
タンデム・ラングチェーン・オープン・ディープ・サーチ・キュー用語

プロジェクトの実行プロセスをつなぎ合わせ、キュー・ワードの指示を翻訳するためには、プロジェクトのベースとなるprompts.pyファイルで、各ステップの実行フローとそれに対応するキューワードの指示を詳細に記述する。
プロジェクトの実行プロセスとそれに対応するキュー・ワードの指示
1.レポート作成に役立つ検索クエリの作成
- プロンプト:
report_planner_query_writer_instructions = """ 你是一名专家技术写手,正在帮助计划一份报告。 <报告主题> {topic} </报告主题> <报告组织> {report_organization} </报告组织> <任务> 你的目标是生成 {number_of_queries} 个搜索查询,以帮助收集全面的信息来规划报告部分。 这些查询应当: 1. 与报告主题相关 2. 帮助满足报告组织中规定的要求 使查询足够具体,以找到高质量、相关的资源,同时覆盖报告结构所需的广度。 </任务> """
2.レポート作成計画
- プロンプト:
report_planner_instructions = """ 我需要一个报告计划。 <任务> 生成一个报告部分的列表。 每个部分应当包含以下字段: - 名称 - 报告部分的名称。 - 描述 - 本部分涵盖的主要主题的简要概述。 - 研究 - 是否需要为本部分报告进行网络研究。 - 内容 - 本部分的内容,现在可以留空。 例如,介绍和结论将不需要研究,因为它们将从报告的其他部分提炼信息。 </任务> <主题> 报告的主题是: {topic} </主题> <报告组织> 报告应遵循此组织: {report_organization} </报告组织> <上下文> 以下是用于规划报告部分的上下文: {context} </上下文> <反馈> 以下是对报告结构的审查反馈(如果有): {feedback} </反馈> """
3.検索クエリの準備
- プロンプト:
query_writer_instructions = """ 你是一名专家技术写手,正在编写有针对性的网络搜索查询,以收集撰写技术报告部分的全面信息。 <部分主题> {section_topic} </部分主题> <任务> 你的目标是生成 {number_of_queries} 个搜索查询,以帮助收集有关本部分主题的全面信息。 这些查询应当: 1. 与主题相关 2. 检查该主题的不同方面 使查询足够具体,以找到高质量、相关的资源。 </任务> """
4.レポート作成
- プロンプト:
section_writer_instructions = """ 你是一名专家技术写手,正在撰写技术报告的一个部分。 <部分主题> {section_topic} </部分主题> <现有部分内容(如果已填写)> {section_content} </现有部分内容> <源材料> {context} </源材料> <撰写指南> 1. 如果现有部分内容未填写,则从头撰写新的部分。 2. 如果现有部分内容已填写,请撰写一个新的部分,将现有内容与新信息综合起来。 <长度和风格> - 严格限制在150-200字 - 不使用营销语言 - 技术重点 - 使用简单、清晰的语言 - 用**加粗**的最重要的见解开头 - 使用简短的段落(每段最多2-3句话) - 使用 ## 作为部分标题(Markdown格式) - 仅在有助于澄清观点时使用一个结构元素: * 要么是比较2-3个关键项目的集中表格(使用Markdown表格语法) * 要么是使用正确的Markdown列表语法的简短列表(3-5项): - 使用 `*` 或 `-` 表示无序列表 - 使用 `1.` 表示有序列表 - 确保正确的缩进和间距 - 以参考以下源材料的###来源结束: * 列出每个来源的标题、日期和URL * 格式:`- 标题 : URL` </长度和风格> <质量检查> - 恰好150-200字(不包括标题和来源) - 仔细使用一个结构元素(表格或列表),仅在有助于澄清观点时 - 一个具体的例子/案例研究 - 以加粗见解开头 - 在创建部分内容之前不作任何序言 - 在结尾引用来源 </质量检查> """
5.レポーティング・コンポーネントの評価
- プロンプト:
section_grader_instructions = """ 审核相对于指定主题的报告部分: <部分主题> {section_topic} </部分主题> <部分内容> {section} </部分内容> <任务> 评估该部分是否通过检查技术准确性和深度,充分涵盖了主题。 如果该部分未满足任何标准,请生成具体的后续搜索查询以收集缺失的信息。 </任务> <格式> grade: Literal["pass","fail"] = Field( description="评估结果,指示响应是否符合要求('通过')或需要修订('失败')。" ) follow_up_queries: List[SearchQuery] = Field( description="后续搜索查询列表。", ) </格式> """
6.最終報告セクションの執筆
- プロンプト:
final_section_writer_instructions = """ 你是一名专家技术写手,正在撰写综合报告其他部分信息的部分。 <部分主题> {section_topic} </部分主题> <可用报告内容> {context} </可用报告内容> <任务> 1. 部分特定方法: 对于介绍: - 使用 # 作为报告标题(Markdown格式) - 50-100字限制 - 使用简单和清晰的语言 - 重点介绍报告的核心动机,1-2段 - 使用清晰的叙述弧线介绍报告 - 不使用任何结构元素(无列表或表格) - 不需要来源部分 对于结论/总结: - 使用 ## 作为部分标题(Markdown格式) - 100-150字限制 - 对于比较报告: * 必须包含使用Markdown表格语法的集中比较表 * 表格应提炼报告中的见解 * 保持表格条目清晰简洁 - 对于非比较报告: * 仅在有助于提炼报告中的要点时使用一个结构元素: * 要么是比较报告中项目的集中表格(使用Markdown表格语法) * 要么是使用正确的Markdown列表语法的简短列表: - 使用 `*` 或 `-` 表示无序列表 - 使用 `1.` 表示有序列表 - 确保正确的缩进和间距 - 以具体的下一步或影响结束 - 不需要来源部分 3. 撰写方法: - 使用具体细节而非一般陈述 - 每个字都要有意义 - 重点突出最重要的一点 </任务> <质量检查> - 对于介绍:50-100字限制,# 作为报告标题,无结构元素,无来源部分 - 对于结论:100-150字限制,## 作为部分标题,仅使用一个结构元素,无来源部分 - Markdown格式 - 不在响应中包含字数或任何序言 </质量检查> """
タンデム実行プロセス
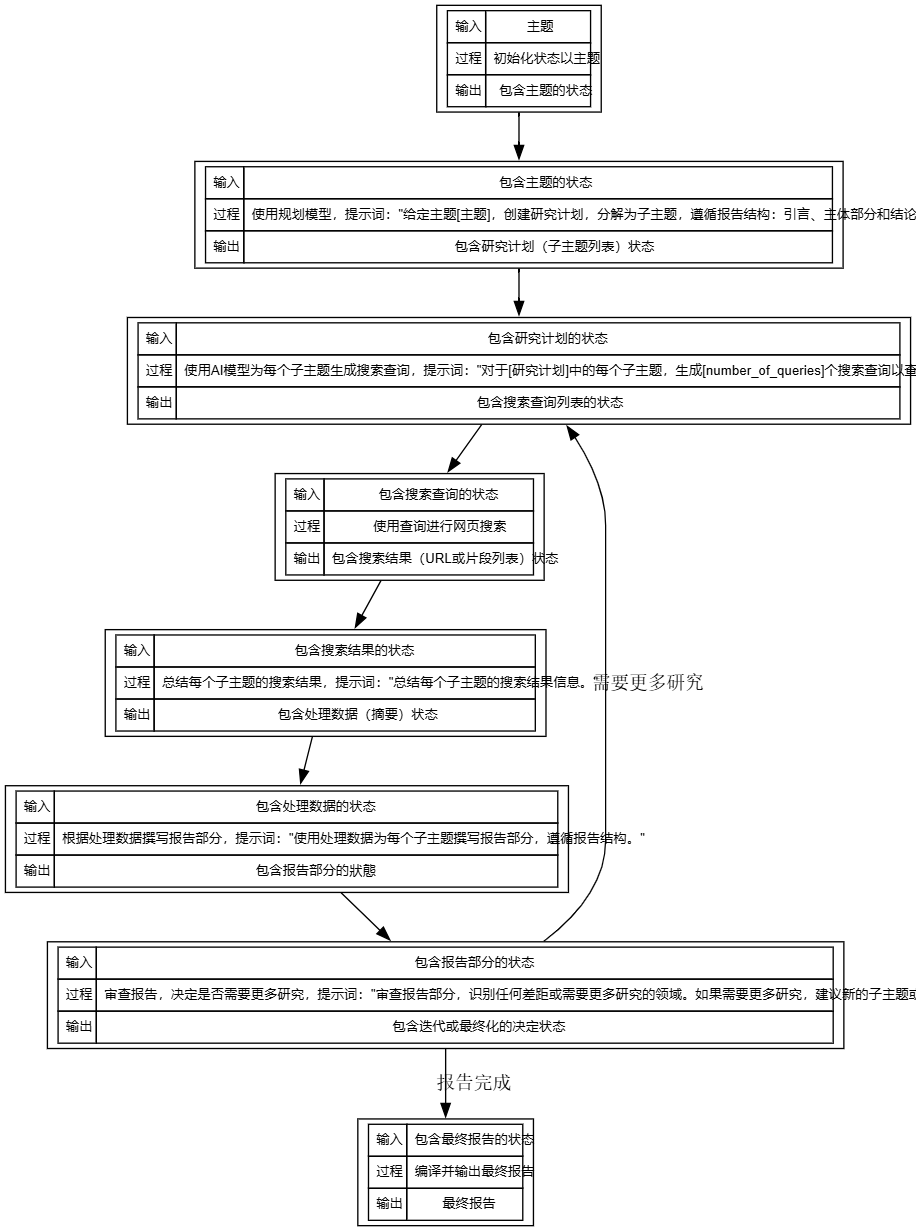
1.初期化(スタート)
- 輸入 「Fireworks、Together.ai、Groqを中心としたAI推論市場の概要」など、ユーザー提供のトピック。
- 成り行き システムは状態を初期化し、AIモデルを呼び出すことなく、トピックを状態の一部として保存する。
- 輸出 以降のステップで使用するために、トピックのステータスを含む。
2.プランニング
- 輸入 トピックのステータスを含む。
- 成り行き OpenAIのデフォルトのo3-miniやGroqのdeepseek-r1-distill-llama-70bのような計画モデルを使って研究計画を作成しなさい。プロンプトワードは、"トピック(テーマ)が与えられたら、レポートの構造(序論、本文セクション、結論)に従った、サブトピックに分かれた研究計画を作成する "です。
- 輸出 例:「1.AI推論市場の定義、2.花火の役割、3.AI推論市場の定義、4.AI推論市場の定義、5.AI推論市場の定義、6.AI推論市場の定義、7.AI推論市場の定義」。 一緒に.aiのケーススタディ」など。
- キュー・ワードの出所 :おそらくconfiguration.pyのDEFAULT_REPORT_STRUCTUREから、構成は序論、本文、結論からなり、本文では主要な概念、定義、例をカバーする必要がある。
3.クエリー生成
- 輸入 研究プログラムの状況を掲載。
- 成り行き AIモデルを使用して、各サブトピックに対して検索クエリを生成する。デフォルトの number_of_queries は 2 です。
- 輸出 AI Reasoning Market Definition 2023」、「Fireworks AI Service Cases」などの検索クエリリストを含むステータスを更新しました。
- キュー・ワードの出所 プロジェクトのドキュメントには、プロンプトの単語が生成されるクエリの一般的な形式であると仮定して、クエリの数を設定できることが記載されています。
4.ウェブ検索
- 輸入 検索クエリのステータスを含む。
- 成り行き 検索API(例えばデフォルトのTavily)を使って各クエリを実行し、ウェブ検索結果を得る。AIモデルの呼び出しはなく、ツールから直接実行される。
- 輸出 : ステータスは、Tavilyによって返されたページの要約のような検索結果(URLまたはスニペットリスト)を含むように更新されます。
- 技術的詳細 TAVILY_API_KEY を設定する必要があります。
5.データ処理
- 輸入 検索結果のステータスを含む。
- 成り行き AIモデルを使って、各サブトピックの検索結果を要約する。
- 輸出 例:"AI推論市場定義:リアルタイム予測にAIモデルを使用する業界を指し、2023年までに急成長"
- キュー・ワードの出所 レポート作成のプロジェクト目標に基づく、要約タスクの一般的なプロンプトの前提条件。
6.レポート作成
- 輸入 処理されたデータのステータスを含む。
- 成り行き ライティング・モデルを使用する(例:デフォルトの人間工学)。 クロード 3.5 ソネット) "加工されたデータを使って、レポートの構成にしたがって、サブテーマごとにレポートのセクションを書きなさい "という促しの言葉に従って、加工されたデータをもとにレポートのセクションを書きなさい。
- 輸出 例えば、"はじめに:AI推論市場はAI導入のための重要な分野である。""本文セクション1:Fireworksは効率的な推論サービスを提供し、クラウド展開を含む事例を紹介する。"など。
- キュー・ワードの出所 DEFAULT_REPORT_STRUCTUREと連動して、報告書には概要、主要概念、例を含める必要がある。
7.反省
- 輸入 レポートセクションのステータスを含む。
- 成り行き 報告書のセクションを見直し、ギャップやさらなる調査が必要な分野を特定する。さらに調査が必要な場合は、新しいサブトピックやクエリーを提案してください。"
- 輸出 : ステータスが更新され、反復の決定(さらなる調査が必要など)または最終報告が含まれる。反復が必要な場合は、新しいサブトピックまたはクエリの提案を出力。
- キュー・ワードの出所 プロジェクト文書から、反省と反復がサポートされていることに言及する。
8.出力
- 輸入 : 最終レポートのステータス (Reflection がレポートを完了したと判断した場合) が含まれます。
- 成り行き すべてのレポートセクションをコンパイルし、AIモデルを呼び出すことなく、Markdown形式で最終レポートを作成します。
- 輸出 最終報告書(ユーザーがダウンロードまたは閲覧できる完全なMarkdown文書など)。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません