
OpenAI-o1の大規模モデルによる複雑な推論

2022年、オープンAIはChatGPTをリリースし、世界で最も早く数億ユーザーを突破したAPPとなり、当時人々は本物のAIに近づいたと考えた。しかし、人々はすぐにChatGPTが会話をし、詩や記事を書くことさえできることを発見したが、有名な「イチゴ」に複数の「r」の茎が入っているような単純なロジックではまだ不満足だった。
それから2年、OpenAIはo1モデルを発表し、その強力な論理推論能力とOpenAIの強力な技術隠蔽能力で、その背後にある方法論について熱い議論を巻き起こしている。今回は、o1モデルの技術に関する推測を手掛かりに、関連記事をいくつか調べ、大規模モデルの複雑な推論能力の発展を見てみたい。
01 背景
思考の連鎖(Chain of Thought、CoT)とは、認知心理学や教育における概念で、人が問題を解決したり意思決定をしたりする際に、思考が段階的に発展していくプロセスを説明するものである。単純に質問から答えにジャンプするのではなく、そのプロセスには複数の段階があり、それぞれの段階には、過去の結論の収集、分析、評価、修正が含まれる。こうすることで、複雑な問題により体系的に対処し、合理的な解決策を構築することができる。
教師ありの微調整教師あり学習(supervised learning)は、機械学習の分野で最も一般的なモデル学習の形態であり、データを正確に分類したり結果を予測したりするために、ラベル付けされたデータセットを使用してモデルを学習させる。入力データがモデルに入ってくると、教師あり学習はモデルが適切な適合を示すまでモデルの重みを調整する。
Supervised Fine-Tune、略してSFTとは、教師あり学習のことで、既存のベースモデルの上に、特定のタスクに特化したデータセットを用いてモデルを訓練する。
強化学習強化学習、略してRLは、教師あり学習、教師なし学習と並ぶ、3つの基本的な機械学習パラダイムの1つである。強化学習は、探索(未知)と利用(既知)のバランスを見つけることに焦点を当て、モデルが長期的なリターンを最大化することを目標に、適切な行動を学習することを可能にする。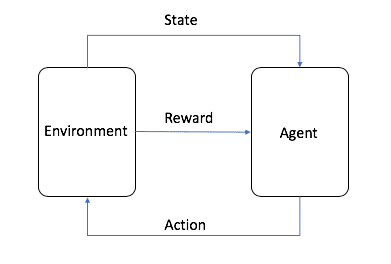
画像はAWSのものですが、図のように、強化学習では、Agentが最終的な学習対象であり、設定された環境(Environment)と相互作用して、Reward(報酬)と状態遷移を発生させ、AgentはそのRewardに基づいて学習し、より良い次のActionを選択する、というサイクルが学習プロセスです。このサイクルが強化学習の学習プロセスです。
LLMの学習プロセスにおいて、RLは重要な役割を果たしており、学習前の段階はRLHFの助けを借りて調整されることが業界のコンセンサスとなっている。LLMの強化学習では、通常、LLMの出力に報酬を与える環境をシミュレートする別のモデルが必要であり、これは報酬モデル、略してRMと呼ばれる。
ここでは、Actorモデル、Criticモデル、Rewardモデルという複数のモデルを用意する。上記の標準的なRL学習フレームワークと同様に、ActorとCriticはAgentを形成し、RewardはRL学習プロセスにおいてEnvironmentとして学習される。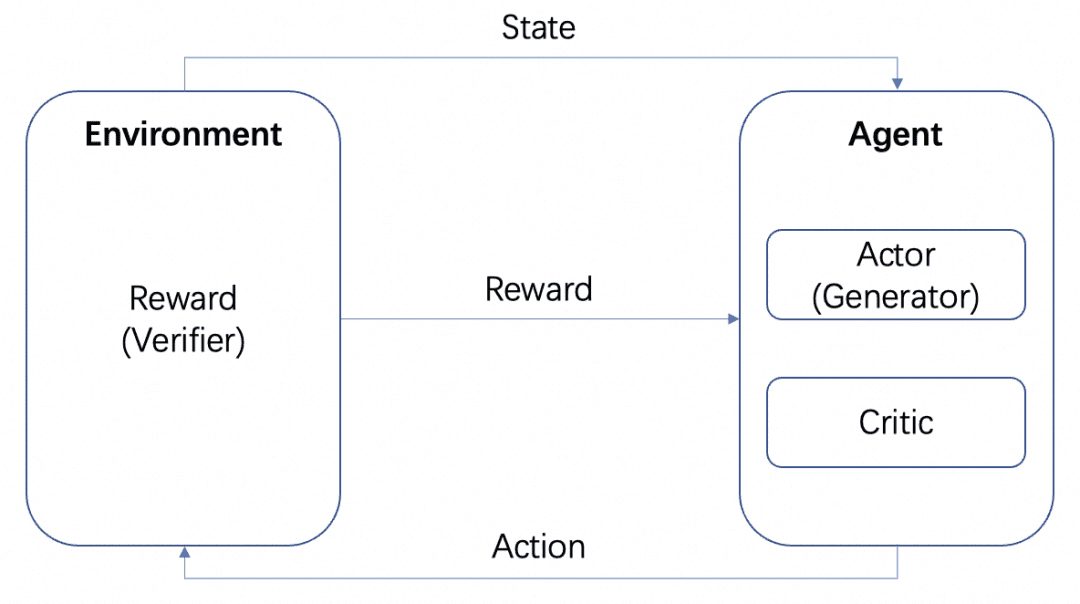
ActorモデルはGeneratorで、RewardモデルはGeneratorの生成品質を測定するためのVerifierです。これはOpenAIのLet's verify step by stepという論文で言及されているGenerator-Verifier構造です。これがOpenAIの論文Let's verify step by stepで言及されているGenerator-Verifier構造です。
そして報酬モデルは、フィードバックの詳細さによって分類することができる:
-プロセスベースの報酬モデルPRM:PRMは、LLMの中間結果に基づいてフィードバックを与える。
-成果ベースの報酬モデルORM:ORMは、最終的な結果が出た後にのみフィードバックを与える。
以下、具体的なシナリオでこの2つのコンセプトを取り上げる。
モンテカルロ・ツリー・サーチ モンテカルロ・ツリー・サーチ(MCTS)は、ツリー・サーチ・アルゴリズムであり、各ステップにおいて、複数の行動が試みられ、その行動の将来起こりうるペイオフが予測され、より報酬の高い行動のいくつかを選択的に探索することに重点を置いている。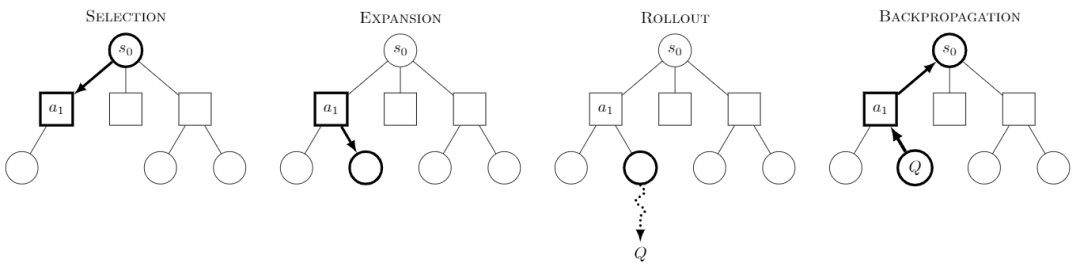
画像はWikipediaより各クエストは4つのステップに分かれていると言われている:
-選択:ノードを選択する
-拡張:このノードから新しいノードを生成して探索する。
-ロールアウト:この新しいノードに沿ってシミュレーションを実行し、結果を生成する。
-バックプロパゲーション:シミュレーションの結果を後方に伝搬し、パス上のノードを更新する。
探索を続けることで、木が得られ、各ノードが探索の可能性のある結果を持ち、この木の中で探索することで、最良のパスや結果を得ることができる。
RLにMCTSを使用することで、AlphaZeroのような、学習可能なモデルを使用してSelectionとRolloutステップを実行する有名なモデルが生まれた。AlphaZeroのアプローチは、学習可能なモデルを用いてSelectionとRolloutステップを実行することで、MCTSの大きな探索空間とシミュレーションコストを削減し、効率的に最適解を得ることです。例えば、Policy Networkを用いて効率的に次の可能なステップを探索し、Rolloutシミュレーションの代わりにValue Networkを用いて各ステップの値を決定します。
o1の多段階推論能力 o1モデルといえば、その驚異的な多段階推論能力について語らなければならない。OpenAIのウェブサイトでは、パスワード、暗号、数学、クロスワードパズルなど、その多段階推論能力を示すいくつかの例を紹介している。パスワード」に関連する例では、解読結果は「THERE A THREE R'S IN STRAWBERRY」であり、これはかつて存在した「パスワード」の結果でもある。 チャットGPT 対応する推理力。
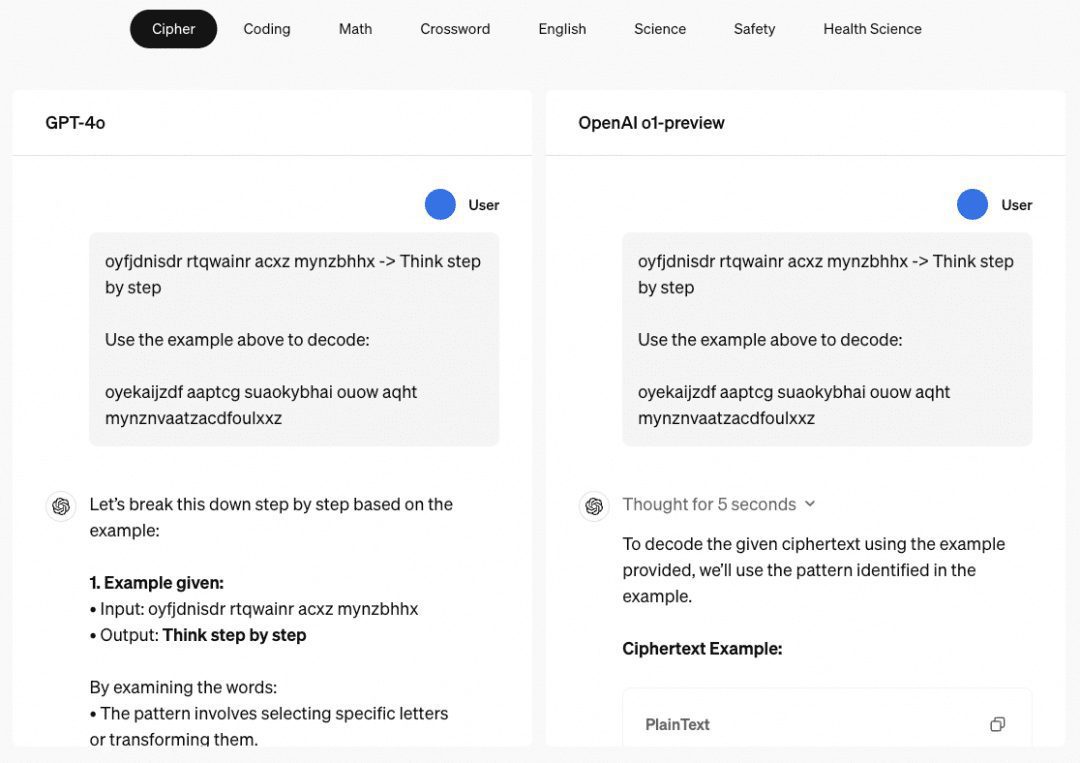
そこで我々は、主にこのような立場で数多くの論文を調査し、以下のように照合・要約した。
02 キュー・ワード・エンジニアリング
モデル推論を改善するための手がかり語工学を紹介する前に、Few-Shot Learningとは何かを理解する必要がある。現在、AIの学習には一般的に大量の例データが必要だが、例データがほとんどない状態での学習はFew-Shot、あるいは例データがまったく与えられない場合はZero-Shotと呼ばれる。
論文「Chain of Thought Prompting Elicits Reasoning in Large Language Models」は、モデルの数学的推論を強化するためのFew-Shotアプローチを提案している:
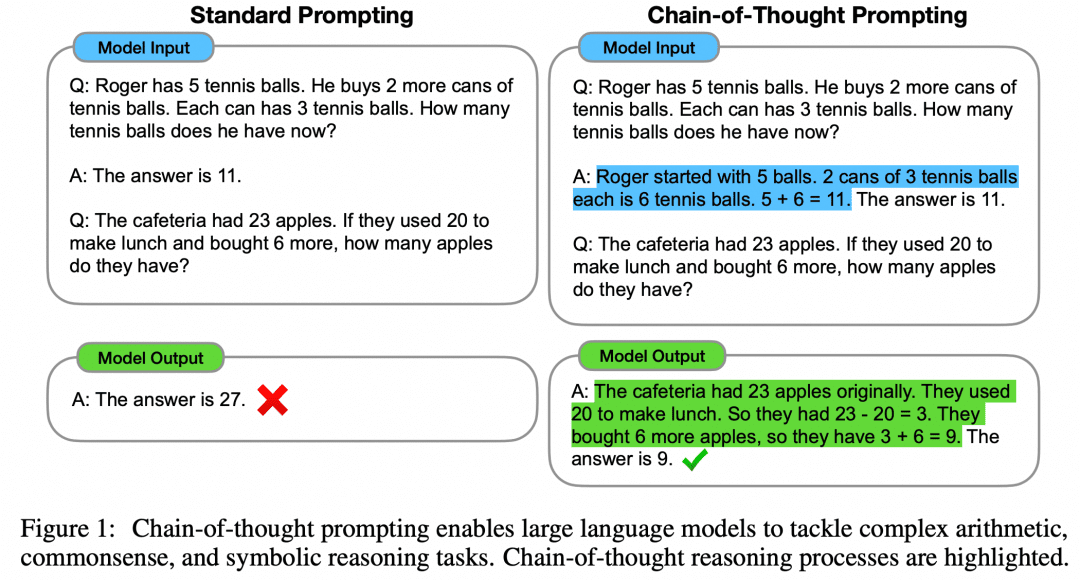
図に示すように、左側は入力LLMのプロンプトでLLMに学習させるサンプルを与えるもので、Few-Shot Learningであるが、その効果はまだ満足できるものではない。本論文では、このFew-Shotパラダイムを、右側のCoTとともに提案している。つまり、右側のFew-Shotでは、例題の質問と答えだけでなく、その中間過程と結果も与えられる。著者らは、CoTを用いてこのように構成されたFew-Shot Promptがモデルの推論を改善することを発見した。
モデル自体が改善され、さらに研究が進むにつれて、「大規模言語モデルはゼロショット推論者である」という記事では、ゼロショットがCoTを使ってモデルの能力を高めることもできることがさらに明らかにされている:

わざわざCoTの中間プロセスを組み立てたり、フューショットの例を組み立てたりしなくても、「ステップ・バイ・ステップで考えよう」というだけで、LLMを充実させることができる。当たり前のことのように聞こえる。このプロンプトは後にOpenAIによって「ステップ・バイ・ステップで検証しよう」と変更され、今ではo1を理解しようとする誰もが繰り返し読む中心的な論文となっている。
もちろん、キューワードエンジニアリングにCoTを構築することだけが、o1がこれほど強力である理由にはなり得ないが、論理を段階的に進めるCoTは、大規模なモデルにおける推論を補強するための主要な方向性となっている。
03 CoT + スーパーバイズド・ファインチューン
STaR: Bootstrapping Reasoning With Reasoning」はその初期の試みである。下の画像はその論文からのものである: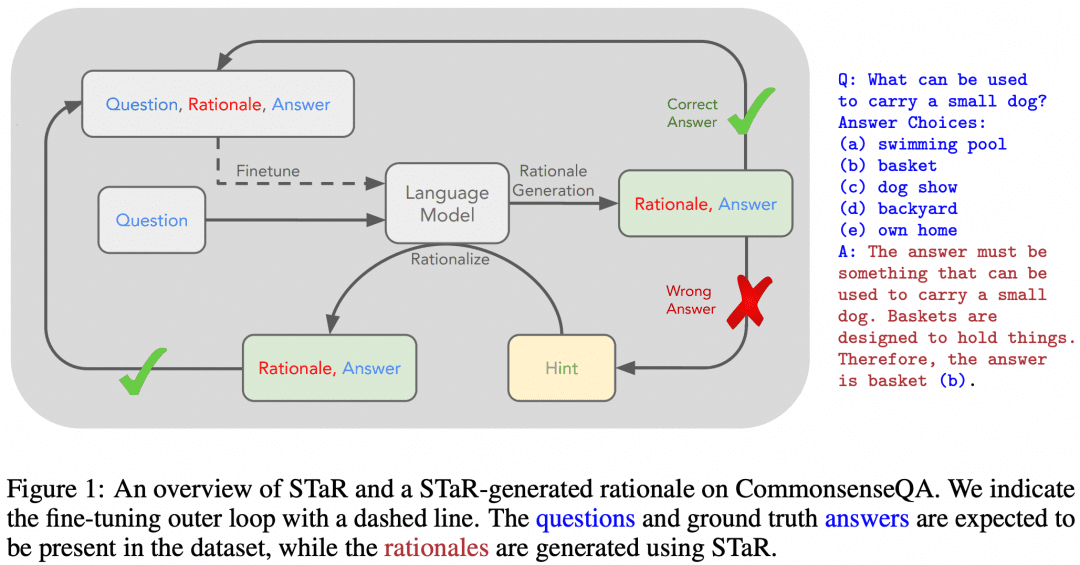
この論文のアイデアはこうだ。まず、前述のキュー・ワード・エンジニアリングのアプローチを使って、モデルにCoTを試させ、データセットを推論させる:
正解が得られた場合、モデルによって生成された対応するCoTを高品質なCoTとみなし、そのような高品質な「質問-CoT-回答」サンプルを集めて新しいデータセットを取得し、このデータセットを使ってLLMをSFTし、ループを繰り返すことで、より推論能力の高いLLMを得ることができる。LLM;
-LLMがいつも間違えて答えてしまう問題がある場合、LLMに直接 "Question+Answer "を表示させ、問題から答えまでのCoTを生成させれば、答えがわかっている場合、LLMが生成したCoTは正しいと考えることができます。Question-CoT-Answer" サンプルのこの部分もトレーニングに使うことができる。
例えば、LLMはしばしば「プロセスは間違っているが結果は正しい」あるいは「プロセスは正しいが結果は間違っている」ことがあり、これは我々がトレーニングに使用したサンプルがそれほど質が高くないことを意味する。これは、我々がトレーニングに使用したサンプルはそれほど質が高くないことを意味する。では、どうすればより正しい推論プロセスを得ることができるのだろうか?
04 モンテカルロ木探索
CoTは質問から答えまでの論理を中間的な思考プロセスの後に中間的な思考プロセスに分解することを上で学んだが、MCTSは次の推論のステップのための最良の思考ステップ、ひいては最良の推論思考の連鎖を探索するために使用できるのだろうか?当然、そうである。
Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solversは、rStarと呼ばれるこのようなMCTSアルゴリズムを考案し、プロジェクトをGitHubにオープンソース化した。下の画像はその論文からのものだが、上のMCTSの画像とどこか似ていないだろうか?
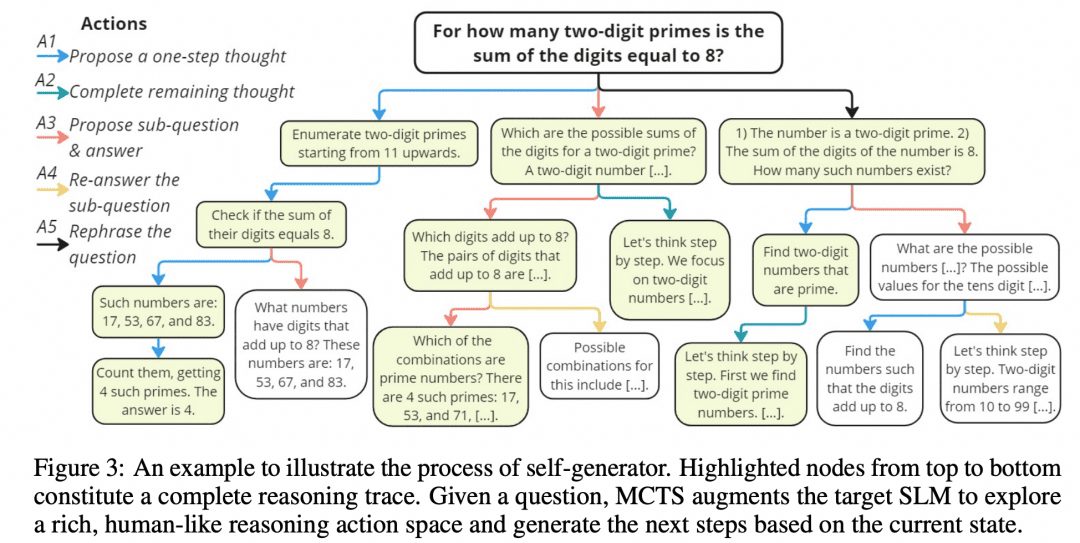
上の図に示すように、研究者たちはCoTの中間ステップを5種類のノードに分けた:
1.推論における次のステップの生成
2.後続のすべての推論を生成する
3.小質問と回答を作成する
4.小質問の再回答
5.再構成の問題
そして、MCTSを使って次の思考ステップのノードを決定する。思考のノードに次ぐノードによってリンクされたパスがCoTである。私たちは単純に、最終的に得られた結果をすべて取り出して投票する。
もちろん、それだけではなく、前述したように、各ステップにおけるノードの正しさや推論の正しさを測定できるようにする必要があり、研究者たちは次のような方法を考案した:
-識別フィルタリング:元の推論経路が得られた後、その一部をランダムにマスクし、別のモデルを出力に使用する。元のジェネレータと同じ結果が得られた場合、元の推論経路は信頼できる。
-解答の正しさ: すべての最終解答が集められ、すべての解答に対する特定の解答の割合が解答スコアとなる。
-プロセスの正しさ:パスの各推論ノードに対して、多数のタイプ2ノ ードが並列に生成され、多数の1ステップの最終結果が生成され、これらの 結果のうち、現在のパスの最終結果である割合が、その推論ノードの プロセススコアとみなされる。3つの部分からなる方策は最適経路を導き、最適経路の最終結果はMCTSの結果とみなされる。
05 ジェネレーター+ベリファイア
思考プロセスをツリーに整理して探索することができる上記のMCTSに加えて、これを行う方法は他にもある。例えば強化学習だ。強化学習の入門書をもう一度見てみよう: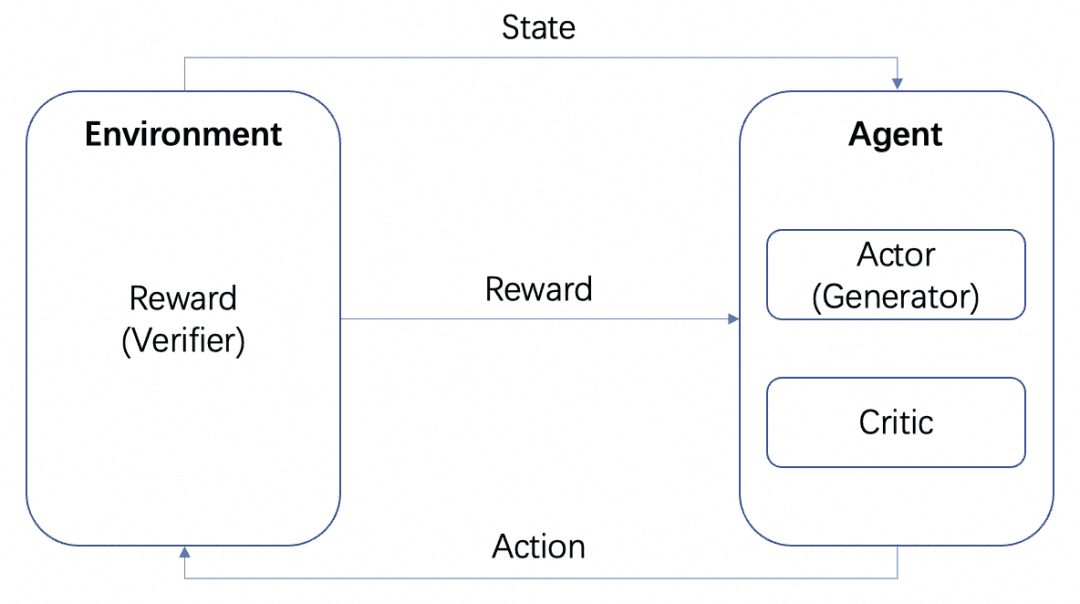
LLMをActor、問題に対して訓練された別のRMをEnvironment、そして暗黙のCriticとすると、強化学習のループは次のようになる:Actorは問題に対する結果を生成し、RMはその結果の正しさを検証してAgentにフィードバックし、ActorとCriticはRewardに従って訓練する。ActorとCriticはRewardに基づいて訓練される。エージェントのタスクは結果を生成することであるため、エージェントをGeneratorと呼び、RMのタスクは結果を検証することであるため、RMをVerifierと呼ぶ。
考えてみれば、Agentの中のActorとCriticの関係は、AlphaZeroが使っているPolicyとValueのネットワークとよく似ているのではないだろうか?PolicyとValueのネットワークがActorとCriticのフレームワークにフィットしているのも事実です。
ここで、強化学習プロセスには、Actor、Critic、RMの3つのネットワークが含まれることをまとめる。ボードゲームでは、勝敗はゲーム終了時にしか分からないし、RMが与えるRewardは少なすぎるので、Actor-Criticの枠組みを維持したまま、より良い解を得るためにMCTSを行う。LLMデプロイメントでは、訓練されたRMがタイムリーなフィードバックを提供できるので、デプロイメント時にActorとRMをGenerator-Verifierフレームワークに自然に組み合わせることができる。
OpenAIはGPT3の時代からこの方向に取り組んできた(ChatGPTはGPT-3.5モデルに基づいている)。彼らが出した解決策は、Training Verifiers to Solve Math Word Problemsという論文です。下の画像はその論文からのものです:
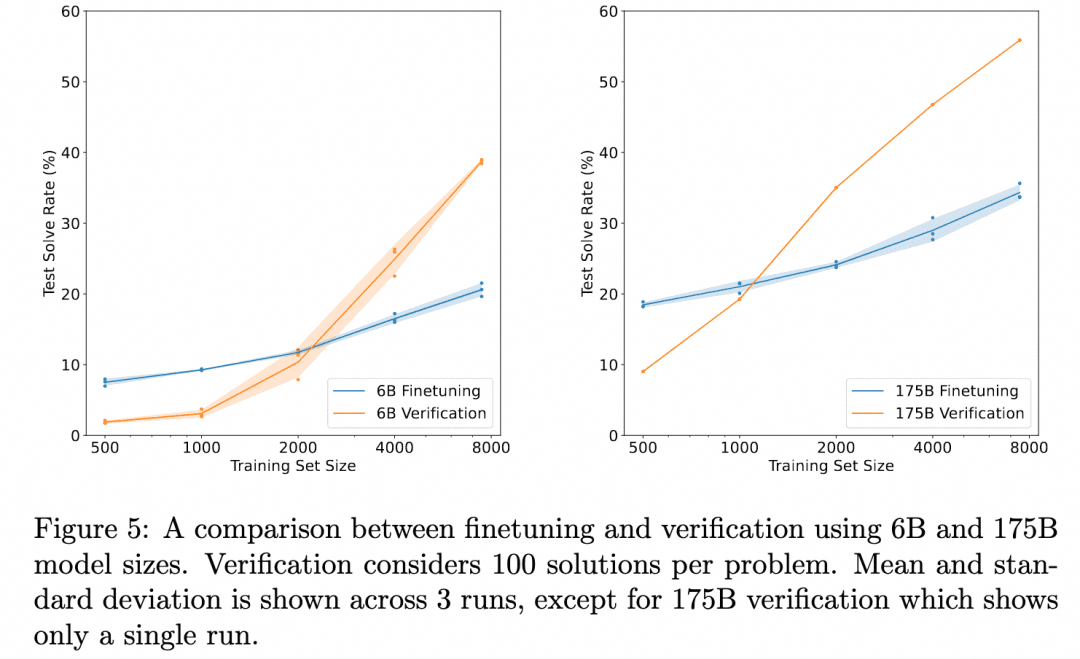
上のグラフは、「ジェネレータを微調整しただけで得られる結果の正しさ」と、「ベリファイアを微調整し、ジェネレータが生成した複数の結果を評価し、より評価の高い結果を選択した結果の正しさ」を比較したものである。これは検証器の有効性を示している。
なぜなら、ここでのタスクは「結果を得るための推論」だからである。したがって、使用されるジェネレーターは中間推論プロセスを生成せず、結果を直接生成する。検証者もまた、強化学習のセクションで述べたORM(Outcome Based Reward Model)であり、ジェネレーターの結果に基づいてスコアを生成する役割を果たす。ORMの検証は、単純な微調整よりも最終的に良い結果をもたらすという発見だけである。
そこでOpenAIチームはさらに一歩踏み込み、Generatorに結果を直接出力させず、ステップバイステップの推論を行わせる一方、PRM(Process-based Reward Model)をVerifierとして訓練し、Generatorの推論プロセスの各ステップに対してスコアを出す役割を持たせた。このようにGeneratorの推論プロセスの正しさを追求した結果が、最も正しい可能性が高いと考えている。
これが前述したLet's verify step by stepである。この研究では、PRMとORMを検証器として同じGeneratorを検索して生成された推論結果を比較し(この時点で、彼らのGeneratorはすでにGPT-4であった)、検証器としてのPRMがより正確な結果を検索することを証明した。下図はその論文からの引用である:
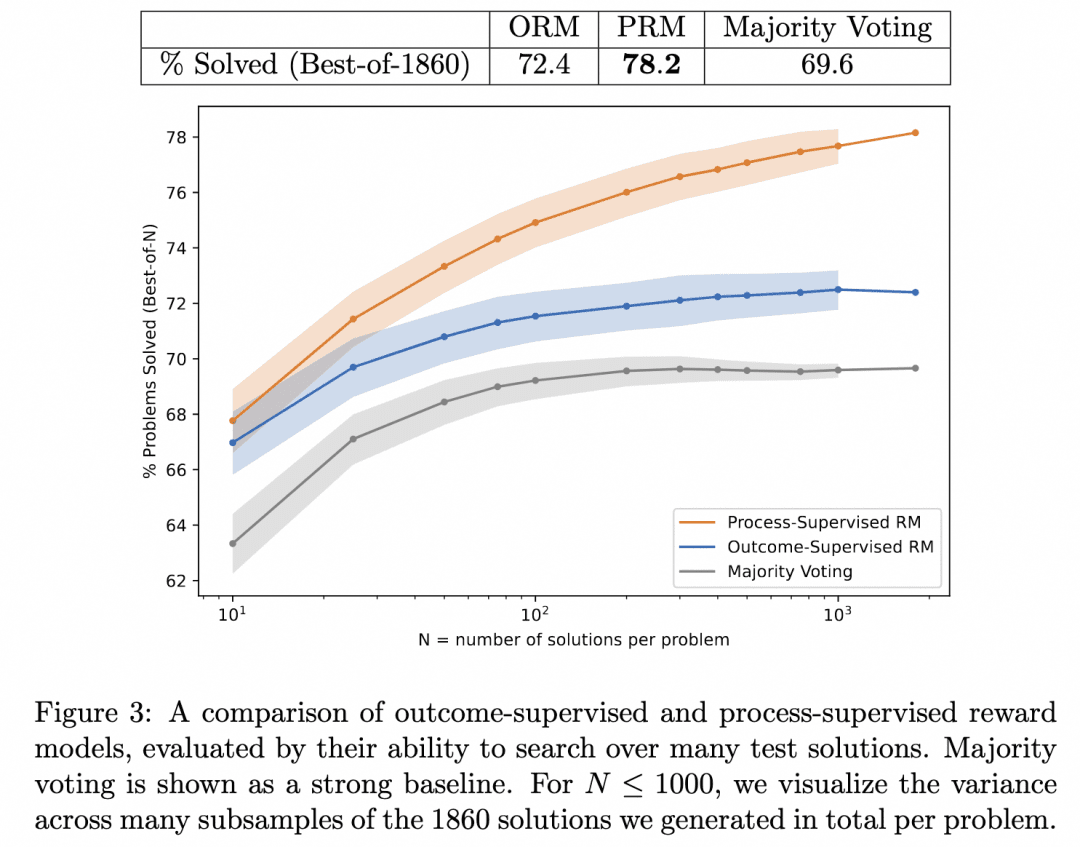
上の図は、同じ段階的推論ジェネレーターでも、ORMを検証器として使って結果のベストアンサーを選ぶことは有効だが、PRMを検証器として使ってプロセスのベストアンサーを選ぶ方が正しい可能性が高いという結果を示している!
これが、私たちが探しているo1を支える技術なのだろうか?現時点では、これがその背後にあるコア技術のひとつであると推測するしかない。その理由は以下の通りである:
1、この論文はo1のリリースから比較的遠く、OpenAIの研究者がこの方向をより深く掘り下げるには1年という時間は十分です。PRMの妥当性から、1年という時間は他の方向性に適応するのに十分な時間でもありますが、それでも彼らは方向転換するのではなく、より深く進んでいると考えています。
2.この論文は、検証機としてのPRMの有効性を実証しており、次のステップは、より良い結果を出すために、強力な検証機でジェネレータを改良することであることは明らかです。しかし、この論文ではそこまで踏み込んでいないため、OpenAIが試みたに違いないと信じるに足る理由があり、その結果がo1であったかどうかは不明です。
この推測はさておき、Verifierを検索に利用する他の方法を探ってみよう。今年8月にGoogle DeepMindが発表した「Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters(LLMのテスト時間計算を最適にスケーリングすることは、モデル・パラメーターをスケーリングするよりも効果的である)」という論文では、さらに詳しい研究が行われている。この論文は、o1の背後にある原理と同様の技術的な路線を示していると多くの人が見ている。下の画像はその論文から:
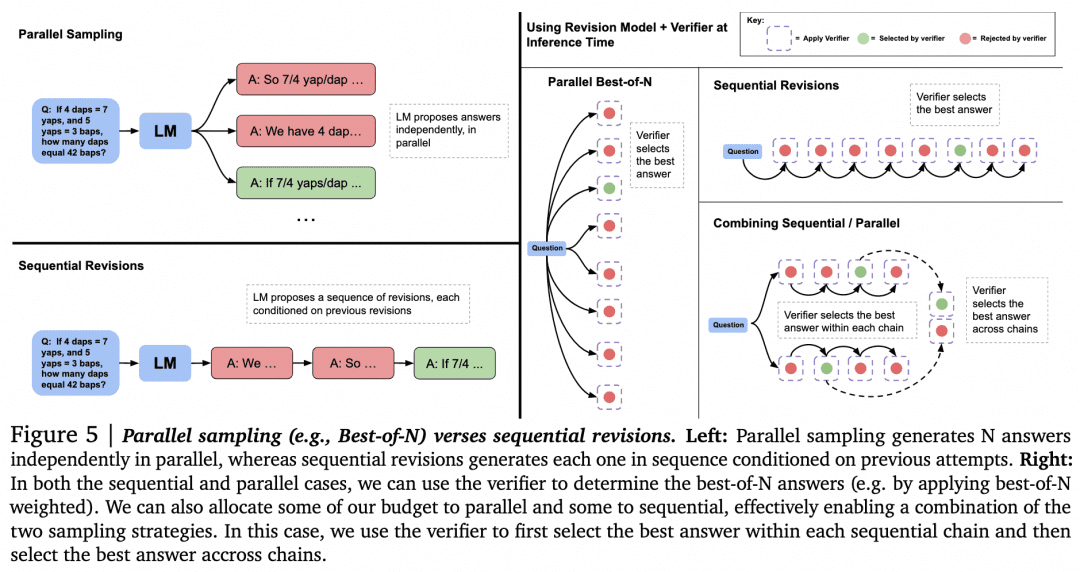
さて、ジェネレーターとベリファイアが揃ったところで、最良の結果を得るために、どのようにこれらを連携させればよいのだろうか。その1つの方法は、上述したように、ジェネレーターが並列にサンプリングして複数の結果を得、ベリファイアがそれらを評価して最も高いスコアを選択することです。これが上図左の「並列サンプリング+Best-of-N」アプローチである。しかし、他のアプローチも当然あります:
-複数の結果を生成する場合、複数の結果を並行してサンプリングすることに加えて、ジェネレーターが結果を生成し、その結果自体をチェックして修正することで、互いに並列でなくなる一連の答えを得ることも可能である。
-ベリファイアが選択する場合、Best-of-Nに代わるものがあり得る。論文の次の図に示すとおりである:
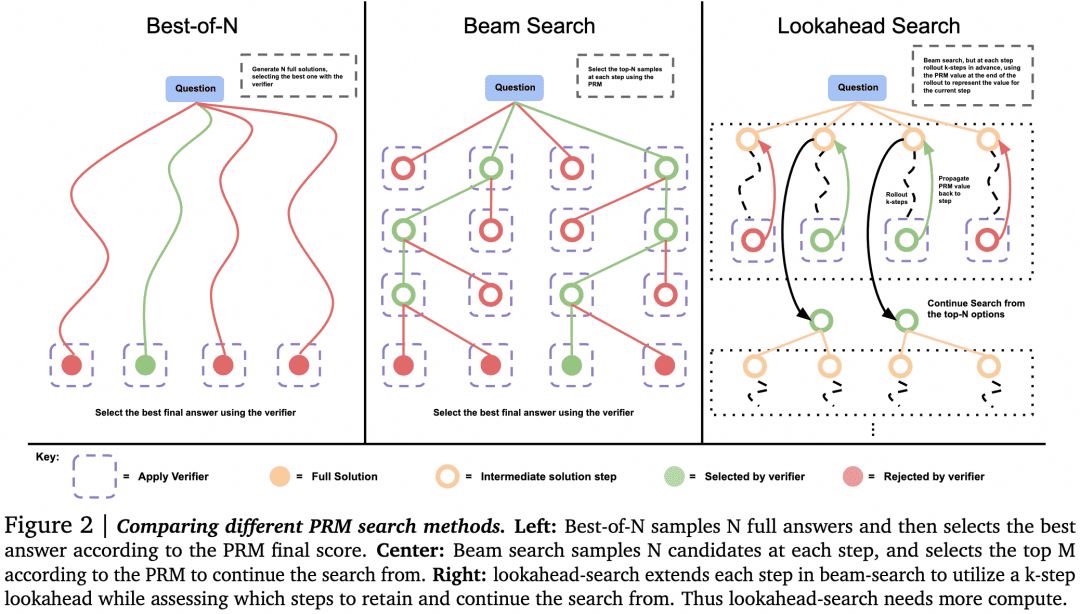
この論文では、単純な問題については、やみくもに並列検索を行うのではなく、Verifierを使ってGeneratorに自己チェックと修正を促すべきであることがわかった。複雑な問題では、Generatorが並行してさまざまな解決策を試す方がよい。
同様の研究に、A Comparative Study on Reasoning Patterns of OpenAI's o1 Modelがある。この論文チームは、o1のレプリカであるOpen-o1をGitHubでオープンソース化しており、この記事はo1リリース後の研究の成果の一部である。下の画像は論文からの引用です:
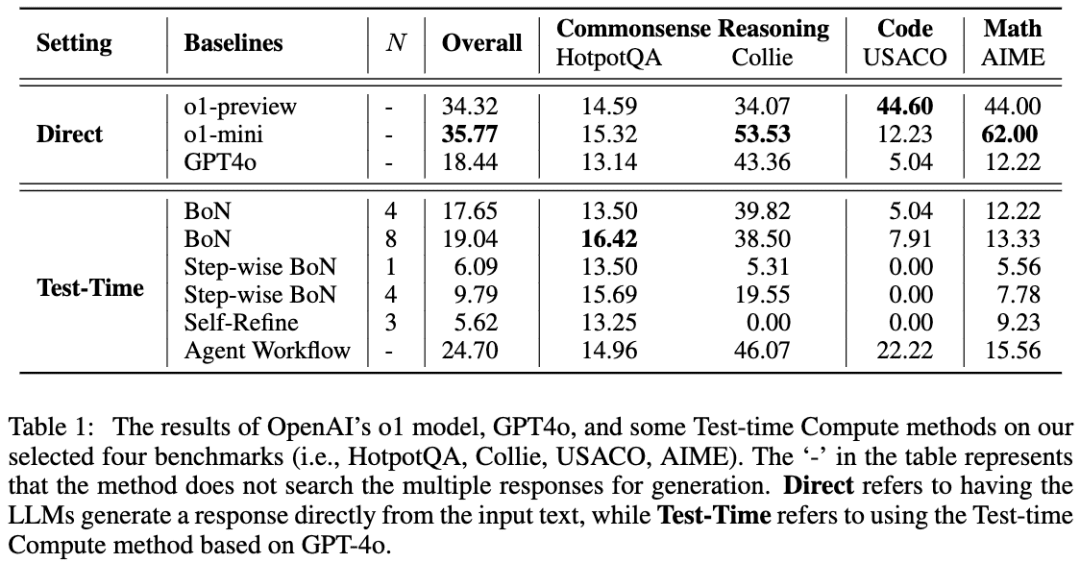
研究チームは、GPT-4oをスケルトンモデルとして使用し、LLMに推論前に考えさせるための4つの一般的なアプローチを用いて結果を比較した。その結果、HotpotQAタスクでは、Best-of-NアプローチとStep-wise BoNアプローチの両方が、LLMの推論を大幅に改善できることがわかった。
06 オープンアール
o1を再現しようとする現在のオープンソースプロジェクトの中で、OpenRは比較的よくできたプロジェクトのひとつだ。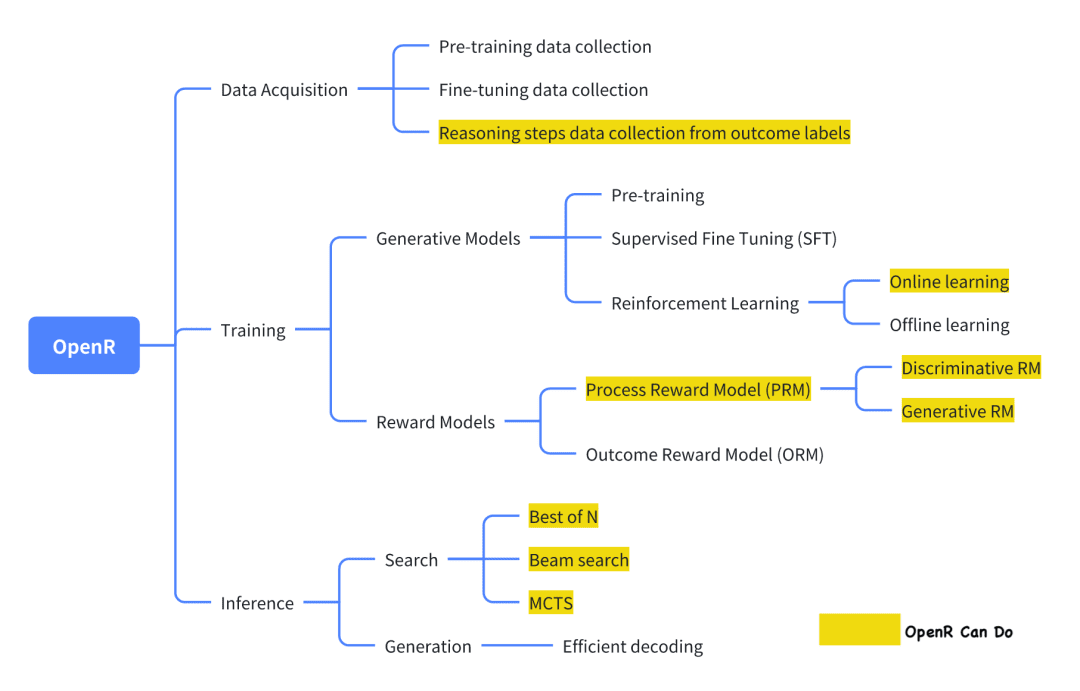
画像はその公式文書に掲載されているもので、現状では、Generator-Verifierのフレームワークに沿って、データ収集、トレーニング、配備が実施されている。
データ収集 公式な紹介によると、データ収集方法は論文「Improve Mathematical Reasoning in Language Models by Automated Process Supervision」による。要するに、MCTSを使って元の問題-最終解答データセットを拡張し、CoT推論ステップを生成する。最終的に、MATH-APSデータセットが得られる。
関連データセットはModelScopeにホストされている:
PRM800K-Stepwiseデータセット:
https://modelscope.cn/datasets/AI-ModelScope/openai-prm800k-stepwise-critic/
MATH-APSデータセット:
https://modelscope.cn/datasets/AI-ModelScope/MATH-APS/
Math-Shepherdデータセット:
https://modelscope.cn/datasets/AI-ModelScope/Math-Shepherd
Generatorの学習チームは、Generatorの学習に強化学習のPPOアルゴリズムの変種を使用する。 つまり、PPOアルゴリズムは、Reward Modelによって提供されるReward情報をGeneratorの学習に使用すると同時に、既存の知識を失わないように、学習プロセス中に元のActorから大きく逸脱しないようにActorを制限する。現在、OpenRは、APPO、GRPO、TPPOの3種類をサポートしている。
Virifierのトレーニングチームは、上記のMATH-APSデータセットと、2つのオープンソースデータセット、PRM800KとMath-Shepherdを使用して、SFT教師あり学習を使用してPRMをトレーニングした。具体的には、これら3つのステップレベルデータセットにおいて、チームは各ステップに「+」または「-」のラベルを付け、PRMに各ステップのラベルを予測し、それが正しいか正しくないかを判断するよう学習させた。
このモデルは、PPOトレーニングのために "ステップワイズ "データを使用し、得られたモデルの重みは、現在SFT、PRM、RLモデル、およびいくつかのGGUF形式のチェックポイントを提供するModelScopeにホストされている:
mistral-7b-sftモデル:
https://modelscope.cn/models/AI-ModelScope/mistral-7b-sft
RLモデル(GGUFバージョン):
https://modelscope.cn/models/QuantFactory/math-shepherd-mistral-7b-rl-GGUF
PRMモデリング:
GGUFバージョン:https://modelscope.cn/models/QuantFactory/math-shepherd-mistral-7b-prm-GGUF
PRMモデル:https://modelscope.cn/models/AI-ModelScope/math-shepherd-mistral-7b-prm
推論のデプロイメント デプロイメント時に、OpenRは指定されたGeneratorとVerifierを通して、推論プロセスと最終的な答えを得るために検索アルゴリズムを使用します。現在、MCTS、Beam Search、best_of_nがサポートされています。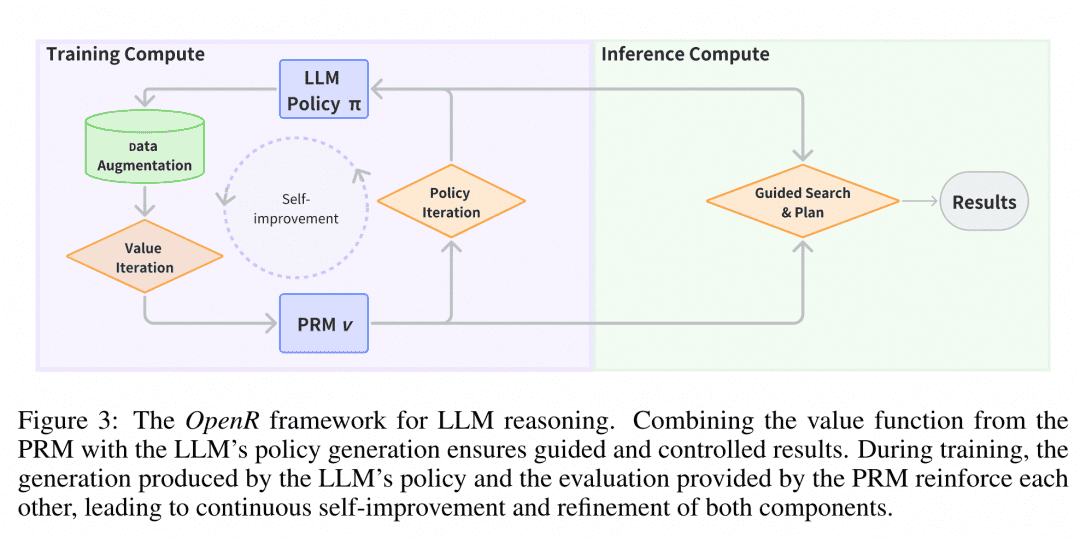
画像は論文 "OpenR: An Open Source Framework for Advanced Reasoning with Large Language Models "からの引用である。 OpenRの構造は図の通りであり、これまでのところ、O1は学習データの収集から、PRMのトレーニング、PRMを使った学習の強化、そして最終的にモデルのデプロイまで、O1を複製したチェーンを実装している。OpenRは現在、訓練データの収集から、PRMの訓練、PRMを使った学習の強化、そして検索用のモデルの配備まで、O1を複製したチェーンを実装しており、チームはこの作業のすべてをオープンソースにして、コミュニティが学んだり試したりできるようにしているので、その一端を垣間見ることができる。
クリエイティブ・スペースの体験マジック・ヒッチ・コミュニティ・クリエイティブ・スペースにOpenRの推論サービスをデプロイしました。開発者は次のリンクにアクセスして、オンラインでOpenRの効果を体験することができます: https://www.modelscope.cn/studios/modelscope/OpenR_Inference
07 まとめ
我々が調査した上記の多段階推論に関する論文は、LLMに中間過程をスキップさせるのではなく、段階的に推論させることで、論理関連の問題に対する精度を大幅に向上させることができることを示している。LLMにステップバイステップで推論させるためには、簡単な手がかり語工学によるガイドに加え、中間過程を含むいくつかのデータセットを用いて微調整を行うことができる。より効率的には、ジェネレータが生成した結果を検索するために、ジェネレータの精度を段階的に検証するベリファイアを訓練することができる。
これまでの推測や論文を見る限り、o1に向けた技術は、まさに強力なLLMジェネレーターとLLMベリファイアーの協調に基づいていると思われる。このような左足と右足の自己反復は、ディープラーニングでは初めてのことではないが、OpenAIはLLM分野にこのようなモデルを導入した最初の例であり、Generatorを訓練するだけでも非常にコストがかかるので、本当に大変なことだ。
したがって、o1 を再現したい場合、まず必要なのは、Generator に支援と指導を提供できる Verifier であり、Verifier を訓練するために必要なデータを生成するためには、上記の CoT + Supervised Fine-Tune と Monte Carlo Tree Search の章を参考にして、より質の高いデータを低コストで入手することができると考える。検証機の訓練に必要なデータを生成するために、上記の「CoT + Supervised Fine-Tune」と「モンテカルロ・ツリー・サーチ」の章を参照することで、より質の高いデータを低コストで入手することができます。このため、これらのタスクも紹介しました。
最後に、完成度の高いオープンソースプロジェクトを発表し、彼らの作品に基づいて、自分たちの考えやアイデアを整理することができた。
08 参考
思考の連鎖が大規模言語モデルの推論を引き出す
大規模言語モデルはゼロショット推論者である
STaR: 推論によるブートストラップ推論
相互推論が小さなLLMを強い問題解決者にする
数学の単語問題を解く検証者のトレーニング
ステップ・バイ・ステップで検証してみよう
LLMのテスト時間計算を最適にスケーリングすることは、モデルパラメータをスケーリングするよりも効果的である。
OpenAIのo1モデルの推論パターンに関する比較研究
OpenR: 大規模言語モデルによる高度な推論のためのオープンソースフレームワーク
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事




コメントはありません