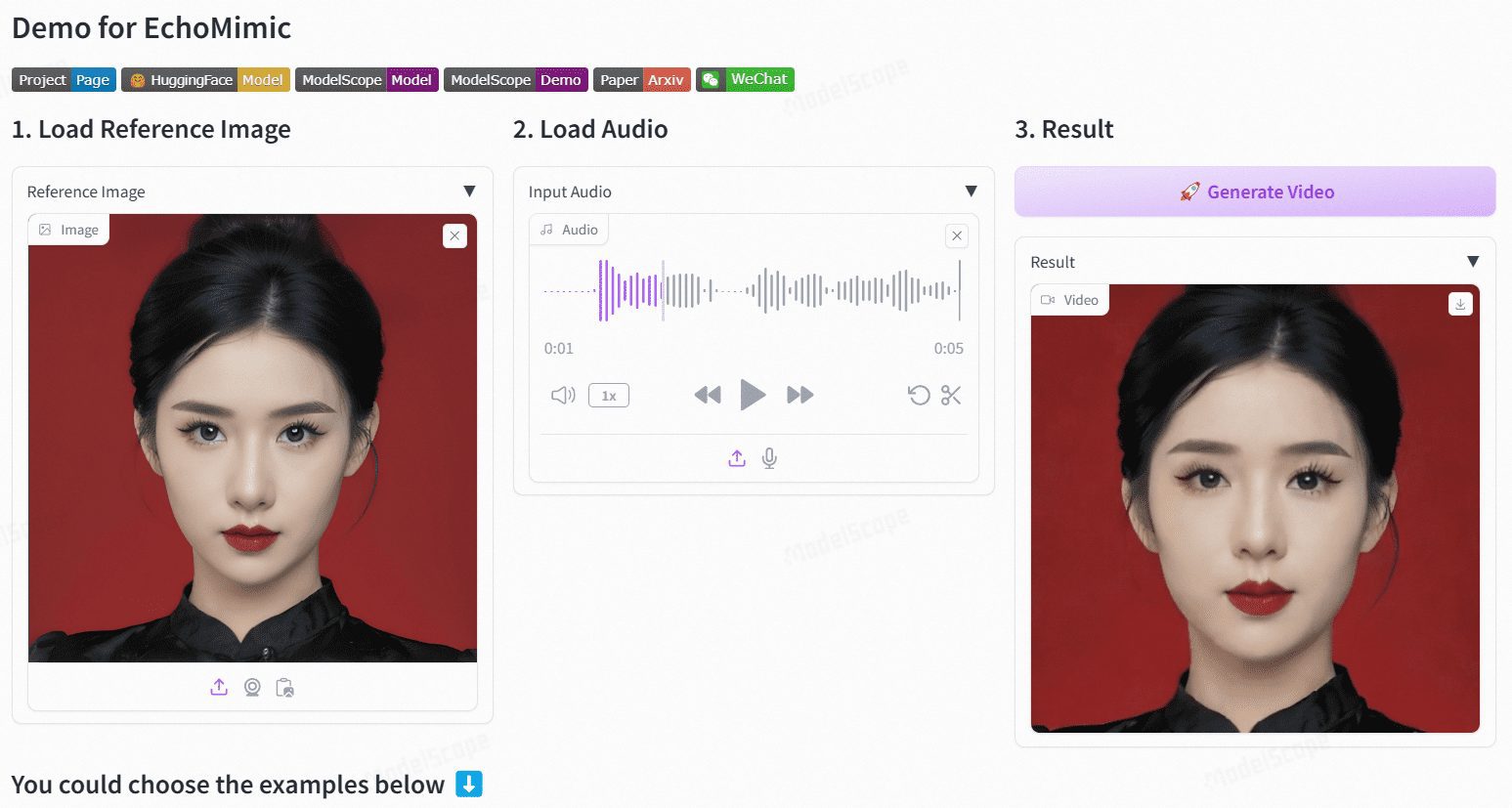
ArenaRL - 高德地图联合阿里通义开源的对比式强化学习方法

ArenaRL是什么
ArenaRL是高德地图与阿里通义团队联合开源的对比式强化学习方法,专为解决开放域任务(如出行规划)中缺乏标准答案的问题。核心创新在于用“相对排序”替代传统“绝对打分”机制,通过智能体自动生成多套方案并相互淘汰(类似体育赛事),在模糊需求(如“适合亲子游且性价比高”)中持续优化解空间。法已开源配套训练框架,适用于无标准解但可比较的任务场景,显著提升了高德在POI排序和开放式出行规划等业务指标。

ArenaRL的功能特色
- 解决开放域任务中的判别崩溃问题:通过引入基于锦标赛的相对排名机制,将传统的绝对评分体系转变为组内相对排序方式,有效解决了开放域任务中因缺乏明确标准答案而导致的判别模型性能退化问题。
- 高效的评估机制:采用种子单败淘汰赛的拓扑结构,将计算复杂度控制在最优线性水平,大幅降低了计算资源消耗,同时保证了模型评估的准确性。
- 提升智能体决策能力:通过过程感知的成对评估机制,对整个推理轨迹进行对比评估,不仅考虑最终答案的合理性,还关注推理过程的合理性,提升智能体在复杂任务中的决策能力和泛化能力。
- 构建完整的训练-评测基准:配套构建了Open-Travel和Open-DeepResearch两个完整的训练和评测基准,为学术研究和实际应用提供了标准化的测试环境。
- 广泛的应用场景适配:不仅在学术研究中表现出色,在实际业务场景中也展现出显著优势,例如在高德地图的复杂任务规划与执行效率提升方面表现突出。
ArenaRL的核心优势
- 创新的对比式强化学习机制:通过锦标赛机制进行相对排名,解决了开放域任务中判别模型崩溃的问题,提升了模型的稳定性和泛化能力。
- 高效的评估效率:采用种子单败淘汰赛结构,将评估复杂度控制在最优线性水平,显著降低了计算资源消耗。
- 强化过程感知评估:不仅评估最终结果,还关注推理过程的合理性,使智能体在复杂任务中表现更优。
- 完整的训练与评测基准:提供了Open-Travel和Open-DeepResearch等基准,为研究和应用提供了标准化的测试环境。
- 强大的基础设施支持:构建了仿真训练环境和稳定高效的工具沙盒,加速研究和迭代速度。
- 显著的业务应用效果:在高德地图等实际业务中表现出色,提升了任务规划和执行效率。
- 开源与社区推动:通过开源代码和数据,为AI研究社区提供了宝贵的资源,促进了开放域智能体的研究和发展。
ArenaRL官网是什么
- プロジェクトのウェブサイト:https://tongyi-agent.github.io/zh/blog/arenarl/
- GitHubリポジトリ:https://github.com/Alibaba-NLP/qqr
- HuggingFaceモデルライブラリ:https://huggingface.co/papers/2601.06487
- arXivテクニカルペーパー:https://arxiv.org/pdf/2601.06487
ArenaRL的适用人群
- 人工知能研究者:致力于开放域智能体、强化学习和自然语言处理领域的研究者,可以用ArenaRL的创新方法和基准环境推动学术研究。
- 算法工程师:从事智能系统开发的工程师,需要提升模型在复杂动态环境中的决策能力和泛化能力的专业人士。
- データサイエンティスト:关注高质量数据生成和模型评估的从业者,可以通过ArenaRL的仿真环境和数据生成工具提升数据处理和模型训练效率。
- コーポレート・テクニカル・チーム:在实际业务中需要优化智能体任务规划和执行效率的企业团队,例如高德地图等场景的开发者。
- 大学・研究機関:从事人工智能相关课程教学和科研项目的高校教师和学生,可以用ArenaRL作为实践和研究的工具。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません