
Youtu-Embedding - Tencent Youtuオープンソースの汎用テキスト表現モデル
Youtu-Embeddingは、TencentのYoutu Labsによるオープンソースのユニバーサルテキスト表現モデルで、エンタープライズレベルのアプリケーション向けに設計されている。テキストはディープニューラルネットワークによって高次元のベクトル空間にマッピングされ、その空間では意味的に類似した文章がより近くに配置され、正確な意味検索が実現される。

SAIL-VL2 - ByteHopのオープンソース・マルチモーダル視覚言語モデル
SAIL-VL2は、Byte Jumpチームによるオープンソースのマルチモーダル視覚言語モデルで、画像やテキストなどのマルチモーダル入力の共同モデリングに焦点を当てています。スパース混合エキスパート(MoE)アーキテクチャと漸進的な学習ストラテジーを用いて、2Bから8Bのパラメータスケールで、特に図形理解、数学的...

MineContext - バイト・オープンソース・アクティブ・コンテキスト・アウェアAIパートナー
MineContextは、ByteDance Vikingチームによってオープンソース化されたアクティブなコンテキスト認識AIパートナーで、ユーザーが大量の情報を効率的に管理し、知識作業の効率を向上させることを支援します。スクリーンショットとコンテンツ理解技術により、ユーザーの日常操作(ウェブ閲覧、文書編集など)を自動的に記録し、...

nanochat - カルパシーによるフリーでオープンソースの低コストモデル・トレーニング・プロジェクト
nanochatは、AIのレジェンドであり元テスラAIディレクターのアンドレイ・カルパシーが公開したオープンソースプロジェクトで、個人が非常に低コストかつシンプルに、小規模なChatGPTのような言語モデルを素早く学習することを可能にする。プロジェクト全体で使用されているのは、わずか約800...
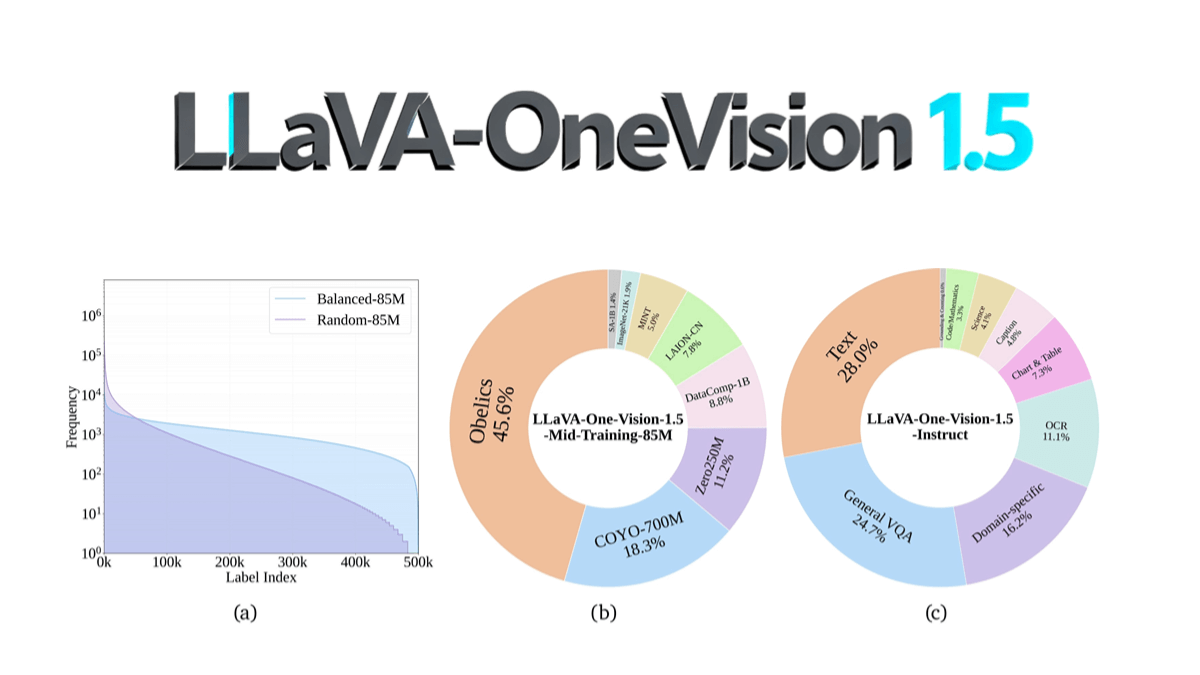
LLaVA-OneVision-1.5 - 高性能マルチモーダル理解のためのフリーでオープンソースのマルチモーダルモデル
LLaVA-OneVision-1.5は、EvolvingLMMS-Labチームによるオープンソースのマルチモーダルモデルで、8Bパラメータスケールを使用し、128 A800上でコンパクトな3段階のトレーニングプロセス(言語-イメージのアライメント、概念の平衡化と知識の注入、命令の微調整)を通じて...
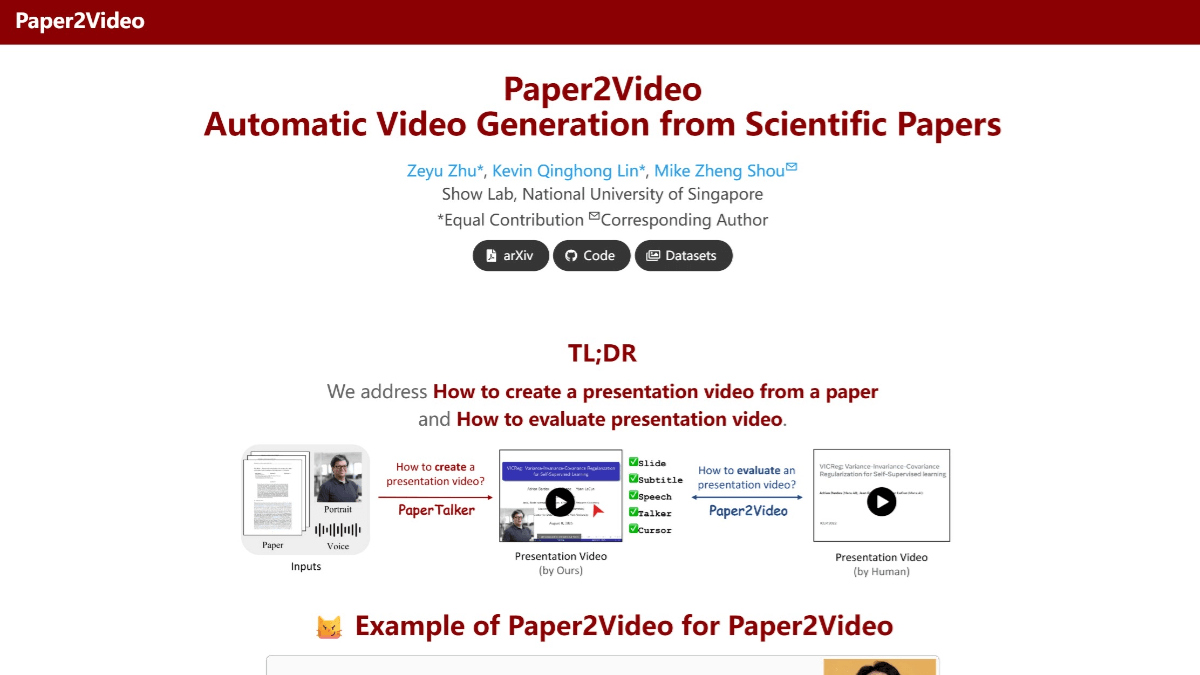
Paper2Video - 論文のデモビデオを自動生成するNUSのオープンソースプロジェクト
Paper2Videoは、シンガポール国立大学のShow Labで行われている、学術論文のプレゼンテーションビデオを自動生成するオープンソースプロジェクトです。PaperTalkerマルチインテリジェンスフレームワークを使用し、論文はスライド、字幕、ナレーション、スピーカーアバターを含む完全なプレゼンテーションビデオに変換されます。

NeuTTS Air - オフラインCPU実行をサポートしたフリーで軽量な音声合成モデル
NeuTTS Airは、Neuphonicチームによって開発されたオープンソースの軽量音声合成モデルで、クラウドに依存することなく、ローカルデバイス(携帯電話、ラップトップ、Raspberry Piなど)上でリアルタイムに実行できる。0.5BパラメータのQwenアーキテクチャと自社開発のNeuCodecコーデックを使用しています。

KAT-Dev-72B-Exp - レーサー・オープンソース・フリーのプログラミング専用モデル
KAT-Dev-72B-Expは、強化学習技術に基づいて最適化された、Racerチームによって発表されたオープンソースのプログラミング専用大規模言語モデルであり、SWE-Bench Verifiedベンチマークテストで74.6%の精度を達成した。このモデルは革新的な...

Jamba Reasoning 3B - イスラエルAI21ラボのオープンソース軽量推論モデル
Jamba Reasoning 3Bは、イスラエルのAIスタートアップAI21 Labsによってオープンソース化された軽量推論モデルで、強力なパフォーマンスと幅広いアプリケーションへの応用が期待されている。SSMとTransformerのハイブリッド・アーキテクチャを採用し、Trans...
エルンスト・ウーによるAgentic AIから最新のインテリジェンスを学ぶ無料コース
Agentic AIは、アーネスト・ングが開始した知的身体に関する最新のコースです。このコースでは、知的身体の設計と構築に焦点を当て、4つの主要な設計モードである反射、ツールの使用、計画、および複数の知的身体のコラボレーションをカバーします。学習者は、理論的な説明と実践的なコードを通して、インテリジェント・ボディが出力をチェックし、自律的に調整する方法を習得します。