91Writing - オープンソースAIインテリジェント小説作成プラットフォーム
91Writingは、Vue 3とElement Plusをベースに開発された完全オープンソースのAI小説作成ツールで、GPT、Claude、Geminiなどの様々な高度なAIモデルを統合しています。このツールは、プロジェクトの作成を含む、アイデアからテキストまでの完全な作成ツールチェーンをクリエイターに提供します...

MITの新しいレポート『The Generative AI Divide: The State of Business AI in 2025』。
MITの最新レポート『The Generative AI Divide: The State of Business AI in 2025』は、300を超えるAIプロジェクトに関する詳細な調査、52の組織へのインタビュー、153人の経営幹部へのアンケート調査を実施することで、企業が経験しているジェネレーティブAI(GenAI)導入プロセスの核心を明らかにしている。
AutoClip - ワンクリックでテーマ別のビデオコレクションを生成するオープンソースの AI ビデオスライスツール!
AutoClipは、自動化されたビデオ処理の完全なプロセスを達成するために高度なAI技術に基づいて、オープンソースのAIビデオ編集ツールです。ツールは自動的にビデオのハイライトを識別することができ、貴重なコンテンツの正確な抽出は、コンテンツのコレクションを生成するために、インテリジェントなクラスタリングのテーマの類似性に基づいて行うことができます。

ハンズオンAI:人工知能の一般知識と実践 - AliCloudによる無料のAI一般知識コース
AliCloudの "Hands-On Learning AI: Artificial Intelligence General Knowledge and Practice "は、Superstar Erlangと共同で、様々な専門的背景を持つ学習者のための体系的なAI学習コースです。このコースは、5つの一流大学のマスター教師が指導し、AIの発展の歴史、コア技術から倫理的安全性まで、総合的な知識を身につけることができます。

Seed-OSS - Wordpressチームがオープンソース化した新しいAIモデル
Seed-OSSは、Byte Jump Seedチームによってオープンソース化された大規模な言語モデルのファミリーで、長いテキストと推論タスクに焦点を当てています。Seed-OSSは、複雑な論理的推論や多段階推論で高い精度を発揮し、難しい問題を効率的に解くことができます。Seed-OSSは、最大512Kまでの長いテキストコンテキストをサポートしています。
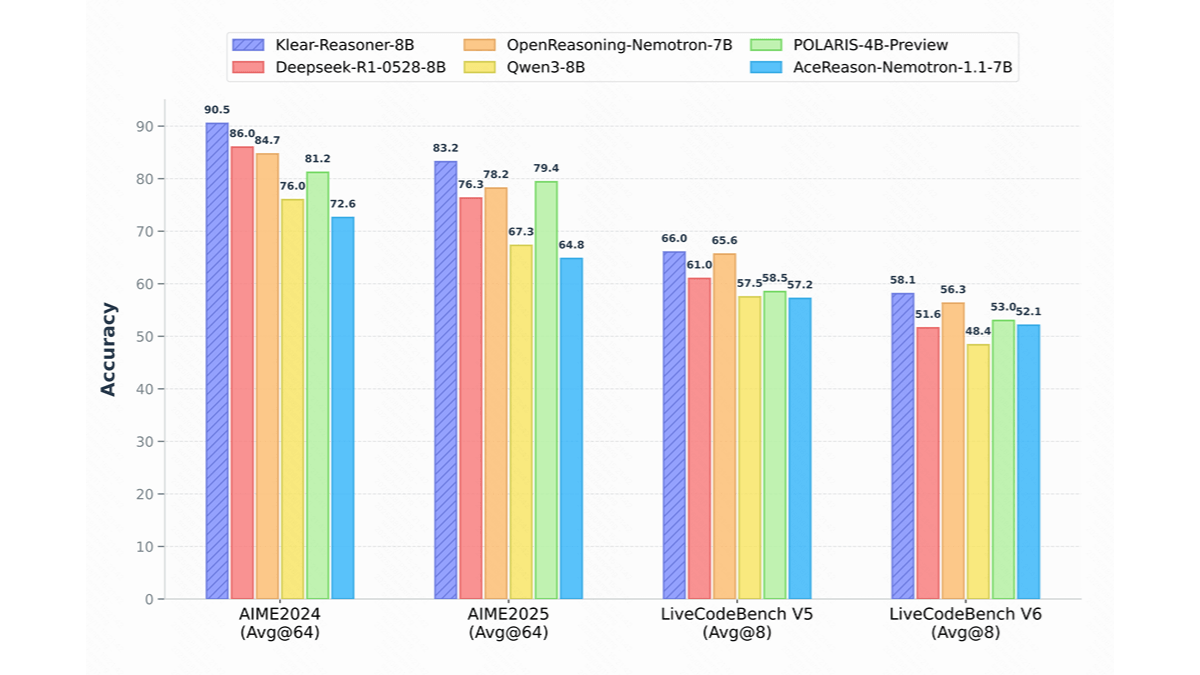
Klear-Reasoner - レーサーが導入した新しい推論モデル
Klear-ReasonerはQwen3-8B-BaseをベースとしたRacerの高性能推論モデルである。Klear-Reasonerは、長い思考連鎖による教師付き微調整と強化学習によって学習され、数学的推論やコード推論において優れた性能を発揮する。

CombatVLA - アモイ・グループによる効率的なVLAモデル
CombatVLAは、3Bパラメトリックスケールで構築されたビジョン-言語-アクション(VLA)モデルで、モーショントラッカーを通して人間のプレイヤーを収集します。

DeepSeek V3.1 - DeepSeekの最新のオープンソースAIモデル
DeepSeek V3.1は、DeepSeekが導入した新世代のAIモデルで、前モデルのV3をベースに重要なアップグレードが施されています。 DeepSeek V3.1は、思考モードと非思考モードを柔軟に切り替えることができるハイブリッド推論アーキテクチャを導入しており、思考...

Qwen-Image-Edit - Ali Tongyi オープンソース画像編集モデル
Qwen-Image-Editは、Ali Tongyiによって導入された、200億のパラメータを持つQwen-Imageアーキテクチャ上に構築された、万能画像編集モデルです。このモデルはセマンティック編集と外観編集の両方の機能を兼ね備えており、画像に対して低レベルの視覚的外観編集を行うことができます(例:追加、削除...

MoE-TTS - 崑崙微の最新音声生成フレームワーク
MoE-TTSは、KunlunWanweiによって導入された音声合成フレームワークで、事前に訓練された大規模言語モデル(LLM)と音声専門家モジュールを組み合わせたMixed Expert(MoE)アーキテクチャに基づいています。MoE-TTSは、テキストモジュールのパラメータを凍結し、音声モジュールのパラメータのみを更新することにより、強力なテキスト推論を保持します...