
Mureka V7.5 - クインテッセンスの先進AI音楽制作モデル
Mureka V7.5は、崑崙ワールドワイドが提供する、中国歌曲に特化した最先端のAI音楽生成モデルです。このモデルは、音色と演奏テクニックを正確に再現し、自然で滑らかで感情的なボーカルを生成します。最適化された自動音声認識(ASR)技術に基づき、Mureka V...

Skywork Deep Research Agent v2 - 崑崙のDeep Research Intelligenceのアップグレード版。
Skywork Deep Research Agent v2は、Kunlun Waveが発表したマルチモーダル情報の統合と分析に特化したディープリサーチインテリジェントボディです。

Hunyuan-GameCraft - Tencent Hunyuanのオープンソースフレームワーク。
Hunyuan-GameCraftはTencent Hunyuanチームのオープンソースインタラクティブゲームビデオ生成フレームワークです。1枚の画像とプロンプトから、非常にダイナミックなゲームビデオを生成するフレームワークで、キーボードとマウスを使ってリアルタイムでビデオコンテンツを制御するユーザーをサポートします。

Skywork UniPic 2.0 - オープンソースの効率的なマルチモーダルモデリング by KunlunWanwei
Skywork UniPic 2.0は、Quintessenceによってオープンソース化された効率的なマルチモーダルモデルであり、画像生成、編集、理解に焦点を当てている。このモデルは、2BパラメータのSD3.5-Mediumアーキテクチャに基づいており、事前学習、漸進的なデュアルタスク強化戦略、共同学習によって実現される。

RynnRCP - アリ・ダルマ研究所による初のオープンソース・ロボティクス・コンテキスト・プロトコル
RynnRCPは、Ali Dharma Instituteによるオープンソースのロボットコンテキストプロトコル(RCP)であり、身体化された知能の開発の敷居を下げ、開発プロセス全体を開放します。RynnRCPは、RCPフレームワークとRobotMotionモジュールで構成されています。RCPフレームワークは、能力の抽象化とマルチプロトコルのサポートを通じて、...

RynnEC - アリ・ダルマ・インスティテュートのオープンソース世界理解モデル
RynnECはAlibaba Dharma Instituteが導入した世界理解モデルで、具現化知能タスクに焦点を当てている。このモデルは、映像データと自然言語を組み合わせたマルチモーダル融合技術に基づいており、シーン内のオブジェクトを多次元から解析し、オブジェクトの理解、空間認識、映像ターゲットのセグメンテーションなどの機能をサポートする。

Matrix-3D - 崑崙ワールドワイドオープンソース3D世界生成フレームワーク
Matrix-3Dは、Skywork AIチームによるオープンソースのフレームワークで、探索可能なパノラマ3D世界の生成に特化している。このフレームワークは、パノラマビデオ生成と3D再構成技術を組み合わせて、1枚の画像やテキストプロンプトから高品質で全方位探索可能な3D世界を生成します。
GLM-4.5V - Smart Spectrumによるマルチモーダル・オープンソース視覚推論モデル
GLM-4.5Vは、Smart Spectrumによって導入された世界有数のオープンソース視覚推論モデルであり、1060億の総パラメータと120億の活性化パラメータを持つ。このモデルは、新世代のテキストベースモデルGLM-4.5-Airをベースに学習され、強力な視覚理解・推論能力を持ち、画像、動画...
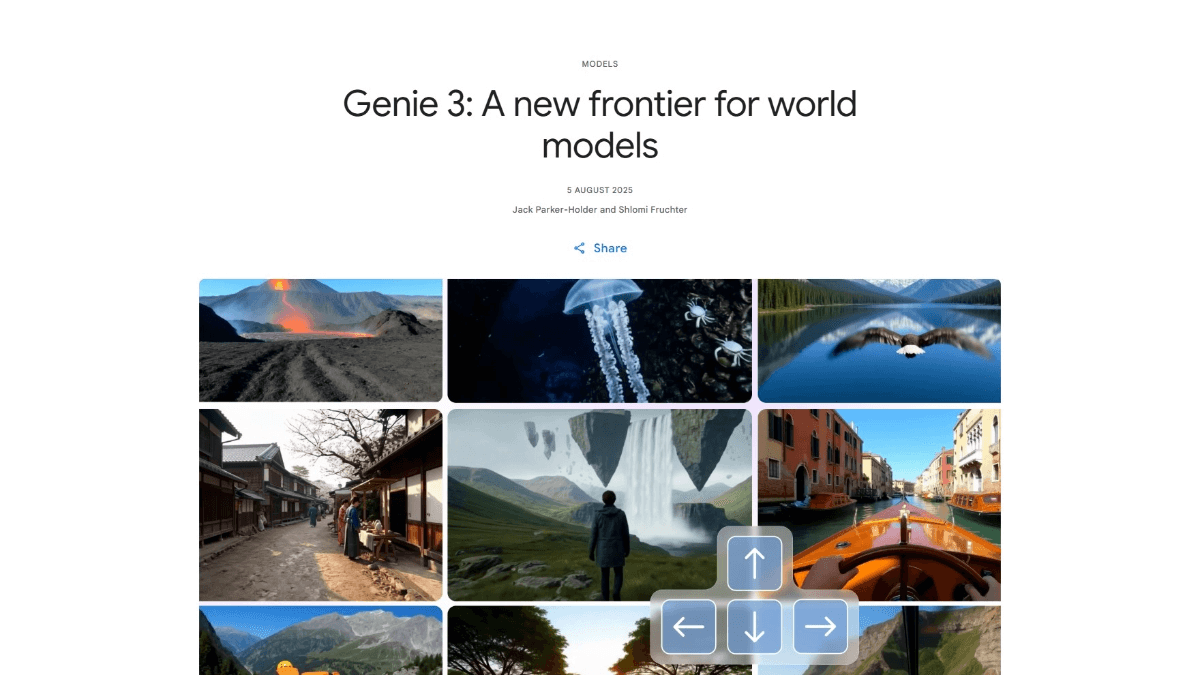
ジーニー3 - グーグルのユニバーサル世界モデル
Genie 3は、Google DeepMindが提供する新世代のユニバーサルワールドモデルで、高度にダイナミックで一貫性のある仮想世界をリアルタイムで生成することができます。Genie 3は、物理現象や自然生態系をシミュレートし、ファンタジーや歴史的なシナリオの作成をサポートします。テキストプロンプトにより、ユーザーは...
Claude Opus 4.1 - Anthropicの最強プログラミングモデル
Claude Opus 4.1は、複雑なタスクを効率的に処理するために設計された、Anthropicによる最先端の大規模言語モデルです。このモデルはプログラミング領域で優れており、高品質のコードを生成し、最大32kの単一出力をサポートし、幅広いプログラミングスタイルに適応します。