理解するために、研究者たちはモデル出力における主要な認知行動を特定し分析するためのフレームワークを開発した。 このフレームワークは、4つの基本的な行動に焦点を当てている:
- バックトラックエラーが検出された場合、明示的にメソッドを修正する(例えば、"This method doesn't work because ....).").
- 検証: 中間結果を系統的にチェックする(例えば、「この結果を検証するために.... でこの結果を検証しよう」など)。
- サブゴールの設定複雑な問題を管理しやすいステップに分解する(例:「この問題を解決するには、まず...する必要がある」)。.
- 逆転の発想目標指向の推論問題では、望ましい結果から出発し、逆算して解答への道筋を見つける(例:「目標の75に到達するには、...で割り切れる数が必要です。) .").
これらの行動が選ばれたのは、言語モデルで一般的な直線的で単調な推論パターンとはまったく異なる問題解決戦略を表しているからである。 これらの認知行動は、よりダイナミックで、探索のような推論の軌跡を可能にする。 この一連の行動は網羅的なものではないが、研究者たちは、カウントダウンゲームや、数学的証明の構築など、より広範な数学的推論タスクにおける人間の問題解決戦略を特定しやすく、自然に適合するものを選んだ。
それぞれの認知行動は、推論における役割を通して理解することができる。 トークン 例えば、バックトラックは、前のステップのトークン列を明示的に否定したり置き換えたりすることで表現される。 例えば、バックトラックは、前のステップを明示的に否定したり置き換えたりするトークン列として表現される。検証は、結果を解の基準と比較するトークンを生成することで表現される。バックトラックは、ゴールから初期状態への解の経路をインクリメンタルに構築するトークンで表現される。サブゴールセッティングは、最終ゴールへの経路に沿って達成すべき中間ステップを明示的に提案することで表現される。 研究者らは、GPT-4o-miniモデルを用いた分類パイプラインを開発し、モデル出力中のこれらのパターンを確実に識別した。
最初の行動が自己改善に与える影響
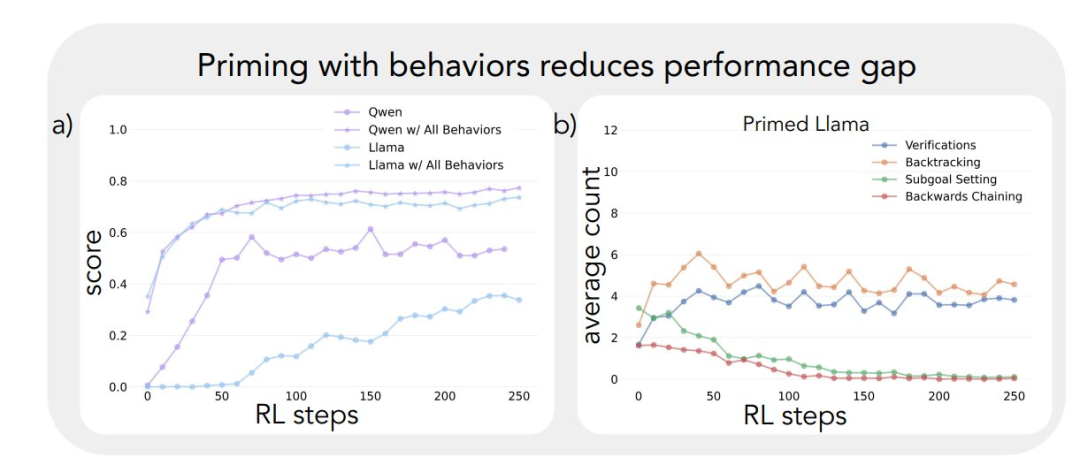
上記の分析フレームワークを最初の実験に適用したところ、重要な洞察が得られた: Qwen-2.5-3Bモデルの性能の大幅な向上は、認知行動、特に検証行動とバックトラック行動の出現と並行して起こる。 一方、Llama-3.2-3Bモデルでは、トレーニング中、これらの行動はほとんど見られなかった。
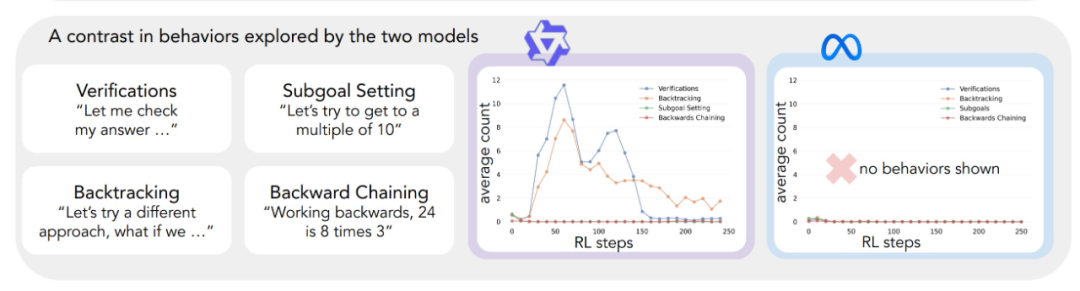
その結果、Qwen-2.5-3Bモデルは、Llama-3.2-3BとLlama-3.1-70Bの2つのLlamaモデルよりも、すべての認知行動の割合が高いことがわかった。2.5-3Bモデルの方がすべての認知行動の割合が高かった。 より大きなLlama-3.1-70Bモデルは、Llama-3.2-3Bモデルよりも一般的にこれらの行動をより頻繁に活性化させたが、この増加にはばらつきがあり、特に回顧的行動については、より大きなモデルでも制限されたままであった。

これらの観察から、2つの重要な洞察が明らかになった:
- 初期戦略における特定の認知行動の存在は、モデルが推論順序を拡張することによって増加したテスト時間の計算を有効に利用するために必要な前提条件かもしれない。
- モデルサイズを大きくすることで、これらの認知行動の文脈的活性化の頻度をある程度向上させることができる。
強化学習は、成功した軌跡の中にすでに存在する行動のみを増幅することができるため、このモデルは極めて重要である。 つまり、このモデルで効果的に学習するためには、これらの認知行動が最初に利用可能であることが前提条件となる。
初期行動への介入:モデル学習を導く
ベースモデルにおける認知行動の重要性を立証した上で、次の疑問は、これらの行動を、的を絞った介入によって人工的に誘発することは可能か、ということである。 研究者たちは、強化学習トレーニングの前に、特定の認知行動を選択的に表示する基本モデルの変種を作成することで、どの行動パターンが効果的な学習に不可欠であるかをより深く理解することができるという仮説を立てた。
この仮説を検証するために、彼らはまず、カウントダウン・ゲームを使った7つの異なるスターター・データセットを設計した。 これらのデータセットのうち5つは、すべての戦略の組み合わせ、バックトラックのみ、バックトラックと検証、バックトラックとサブゴール設定、バックトラックと後方思考という、行動の異なる組み合わせを強調したものである。 これらのデータセットの生成にClaude-3.5-Sonnetモデルを使用したのは、Claude-3.5-Sonnetが正確に指定された行動特性を持つ推論軌跡を生成できるからである。
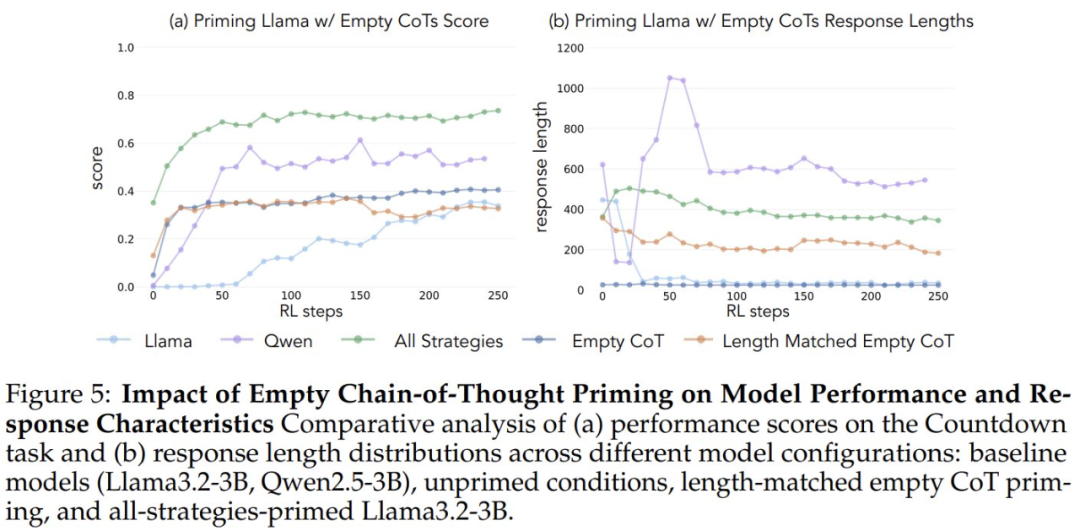
性能の向上が、単なる計算時間の増加ではなく、特定の認知行動によるものであることを検証するために、研究者たちは2つの対照条件も導入した。すなわち、空の「思考の連鎖」と、プレースホルダートークンを連鎖に入力し、データポイントの長さを「すべての戦略の組み合わせ」データセットに一致させる対照条件である。"データセットである。 これらの対照データセットは、観察されたパフォーマンスの向上が、単なる計算時間の増加ではなく、実際に特定の認知行動によるものであることを検証するのに役立った。
さらに、研究者は「完全な戦略の組み合わせ」データセットの変種を作成した。このデータセットには不正解のみが含まれているが、必要な推論パターンは保持されている。 この変種の目的は、認知行動の重要性と解答の正確さの違いを区別することである。
実験の結果、Llama-3とQwen-2.5-3Bの両モデルは、遡及的な行動を含むデータセットで初期化された場合、強化学習トレーニングによって性能が大幅に向上することが示された。 さらに行動分析から 強化学習は、経験的に有用であることが示されている行動を選択的に増幅し、他の行動を抑制する。 例えば、完全戦略組み合わせ条件では、モデルは回顧的行動と検証行動を保持し強化する一方で、後戻り思考とサブゴール設定行動の頻度を減少させる。 しかし、回顧的行動のみと組み合わせた場合、抑制された行動(バックトラックやサブゴール設定など)がトレーニング中ずっと続く。
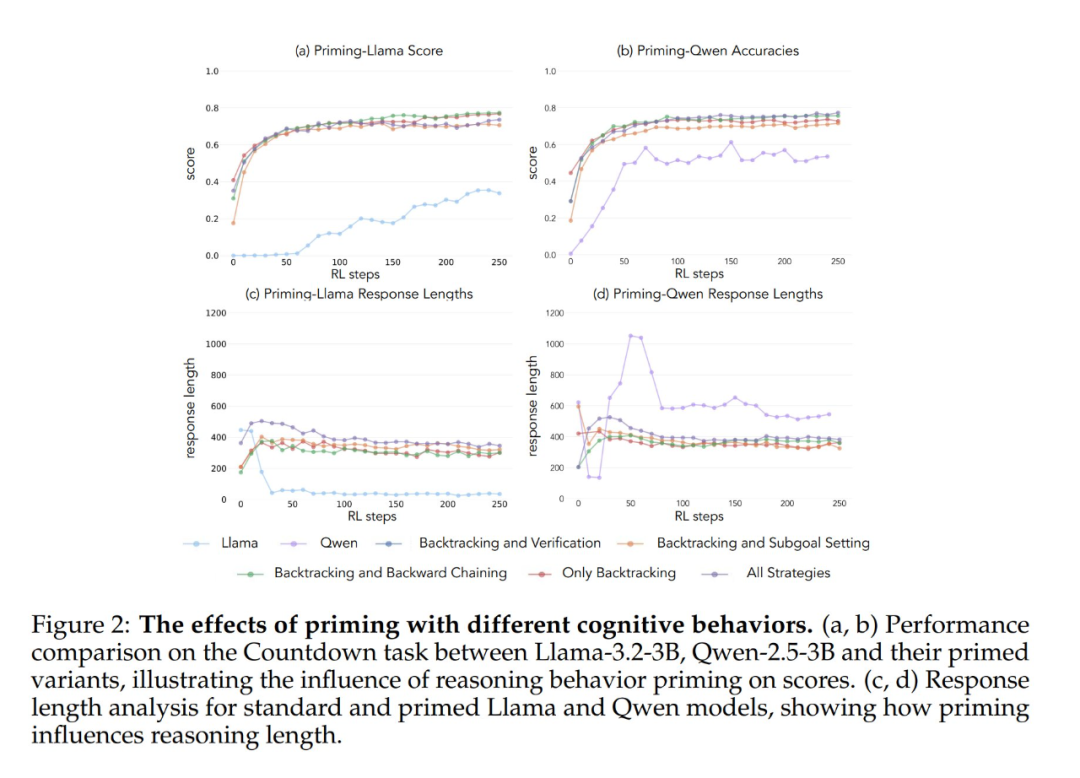
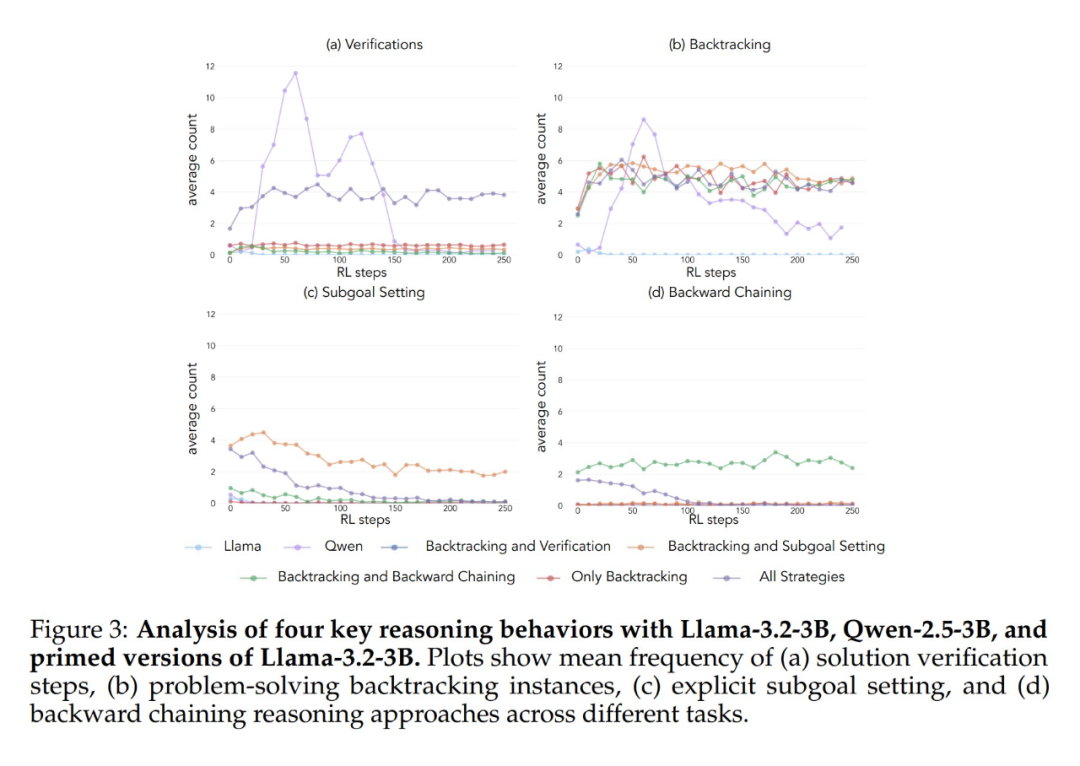
空の思考連鎖を対照条件として開始した場合、どちらのモデルも基本的なLlama-3モデルと同等の結果を示した(精度は約30%-35%)。 このことは、認知行動を含めずに単純に追加トークンを割り当てることは、テスト時間の計算を効率的に使用できないことを示唆している。 Qwen-2.5-3Bモデルは新しい行動パターンを探索しなくなった。 これは、次のことを示すさらなる証拠である。 このような認知行動は、モデルがより長い推論シーケンスを通じて、拡張された計算資源を効率的に利用するために極めて重要である。
さらに驚くべきことに、誤った解で初期化されたが正しい認知行動をとったモデルは、正しい解を含むデータセットで訓練されたモデルとほぼ同じレベルの性能を達成した。 この結果は、次のことを強く示唆している。 強化学習による自己改善を成功させるためには、(正解の獲得よりも)認知行動の存在が重要な要素となる。 このように、比較的弱いモデルからの推論パターンは、より強いモデルを構築するための学習プロセスを効果的に導くことができる。 このことは、次のことを改めて証明している。 認知行動の有無は、結果の正しさよりも重要である。

事前学習データにおける行動選択
これらの実験結果は、モデルの自己改善には特定の認知行動が不可欠であることを示唆している。 しかし、先の研究で初期モデルに特定の行動を誘発するために用いられた方法は、ドメイン固有であり、カウントダウンゲームに依存していた。 これは、最終的な推論の一般化能力に悪影響を及ぼす可能性がある。 では、より一般化された自己改善能力を達成するために、モデルの事前学習データの分布を変更することで、有益な推論行動の頻度を増加させることは可能なのだろうか?
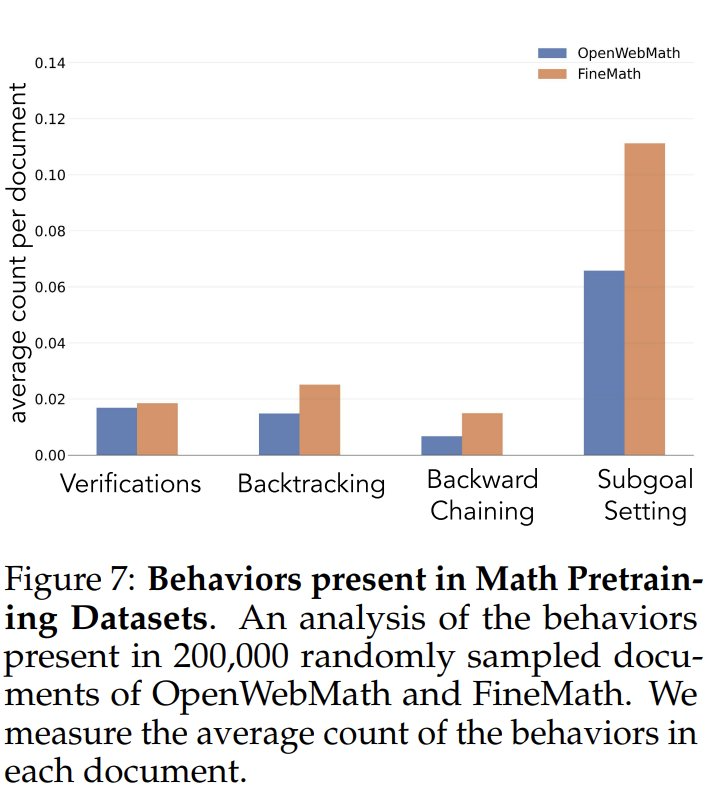
事前学習データにおける認知行動の頻度を調べるために、研究者たちはまず、事前学習データにおける認知行動の自然頻度を分析した。 特に数学的推論のために構築されたOpenWebMathとFineMathデータセットに注目した。 Qwen-2.5-32Bモデルを分類器として使用し、研究者はこれら2つのデータセットから無作為に選んだ20万件の文書を分析し、対象となる認知行動の有無を調べた。 その結果、数学に特化したコーパスであっても、バックトラックや検証といった認知行動の頻度は低いままであることがわかった。 これは、標準的な事前学習プロセスでは、これらの重要な行動パターンに触れる機会が限られていることを示唆している。
人為的に認知行動に触れる機会を増やすことで、モデルの自己改善能力が高まるかどうかを検証するため、研究者らはOpenWebMathデータセットから、目標とする連続的な事前学習データセットを開発した。 研究チームはまず、Qwen-2.5-32Bモデルを分類器として使用し、事前学習コーパスの数学文書を分析して、対象となる推論行動の存在を特定した。 これに基づいて、2つの比較データセットを作成した。1つは認知行動が豊富なデータセット、もう1つは認知行動がほとんどない対照データセットである。 そして、Qwen-2.5-32Bモデルを使用して、両データセットの各文書を、ソース文書における認知行動の自然な有無を保持しながら、構造化された質問と回答の形式に書き換えた。 このアプローチにより、研究者は事前学習時に数学的内容の形式と量を制御しながら、推論行動の影響を効果的に分離することができた。
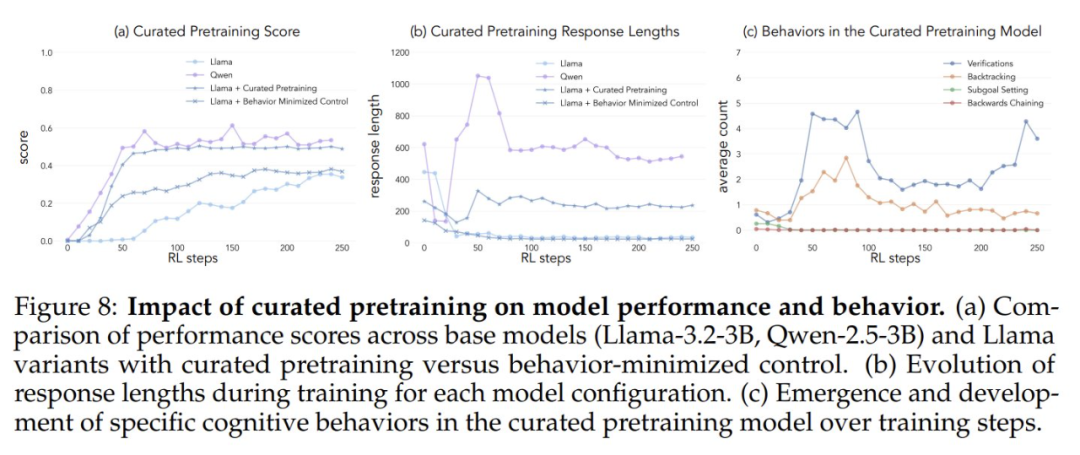
これらのデータセットでLlama-3.2-3Bモデルを事前学習し、強化学習を適用したところ、研究者たちは次のように観察した:
- 行動リッチな事前訓練済みモデルは、最終的にQwen-2.5-3Bモデルに匹敵するレベルの性能を達成し、コントロールモデルの性能向上は比較的限られている。
- 訓練後のモデルの行動分析によると、事前訓練モデルの行動強化バリアントは訓練過程を通じて推論行動の高い活性化を維持したが、対照モデルは基本的なLlama-3モデルと同様の行動パターンを示した。
これらの実験結果は、次のことを強く示唆している。 事前学習データの的を絞った修正により、強化学習を通じて効果的な自己改善に必要な主要な認知行動を生成することに成功する。 本研究は、大規模言語モデルの自己改善能力を理解し、改善するための新しいアイデアと方法を提供する。 詳細は原著論文を参照されたい。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事




コメントはありません