GPT-5-Codex-OpenAIが導入した最強のプログラミングモデル
GPT-5-Codexは、OpenAIの強力なプログラミング最適化モデルで、GPT-5によってさらに強化され、ソフトウェアエンジニアのために設計されています。このモデルは、高品質なコードを迅速に生成し、複数のプログラミング言語をサポートし、パフォーマンスを向上させるために既存のコードを最適化します。

MiniMax Music 1.5 - MiniMaxの最新AI音楽生成モデル!
MiniMax Music 1.5は、ユーザーの自然言語による記述に基づいて最大4分の音楽を生成する、高度なAI音楽生成ツールです。このモデルは、幅広い音楽スタイルとムードのカスタマイズをサポートし、自然で完全なボーカルトーン、スムーズなトランジション、豊かなレイヤーアレンジを生成します...
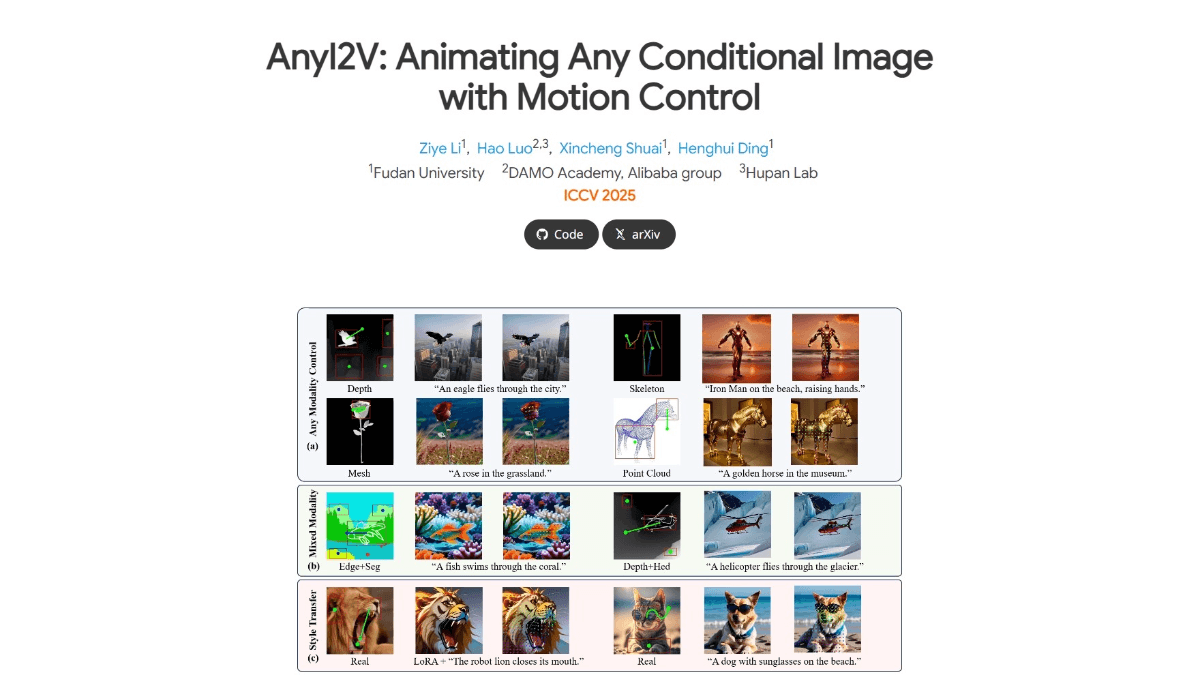
AnyI2V - FudanとAli Dharma Instituteとその他のオープンソースインテリジェント画像アニメーション生成フレームワーク
AnyI2Vは復旦大学、Alibaba Darmo Academyなどが共同で立ち上げた画像アニメーション生成フレームワークで、複雑な学習プロセスや大量のデータを必要とせずに、静的な条件画像(グリッド、点群など)を動的な動画に変換することをサポートする。
SRPO - テンセントハイブリッドがテキスト画像生成モデルを発表
SRPO(Semantic Relative Preference Optimization)は、Tencent Mixed Metaによって導入されたテキストから画像への生成モデルであり、報酬のオンライン調整を達成し、オフラインの微調整依存性を低減するために、テキスト条件信号を通じて報酬メカニズムを最適化する。
Qwen3-Next-アリ・トンイが発表した最新ベースモデル
Qwen3-Nextは、Ali Tongyi氏によってオープンソース化された新世代のハイブリッドアーキテクチャ・ビッグモデルで、Gated DeltaNetとGated Attention技術を組み合わせたものである。
文信ビッグモデルX1.1 - 百度のより良い理解のための深層思考モデル
Wenxin Big Model X1.1は、バイドゥが発表したディープシンキングモデルで、ハイブリッド強化学習フレームワークに基づいており、言語理解と生成の向上に重点を置いている。このモデルは、複雑な質問の処理、指示に従うこと、知性の行動のシミュレーションに優れており、知識豊富な回答や高品質のテキストコンテンツを正確に提供することができる。

ハイブリッドイメージ2.1 - テンセントのオープンソース・ベンダーグラフ・モデル
HunyuanImage 2.1は、高品質の画像生成のために設計されたテンセントのオープンソースグラフィックモデルです。このモデルはネイティブ2K解像度をサポートし、複雑なシーンやディテールを正確にレンダリングすることができ、キャラクターの表情や動きを生き生きと再現することができます。
アーネスト・ンによるLLMアプリケーション開発コースのための無料LangChain
LangChainによるLLMアプリケーション開発は、DeepLearning.AIが提供するオンラインコースで、LangChainの創設者であるハリソン・チェイスとアンドリュー・ングが登場します。
エンダ・ウーによるトランスフォーマーLLMの仕組みに関する無料コース
トランスフォーマーLLMは、DeepLearning.AIと『Hands-On Large Language Models』の著者であるJay Alammar氏とMaarten Grootend氏が提唱する原理で動作する。

Seedream4.0-バイトが発表した最新世代の画像作成モデル
Seedream4.0は、ByteDance社が発表した高度な画像生成・編集ツールで、生成と編集の統合を中心に、正確なコマンド編集、高い機能保持、深いインテント理解などの強力な機能を備えています。