Chonkie: 軽量なRAGテキストチャンキングライブラリ

はじめに
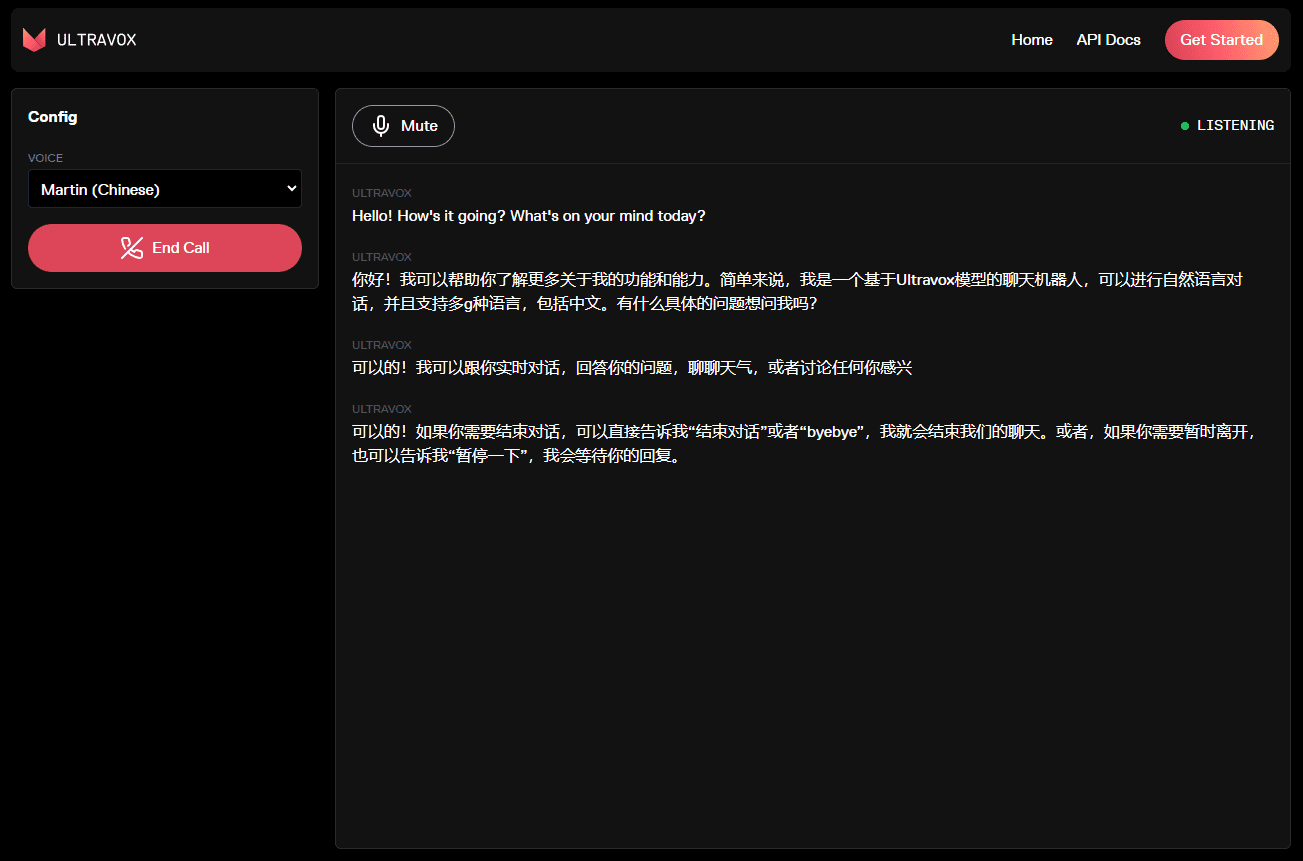
Chonkieは軽量で効率的なRAG(Retrieval-Augmented Generation)テキストチャンキングライブラリで、開発者が素早く簡単にテキストをチャンキングできるように設計されています。トークン、単語、文、意味的類似度に基づくチャンキングなど、様々なチャンキング手法をサポートしており、テキスト処理や自然言語処理の幅広いタスクに適しています。デフォルトのインストールに必要な容量はわずか21MB(他の類似製品は80~171MB) 主要なチャンカーをすべてサポート。
機能一覧
- トーケンチャンカーテキストを固定サイズのマーカーブロックに分割します。
- ワードチャンカーテキストを単語からチャンクに分ける。
- センテンスチャンカー文章をチャンクに分ける。
- セマンティック・チャンカー意味的類似性に基づいてテキストをチャンクに分割する。
- SDPMChunkerセマンティックダブルマージアプローチによるテキストのセグメンテーション。
ヘルプの使用
取り付け
チョンキーをインストールするには、以下のコマンドを実行するだけだ:
pip install chonkie
Chonkieはデフォルトのインストールを最小限にするという原則に従い、必要に応じて特定のチャンカーをインストールするか、依存関係を考慮したくない場合はすべてのチャンカーをインストールすることを推奨している(推奨されていない)。
pip install chonkie[all]
利用する
ここでは、すぐに始められるように基本的な例を示します:
- まず、目的のチャンカーをインポートする:
from chonkie import TokenChunker - お気に入りのトークナイザー・ライブラリをインポートします(AutoTokenizers、TikToken、AutoTikTokenizerがサポートされています):
from tokenizers import Tokenizer tokenizer = Tokenizer.from_pretrained("gpt2") - チャンカーを初期化する:
chunker = TokenChunker(tokenizer) - テキストのチャンキング
chunks = chunker("Woah! Chonkie, the chunking library is so cool! I love the tiny hippo hehe.") - チャンキング結果にアクセスする:
for chunk in chunks: print(f"Chunk: {chunk.text}") print(f"Tokens: {chunk.token_count}")
支援方法
Chonkieは、独自のチャンクを効率的に作成・配布するための幅広いチャンカーを提供しています。 ラグ アプリケーションはテキストを分割する。以下は、利用可能なチャンカーの概要です:
- トーケンチャンカーテキストを固定サイズのマーカーブロックに分割します。
- ワードチャンカーテキストを単語からチャンクに分ける。
- センテンスチャンカー文章をチャンクに分ける。
- セマンティック・チャンカー意味的類似性に基づいてテキストをチャンクに分割する。
- SDPMChunkerセマンティックダブルマージアプローチによるテキストのセグメンテーション。
ベンチマーキング
チョンキーはいくつかのベンチマークで好成績を収めている:
- サイズデフォルトのインストールはわずか9.7MB(他のバージョンは80~171MB)で、セマンティック・チャンキングを含めても競合他社より軽い。
- テンポタグ・チャンキングは最も遅い方法より33倍速く、センテン・チャンキングは競合より2倍近く速く、セマンティック・チャンキングは他の方法より2.5倍速い。
詳しい操作手順
- インストーラChonkieと必要なタガーライブラリをpipでインストールします。
- インポートライブラリPythonスクリプトにChonkieとタグ付けライブラリをインポートしてください。
- チャンカーの初期化適切なチャンカーを選択し、初期化する。
- チャンクドテキスト初期化されたチャンカーを使ってテキストをチャンクする。
- 結果チャンキングの結果を繰り返し、さらなる処理や分析を行う。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません