
落とし穴ガイド:淘宝網DeepSeek R1インストールパッケージ有料アップセル?無料でローカル展開を教える(ワンクリックインストーラ付き)

最近、タオバオのプラットフォームで ディープシーク インストール・パッケージの販売という現象は、広く懸念を呼んでいる。この無料かつオープンソースのAIモデルから利益を得ている企業があることは驚きである。これは、DeepSeekモデルが生み出している地域展開ブームの反映でもある。

TaobaoやJinduoduoなどのeコマースプラットフォームで「DeepSeek」を検索すると、インストールパッケージ、キューワードパッケージ、チュートリアルなど、無料で入手できるはずのリソースを販売している多くの商人を見つけることができます。 一部の販売者は、DeepSeek関連のチュートリアルをマークアップした価格で販売していますが、実際には、ユーザは検索エンジンを使用するだけで、多数の無料ダウンロードリンクを簡単に見つけることができます。
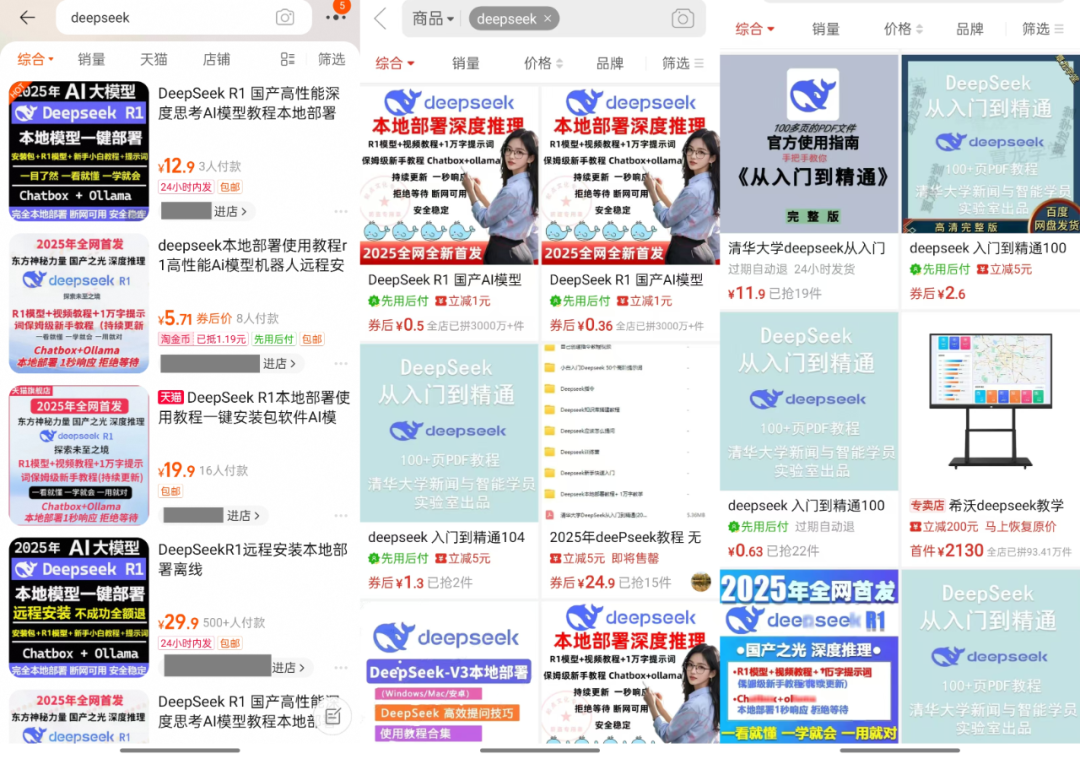
では、これらのリソースはいくらで売られているのだろうか? インストーラー + チュートリアル + ヒント」のパッケージ価格は、通常10ドルから30ドルの範囲であることが観察されており、ほとんどの商人はまた、一定の顧客サービスのサポートを提供しています。 その中でも、商品の多くは数百部、いくつかの人気商品、さらにはスケールを支払うためにдостигают千人を販売されている。 もっと驚いたことに、価格100ドルのソフトウェアパッケージやチュートリアルだけでなく、22人が購入することを選択します。

このように、情報格差がもたらすビジネスチャンスは明らかだ。
この記事では、DeepSeek モデルをコストをかけずにローカルに展開する方法を説明します。 その前に、ローカル展開の必要性を簡単に分析します。
DeepSeek-R1をローカルに展開することを選択する理由
ディープシーク-R1 モデルは、現在利用可能な推論モデルの中ではトップクラスの性能とは言えないかもしれないが、市場で非常に求められているオプションであることは間違いない。 しかし、公式またはサードパーティのホスティング・プラットフォームのサービスを直接利用する場合、ユーザーはしばしばサーバーの混雑に見舞われる。
ローカル展開モデルは、この問題を効果的に回避することができる。 つまり、ローカルデプロイメントとは、クラウドAPIやオンラインサービスに依存するのではなく、ユーザー自身のデバイスにAIモデルをインストールすることを意味する。 一般的なローカル・デプロイメント方法には、以下のようなものがある:
- 軽量局所推論Llama.cpp、Whisper、GGUF形式のモデルなど。
- サーバー/ワークステーションの展開NVIDIA RTX 4090、A100などの高性能GPUやTPUで大規模モデルを実行します。
- プライベート・クラウド/イントラネット・サーバー例えば、TensorRT、ONNX Runtime、vLLMなどのツールを使って、オンプレミスのサーバーにデプロイする。
- エッジデバイスの展開Jetson NanoやRaspberry Piなどの組み込みシステムやIoTデバイス上でAIモデルを実行します。
異なる展開方法は、異なるアプリケーションシナリオに適している。 ローカル展開技術は、いくつかの分野で独自の価値を示してきた:
- オンプレミスAIアプリケーションプライベートチャットボット、文書分析システムなどの構築
- 科学研究計算生物医学、物理シミュレーション、その他の分野におけるデータ解析やモデルトレーニングへの応用。
- オフラインAI機能ネットワークレス環境で音声認識、OCR、画像処理機能を提供。
- セキュリティ監査と監視法律、金融、その他の業界におけるコンプライアンス分析を支援する。
この記事では、幅広い個人ユーザーにとって最も適切な展開オプションである、軽量局所推論に焦点を当てる。
ローカル展開の利点
ビジーサーバー」問題の根本的な原因を解決するだけでなく、ローカル展開には多くの利点がある:
- データプライバシーとセキュリティAIモデルをローカルに展開することで、機密データをクラウドにアップロードする必要がなくなり、データ漏えいのリスクを効果的に防ぐことができます。 これは、金融、ヘルスケア、法務など、高レベルのデータ・セキュリティが求められる業界にとって非常に重要です。 さらに、ローカルでの展開は、企業や組織が中国のデータ・セキュリティ法やEUのGDPRなどのデータ・コンプライアンス要件を満たすのにも役立つ。
- 低レイテンシーとリアルタイム性能すべての計算がネットワークからの要求なしにローカルで実行されるため、推論速度はすべてローカルデバイスの計算性能に依存します。 そのため、デバイスの性能さえ十分であれば、ユーザーは優れたリアルタイムレスポンスを得ることができ、音声認識、自動運転、工業検査など、リアルタイム性が要求されるアプリケーションシナリオに最適なローカル展開が可能になります。
- 長期的な費用対効果ネイティブなデプロイメントにより、APIサブスクリプション料金が不要となり、一度デプロイすれば長期間の使用が可能になります。 性能要件が低いアプリケーションでは、INT 8ビットや4ビット量子化モデルなどの軽量モデルを展開することで、ハードウェア・コストを削減することもできます。
- オフライン可用性AIモデルは、ネットワーク接続がない場合でも使用できるため、エッジコンピューティング、オフラインオフィス、リモート環境などのシナリオに適している。 また、オフラインで実行できるため、重要なサービスの継続性が確保され、ネットワークの切断によるビジネスの中断を回避できる。
- 高いカスタマイズ性と制御性ローカルに展開することで、ユーザは特定のビジネスニーズに合わせてモデルを微調整し、最適化することができます。 たとえば、DeepSeek-R1 モデルは、制限のないバージョンの deepseek-r1-abliterated を含め、数多くの微調整および蒸留バージョンを生み出してきました。 さらに、ローカルでの展開は、サードパーティのポリシー変更の影響を受けないため、より大きなコントロールを提供し、APIの価格調整やアクセス制限などの潜在的なリスクを回避することができる。
ローカル展開の限界
ローカル展開の利点は大きいが、その限界は無視できない。
- ハードウェア・コストの投入個々のユーザーは、大きなパラメータを持つモデルをローカル機器で実行することが困難な場合が多く、一方、小さなパラメータを持つモデルはパフォーマンスが低下する可能性があります。 そのため、ユーザーはハードウェアのコストとモデルの性能をトレードオフする必要があります。 高性能なモデルを追求するためには、必然的にハードウェアへの追加投資が必要になります。
- 大規模タスク処理能力大規模なデータ処理が必要なタスクを効率的にこなすには、サーバーレベルのハードウェアサポートが必要になることが多い。 パーソナル・デバイスは、処理能力において自然なボトルネックを持っています。
- 技術的閾値ウェブページにアクセスしたり、APIを設定するだけで利用できるクラウドサービスの利便性に比べ、ローカルでの展開には技術的な障壁がある。 ユーザーがモデルをさらに微調整する必要があれば、デプロイはさらに難しくなる。 ありがたいことに、ローカル展開の技術的障壁は徐々に低くなっている。
- 維持費モデルや関連ツールのアップグレードや反復は、環境設定に問題を引き起こす可能性があり、ユーザーはメンテナンスと問題解決に時間と労力を費やす必要があります。
したがって、ユーザーの実際の状況に応じて、ローカル展開かオンラインモデルかを選択する必要がある。 以下は、ローカル展開が適用できるシナリオと適用できないシナリオを簡単にまとめたものである:
- ローカル展開に適したシナリオ高いプライバシー要件、低遅延要件、長期使用(例:企業向けAIアシスタント、法的分析システムなど)。
- ローカル展開に適さないシナリオ短期間のテスト検証、高い演算要件、非常に大規模なモデル(例えば70B以上のパラメータレベル)への依存。
クラウド上の無料サーバーを利用したプライベート・デプロイも良い方法であり、ずいぶん前から推奨されているが、一定の技術的基盤が必要である:無料のGPUパワーでDeepSeek-R1オープンソースモデルをオンライン展開
DeepSeek-R1のローカル展開の実際
DeepSeek-R1 をローカルに展開する方法は多数ありますが、この記事では、以下の 2 つの簡単な方法を紹介します。 オーラマ LM Studio を使用したデプロイメント方法とゼロコードデプロイメントシナリオ。
オプション 1: Ollama ベースの DeepSeek-R1 の展開
Ollamaは、ネイティブ言語モデルのデプロイと実行のための主要なフレームワークです。 Ollamaは軽量で拡張性が高く、MetaのLlamaモデルファミリーがリリースされて以来、注目されるようになった。 その名前とは裏腹に、Ollamaプロジェクトはコミュニティ主導であり、MetaやLlamaモデルの開発とは直接関係ありません。

Ollamaプロジェクトは急速に成長しており、サポートするモデルやエコシステムの種類も急速に拡大している。
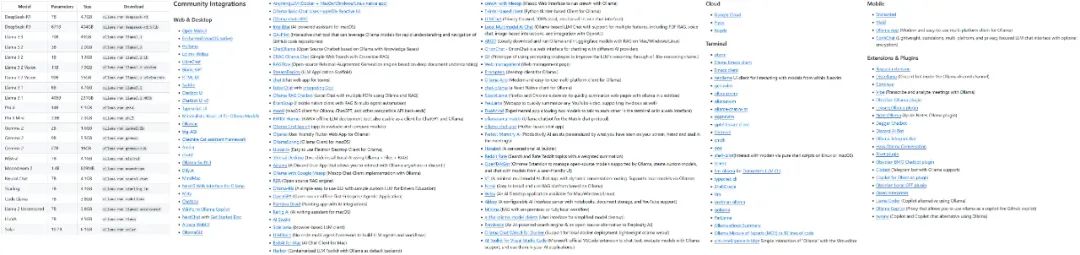
Ollamaがサポートするモデルとエコロジーの一部
Ollamaを使用する最初のステップは、Ollamaソフトウェアをダウンロードしてインストールすることです。 Ollamaの公式ダウンロードページにアクセスし、お使いのOSに合ったバージョンを選択してください。
ダウンロード:https://ollama.com/download
Ollamaをインストールしたら、デバイスのAIモデルを設定する必要がある。 ここではDeepSeek-R1を例にとって説明します。 Ollamaのウェブサイトにあるモデル・ライブラリにアクセスし、サポートされているモデルとバージョンを参照してください:
https://ollama.com/search
DeepSeek-R1は、オープンソースのモデルLlamaとQwenに基づいて微調整、抽出、定量化されたバージョンを含む、1.5Bから67BまでのスケールのOllamaモデルライブラリの29の異なるバージョンで利用可能です。
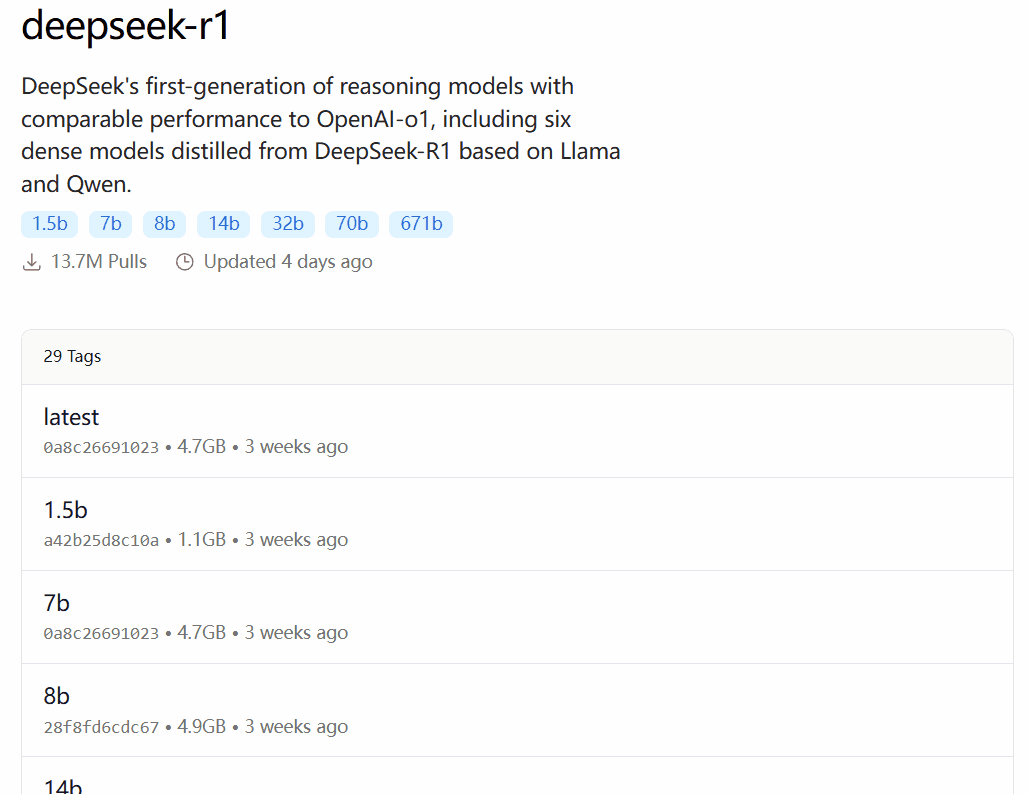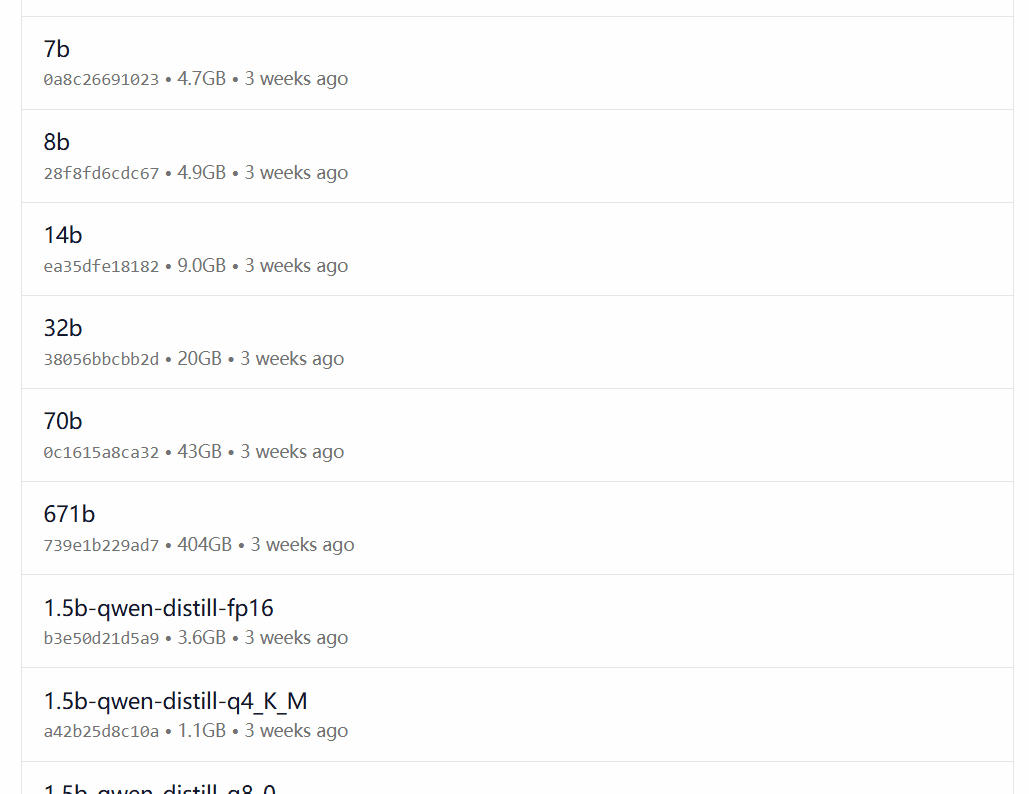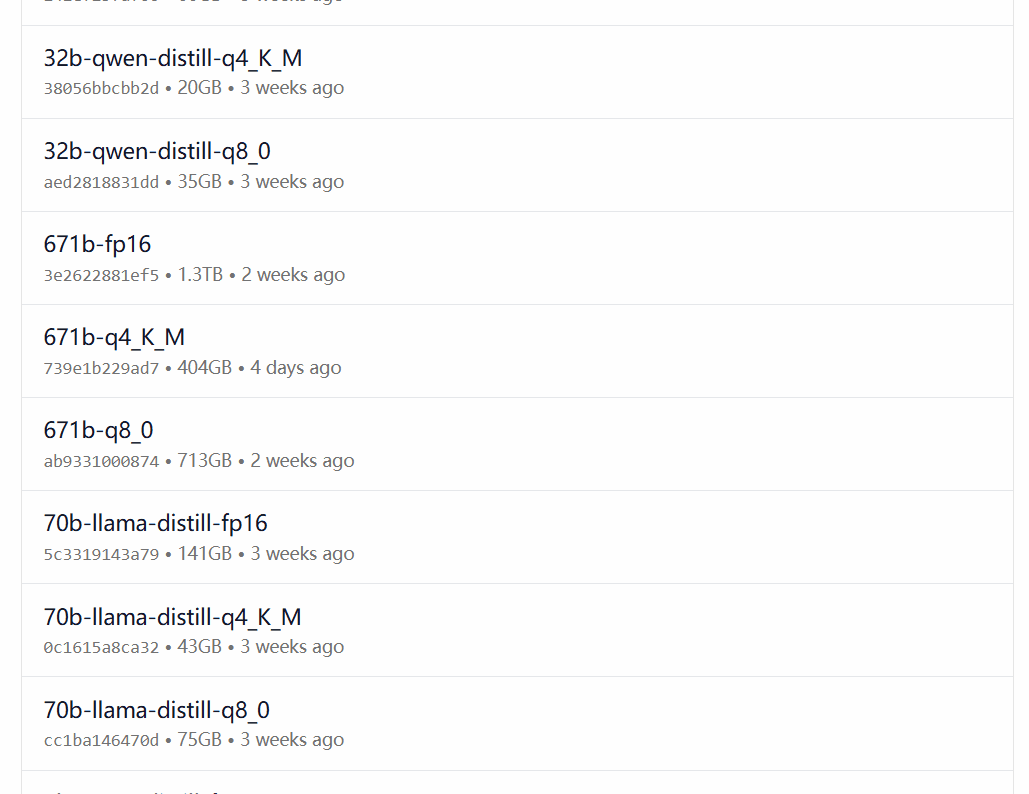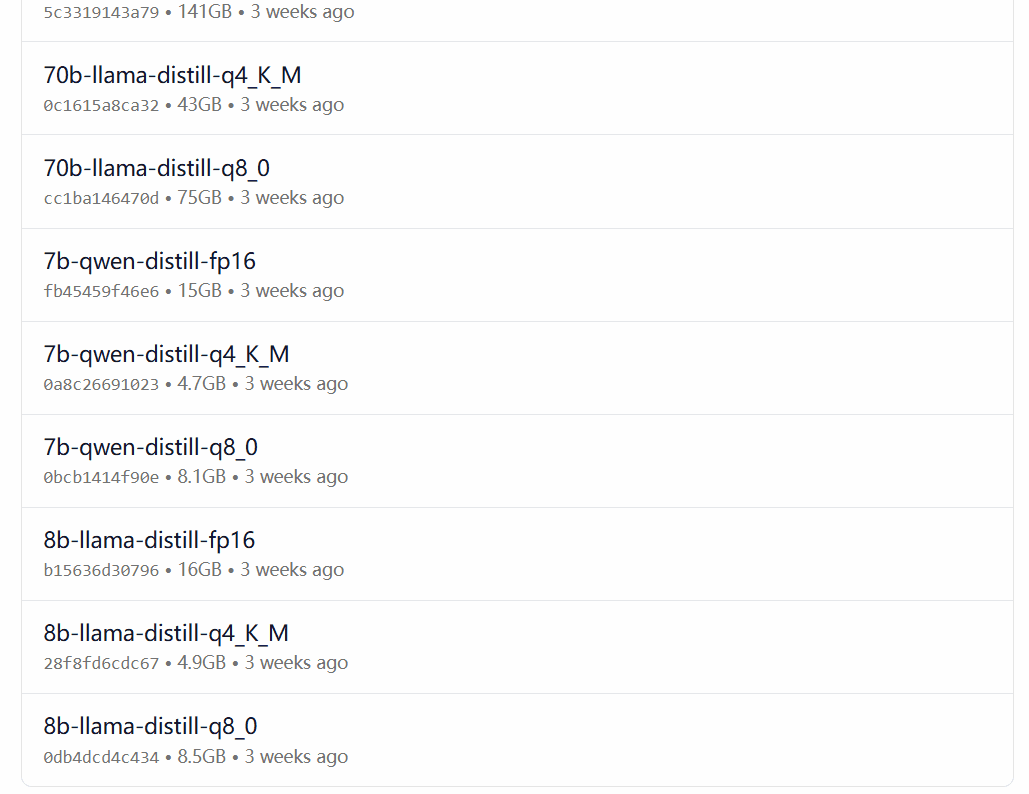
どのバージョンを選択するかは、ユーザーのハードウェア構成に依存します。 dev.to開発者コミュニティのAvnishは、DeepSeek-R1のさまざまなサイズのバージョンのハードウェア要件をまとめた記事を書いています:
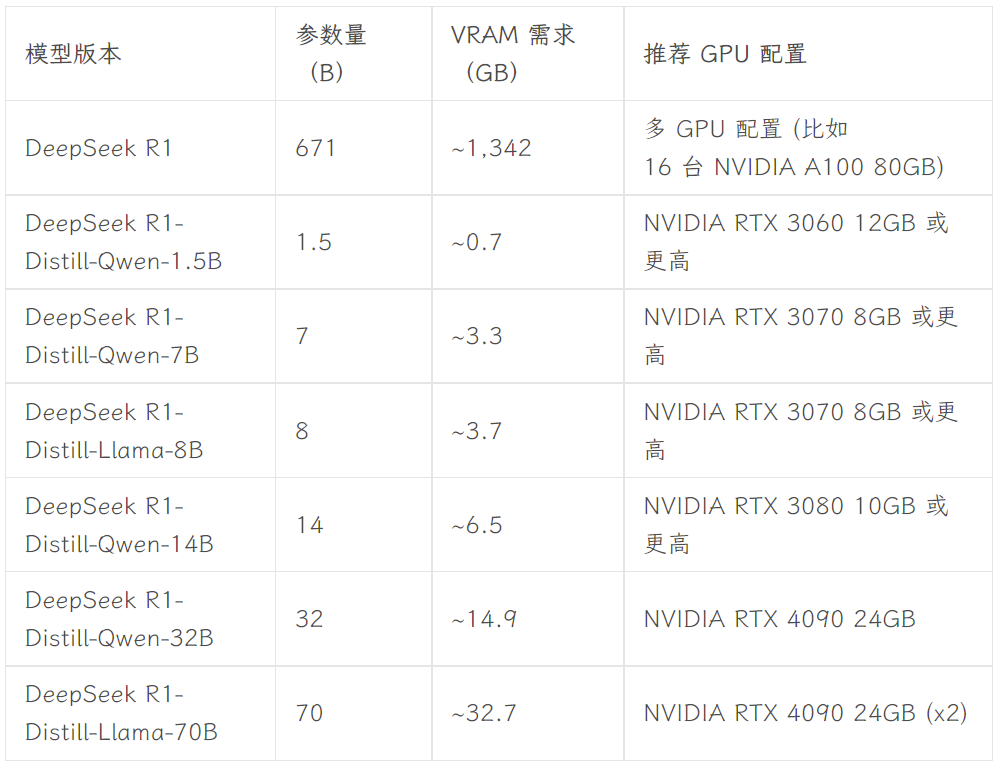
画像出典:https://dev.to/askyt/deepseek-r1-architecture-training-local-deployment-and-hardware-requirements-3mf8
この記事では、バージョン8Bを例にして説明します。 端末を開き、以下のコマンドを実行する:
ollama run deepseek-r1:8b
次に、モデルのダウンロードが終わるのを待つだけです。(OllamaはHugging Faceから直接モデルをダウンロードすることもサポートしています。ollama run hf.co/{ユーザー名}/{ライブラリ}:{量子化バージョン}というコマンドを使います。例えば、ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0)。

モデルをダウンロードしたら、ターミナルで 8B バージョンの DeepSeek-R1 と会話できます。

しかし、この種の端末対話は、一般ユーザーにとって直感的で便利なものではない。 したがって、ユーザーフレンドリーなグラフィカル・インターフェースのフロントエンドが必要となる。 以下のような幅広いフロントエンドがあります。 WebUIを開く のようなものを得る。 チャットGPT または チャットボックス およびその他のデスクトップ・アプリケーション。 その他のフロントエンド・オプションについては、Ollamaの公式ドキュメントを参照されたい:
https://github.com/ollama/ollama
- WebUIを開く
Open WebUIを選択した場合は、ターミナルで以下の2行のコードを実行するだけだ:
Open WebUIをインストールします:
pip install open-webui
Open WebUI サービスを実行します:
open-webui serve
その後、ブラウザでhttp://localhost:8080、ChatGPTのようなWebインタフェースを体験してください。 Open WebUIのモデル・リストには、DeepSeek-R1 7Bおよび8Bバージョンや、Llama 3.1 8B、Llama 3.2 3B、Phi 4、Qwen 2.5 Coderなど、ローカルのOllamaによって設定された複数のモデルが表示されます。 テストには、DeepSeek-R1 8B モデルが選択されています:

- チャットボックス
スタンドアロンのデスクトップ・アプリケーションを使いたい場合は、Chatboxなどのツールをご検討ください。 設定手順も同様に簡単で、Chatboxアプリケーションのダウンロードとインストールから始まります:
https://chatboxai.app/zh
Chatboxを起動後、"Settings "インターフェイスに入り、"Model Provider "でOLLAMA APIを選択し、"Model "欄で使用したいモデルを選択します。次に "Model "欄で使用したいモデルを選択し、コンテキストメッセージの最大数や温度などのパラメータを必要に応じて設定します(デフォルトのままでも構いません)。

設定後は、ローカルに配置した DeepSeek-R1 モデルと Chatbox でスムーズに会話できます。 ただし、テスト結果によると、複雑なコマンドを処理する場合、DeepSeek-R1 7B モデルのパフォーマンスがわずかに低下します。 このことは、個人ユーザは通常、ローカル・デバイス上では比較的限られた性能のモデルしか実行できないという前出の指摘を裏付けるものです。 しかし、ハードウェア技術が進化し続けるにつれて、個人ユーザーによる大パラメータモデルのローカル使用に対する障壁が将来的にさらに低くなることは予想され、その日はそう遠くないかもしれない。

**Open WebUIとChatboxの両方が、APIを介してDeepSeekのモデル、ChatGPT、およびClaudeへのアクセスをサポートしています、 ジェミニ などのビジネスモデルがある。 ユーザーはAIツールを日常的に使用するためのフロントエンド・インターフェースとして使用することができる。 さらに、Ollamaで構成されたモデルは、ObsidianやCivic Notesのようなノート作成アプリケーションなど、他のツールに統合することもできる。
オプション 2: LM Studio を使用して、コードなしで DeepSeek-R1 をデプロイする
コマンドライン操作やコードに不慣れなユーザは、LM Studio を使用することで、コードなしで DeepSeek-R1 を導入できます。 まず、LM Studio の公式ダウンロードページから、お使いのオペレーティングシステムに合ったプログラムをダウンロードしてください:
https://lmstudio.ai
インストールが完了したら、LM Studioを起動します。 My Models "タブで、モデルのローカルストレージフォルダを設定します:

次に、Hugging Faceから必要な言語モデルファイルをダウンロードし、指定されたディレクトリ構造に従って上記のフォルダに配置します(LM Studioにはモデル検索機能が組み込まれていますが、実際にはうまく動作しません)。 なお、モデルファイルは.gguf形式でダウンロードする必要があります。 例えば アンクロス 組織が提供するDeepSeek-R1モデルのコレクション:
https://huggingface.co/collections/unsloth/deepseek-r1-all-versions-678e1c48f5d2fce87892ace5
本稿では、ハードウェア構成を考慮し、Qwen モデルのファインチューニングに基づく DeepSeek-R1 Distillate バージョン(パラメータ番号 14B)、および 4 ビット量子化バージョン(DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf)を選択します。
ダウンロードが完了したら、以下のディレクトリ構造に従って、モデルファイルをあらかじめ設定したフォルダに配置します:
モデルフォルダ /unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf
最後に、LM Studio を開き、アプリケーションインターフェイスの上部にあるロードしたいモデルを選択し、ローカルモデルと会話します。

LMスタジオの最大の利点は、完全にゼロコードであることです。ターミナルを使ったり、コードを書いたりする必要がなく、ソフトウェアをインストールしてフォルダを設定するだけで、非常にユーザーフレンドリーです。
概要
このチュートリアルでは、DeepSeek-R1 のローカル展開の基本的なレベルのみを説明します。 この人気モデルをローカルのワークフローに深く統合するには、システムプロンプトの設定やより高度なモデルの微調整など、より詳細な設定が必要です、 ラグ 統合、検索機能、マルチモーダル機能、ツール呼び出し機能。 同時に、AIに特化したハードウェアや小型モデルの技術が進化し続けることで、大型モデルをローカルに展開する障壁は今後も下がっていくと思います。 この記事を読んで、あなたはDeepSeek-R1モデルを自分で展開してみようと思いますか?
添付のDeepSeek R1+OpenwebUIワンクリックインストールパッケージ
Sword27 が提供するワンクリックインストールパッケージは、DeepSeek 専用に以下の機能を統合しています。 WebUIを開く
ワンクリック実行のDeepSeekローカル展開、使用するために解凍 サポート1.5b 7b 8b 14b 32b、2Gグラフィックカードの最小サポート
設置プロセス
1.AI環境ダウンロード:https://pan.quark.cn/s/1b1ad88c7244
2.インストールパッケージのダウンロード:https://pan.quark.cn/s/7ec8d85b2f95
元の記事で助けを得る: https://www.jian27.com/html/1396.html
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません