Cognita:モジュラーRAGアプリケーションを構築し、多様なRAG戦略を迅速にテストするためのオープンソースフレームワーク

はじめに
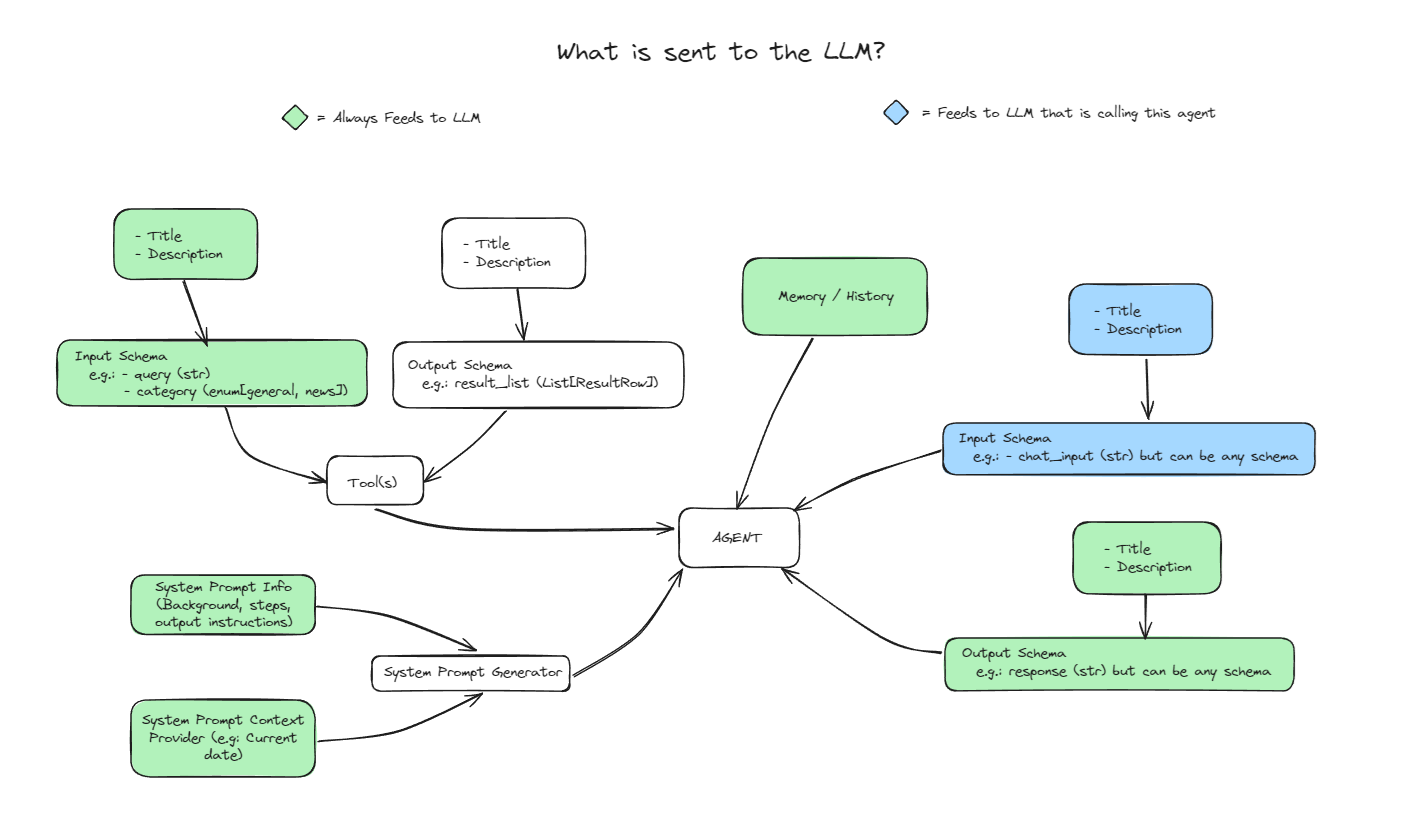
Cognitaは、RAG(Retrieval-Augmented Generation)ベースのアプリケーションの開発を簡素化するためにTrueFoundryによって開発されたオープンソースのフレームワークです。このフレームワークは、構造化されたモジュール式のソリューションを提供し、RAG(Retrieval-Augmented Generation)ベースのアプリケーションを簡単に組み込むことができます。 ラグ Cognitaは複数のデータソース、パーサー、組み込みモデルをサポートし、技術的なバックグラウンドを持たないユーザーでもRAGの設定を試すことができる使いやすいユーザーインターフェースを提供します。既存のシステムとシームレスに統合し、インクリメンタルインデキシングと複数のベクターデータベースをサポートし、開発者がAIアプリケーション開発において迅速な反復と展開を達成できるよう支援します。
Langchain/LlamaIndexのモジュール性に基づくさまざまなRAG戦略を参照し、本番グレードのアプリケーションを素早くテストしてリリースするためのユーザーフレンドリーなインターフェイスを提供する。



機能一覧
- モジュール設計: RAGアプリケーションをデータローダー、パーサー、エンベッダー、リトリーバーなどの個別のモジュールに分割し、コードの再利用性と保守性を向上させます。
- 直感的なユーザーインターフェース:ユーザーが簡単に文書をアップロードし、Q&A操作を実行できるビジュアルインターフェースを提供します。
- APIドライバ:完全なAPIドライバをサポートし、他のシステムとの統合が容易です。
- インクリメンタルインデックス作成:変更された文書のみ再インデックス作成し、コンピューティングリソースを節約します。
- 複数のデータソースをサポート:ローカルディレクトリ、S3、データベースなどの複数のデータソースからデータをロードします。
- マルチモデルのサポート:OpenAI、Cohere、その他の組み込みモデル、言語モデルのサポートを含む。
- ベクターデータベースの統合:Qdrant、SingleStoreなどのベクターデータベースとのシームレスな統合。
ヘルプの使用
設置プロセス
CognitaはオープンソースのPythonプロジェクトであるため、インストールには以下の手順が必要です:
- クローン倉庫::
git clone https://github.com/truefoundry/cognita.git cd cognita - 仮想環境の設定(推奨慣行):
python -m venv .cognita_env source .cognita_env/bin/activate # Unix .cognita_env\Scripts\activate # Windows - 依存関係のインストール::
pip install -r requirements.txt - 環境変数の設定::
- .env.exampleを.envファイルにコピーし、APIキーやデータベース接続など、必要に応じて設定する。
使用ガイドライン
データのロード:
- データソースの選択: Cognita は、ローカルファイル、S3 ストレージバケット、データベース、または TrueFoundry アーテファクトからのデータのロードをサポートしています。お客様に適したデータソースのタイプを選択してください。
- データのアップロードまたは設定:ローカルファイルを選択した場合は、ファイルを直接アップロードします。他のデータソースの場合は、アクセス権とパスを設定します。
データの解析:
- パーサーの選択:ドキュメントの種類(PDF、Markdown、テキストファイルなど)に応じて、適切なパーサーを選択します。Cognitaはデフォルトで複数のファイルフォーマットのパースをサポートしています。
- 構文解析の実行: 構文解析ボタンをクリックすると、システムは文書を統一フォーマットに変換します。
データの埋め込み:
- 組み込みモデルの選択:ニーズに応じて組み込みモデル(OpenAIのモデルや他のオープンソースモデルなど)を選択します。
- エンベッディングの生成:エンベッディング操作を実行し、テキストをその後の検索のためのベクトル表現に変換する。
照会と検索:
- クエリーの入力:UIまたはAPI経由でクエリーを入力します。
- 関連情報の取得:システムは、クエリに従ってデータベース内の最も関連性の高いドキュメントフラグメントを取得します。
- 回答の生成: 選択した言語モデルを使用して、検索されたセグメントに基づいて回答を生成します。
インクリメンタルインデックス:
- データ変更の監視:Cognitaは新規または更新されたドキュメントのみをインデックス化する機能を提供し、効率を高め、コンピューティングリソースを節約します。
ユーザーインターフェースの操作:
- コレクションの管理:UIでドキュメントコレクションの作成、削除、編集ができます。
- Q&A操作:インターフェイスから直接質疑応答することで、RAGシステムの効果を体感できる。
注目の機能操作
- 多言語サポート: データに複数の言語が含まれている場合、Cognitaの多言語サポートを利用して多言語でのQ&Aを行うことができます。
- 動的なモデル切り替え:Cognitaでは、アプリケーション全体を再デプロイすることなく、必要に応じて異なるエンベッディングモデルや言語モデルを切り替えることができます。
上記のステップと機能により、ユーザーはすぐにCognitaを使い始め、独自のRAGアプリケーションを構築して最適化し、AI主導の情報検索と生成を改善することができる。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません