
アリババAI研究所、改良型ストリーミング音声合成モデル「CosyVoice 2」を発表


1.概要
近年、音声合成技術は大きな進歩を遂げており、特にリアルタイムで自然かつスムーズな音声生成を可能にしています。しかし、待ち時間、発音の正確さ、話者の一貫性といった問題は、実世界のアプリケーション、特に高い応答性が要求されるストリーミングアプリケーションにおいて、依然として業界を悩ませています。このような技術的課題は、舌打ちやポリフォニックな単語など、既存のモデルの処理能力を超えた複雑な言語入力を扱う場合に特に深刻になります。これらの課題に対処するため、アリババの研究者は、これらの問題を効果的に解決することを目的とした、音声合成の技術的課題のためのアップグレードモデルであるCosyVoice 2を発表しました。
2.コージーボイス2デビュー:基礎からブレークスルーへ
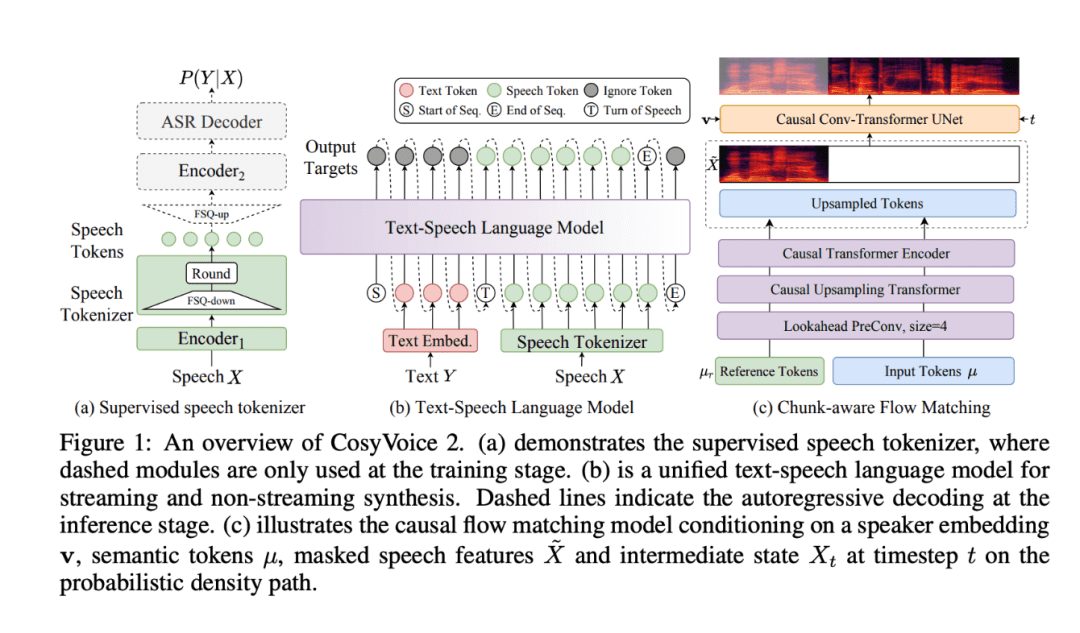 コージーボイス 2はオリジナルのCosyVoiceの基礎の上に構築され、音声合成技術に大幅なアップグレードをもたらします。この強化されたモデルは、ストリーミングアプリケーション用に最適化されているだけでなく、オフラインアプリケーションにおいても大きな進歩を遂げています。特に音声合成や対話音声システムにおいて、幅広いアプリケーションシナリオへの適応性、柔軟性、精度が向上しています。
コージーボイス 2はオリジナルのCosyVoiceの基礎の上に構築され、音声合成技術に大幅なアップグレードをもたらします。この強化されたモデルは、ストリーミングアプリケーション用に最適化されているだけでなく、オフラインアプリケーションにおいても大きな進歩を遂げています。特に音声合成や対話音声システムにおいて、幅広いアプリケーションシナリオへの適応性、柔軟性、精度が向上しています。
CosyVoice 2のコアハイライト:
- 統一されたストリーミングとノン・ストリーミング・モードCosyVoice 2は、リアルタイムで生成されたものであれ、オフラインで処理されたものであれ、パフォーマンスを損なうことなく、様々なアプリケーションシナリオにシームレスに適応します。
- 発音の正確性複雑な言語環境において、CosyVoice 2は30%-50%の発音ミスを減らし、特に多音節の単語や舌を巻くような単語を扱う際に、音声の明瞭度を大幅に向上させます。
- スピーカーの整合性強化ゼロショット合成であれ、言語横断合成であれ、CosyVoice 2は出力が一貫していることを保証し、すべての合成が自然でスムーズであるようにします。
- より正確な指揮コントロールユーザーは、自然言語コマンドによって声のトーン、スタイル、アクセントを正確にコントロールすることができ、感情的なニーズに合わせて声のパフォーマンスを調整することもできます。
3.技術革新の背景にある技術と強み
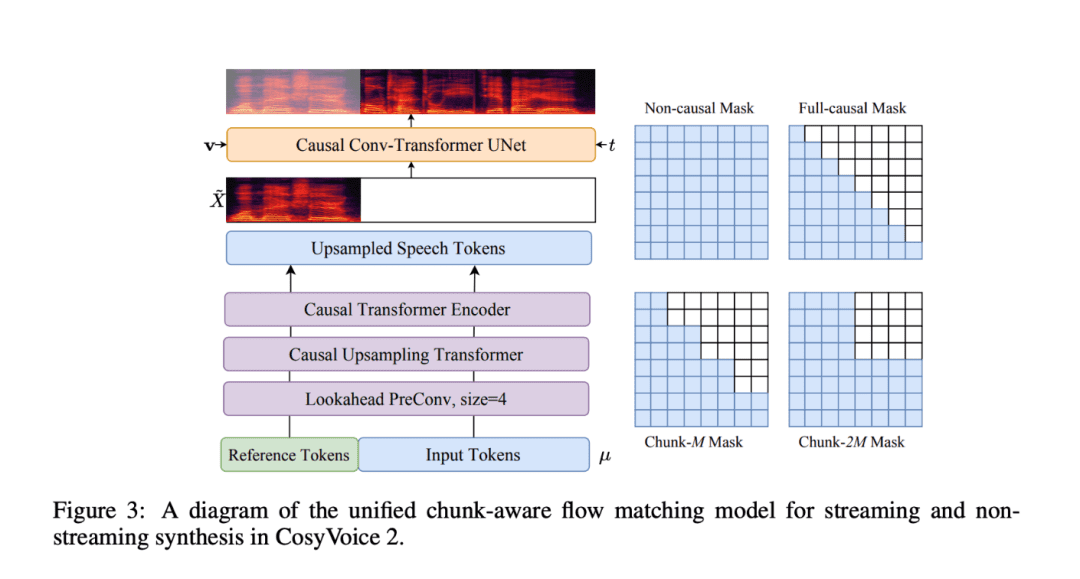
CosyVoice 2は、その技術における数々の革新のおかげで、音声合成の分野における数々の課題を解決することができた。
- 有限スカラー数量化(FSQ)技術:FSQは、従来のベクトル数量化手法に代わり、音声タグ付き語彙の使用を最適化することで、意味表現能力と合成品質を向上させます。この技術革新は、モデルの表現力を高めるだけでなく、データ処理の複雑さを効果的に軽減します。
- 簡素化された音声合成アーキテクチャ: CosyVoice 2は事前にトレーニングされた大規模言語モデル(LLM)をベースとしているため、テキストエンコーダを追加する必要がなく、モデルアーキテクチャを簡素化することで言語間のパフォーマンスを向上させます。このアーキテクチャー設計により、CosyVoice 2は多言語処理時の効率と精度が大幅に向上します。
- ブロック認識因果フロー・マッチング: この革新的なテクノロジーにより、意味的特徴と音響的特徴が最小限の待ち時間で整合され、CosyVoice 2はリアルタイム音声生成、特にリアルタイムの音声対話やストリーミング・アプリケーションで優れた能力を発揮します。
- 拡張されたコマンドデータセット: 1500時間を超えるトレーニングデータにより、CosyVoice 2は様々なアクセント、感情、声のスタイルをきめ細かくコントロールし、音声合成をより柔軟で表現力豊かなものにします。温かみのある声のトーンでも、緊張した感情でも、CosyVoice 2は正確にとらえ、表現することができます。
4.CosyVoiceの性能2:現実の問題をどのように解決するか
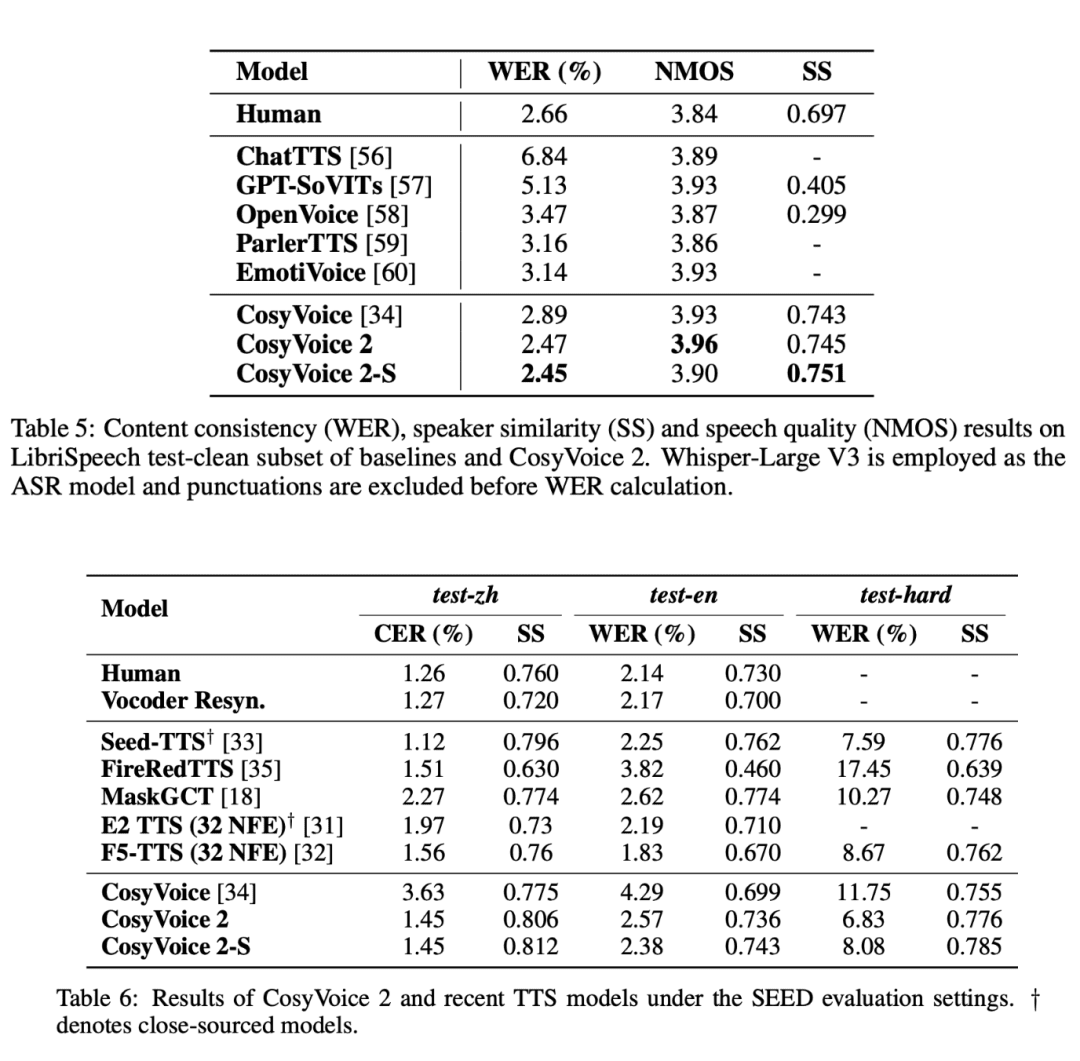
一連の厳しい評価テストにおいて、CosyVoice 2は、特に低遅延、高精度、音声の一貫性という点で、紛れもない利点を実証した。
- 低レイテンシーと高効率CosyVoice 2は、音声生成の応答時間が150ミリ秒と短いため、音声チャットやストリーミング・インタラクションなどのリアルタイム音声アプリケーションに最適です。
- 発音精度の向上CosyVoice 2は複雑な言語構造(例:多音節、舌打ちなど)を大幅に強化し、発音の正確性を飛躍的に向上させ、日常的な音声合成におけるエラーを減らします。
- 安定したスピーカー性能CosyVoice 2は、異言語合成やゼロショット合成など、異なる合成タスクにおいても高い一貫性を維持することができ、音声の自然さと安定性が保証されています。
- 多言語主義CosyVoice 2は、日本語や韓国語などの言語のベンチマークでも好成績を収めており、文字セットの重複という課題はあるものの、言語横断的な合成の威力を発揮しています。
- 困難なシナリオにおける回復力CosyVoice 2は、難易度の高いスピーチシナリオ(舌打ちなど)において、従来のモデルよりも明瞭で正確であることを実証し、これまでの技術的限界を超えました。
5.結論
CosyVoice 2の発売は、音声合成技術における重要な進歩です。FSQやブロックを意識した因果フローマッチングなどの革新的な技術は、このモデルの性能と使いやすさを強力にサポートします。また、大規模なトレーニングデータセットと発話スタイルの正確な制御により、幅広い複雑な音声アプリケーションシナリオに対応することができます。
CosyVoice 2は、多言語サポートや複雑な言語シナリオの処理という点で、さらなる改良が必要ではあるが、将来の音声合成技術、特に幅広い発展が期待されるストリーミングメディアやリアルタイム音声生成の応用において、確固たる基盤を築いた。AI音声アシスタント、インテリジェントな顧客サービス、リアルタイム翻訳のいずれの分野においても、CosyVoice 2はその強力な潜在能力を発揮し、音声合成技術のさらなる飛躍への道を開く。
参考までに:
- https://arxiv.org/abs/2412.10117
- https://huggingface.co/spaces/FunAudioLLM/CosyVoice2-0.5B
- https://www.modelscope.cn/models/iic/CosyVoice2-0.5B
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません