クロード 3.7 ソネット:初のハイブリッド推論モデルと知的コーディングツール「クロード・コード」の発表

昨晩、Anthropicが新モデルを発表するというニュースがAIコミュニティで瞬く間に広まった。 クロード 4.0ではなく、クロード3.7のソネット版だ。

今朝早く、Anthropicは最新のフラッグシップモデルを発表した。クロード3.7ソネットの正式発表。これまでで最もスマートで、市場初のハイブリッド推論モデルである!.
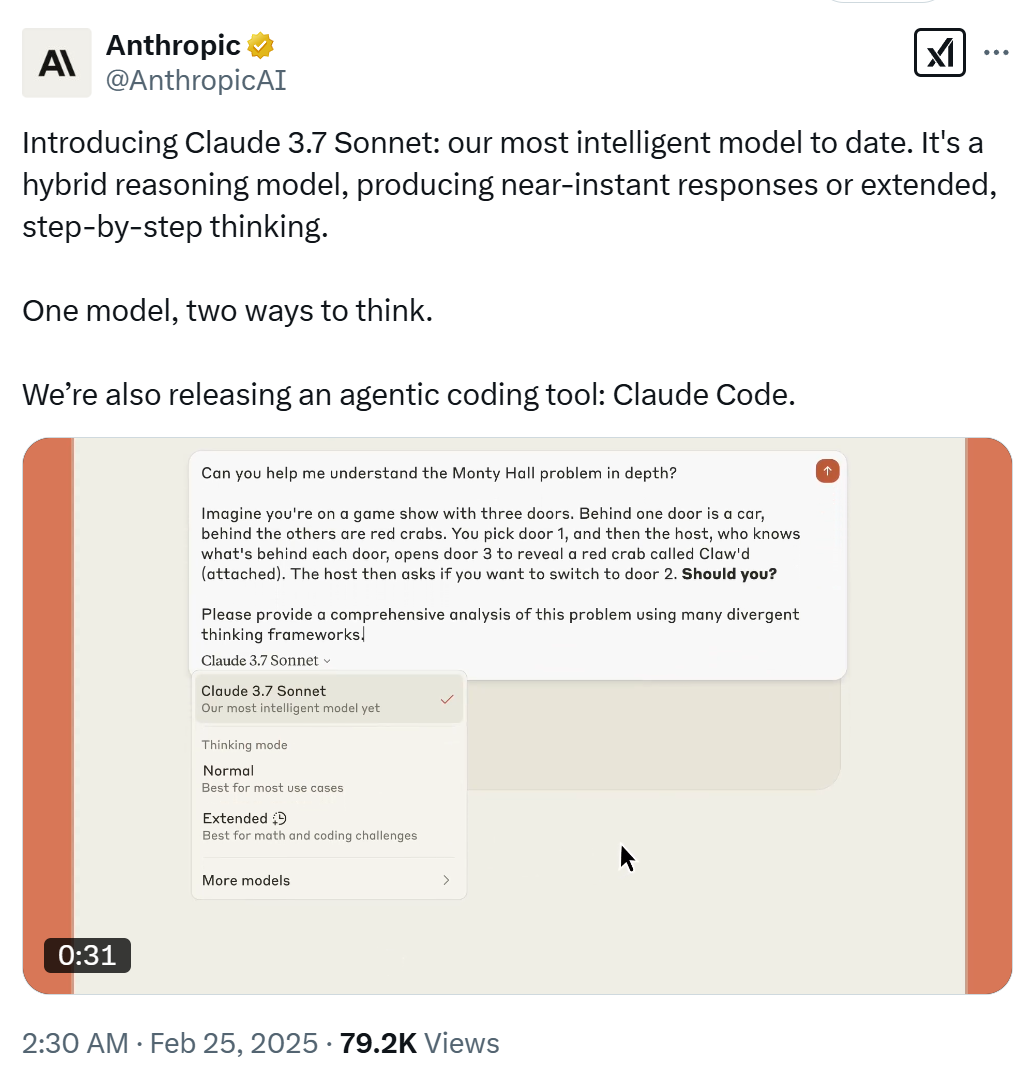
Claude 3.7 Sonnetは、ほぼリアルタイムの迅速な対応と、ユーザーのニーズに基づいたより詳細なステップバイステップの思考の両方を提供します。.として アンソロピック 1つのモデルで、2通りの考え方ができる...」という説明は、標準的な思考モードと拡張された思考モードの両方を備えていることを指している。さらに、APIユーザーはモデルの思考の長さをより細かくコントロールすることができる。

クロード3.7ソネットのリリースに加えて。Anthropicはまた、Claude Codeと呼ばれる並列コマンドラインツールを発表した。.このツールは現在、限定的な研究プレビューとして利用可能で、開発者がターミナル環境で直接クロードに多くのエンジニアリング作業を任せられるように設計されている。
コーディング機能に関して、AnthropicはClaude.aiプラットフォームでのコーディング体験をさらに最適化した。そのGitHub統合は現在、すべてのClaudeプログラムで利用可能で、開発者は自分のコードリポジトリを直接Claudeに接続することができます。個人、仕事、オープンソースプロジェクトをより深く理解することで、ClaudeはGitHubプロジェクトのバグ修正、機能開発、文書作成に関して、開発者にとってさらに強力なアシスタントになるでしょう。
このため、コーディングとフロントエンドのウェブ開発能力が大幅に向上している。クロード3.7ソネットは、アンソロピックにとってこれまでで最高のエンコーディングモデルとなった。.
ユーザーは、Anthropic API、Amazon Bedrock、Google Cloud Vertex AIなどのプラットフォームだけでなく、すべてのClaudeプラン(Free、Pro、Team、Enterpriseを含む)で最新のClaude 3.7 Sonnetモデルを体験できるようになりました。無料ユーザーに加え、すべての有料会員は拡張思考モデルを体験することができます。
標準思考モードと拡張思考モードではクロード3.7ソネットの価格は、前世代のクロード3.5ソネットと変わらず、100万インプットトークンあたり3ドル、100万アウトプットトークンあたり15ドル(シンクトークンを含む)です。.
Anthropicの新作はどれも驚きと興奮に満ちている。
マキシマム・クロード 3.7 ソネット
最先端の推論をあなたの指先に
Anthropicは、Claude 3.7 Sonnetが市場にある他の推論モデルとは異なる哲学で開発されたことを強調し、人間の脳が素早く反応すると同時に深く考えることができるように、AIの推論も最先端のモデルの機能を分離するのではなく、統合することができるはずだと主張している。この統一されたデザインアプローチは、よりスムーズなユーザー体験を提供することを目的としている。
この哲学に沿って、クロード3.7ソネットは多くのユニークな利点を提供している。
まず第一に。Claude 3.7 Sonnetは、汎用のLLMとして使えるだけでなく、強力な推論機能を備えている点がユニークである。ニーズに応じて、モデルに素早く答えを出させることも、より深く考えてから答えを出させることもできる。標準モードでは、クロード3.7ソネットは、前作クロード3.5ソネットからのアップグレード版と見ることができる。標準モードでは、クロード3.7ソネットは、その前身であるクロード3.5ソネットのアップグレード版として見ることができます。拡張思考モードでは、答えを出す前に自分自身を振り返り、数学、物理学、命令追従、コーディングなど、幅広いタスクのパフォーマンスを大幅に向上させる。両モードにおいて、モデルはキューワードを同様に理解し、処理することにAnthropic関係者は注目している。
第二に。APIを使ってクロード3.7ソネットを呼び出す際、ユーザーはモデルの "思考予算 "をカスタマイズすることもできる。.具体的には、ユーザーはクロードに最大数で考えるように設定することができる。 トークン 数(N)。Nの値に関係なく、このモデルは出力トークン数を128Kに制限している。 これによりユーザーは、応答のスピード(とコスト)と回答の質の最適なバランスを見つけることができる。
第三に、推論モデルを開発する際にAnthropicは、他の組織が行っているような数学やコンピュータサイエンスのコンペティションの問題でモデルのパフォーマンスを最適化することに過度に注力するのではなく、より実践的な企業アプリケーションのシナリオに関連する実世界のタスクに焦点を当てています。.
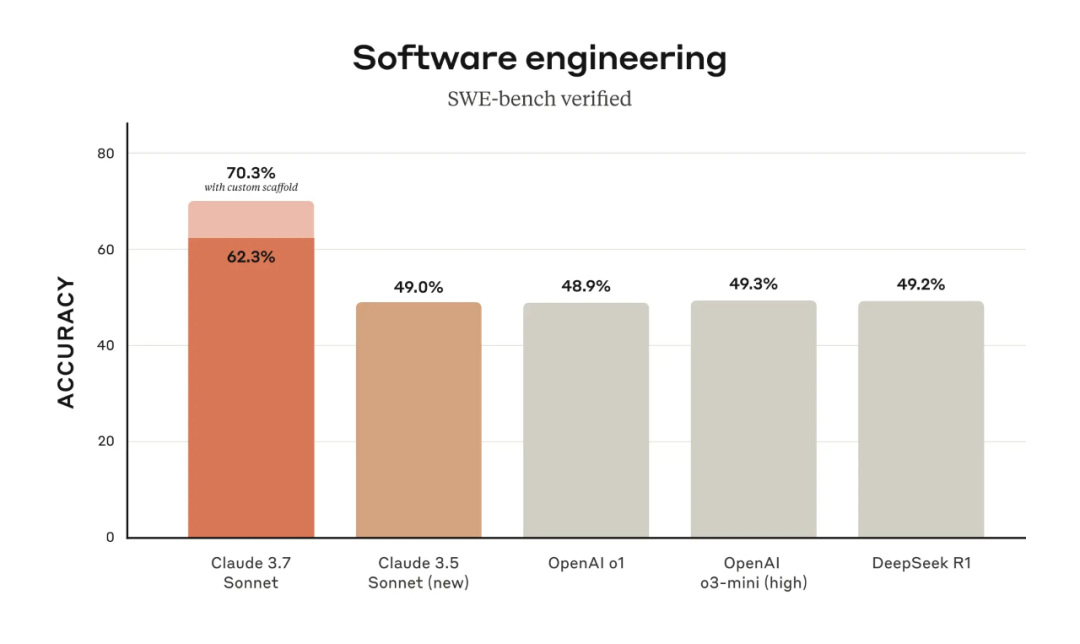
Claude 3.7 Sonnet ベンチマークの結果から、SWE-bench Verified ベンチマーク(LLM が GitHub 上で実際のソフトウェア問題を解決する能力を評価するために設計されたベンチマーク)ではクロード3.7ソネットはSOTAレベルの性能を達成し、クロード3.5ソネット、OpenAIのo3-mini(high)とo1、DeepSeek R1などのモデルを大きく引き離した。.
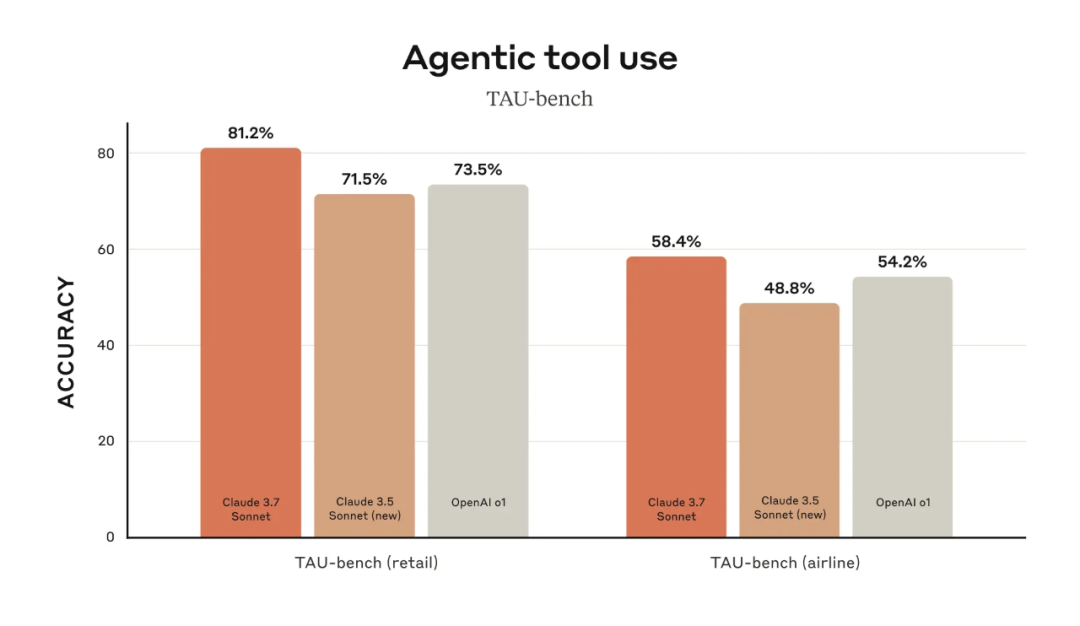
複雑で現実的なシナリオにおけるLLMの能力を評価するためのベンチマークプラットフォームであるTAU-benchベンチマークにおいても、クロード3.7ソネットは、クロード3.5ソネットとOpenAIのo1モデルの両方を上回るSOTAレベルの性能を達成し、良好なパフォーマンスを示しています。
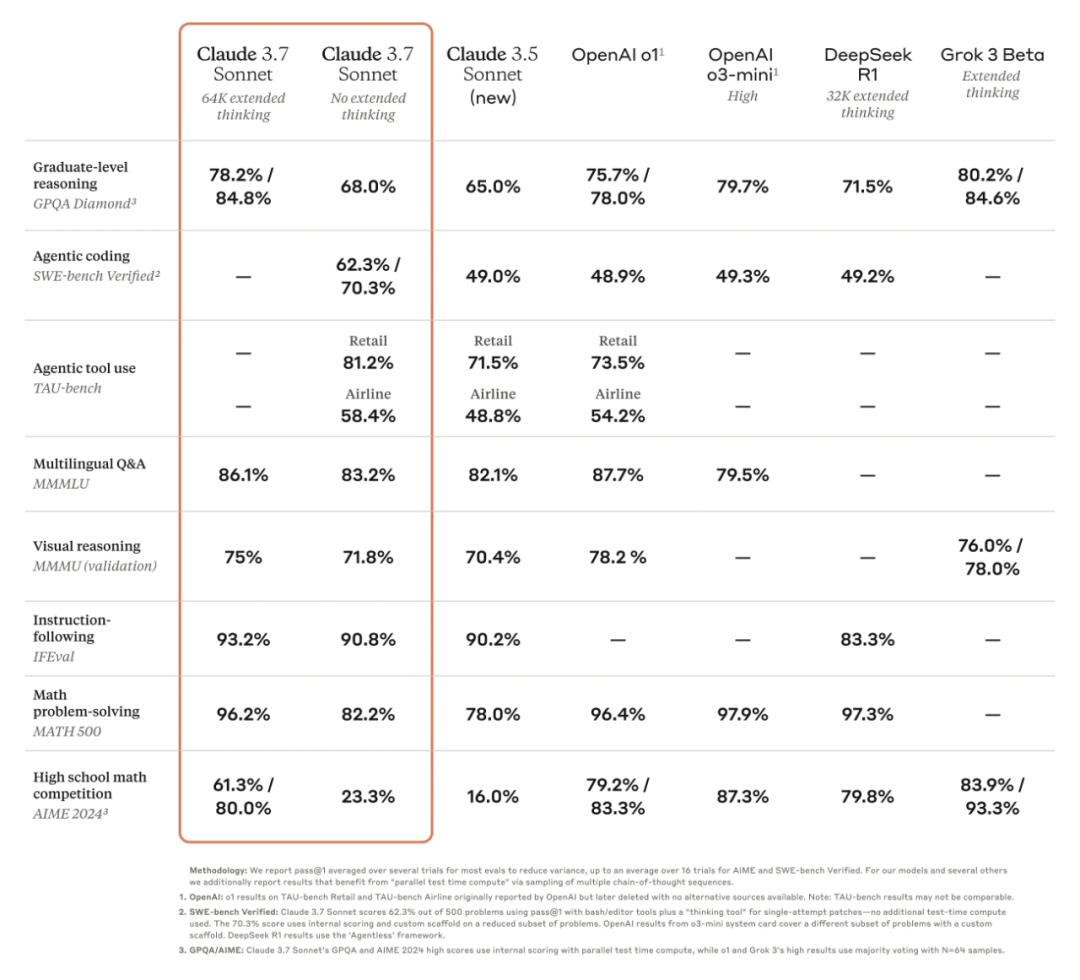
クロード3.7 Sonnetは、命令の順守、一般化された推論、マルチモーダル能力、インテリジェント・コーディングなど、多くの分野で優れた性能を発揮し、特に拡張思考モードでは数学と科学が大幅に強化された。しかし、いくつかの特定の分野では、OpenAIの能力にわずかに及ばない。 o3-ミニ (高)、Grok-3 Betaなどのモデルがある。
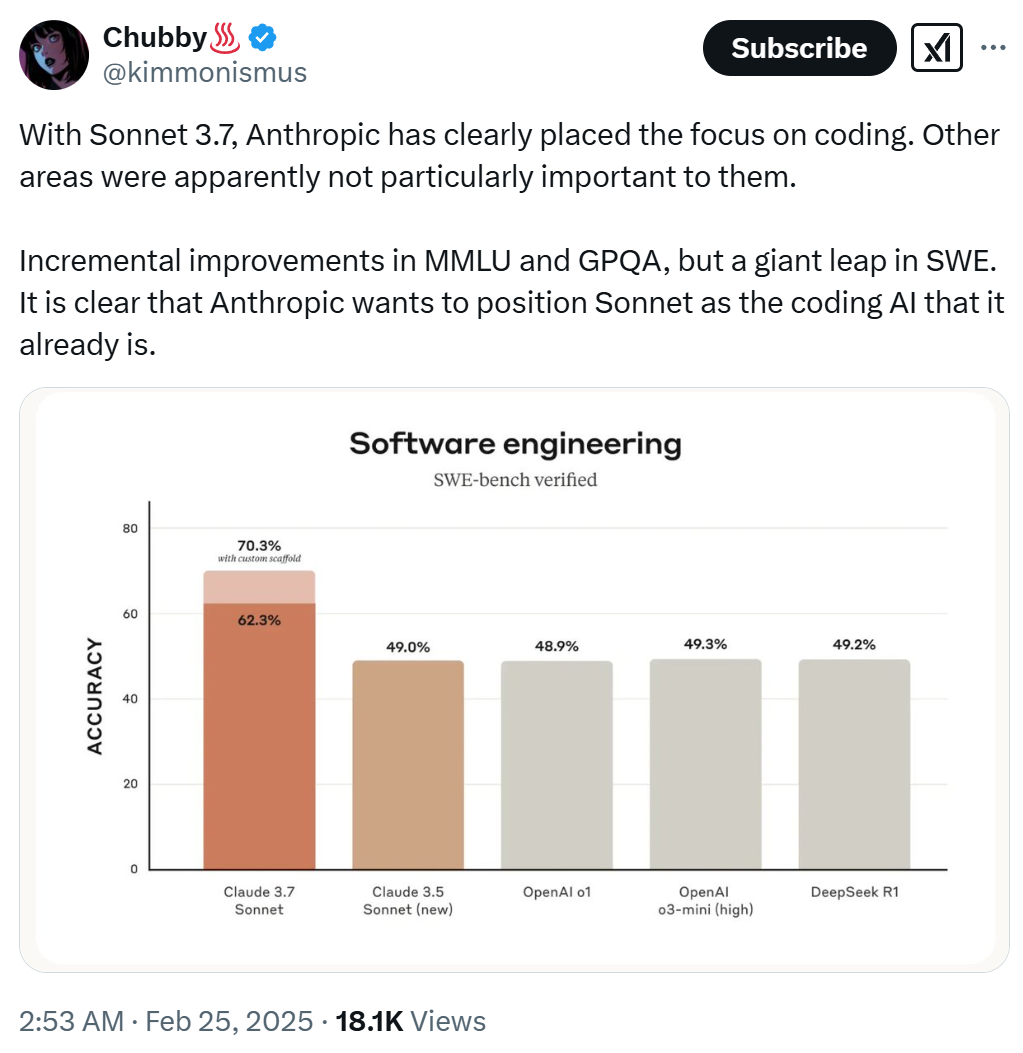
Anthropicがクロード3.7ソネットでコーディング能力に重点を置き、他の分野での改良は比較的目立たなかったことがよくわかる。 AnthropicがSonnetシリーズをコーディングに特化したAIモデルとして位置づけようとしていることは明らかだ(実際にその方向に進んでいる)。
特筆すべきは、従来のベンチマークで優れていたことに加え、ポケモンのプレイテストでクロード3.7ソネットが従来の全モデルを上回っていたことだ。
Anthropicは、すでにパートナーと共に大規模な初期テストを実施しており、その結果、エンコーディング能力という点で、クロード・モデルファミリーのリーダーシップが十分に証明されている。
例えば、Cursorチームは、Claudeが再び実世界のコーディングタスクで選択されるソリューションとなり、複雑なコードベースの処理と高度なツールの使用において大幅な改善を示したと指摘し、Cognitionチームは、Claudeがコード変更計画とフルスタックの更新処理において他のモデルを上回ったことを明らかにしました。Vercelは、複雑なエージェントワークフローにおけるClaudeの精度を強調し、Replitは、他のモデルが苦戦している複雑なウェブアプリケーションとダッシュボードをスクラッチから構築するためにClaudeを使用することに成功しました。エラー率が大幅に減少
クロード・コード
開発を容易にするインテリジェントなコーディング
2024年6月以来、Sonnetファミリーは世界中の開発者に選ばれてきました。現在ではAnthropicは、開発者の生産性と能力をさらに向上させるために設計された、同社初のインテリジェントコーディングツールであるClaude Codeを正式にリリースした(現在は限定的な研究プレビュー版)。.
機能的には、Claude Codeは、コードの検索や読み込み、ファイルの編集、テストの記述と実行、GitHubへのコードのコミットとプッシュ、さまざまなコマンドラインツールの起動などのタスクを実行できる、積極的なコラボレーションパートナーとして位置づけられている。
いくつかの例を見てみよう。 クロード・コード アプリケーションのシナリオ、例えばプロジェクト構造の説明など:

筆記試験:
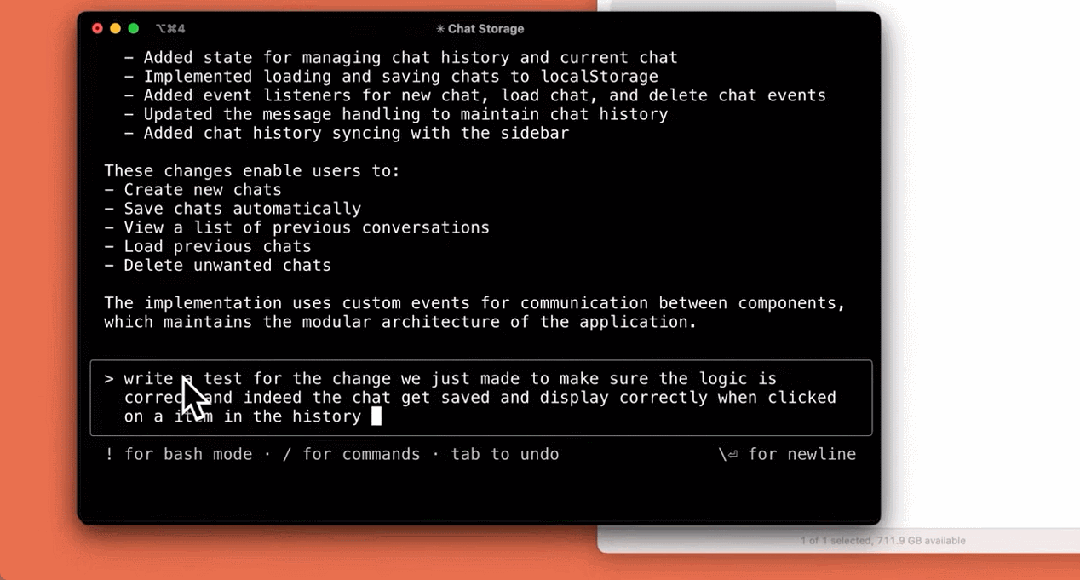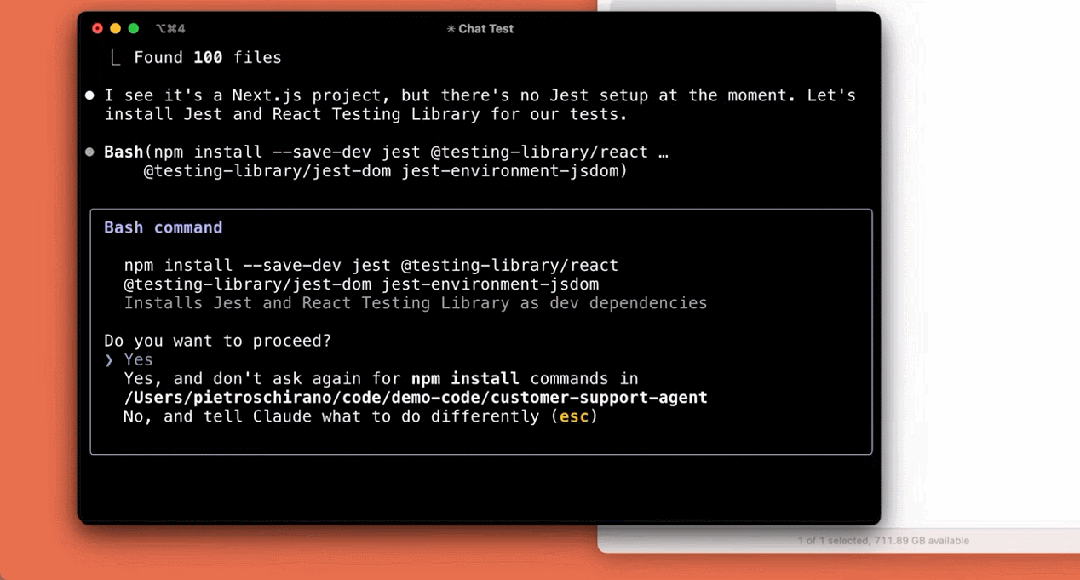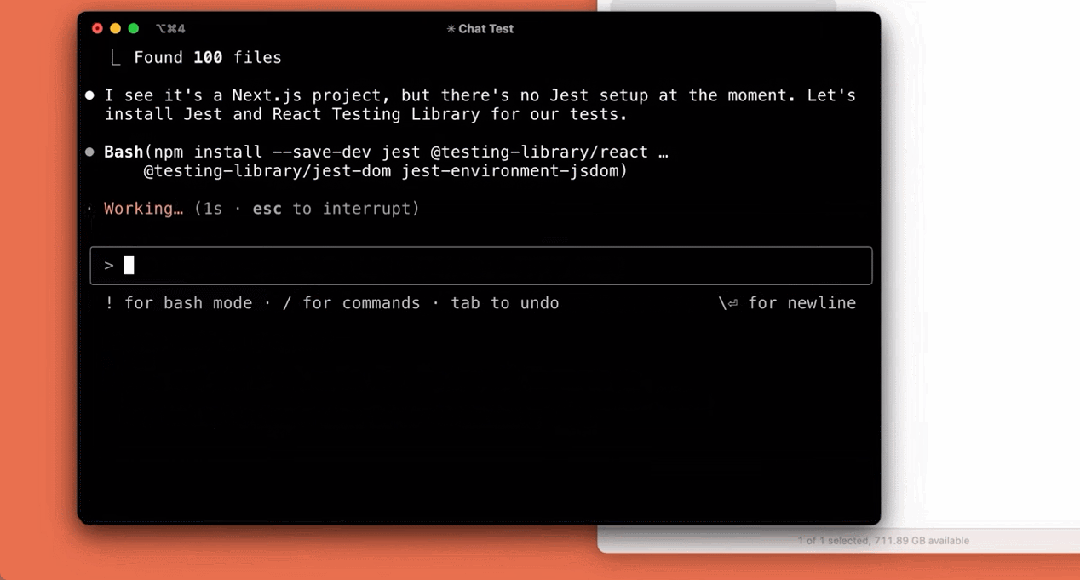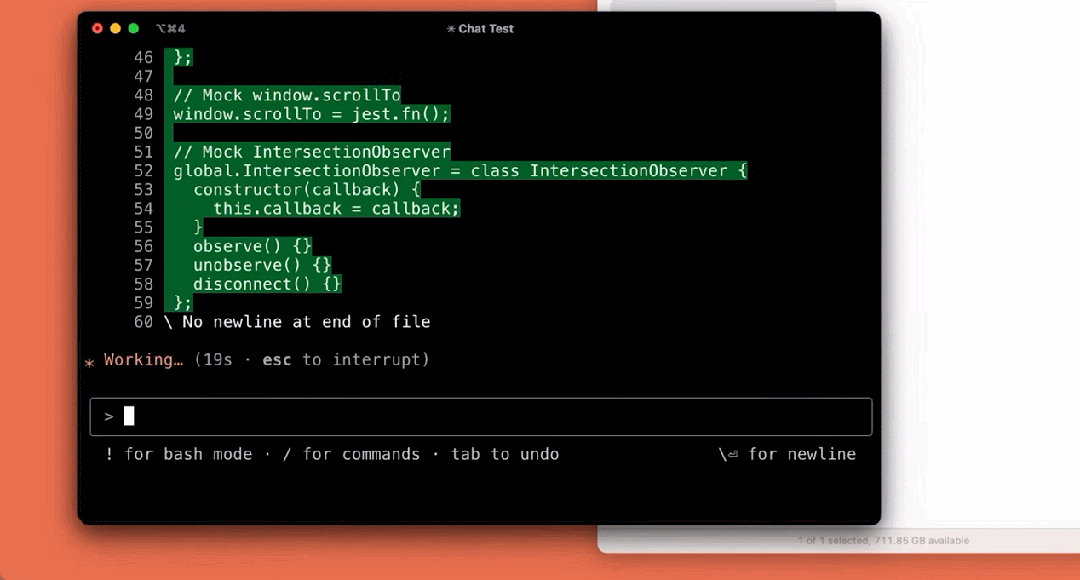
アプリケーションを構築する:
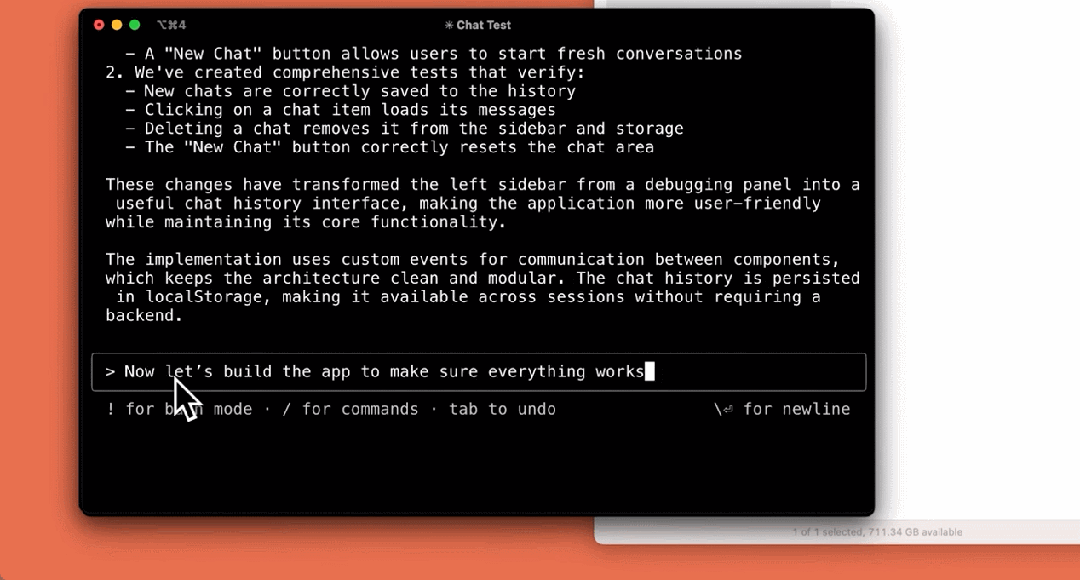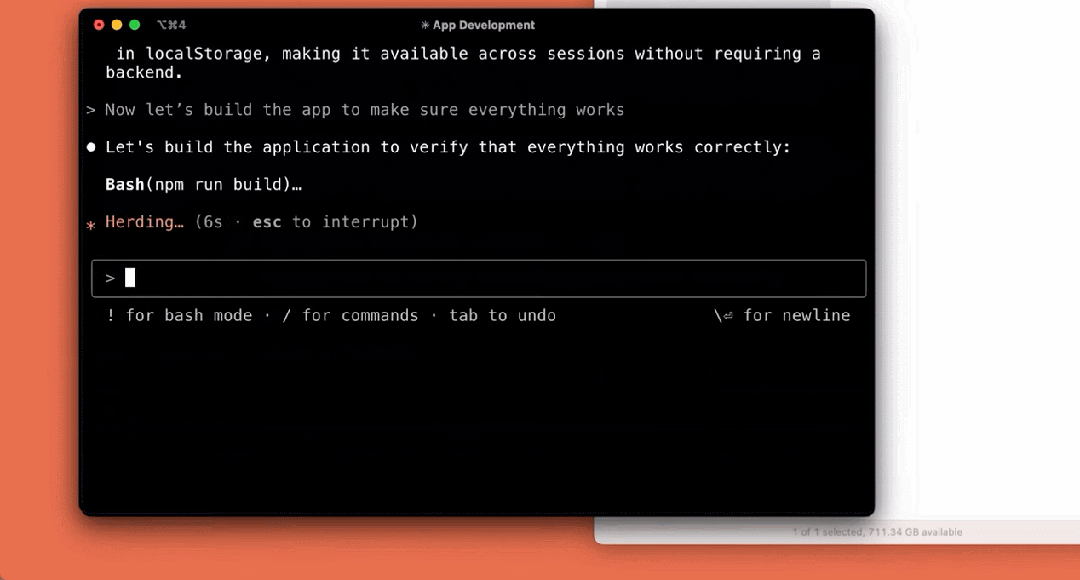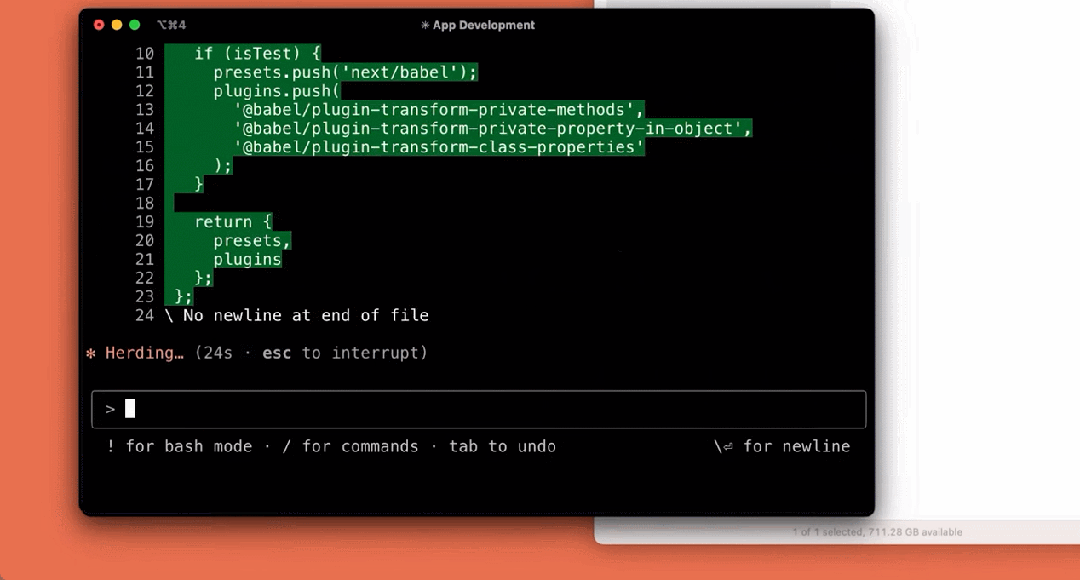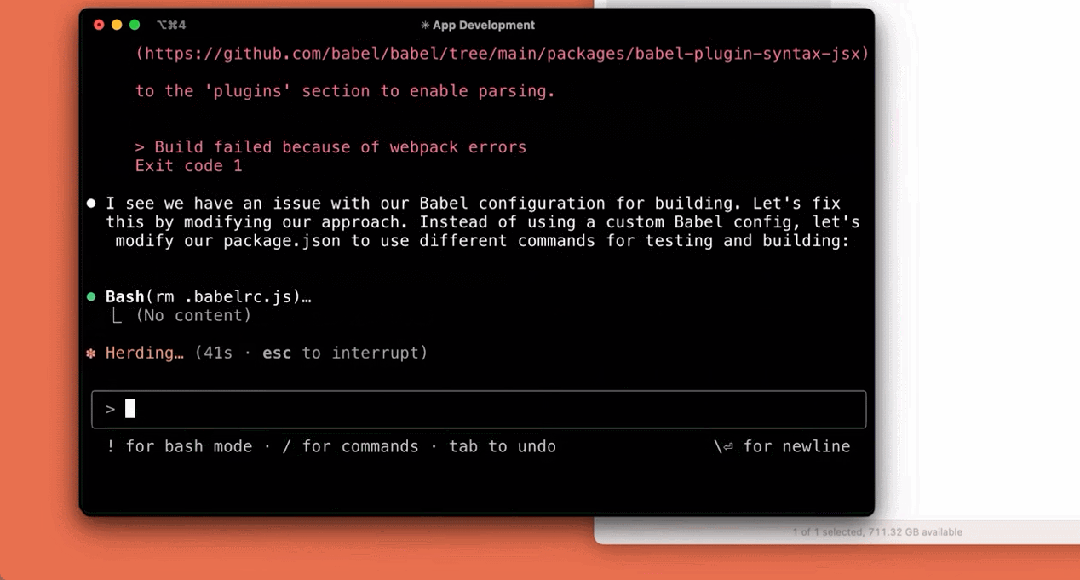
まだプレビューの初期段階ですが、クロード・コードは、特にテスト駆動開発、複雑な問題のデバッグ、大規模なコードのリファクタリングにおいて、Anthropicチームにとって欠かせないツールとなっています。
初期のテストでは、クロード・コードは、通常手作業で45分以上かかる作業を1回でこなし、開発時間とコストを大幅に削減した。.
Anthropicは今後数週間で、ツール呼び出しの信頼性の向上、長時間実行コマンドのサポートの強化、アプリ内レンダリングの改善、クロード自身の機能理解の深さの拡大など、独自の使用フィードバックに基づくクロードコードの最適化を継続する予定です。
Claude Codeは、開発者がClaudeを使ってどのようにコーディングするのかをより深く理解し、Anthropicのモデルを将来的に改良する際の貴重な参考資料とすることを目的としています。 クロードコードのプレビュー体験に参加された方は、Anthropicがクロードモデルの構築と最適化のために社内で使用している強力なツールにいち早くアクセスすることができます。
責任ある建設と将来の展望
Anthropicは、Claude 3.7 Sonnetを徹底的にテスト・評価し、外部のセキュリティ専門家と協力して、このモデルが自社で設定したセキュリティと信頼性の基準を満たしていることを確認しました。
同時に、クロード3.7ソネットは、有害なリクエストと良性のリクエストの区別において、よりきめ細かい判断を示している。前世代モデルと比較して、不要な拒否の数を45%減少させた。

CoTフィデリティ評価の結果。
クロード3.7ソネットのモデルカードでは、Anthropicが責任あるAIのスケーリングポリシーを評価するためのフレームワークを詳細に説明し、関連する他のAIラボや研究者の実践経験を活用しています。さらに、モデルカードでは、AI技術の応用によってもたらされる新しいタイプのリスク、特にラピッドインジェクション攻撃について概説し、Anthropicがこれらの潜在的なセキュリティ脆弱性をどのように評価し、対応するか、また、これらのリスクを防御・軽減するためにClaudeモデルをどのようにトレーニングするかについて説明しています。 これに加えて、モデルカードは推論モデルがもたらす潜在的なセキュリティ上の利点を掘り下げ、「モデルの意思決定プロセスを理解する方法」や「モデルの推論結果が本当に信頼できるものなのか」といった疑問についても検証しています。

Anthropicは、Claude 3.7 SonnetとClaude Codeのリリースが、AIシステムで人間に真の力を与えるための重要な一歩になると信じています。 優れた深層推論、自律的な作業、効率的なコラボレーションにより、AnthropicはAI技術が人間の可能性を完全に豊かにし、拡大する未来のビジョンに近づいています。
2025年までに、クロードは何時間でも自律的に作業できる専門的な知性へと進化し、2027年までに、クロードは人間のチームでは何年もかかるような複雑な問題にも取り組めるようになると、Anthropic社は期待している。

© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません