QwQ-32B大型モデルのローカル展開:PCのための簡単ガイド

人工知能(AI)モデリングの分野は常に驚きに満ちており、あらゆる技術的なブレークスルーが業界の神経に触れることがある。最近、アリババのQwQチームは最新の推論モデル「QwQ-32B」を早朝に発表し、再び多くの注目を集めた。

公式リリースによるとQwQ-32Bは、わずか320億のパラメータースケールを持つ推論モデルである。それなのに、彼らはライバルになれると主張している。 ディープシーク-R1 など、業界をリードする最先端モデルを発表した。 公式ブログへのリンク、ハギング・フェイスのモデル・ライブラリー、モデルのダウンロード、オンライン・デモ、ユーザーが製品について詳しく知り、体験するためのウェブサイトなど、この発表は瞬く間に技術コミュニティを燃え上がらせる爆弾発言となった。
リリース情報は簡潔なものだが、その裏にある技術力は単純なものではない。DeepSeek-R1に匹敵する320億のパラメータ」というフレーズは、一般的にモデルのパラメータ数が多いほど性能が高くなる傾向があることを知っていれば、十分に印象的なものだが、それは同時にコンピューティング・リソースの需要が高くなることも意味する。 QwQ-32B 少ないパラメータでメガモデルに匹敵する性能を実現したことは、間違いなく大きなブレークスルーであり、技術愛好家や専門家の強い関心を呼んでいる。
QwQ-32Bの性能をより直感的に示すため、公式ベンチマークテスト表が同時に公開されました。ベンチマークは、AIモデルの能力を評価する重要な手段であり、あらかじめ設定された標準化された一連のデータセットでテストすることにより、さまざまなタスクに対するモデルの性能を測定し、ユーザーに客観的な性能基準を提供します。

このベンチマーク・チャートから、以下の重要なポイントを素早く把握することができる:
- 驚異的な拡散スピード: モデルリリース情報достига́тьは、わずか12時間で169万人以上に読まれ、高性能AIモデルに対する市場の緊急需要とQwQ-32Bへの期待の高さを十分に反映している。
- 素晴らしいパフォーマンスだ: わずか320億個のパラメータを持つQwQ-32Bは、6,710億個のパラメータを持つフルパラメータバージョンのDeepSeek-R1とベンチマークテストで競合することができ、驚くべきエネルギー効率比を示しています。 小さなモデルが大きなモデルを凌駕するというこの現象は、モデルの性能とパラメータサイズの関係に関する従来の認識を間違いなく覆すものです。
- 同クラスの蒸留モデルを凌駕: QwQ-32B は、DeepSeek-R1 の 32B 蒸留バージョンを大幅に上回る。 ディスティレーションとは、より小さなモデルを学習することで、より大きなモデルの挙動を模倣し、性能を維持しながら計算コストを削減することを目的としたモデル圧縮手法です。 QwQ-32B が 32B 蒸留モデルを上回るという事実は、QwQ-32B のアーキテクチャーと学習手法が高度であることをさらに示しています。
- 多次元パフォーマンス・リーダーシップ: QwQ-32Bは、OpenAIのクローズドソースモデルであるo1-miniを、いくつかのベンチマークにおいて上回っている。 これは、QwQ-32Bが、汎用的な能力という点で、トップクラスのクローズドソースモデルと競合できることを示している。
特に興味深いのは、わずか320億のパラメーターを持つQwQ-32Bが、20倍以上のパラメーター数を持つ巨大モデルを凌駕することができるという事実であり、AI技術における新たな飛躍を表している。 さらにエキサイティングなことに、ユーザーはRTX3090またはRTX4090クラスのコンシューマー向けグラフィックカードで、QwQ-32Bの定量化バージョンをローカルで簡単に実行できるようになった。 ローカルでの展開により、利用への障壁が低くなるだけでなく、データ・セキュリティやパーソナライズされたアプリケーションの可能性が広がります。グラフィックカードの性能が低いユーザーは、推奨されるクラウド展開ソリューションで始めることができます:無料のGPUパワーでDeepSeek-R1オープンソースモデルをオンライン展開または、無料のAPIの利用を直接申し込む。アリババ(火山) は1日100万トークンを提供し(180日間)、そして アカシ APIは登録なしで直接無料で利用できる。
ディープシークはもはや一本調子ではない。
QwQ-32Bがこのような強い競争力を示したことで、オープンエイの既存製品(200ドルのProバージョンと20ドルのPlusバージョン)は、価格/性能の面で深刻な挑戦に直面している。 QwQ-32Bは、特にOpenAIのモデルが時折見せるパフォーマンスの変動を考慮すると、市場に考えさせるものを与えた。 とはいえ、OpenAIにはAI分野における深い歴史と広範なエコシステムがあり、モデルの微調整や特定分野でのアプリケーションの最適化においては、依然として優位性があるかもしれない。 しかし、QwQ-32Bのリリースは、間違いなく市場の当初のパターンを打ち破り、すべてのプレーヤーに自らの技術的優位性と市場戦略の再検討を迫っている。
QwQ-32Bの実戦的な能力をより完全に評価するためには、現地に設置し、詳細なテストを行う必要がある。特に、現地での動作環境における推論性能と「IQ」レベルを検証する必要がある。
幸いなことに オーラマ Ollamaのようなツールの登場により、大規模な言語モデルをパーソナル・コンピュータ上でローカルに展開し、実行することが非常に簡単になりました。 オープンソースの軽量モデル実行フレームワークであるOllamaは、大規模なローカルモデルのデプロイと管理のプロセスを大幅に簡素化します。
Ollamaはその効率性と使いやすさで定評がある。 QwQ-32Bのリリース直後、Ollamaはすぐにこのモデルのサポートを発表し、ユーザーが最新のAI技術を体験するための障壁をさらに低くし、誰もがQwQ-32Bのパワーを簡単に使い始めることができるようにしました。
1.Ollamaのインストールと操作
まず、ollama.com の Ollama 公式ウェブサイトにアクセスし、「ダウンロード」ボタンをクリックして、お使いのオペレーティング・システムに適したインストール・パッケージをダウンロードしてください。
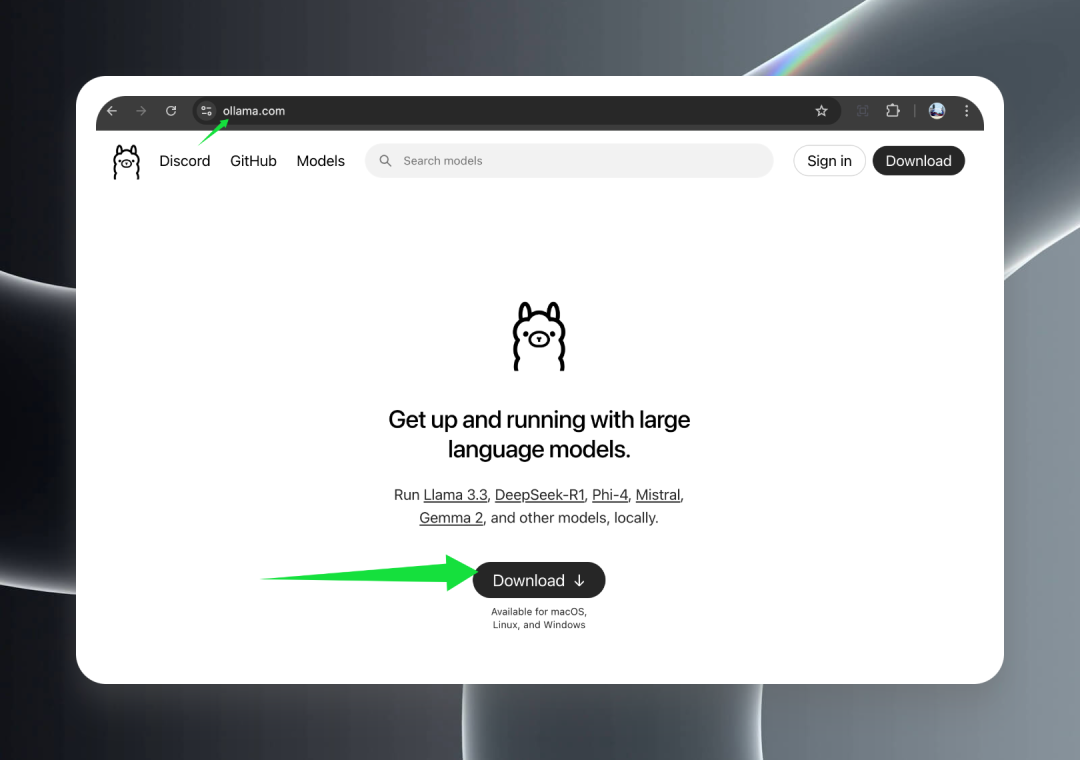
Ollamaは、macOS(IntelおよびApple Silicon)、Windows、Linuxを含むすべての主要なオペレーティングシステムをフルサポートしており、QwQ-32Bモデルがすべてのプラットフォームで簡単に使用できることを保証します。
ダウンロードが完了したら、インストーラーをダブルクリックし、ウィザードに従ってインストール作業を完了させてください。 インストールが完了すると、Windowsではタスクバーのトレイに、macOSではメニューバーに、かわいいアルパカのアイコンが表示されます。
2.QwQ-32B型ダウンロード
Ollamaのインストールと起動に成功したら、QwQ-32Bモデルのダウンロードを開始します。

でOllamaクライアントを開く。 モデル モデルのページでは、QwQ-32Bモデルがすぐにホットモデルリストの上位に上がっていることがわかりますが、これは人気の証です。 qwq "モデルのエントリーを見つけ、それをクリックしてモデルの詳細ページに移動してください。 詳細ページで、赤枠で強調表示されているコマンドをコピーしてください。
ローカルターミナル(macOS/Linux)またはコマンドプロンプト(Windows)を開く。
ターミナルまたはコマンドプロンプトで、以下のコマンドを貼り付けて実行する:ollama run qwq
ollama run qwq
Ollamaは自動的にクラウドからQwQ-32Bモデルファイルのダウンロードを開始し、ダウンロードが完了すると自動的にモデルランタイム環境を起動します。
特筆すべきはモデルのダウンロード・プロセスでは、ユーザー側でネットワーク設定を追加する必要はないようだ。 これは間違いなく、国内ユーザーにとって非常に親切な機能だ。 何しろ、20GB近いサイズのモデルファイルは、ダウンロード速度が遅すぎたり、特別なネットワーク環境が必要だったりすると、ユーザー体験を大きく損なうことになる。
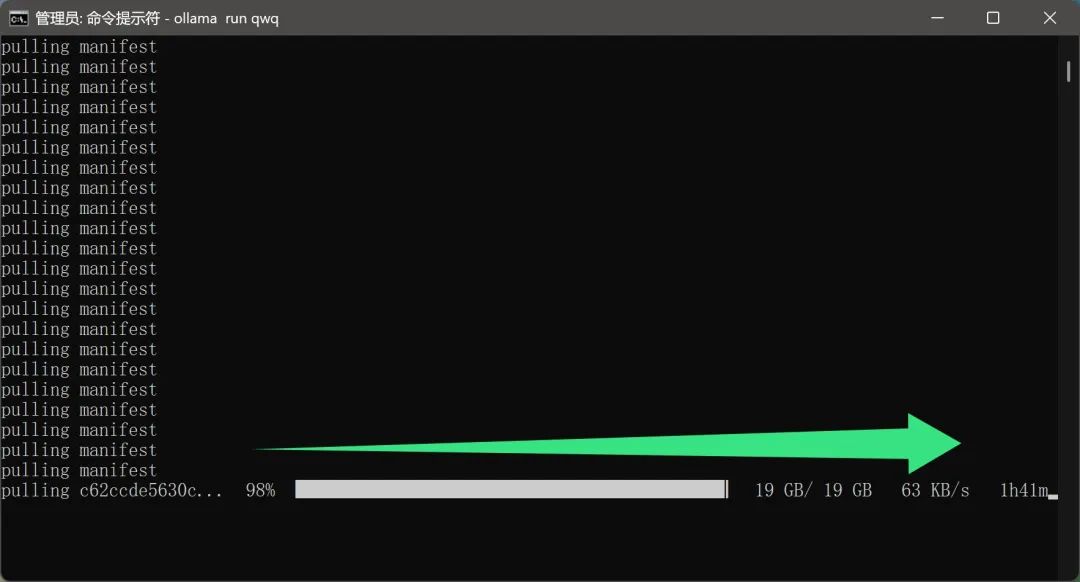
しかし、QwQ-32Bモデルは現在非常に人気があり、多くのユーザーがダウンロードしているため、実際のダウンロード速度にある程度影響する可能性があり、その結果、ダウンロード時間が長くなり、ユーザーは辛抱強く待つ必要があります。
しばらく待って、ようやくモデルがダウンロードされた。 試しに12GBのビデオメモリを搭載したRTX3060デスクトップグレードのグラフィックカードを搭載したコンピュータでQwQ-32Bモデルを動かしてみたところ、モデルは正常にロードされただけでなく、ユーザーの入力に基づいたスムーズな回答を出すことができ、さらに最も重要なことに、プロセス全体を通してビデオメモリのオーバーフロー問題が発生しなかった。 これは、主流のグラフィックカードでもQwQ-32B定量モデルの要件を満たすことができることを意味する。

実際の推論性能では、QwQ-32Bの実力は、ユーザーが冗談で「IQアンダーライン」と呼ぶいくつかのOpenAIモデルをすでに凌駕している。 これもQwQ-32Bの性能の優位性を裏付けている。
Windowsタスクマネージャを通して、モデルのリソース使用状況をリアルタイムで監視することができます。 その結果、CPU、メモリ、グラフィックメモリが、モデル推論プロセス中に高負荷にさらされていることがわかりました。これは、大規模モデルをローカルで実行するために必要なハードウェアリソースの高さを反映しています。
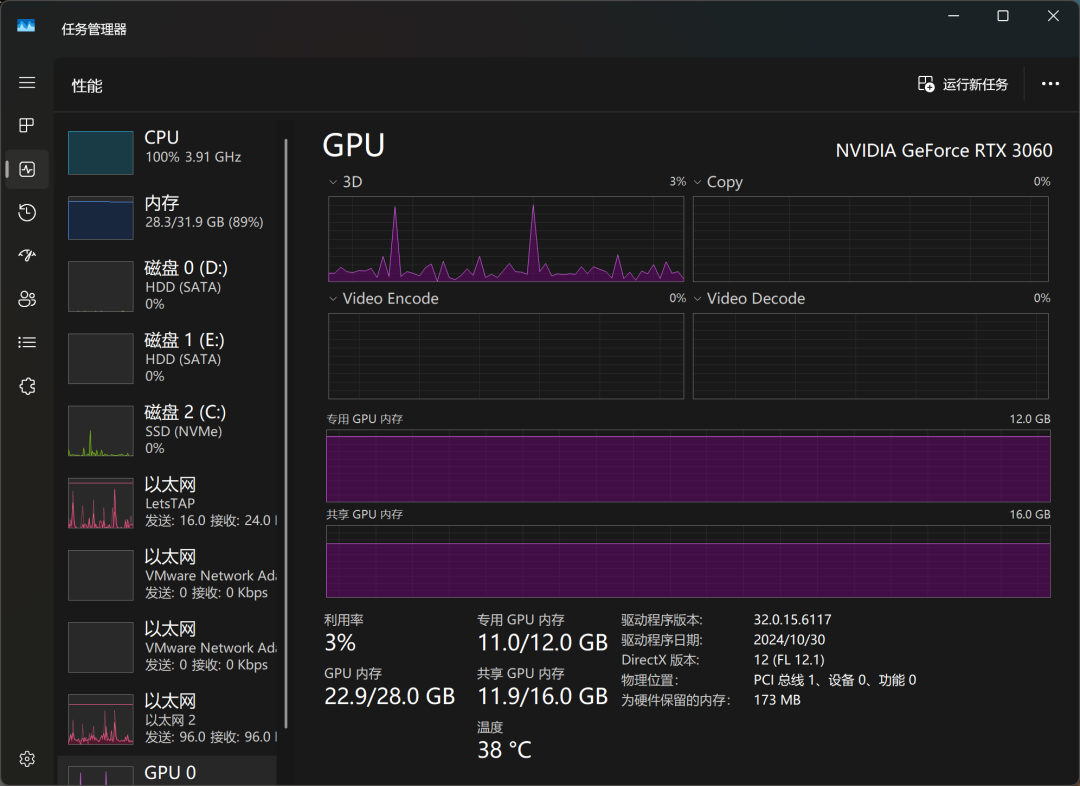
RTX3060グラフィックカードでは、QwQ-32Bは「ダ、ダ、ダ、ダ...」程度のテンポで応答し、基本的な使用ニーズを満たすことができるが、応答性と滑らかさの点ではまだ改善の余地がある。 より過激なローカルモデルの走りを求めるのであれば、より高度なハードウェア構成が必要かもしれない。
モデルの走行速度をさらに向上させるため、QwQ-32Bモデルをダウンロードし、最高級のRTX3090グラフィックカードを搭載したデバイスで再度走らせてみた。 実験の結果、上位のグラフィックカードに交換したことで、モデルの動作速度は大幅に向上し、「空を飛ぶような速さ」と表現しても過言ではない。 このことからも、ローカルの大型模型の走行体験におけるハードウェア構成の重要性が再確認された。
3.QwQ-32Bのクライアントへの統合
コマンドラインインタフェースから直接モデルと会話するのはシンプルで簡単な方法ですが、頻繁に使用する必要がある方や、より良い対話体験を求める方にとっては、グラフィカルクライアントを使用する方がより便利な選択であることは間違いありません。 ChatWiseを選んだ主な理由は、シンプルで直感的なインターフェイスデザイン、明確で分かりやすい操作ロジック、そしてユーザーに良い経験を提供する能力にあります。
以下は、QwQ-32BモデルをChatWiseクライアントに設定する手順の概要です。
ChatWiseクライアントとOllamaサービスが同じコンピューター上で動作している場合、通常、追加設定なしでChatWiseクライアントを開き、QwQ-32Bモデルを直接使用することができます。 Ollamaサービスとクライアント・アプリケーションの両方が同じデバイスにインストールされている場合です。
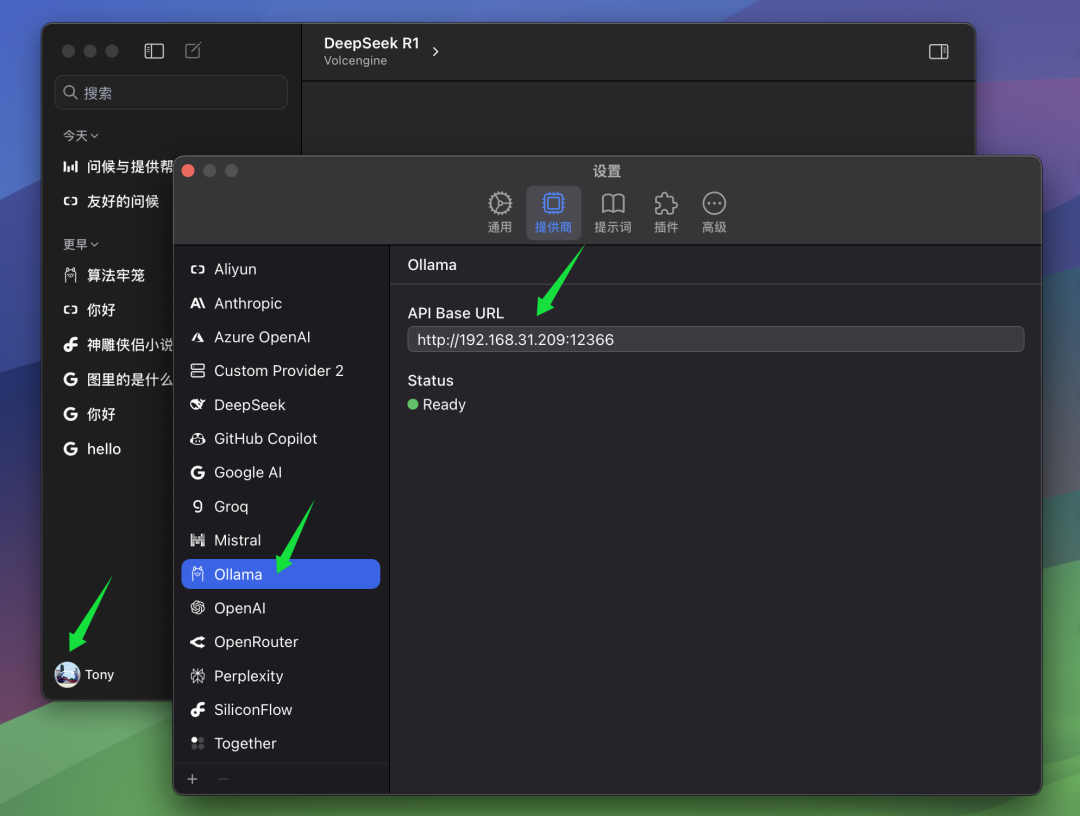
しかし、著者のように、Ollamaサービスを他のコンピュータ(例えばサーバー)にインストールし、ChatWiseクライアントがローカルコンピュータで動作している場合、手動でChatWiseの ベースURL の設定で、クライアントがリモートの Ollama サービスに接続できるようにします。 この設定は ベースURL 設定では、Ollama サービスを実行しているコンピュータの IP アドレスと、Ollama サーバーに設定したポート番号を入力する必要があります。 Ollamaのデフォルト・ポートは13434ですので、特に設定していない場合はデフォルト・ポートをそのままお使いください。
果たす ベースURL 設定後、ChatWiseクライアントで使用するモデルを選択できます。
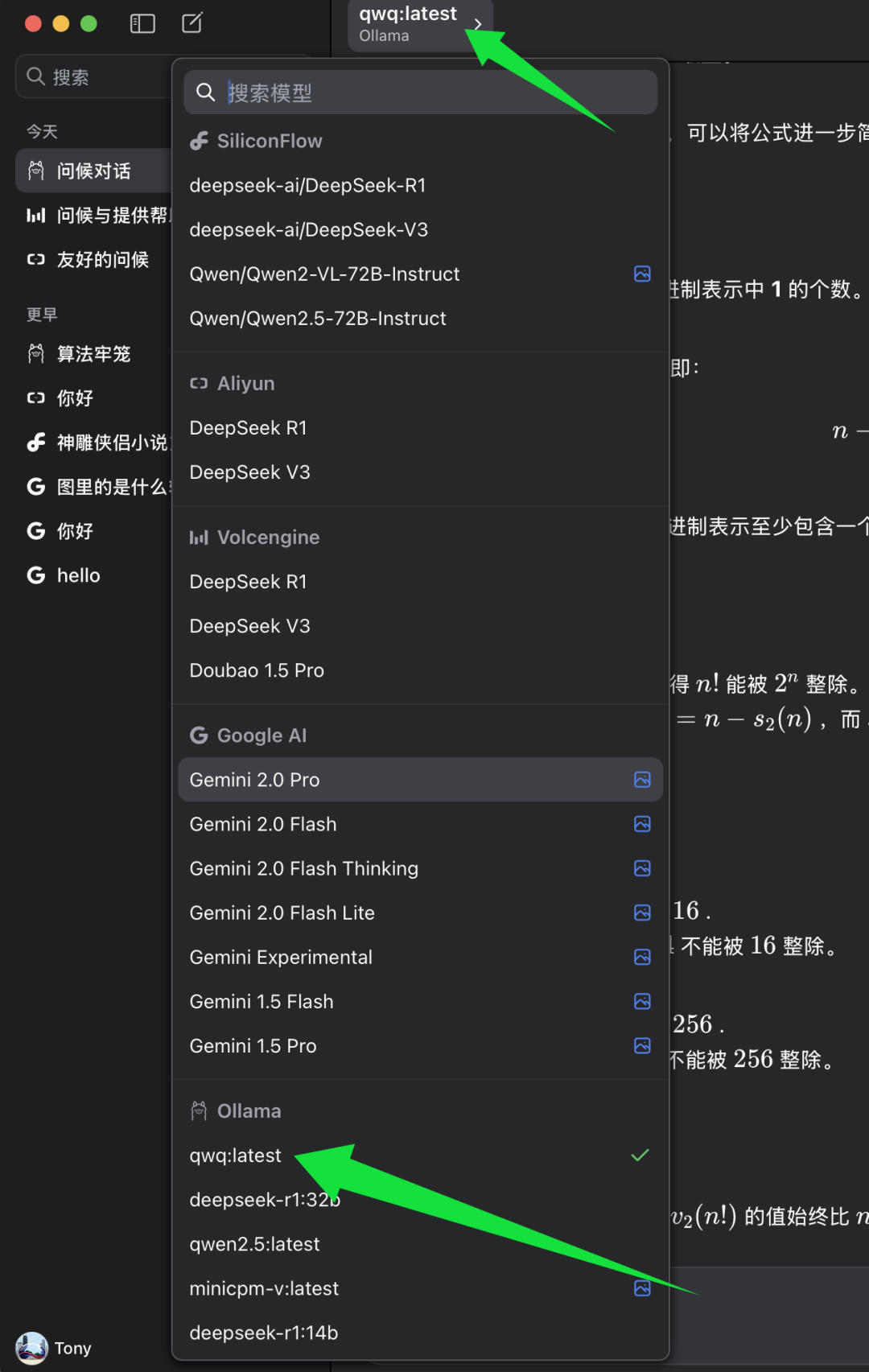
ChatWiseの機種選択リストで、Ollamaの機種カテゴリを探し、その下にある qwq:最新. qwq:最新 QwQ-32Bモデルの最新バージョンを表し、通常は4ビット量子化バージョンでもある。 選択 qwq:最新 その後、ChatWiseクライアントでQwQ-32Bモデルのパワーを体験し始めることができます。
4.QwQ-32Bモデル知能レベルテスト
QwQ-32Bモデルの知能レベルをより客観的に評価するために、OpenAIモデルの「知能低下」問題をテストするために以前に開発された古典的な質問セットを使用しました。 この質問セットは、以下の場合に有用であることが経験的に示されている厳選された4つの質問から構成されています。 チャットGPT (特にGPT-3やGPT-4モデルの場合)、「知能が低下している」というユーザーのフィードバックがある場合、これらの質問に正しく答えることはしばしば困難です。 したがって、この一連の質問は、大型モデルの知能レベルをテストするための参考としてある程度使用することができます。
次に、ローカルで実行したQwQ-32Bモデルがすべての質問にうまく答えられるかどうか、ひとつひとつテストしていく。
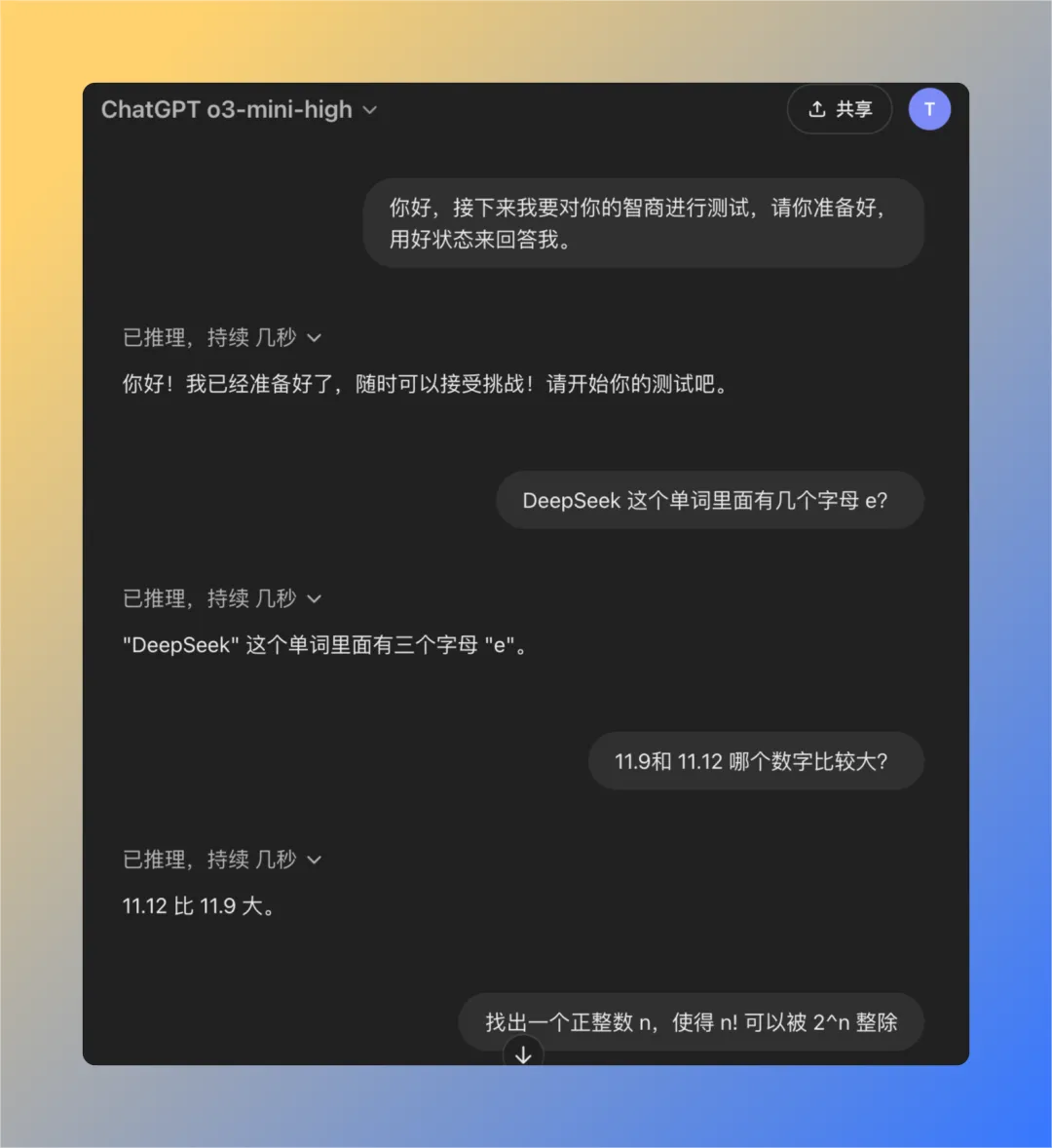
質問1:deepseekという単語にはeという文字が何文字含まれているか?
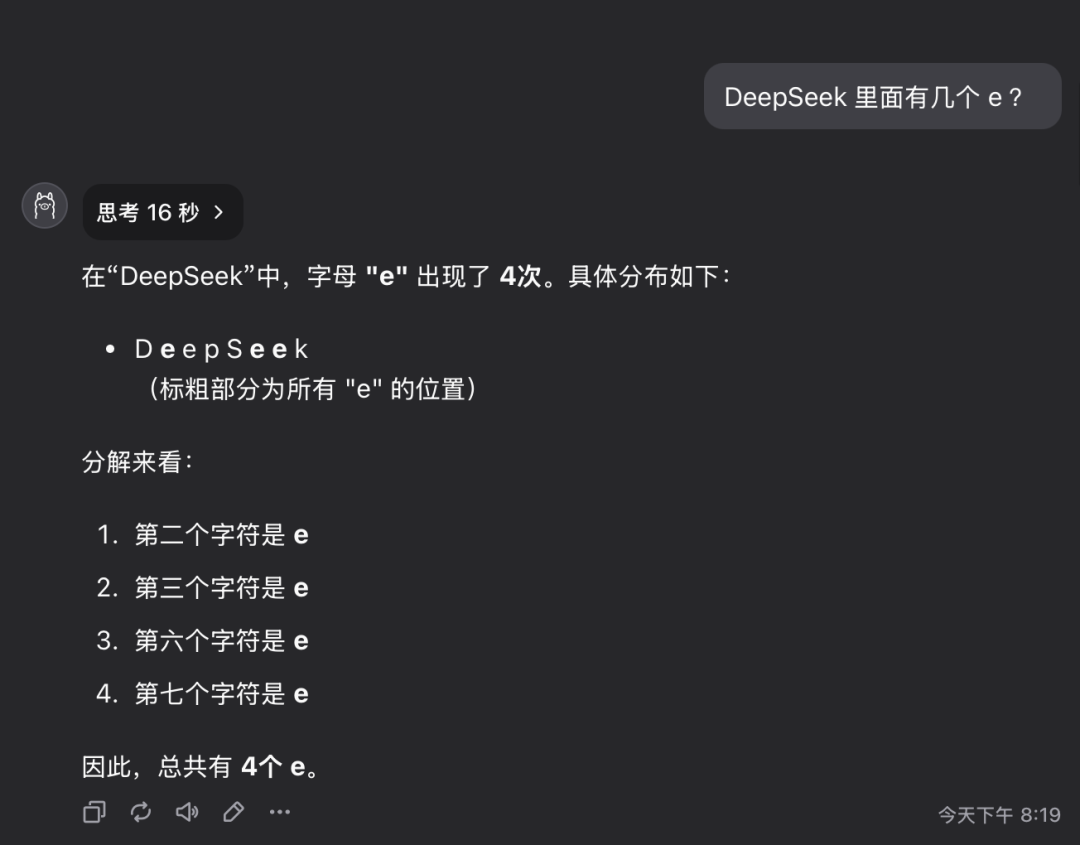
QwQ-32Bモデルは16秒で正解を出した:3。 答えは正しい。.
この質問は単純に見えるかもしれないが、実際には、詳細な情報を正確に理解し、抽出するモデルの能力を調べるものである。 驚くことに、このような質問に正確に答えることができない大規模なモデルがまだ相当数存在する。
質問2:11.9と11.12のどちらが大きいか?

QwQ-32Bモデルは47秒で正解を出した:11.12の方が大きい。 答えは正しい。.
繰り返しになるが、これは一見基本的だが古典的な問題である。 多くの大規模なモデルは、単純な数値比較を混乱させたり、判断を誤ったりするが、これはモデルの根本的な論理的推論に欠陥がある可能性を反映している。
問題3: nの階乗(n!)が2のn乗(2^n)で割り切れるような正の整数nを求めよ。

QwQ-32Bモデルは121秒で正解を出す:そのような正の整数nは存在しない。 答えは正しい。.
この問題のポイントは、具体的な数値の答えを見つけることではなく、モデルが抽象的な思考力、論理的な推論力を持ち、問題の本質を理解し、最終的に "存在しない "という結論に達することができるかどうかを検証することである。 QwQ-32Bはこの問題に正解し、論理的な推論の能力があることを示した。
第4問:古典的論理推理-帽子の色パズル
「5人の人が並んでいて、それぞれ赤か青の帽子をかぶっている。 各人には、列の前の人の帽子の色しか見えないが、自分の頭にかぶった帽子の色は見えない。 ファシリテーターは、「この5人のうち、少なくとも1人は赤い帽子をかぶっています」と、あらかじめグループに伝えておく。 さて、列の最後尾の人から順番に前に進み、各人に "自分の帽子の色を知っていますか?"と尋ねる。 各人は "はい "か "いいえ "しか答えられない。 5番目の人が "いいえ "と答え、4番目の人が "はい "と答えたと仮定すると、可能性のあるすべての帽子の色の分布はどうなりますか?"
最初の3問に比べ、この論理的推論の問題は格段に難しく、モデルにより論理的な分析と推論のスキルが要求された。
最初の質問では、QwQ-32B型が長時間思考状態に入り、画面には「思考中...」という文字が点滅し、あたかも「脳」が高速で動いているかのようで、ハードウェアがこのような激しい計算負荷に耐えられるのかと心配になるほどだった。ハードウェアがそのような激しい計算負荷に耐えられるのかどうか、人々に心配さえさせた。 時間とハードウェアの稼働状況を考慮し、10分以上待った後、私は手動でモデルの思考プロセスを中断させた。
その後、筆者は新たな対話セッションを再開し、QwQ-32Bモデルに再び同じ質問をした。

今回、QwQ-32Bモデルは196秒後にようやく完全な正解を出し、その理由を詳しく説明した。 答えは正しい。.
モデルの推論プロセスの記録を見ると、QwQ-32Bのパラメータサイズは比較的小さいにもかかわらず、複雑な論理的推論問題に直面したとき、非常に「難しい」思考と分析プロセスを示していることが感じられる。 モデルは、最終的に正しい結論に到達する前に、バックグラウンドで多くの論理計算と確率演繹を実行する。
以上のような一連の厳密で詳細なIQテストの結果、QwQ-32B 4ビットモデルの数値化バージョンは、特に論理的推論とクイズにおいて印象的な総合的性能を示し、同クラスの他のモデルを凌駕したと予備的に結論づけることができる。 定量化されていないバージョンのQwQ-32Bの性能はさらに向上すると考えるのが妥当であろう。 32Bフルブラッド・エディション・モデル性能評価レポート QwQ-32Bはより包括的な性能データと分析を提供している。 したがって、QwQ-32Bモデルのリリース時にAlibaba QwQチームが行った性能宣伝は基本的に誇張されたものではなく、QwQ-32Bは実に優れた新しい推論モデルであり、6,710億パラメータのDeepSeek-R1モデルに320億パラメータのパラメータ規模で対抗する強さを達成したと判断できる。
国内のオープンソース・ビッグモデルの急速な台頭は、AI技術分野における中国の活発なイノベーションと巨大な発展の可能性を十分に示している。
さらに素晴らしいのは、QwQ-32B 32Bバージョンでは、24GBのRAMを搭載したグラフィックカードだけで、このモデルをスムーズかつ驚異的なスピードで実行できることだ。 数年前であれば、このような高性能の大規模モデルを動かすには数百万ドルの専用機器が必要だったが、今ではQwQ-32BやOllamaのような技術の進歩のおかげで、ユーザーは1万ドルのPCでローカルに展開し、体験することができる。 QwQ-32Bモデルのリリースは、高性能AIモデルが普及に向けて加速していること、「AI for all」の時代が加速していること、高性能AI技術が個人端末機器や様々な産業においてより広い応用の見通しを持つようになることを示唆している。
今こそ、QwQ-32Bのパワフルな機能を最大限に活用し、深く探求する絶好のチャンスです! AIテクノロジーの明るい未来を一緒に迎えましょう!
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事




コメントはありません