
Ali BailianはQwQ-32B APIを無料で提供しており、毎日100万トークンが無料で利用できる!

最近、AliCloud百錬プラットフォームは、次のような新しいプラットフォームを発表した。 QwQ-32B ビッグ・ランゲージ・モデルはAPIインタフェースを開放し、以下を提供する。1日100万トークンへの無料アクセスQwQ-32Bモデルは、ユーザーが最先端のAI技術を体験するための障壁を大幅に下げる、新しくエキサイティングな技術である。QwQ-32Bモデルのパワフルなパフォーマンスを体験したいが、ローカルハードウェアのコンピューティングパワーに制限されているユーザーにとって、APIインターフェースを通じてクラウドモデルを呼び出すことは、間違いなくより魅力的な選択肢となる。
QwQ-32Bを知らない人にお勧めの一冊:小型モデル、ビッグパワー:QwQ-32B、1/20パラメータで本格派DeepSeek-R1と戦う
APIインターフェイスの利点:ハードウェアの制限を打破し、強力な計算能力を指先に
前回リリース QwQ-32B大型モデルのローカル展開:PCのための簡単ガイド さらに、QwQ-32Bのような大規模な言語モデルを体験したいユーザーは、多くの場合、高性能なコンピューティング機器をローカルに導入する必要がある。24GB、あるいはそれ以上のビデオメモリというハードウェア要件は、多くのユーザーをAI体験の扉から閉ざすことが多い。AliCloudのHundred Refineプラットフォームが提供するAPIインターフェースは、このペインポイントを巧みに解決する。
APIインターフェースを通じてQwQモデルを呼び出すことで、ユーザーはいくつかの利点を得ることができる:
- ハードウェア構成に関する閾値はない。 高性能なハードウェアをローカルに配置する必要がなく、利用の敷居を下げることができます。薄くて軽いノートパソコンやスマートフォンでも、クラウドの強力なモデリングパワーをスムーズに呼び出すことができます。よりスムーズなローカルモデル実行のため、24G以上のビデオメモリを搭載したグラフィックカードの使用を推奨します。
- システムの互換性。 APIインターフェースはOSに依存せず、クロスプラットフォームである。Windows、macOS、Linuxを問わず、簡単にアクセスできます。
- よりパワフルなPlusバージョン。 QwQ Plusは、Qwen2.5モデルをベースとし、強化学習により学習されたQwQ推論モデルである。基本バージョンと比較して、Plusバージョンはモデル推論能力の大幅な向上を達成しており、コアメトリクス(AIME24/25、livecodebenchなど)およびいくつかの一般的なメトリクス(IFEval、LiveBenchなど)の評価において、Plusバージョンは最高の性能を達成している。 ディープシーク-R1 モデルのレベルの全血版。
- 高速レスポンス。 APIインターフェースは、40~50トークン/秒の高速レスポンスを可能にする。つまり、ユーザーはほぼリアルタイムでインタラクティブな体験をすることができ、効率が劇的に向上する。
AliCloud Hundred Refineに加えて、in silicoモビリティプラットフォームもQwQ-32BモデルへのAPIインターフェースを提供していることは特筆に値する。もしユーザーがin silico flowプラットフォームに興味があれば、前回の記事を参照されたい。今回は主にAliCloud Hundred Refineが提供するAPIインターフェースの使い方を紹介する。
Aliyun百錬APIアクセスガイド:開始するための3つの簡単なステップ!
AliCloudの百錬プラットフォームはQwQシリーズのモデルAPIユーザーに毎日100万件のサービスを提供する トークン 無料クレジット。ほとんどのユーザーにとって、日々の体験やテストにはこの金額で十分です。ユーザーは簡単な登録と設定を完了するだけで利用を開始できます。
以下は、クライアント側でAliyun Bai Lian QwQ Plus APIを設定する簡単な手順です:
1.APIキーとモデル名を取得する
まずは AliCloud百錬プラットフォーム をクリックし、登録またはログインを完了してください。
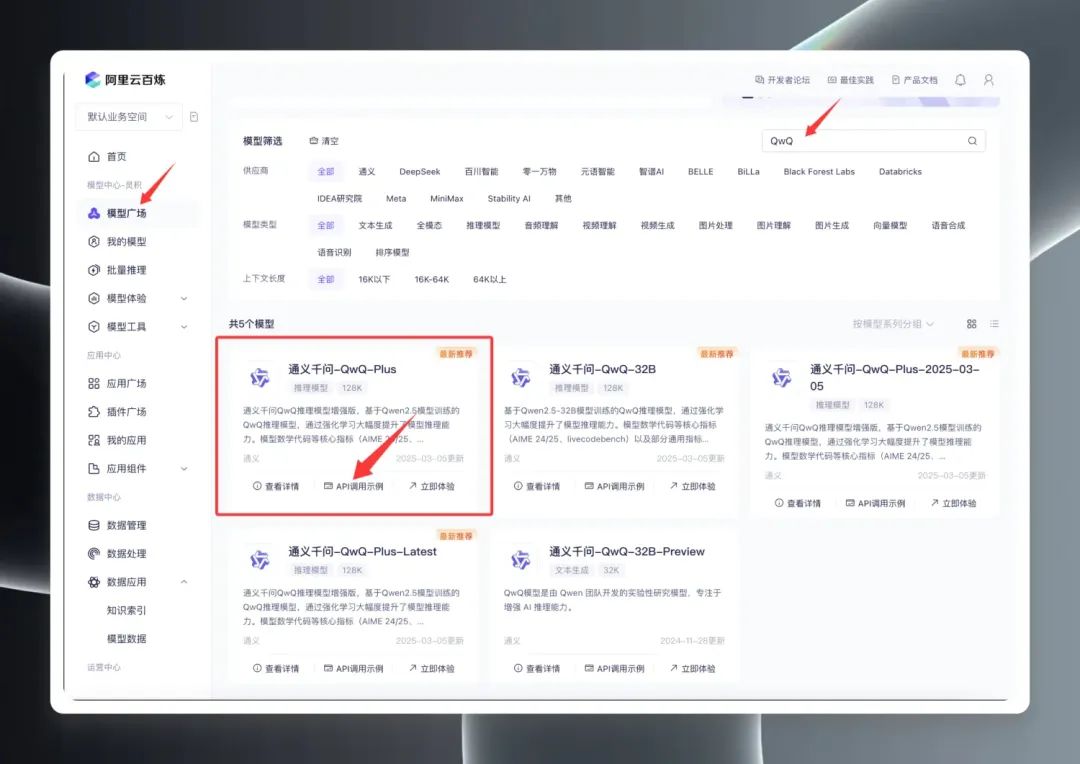
ログインしたら、モデルスクエアで "QwQ "を検索して、QwQの一連のモデルをご覧ください。実際、モデルスクエアには、QwQ32B(正式版)、QwQ32B-Preview(プレビュー版)、QwQ Plus(強化版、コマーシャル版)の3つの主要バージョンが表示されている。
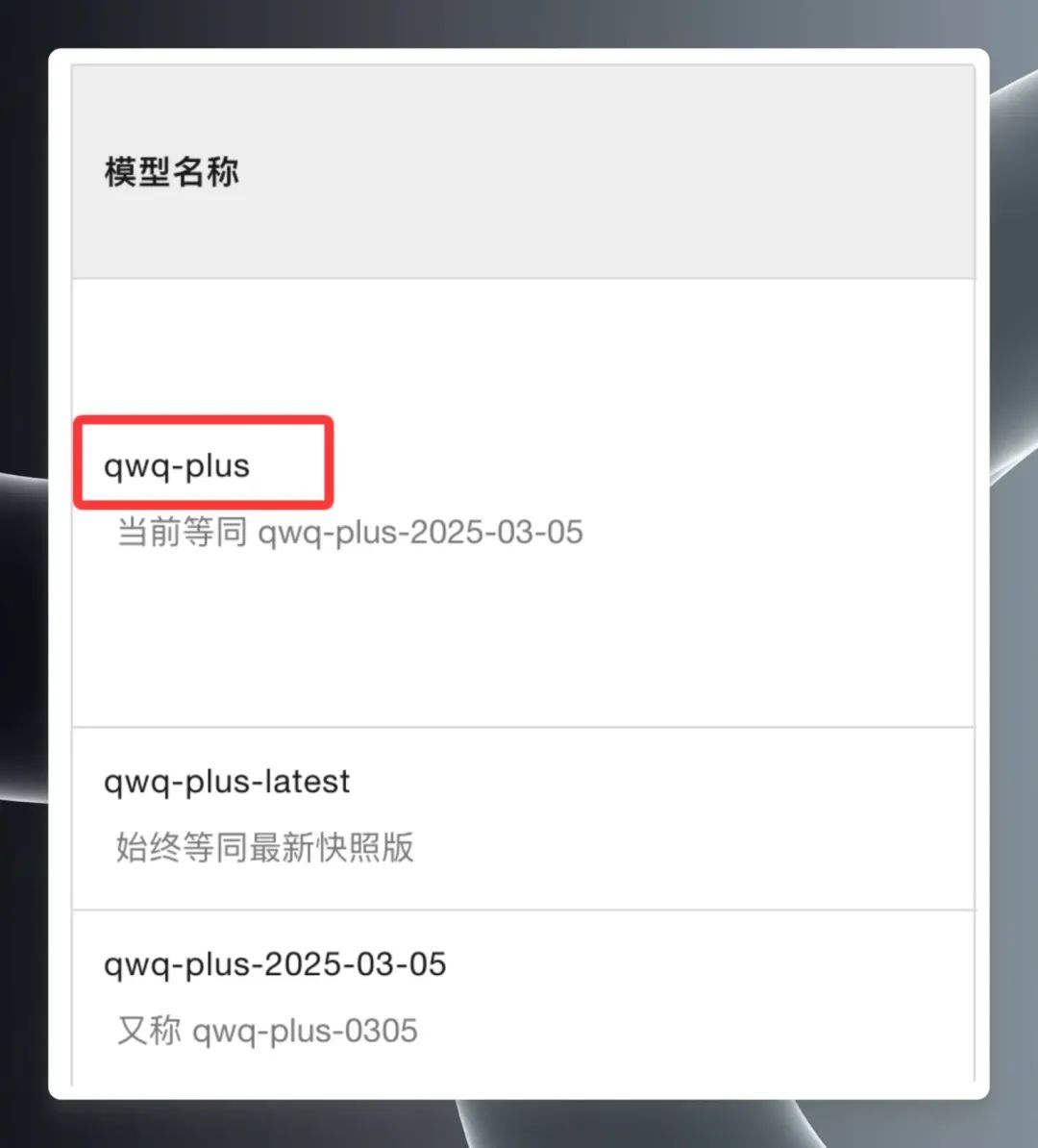
QwQ Plus (Enhanced)" を選択し、"API Call Examples "をクリックし、新しいページで以下を見つける。 モデル名 qwq-plus.
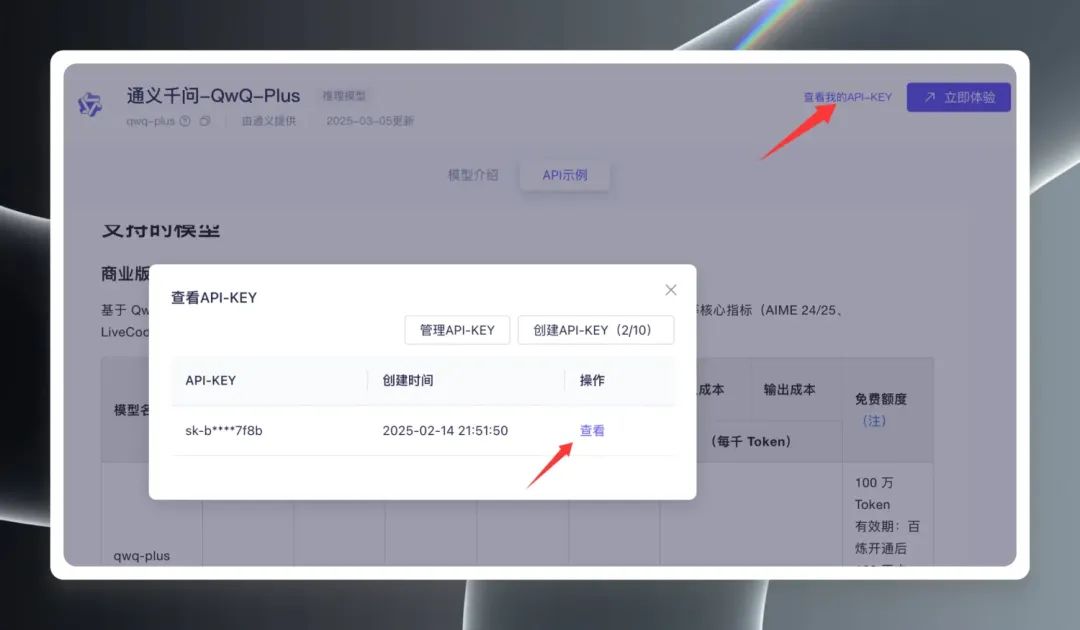
次に、ページ右上の「View My API Key」をクリックします。初めてAPIキーを作成する場合は、APIキーを作成する必要があります。 APIキー.
2.クライアント設定
本稿は以下に基づいている。 Chatwise このクライアントは、デモ用の例として使用されています。Chatwiseソフトウェアを開き、ユーザーのアバターをクリックして "Settings"(設定)画面に進みます。
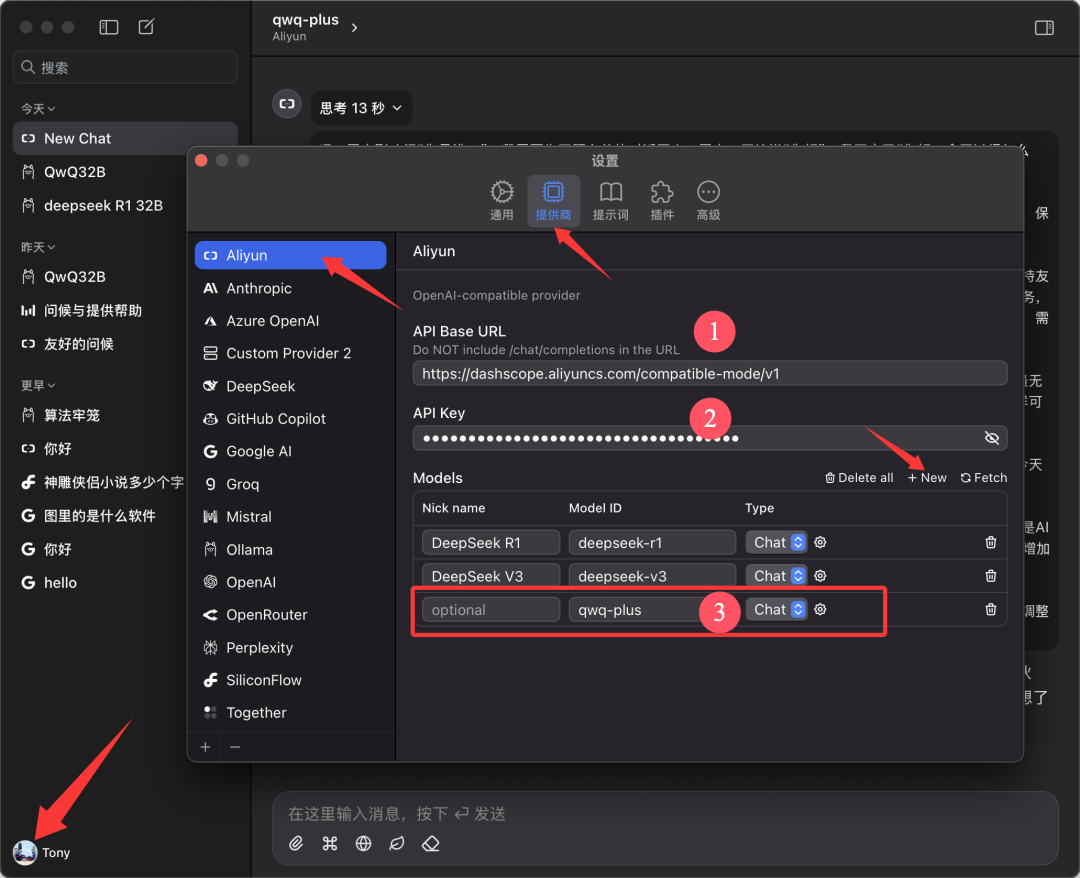
プロバイダーのリストから "Aliyun "を探し、見つからない場合は下部の"➕"をクリックして追加します。
下図のように設定する:
- APIベースURL。
https://bailian.aliyuncs.com(一般) - APIキー 前のステップでコピーしたAPI Keyを貼り付ける。
- モデル モデル名の追加
qwq-plus(名前でなければならない)
3.経験を始める
Chatwiseのメイン画面に戻り、モデル選択ドロップダウンメニューから "qwq-plus "モデルを選択し、対話体験を開始します。
実際のパフォーマンス:ローカル展開と同等かそれ以上
QwQ Plus APIの実際のパフォーマンスを検証するため、簡単な比較テストを行った。
スピードテスト:
測定によると、QwQ Plus APIインターフェースの速度は非常に優れており、40~50トークン/秒と安定している。これに対し ディープシーク R1モデルのAPIでは、10トークン/秒以上とかなり遅い。
互換性テスト:
ユーザーはCherryStudioのようなクライアント上でQwQ Plus APIを構成して使用することもできますが、CherryStudioのテスト中に潜在的な問題が観察されました:モデルが長時間にわたって複雑な推論を実行する場合、CherryStudioは大量のシステムリソースを消費し、構成されたデバイスによってはソフトウェアの再起動が発生する可能性があります。しかし、同じハードウェア環境でChatwiseクライアントを使用した場合、同様の問題は発生しませんでした。これは、クライアントごとの開発フレームワークの違いに関連している可能性があります。
実力比較:
前回の帽子色の論理的推論問題に続き、ローカルのQwQ32モデルとQwQ Plus APIのパフォーマンスを比較します。
問題の説明
赤か青の帽子をかぶった5人が並んでいる。前の人の帽子は見えるが、自分の帽子は見えない。ファシリテーターが、"少なくとも一人、赤い帽子があります "と宣言する。最後の人から順番に「はい」「いいえ」と答える(自分の帽子の色を知っているかどうかを示す)。5人目が「いいえ」、4人目が「はい」と答えた場合、すべての帽子の色の分布を求め る。
ローカルQwQ32モデルのパフォーマンス:

ローカルのQwQ32モデルは、2回目の試行で196秒を要し、最終的に回答が得られた。
QwQ Plus APIパフォーマンス:
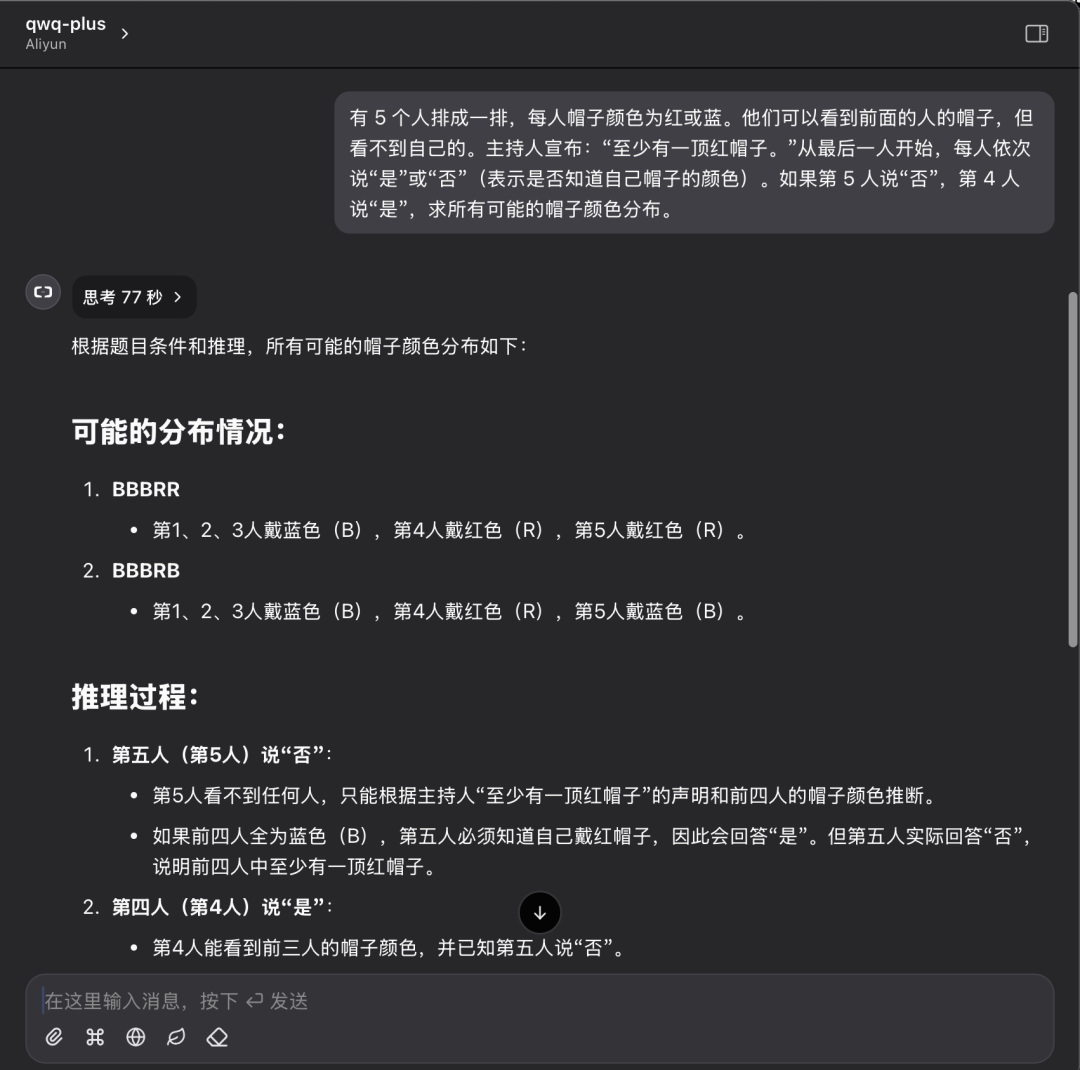
同じ問題に対するQwQ Plus APIのパフォーマンス:77秒で1回だけ正解。
試験結果の分析:
単一のケースはモデルの能力を完全に評価するには十分ではありませんが、このテストの結果は、ローカルに配置されたモデルとクラウドAPIソリューションの違いを視覚的に反映することができます。論理的な推論問題を解く場合、どちらのソリューションも正しい答えを出すことができるが、推論プロセスの効率性と明瞭性という点ではQwQ Plus APIの方が優れており、推論時間が短く、トークンの消費量も少ない。
すべての人にクラウドAIを
AliCloud Hundred RefineプラットフォームでQwQ-32BのAPIインターフェイスを無料で開放し、寛大な無料トークンを提供することは、大規模言語モデリング技術の普及を促進する重要な一歩であることは間違いありません。APIインターフェースにより、ユーザーは高価なハードウェアに投資することなく、クラウド上で高性能AIモデルのパワーを簡単に体験することができます。開発者であれ、研究者であれ、AI愛好家であれ、Aliyun Hundred Refineが提供する無料リソースをフルに活用して、AI探求の旅を始めることができる。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません