また、7B、13B、65Bは何を表しているのでしょうか?

近年、大規模モデルの学習や推論に携わる多くの人々が、モデルのパラメータ数とモデルサイズの関係について議論している。例えば、有名なalpacaシリーズのLLaMAラージモデルには、LLaMA-7B、LLaMA-13B、LLaMA-33B、LLaMA-65Bというパラメータサイズの異なる4つのバージョンがあります。
ここでの "B "は "Billion "の略で、億を意味する。したがって、最小のLLaMA-7Bモデルには約70億のパラメータが含まれ、最大のLLaMA-65Bモデルには約650億のパラメータが含まれる。
では、これらのパラメータ数はどのように計算されているのでしょうか?また、100GBのモデルファイルに対応する大規模モデルのパラメータ数は、おおよそどの程度なのでしょうか?数十億、数百億、数千億、それとも数兆?本稿では、これらの疑問に徹底的に答えていく。
I. 大きなモデルパラメータ量の計算方法
ここでは、ビッグモデルのインフラであるトランスフォーマーを例にとり、パラメータ数の算出プロセスを詳細に分析する。
スタンダード 変圧器 このモデルはL個の同じレイヤーを積み重ねたもので、各レイヤーには2つの主要部分、すなわち自己注意レイヤー(SAL)とフィードフォワード・ニューラルネットワーク・レイヤー(MLP)が含まれている。
1.セルフ・アテンションズ
自己吸着機構は変圧器のコアです。自己吸着でもマルチヘッド自己吸着(MHA)でも、コアパラメータ量の計算は同じです。
自己注意層では、まず入力シーケンスが3つのベクトルにマッピングされる。クエリーベクトル(Query, Q)、キーベクトル(Key, K)、バリューベクトル(Value, V)である。MHAでは、これら3つのベクトルはさらに複数のヘッドに分割され、それぞれのヘッドが入力シーケンスの異なる部分に注目する。

- シングルヘッドの自己アテンション。 Q, K, Vは、それぞれ[h, h]の形状の重み行列によって線形変換され、ここでhは隠れ層の次元である。したがって、Q, K, Vのパラメータの総数は3h²である。さらに、同じ重み行列形状[h, h]を持つ出力用の線形変換層があります。したがって、単頭自己注意のパラメータの総数は 4h² (バイアス用語は無視)。
- マルチヘッデッド・アテンション(MHA)。 各ヘッドは[h, h_head]の形のQ, K, V重み行列を持つ. したがって,各ヘッドのQ, K, V重み行列のパラメトリック量は3 * h * h_head = 3h²/n_headである.したがって、各ヘッドのQ, K, V重み行列のパラメトリック量は、3 * h * h_head = 3h²/n_head となります。 n_headヘッドのパラメトリック量の総数は、n_head * (3h²/n_head) = 3h² となります。最後に、出力層の線形変換重み行列の形状は、[h, h]です。したがって、MHAのパラメータの総数は 4h² (バイアス用語は無視)。
したがって、自己アテンション層のパラメーターの数は、単一ヘッドでも複数ヘッドでも、4h²と近似できる。
2.フィードフォワードニューラルネットワーク層(MLP)
MLP層は2つの線形層からなる。最初の線形層は隠れ層の次元hを4hに拡張し、2番目の線形層は4hからhに戻す。

- 最初の線形層の重み行列は[h, 4h]の形状を持ち、パラメータの数は4h²である。
- 第2の線形層は、同じパラメトリック量4h²を持つ形状[4h, h]の重み行列を持つ。
したがって、MLP層のパラメータ総数は8h²(バイアス項は無視)となります。
3.レイヤーの正規化
各 Self-Attention 層と MLP 層の後、そして Transformer 出力の最後の層の後には、通常 Layer Normalisation 操作があります。各レイヤー正規化レイヤーには、2つの学習可能なパラメータが含まれています:
- スケーリング・パラメーター(ガンマ):形状は[h]。
- 翻訳パラメータ(ベータ):形状は[h]。
各Transformer層は2つのLayer Normalization(それぞれSelf-AttentionとMLPの後)と出力層の後に1つのLayer Normalizationを持つので、L層TransformerのLayer Normalizationパラメータの総数は(2L + 1) * 2hとなる。
4.エンベディング
入力テキストはまず、単語埋め込み層を通して単語ベクトルに変換される必要がある。単語リストのサイズをV、単語ベクトルの次元をhとすると、単語埋め込み層のパラメータ数はVhとなる。
5.出力層
出力層の重み行列は通常、単語埋め込み層と共有され(Weight Tying)、パラメータ数を減らし、性能を向上させる可能性がある。従って、ウェイト共有が使用される場合、出力層は通常、追加のパラメータ数を導入しない。共有しない場合、パラメータ数はVhとなる。
6.位置エンコーディング
位置エンコーディングは、入力シーケンス内の単語の位置に関する情報をモデルに提供するために使用される。
- トレーニング可能なポジションコード 学習可能な位置エンコーディングが使用される場合、パラメータの数はN * hであり、Nは最大シーケンス長である。例えば、ChatGPTの最大配列長は4kである。
- 相対的ポジションコード(RoPEやALiBiなど)。 これらの方法では、学習可能なパラメータは導入されない。
位置エンコードされたパラメータの数は比較的少ないため、通常、パラメータ総数の計算では無視できる。
7.参加者総数の算出
まとめると、Lレイヤートランスフォーマーモデルの総パラメーター数は次のようになる:
パラメータ総数 = L * (自己アテンションパラメータ + MLPパラメータ + LayerNormパラメータ * 2) + 埋め込みパラメータ + 出力層パラメータ + LayerNormパラメータ(出力層以降)
パラメータ総数≒L * (4h² + 8h² + 4h) + Vh + (オプションのVh) + 2h
パラメータの総数 ≈ L * (12h² + 4h) + Vh + 2h (出力層が単語埋め込み層と重みを共有すると仮定)
隠れ次元hが大きい場合、一次項4hと2hは無視でき、モデルパラメータの数はさらに次のように近似できる:
パラメータの総数≈ 12Lh² + Vh
8.LLaMA参加者数の見積もり
以下の表は、LLaMAのさまざまなバージョンの主要パラメータと、そのパラメータ数の推定値を示している:
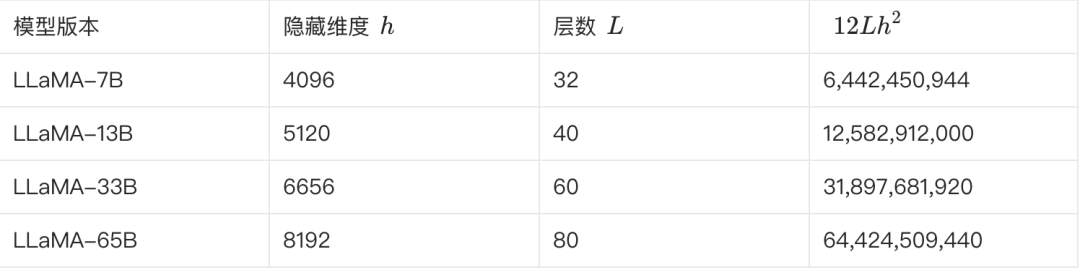
**上記の式で確認できる。LLaMA-7Bを例にとると、表によれば、L=32、h=4096、V=32000.**である。
推定パラメータ数≈ 12 * 32 * 4096² + 32000 * 4096≈ 6.55B
この見積もりは6.7Bに近い。他のいくつかのバージョンは、この方法で見積もり、検証することができる。
II.大きなモデルのパラメトリック量をモデルサイズに変換する
パラメータ数の計算方法を理解した上で、次にパラメータ数とモデルサイズがどのように変換されるかを見てみよう。
LLaMA-7Bは約70億人が参加している。
- 理論的な計算。 各パラメータがFP32(4バイトを占有する32ビット浮動小数点数)フォーマットで格納される場合、LLaMA-7Bの理論上のサイズは、7B * 4バイト = 28GBとなる。
- 物理的なストレージ。 ストレージスペースを節約し、計算効率を向上させるため、モデルウェイトは通常、FP16(2バイトを占有する16ビット浮動小数点数)やBF16のような低精度フォーマットで保存される。 FP16ストレージを使用する場合、LLaMA-7Bのサイズは理論上:7B * 2バイト = 14GBとなる。
- その他の要因 ウェイトパラメータに加えて、モデルファイルには、オプティマイザーの状態(例えば、Adamオプティマイザーの運動量や分散)、ワードリスト、モデル構成などに関する情報が含まれることがあり、これらはさらに記憶領域を占有する。さらに、一部のパラメータ(レイヤー正規化のガンマやベータなど)はFP32形式で保存されることがあります。
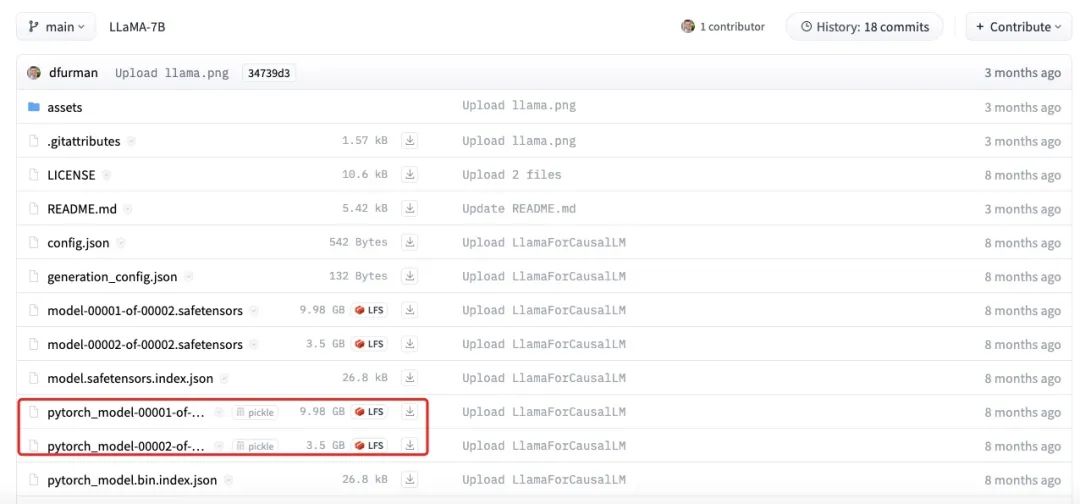
上の図は、LLaMA-7Bモデルファイルの実際のサイズを示している。各部分の合計サイズは約13.5GBであり、我々の推定値である14GBに近いことがわかる。このわずかな差は、丸め誤差、バイアス・パラメーター、またはいくつかのパラメーターがまだFP32を使って保存されていることに起因している可能性がある。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません