AI検索」評価ベンチマークの第1回リストが発表された!4oのトップマージンは小さく、5拠点、11シナリオ、14モデルの合計で国産大型モデルが冴え渡る。


中国ビッグモデルAI検索(SuperCLUE-AISearch)ベンチマーク評価のリリースは、ビッグモデルと検索を組み合わせた能力の詳細な評価です。この評価では、ビッグモデルの基本的な能力に焦点を当てるだけでなく、シナリオアプリケーションでの性能も検証しています。評価対象は、情報検索や最新情報取得など5つの基本能力と、ニュースや生活アプリケーションなど11のシナリオアプリケーションであり、異なる基本能力とシナリオアプリケーションのタスクにおける検索を組み合わせたモデルの性能を総合的に検証している。評価スキームについては、「「AI検索」ベンチマーク評価スキーム公開」を参照。今回は、国内外の代表的な大型モデル14機種のAI検索能力を評価しましたので、以下に詳細な評価レポートを掲載します。
AI検索評価サマリー
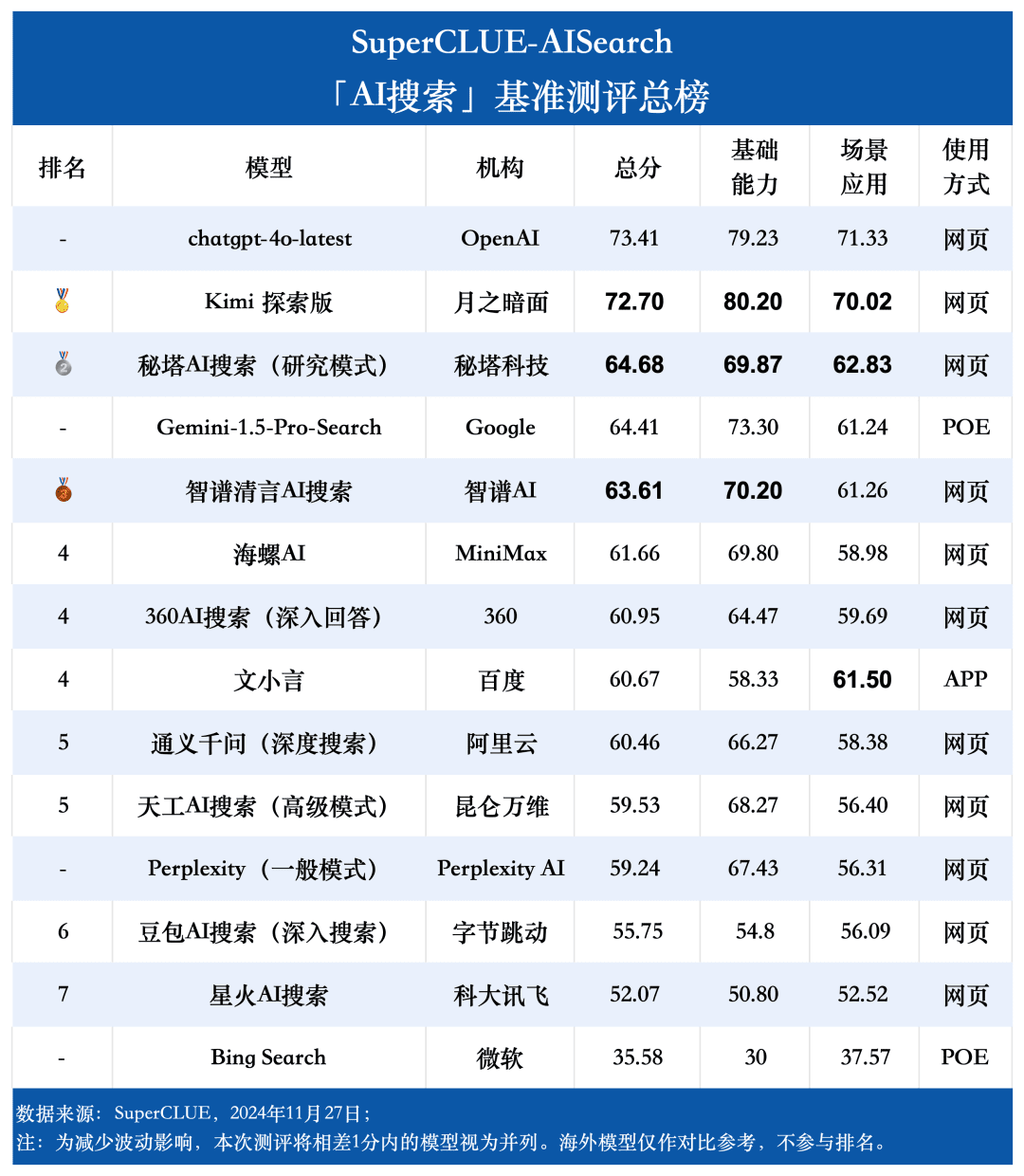
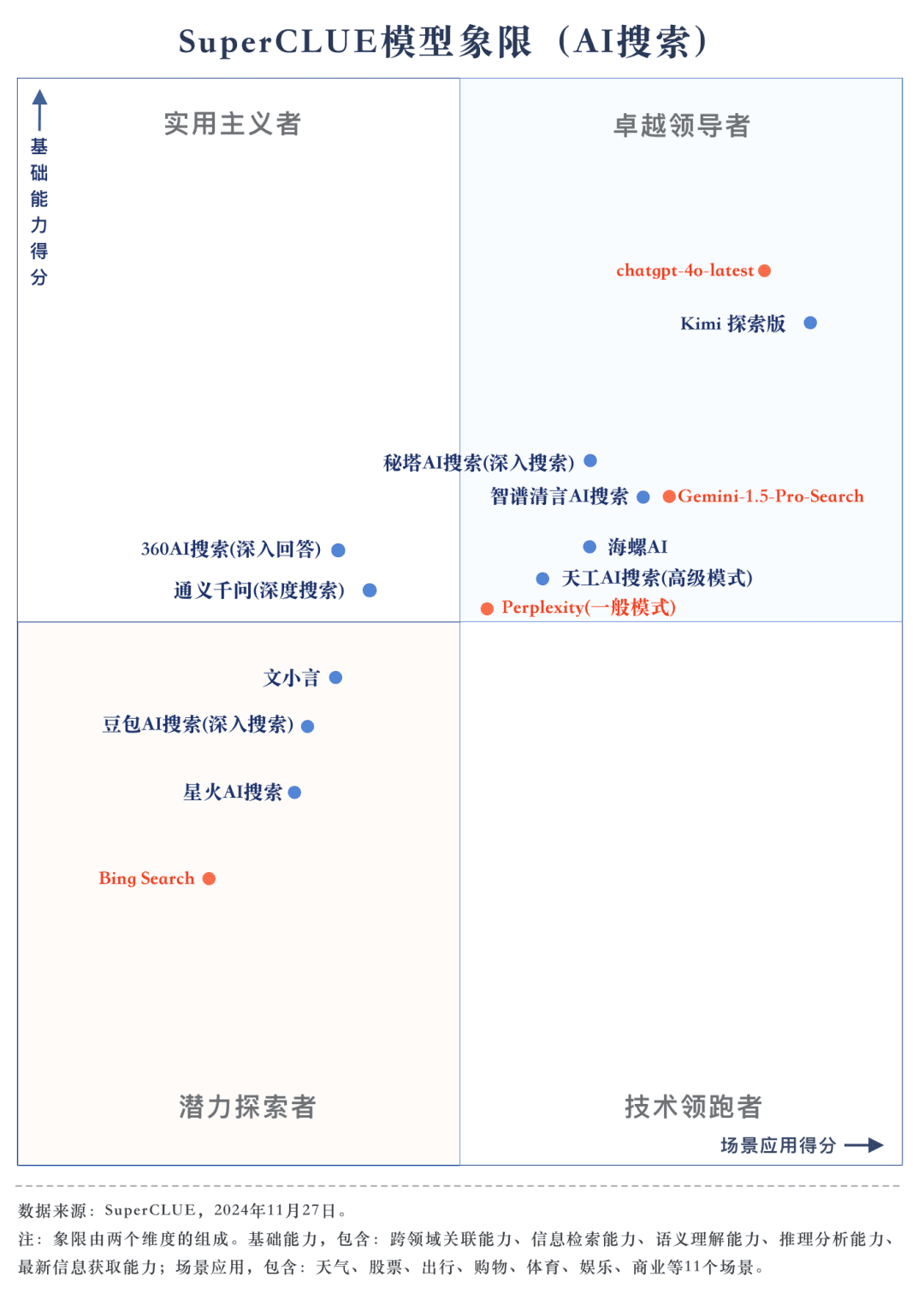
測定ポイント1今回の評価では、chatgpt-4o-latestが73.41点を獲得し、他の参加機種を抑えて優秀な成績を収めた。一方、国内大手モデル キミ エクスプローラー・エディションのパフォーマンスも特筆すべきもので、シナリオ・アプリケーションのショッピングや文化的なトピックで高いパフォーマンスを発揮し、優れたAI検索能力を示すとともに、多次元で優れた包括的パフォーマンスを示している。
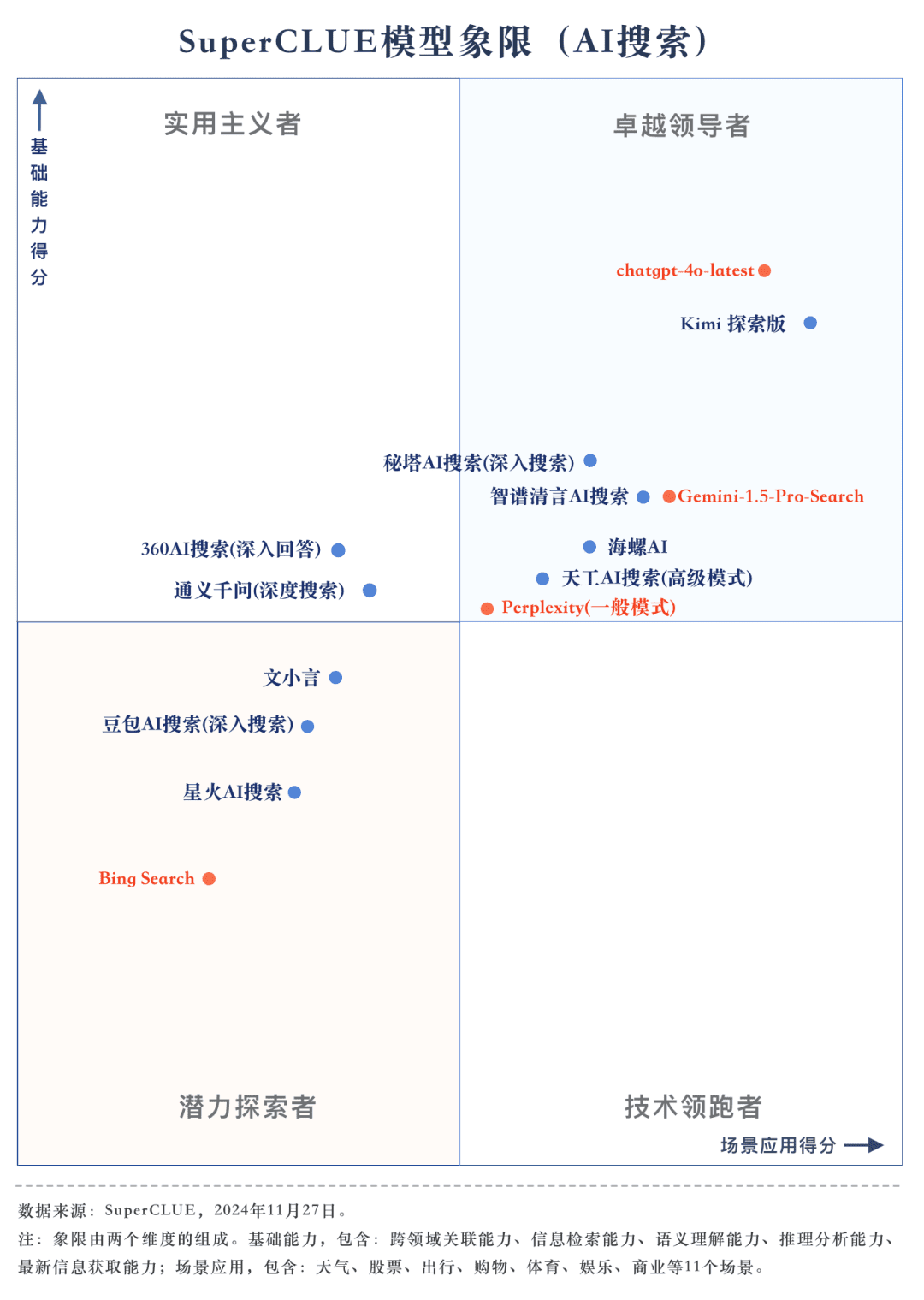
測定ポイント2国産ビッグモデルの総合性能は非常に印象的で、いくつかの海外ビッグモデルを凌駕している。 評価結果から見ると、秘密タワーAIサーチ(リサーチモード)、ウィズダムスペクトル明瞭スピーチAIサーチ、コンクAIなどの国産ビッグモデルの総合性能はより印象的で、海外ビッグモデルのGemini-1.5-Pro-Searchと同等である。それとは別に、360AI検索(詳細回答)、文小銀、同伊銭奇(深層検索)など、総合性能の中間に位置するいくつかの国内ビッグモデルの性能は似て非なるもので、わずかな差を見せている。
測定ポイント3各モデルの性能は、シナリオ・アプリケーションによって異なる。AI検索評価では、シナリオ用途別の各ビッグモデルの性能にも着目した。国産ビッグモデルは、科学技術、文化、ビジネス、エンターテイメントなどのシナリオでは比較的良好な結果を示し、情報の適時性を把握しつつ、優れた情報検索・統合能力を発揮した。しかし、株式やスポーツなどのシナリオ・アプリケーションでは、国産ビッグモデルにはまだ改善の余地がある。
リストの概要
SuperCLUE-AISearchの紹介
SuperCLUE-AISearchは、中国語のAI検索モデルの包括的な評価セットであり、中国語ドメインにおけるAI検索モデルの能力を評価するためのリファレンスを提供することを目的としている。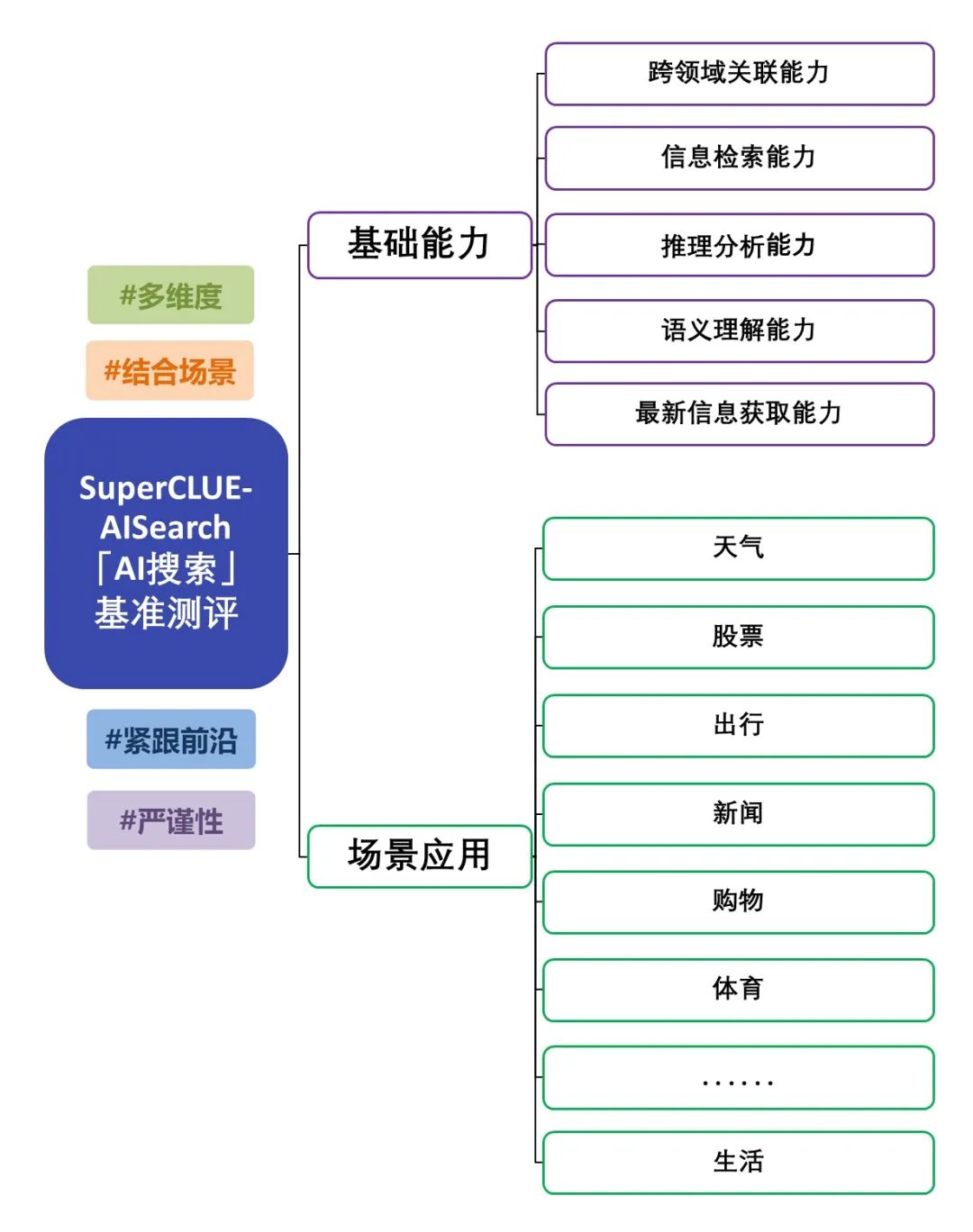
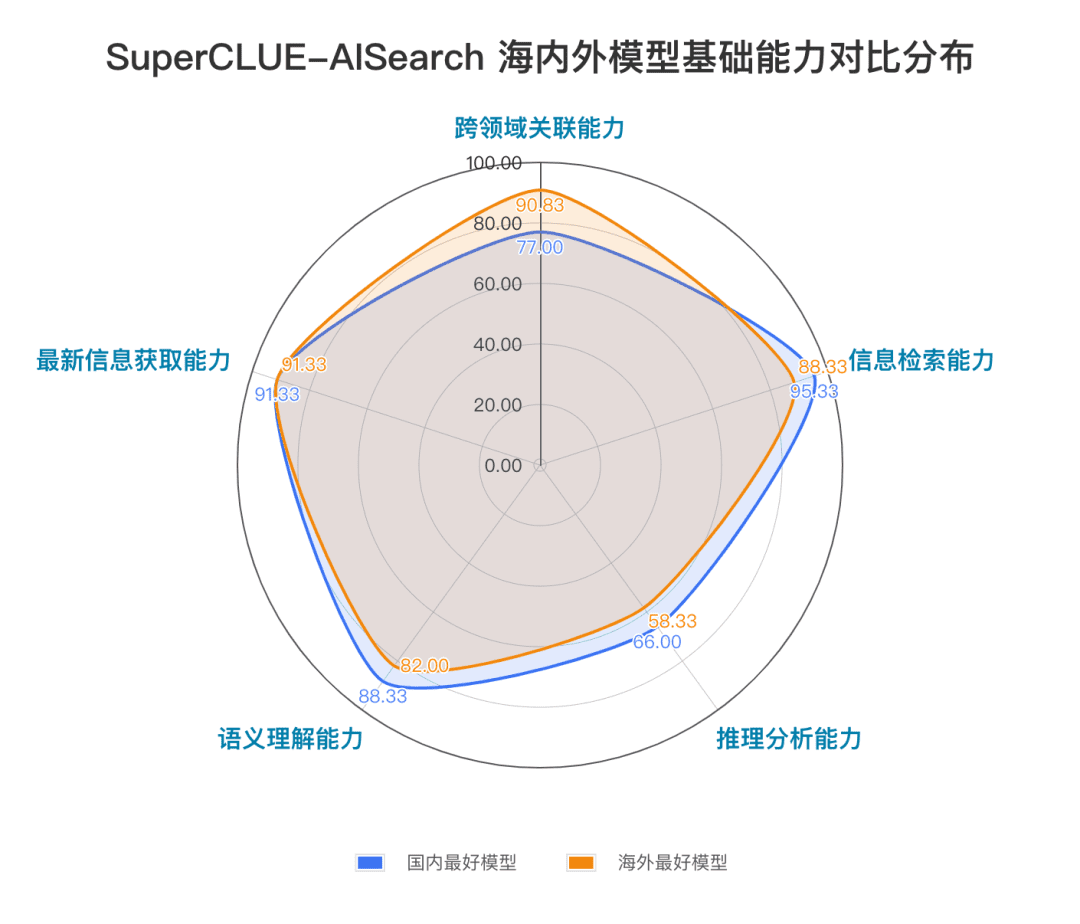
基礎的能力には、AI検索タスクに必要な5つの能力(領域横断的関連性、情報検索、意味理解、最新情報取得、推論)が含まれる。
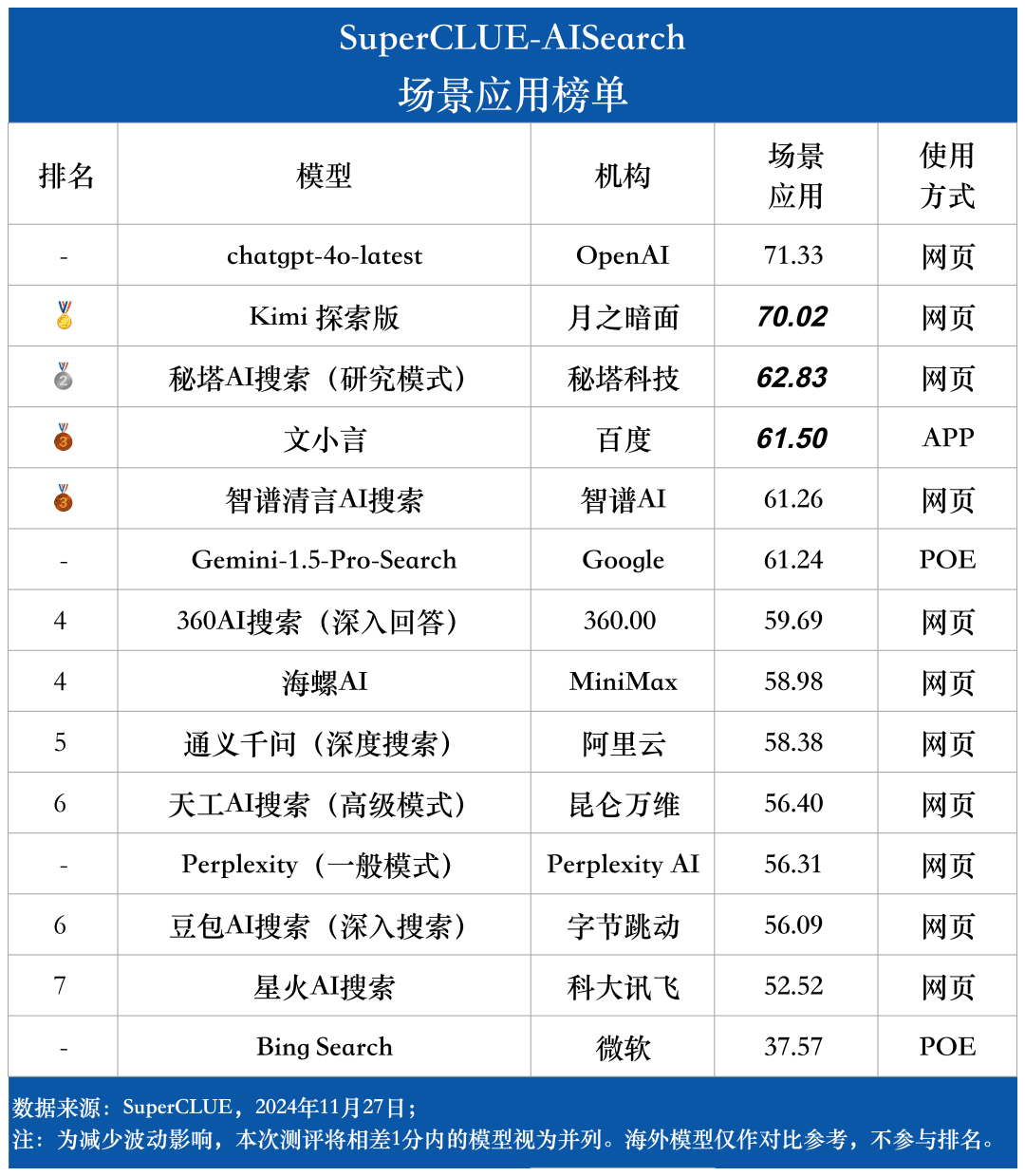
シナリオ・アプリケーションには、天気、株式、旅行、ニュース、ショッピング、スポーツ、エンターテインメント、教育、旅行、ビジネス、文化、テクノロジー、ヘルスケア、生活という、AI検索タスクによくある11のシナリオが含まれている。
方法論
SuperCLUEのきめ細かな評価アプローチを参照すると、専用の測定セットが構築され、各次元がきめ細かなレベルで評価され、詳細なフィードバック情報を提供することができる。
1) 測定セットの構成
中国語プロンプト作成プロセス:1.既存プロンプトの参照 ---> 2.中国語プロンプトの作成 ---> 3.テスト ---> 4.中国語プロンプトの修正と最終化、各次元専用の評価セットの構築。
2) 採点方法
評価プロセスは、モデルとデータセットの相互作用から始まり、提供された質問に基づいて理解し、回答する必要がある。
評価基準は、思考プロセス、問題解決プロセス、内省、調整といった次元をカバーしている。
採点ルールは、自動化された定量的採点と専門家によるレビューを組み合わせることで、評価の科学性と公平性を確保しながら効率的に採点する。
3) 採点基準
評価タスクにおける各マクロモデルの応答品質の評価には、評価セットの主観的質問と客観的質問をそれぞれ評価するために2つの評価基準を使用した。これらの評価基準は、AI検索タスクにおけるグランドモデルの性能を完全に反映するために、評価において異なる重みを与えた。
SuperCLUE-AISearchの評価システムは、主観的な問題を5点満点で採点するように設計されており、情報の有用性、分析精度、表現の明確さの次元から評価され、そのうち情報の有用性は60%、分析精度は20%、表現の明確さは20%を占める。客観的な問題の採点基準は、情報の正確さと表現の明確さの次元から評価され、そのうち情報の正確さは80%、表現の明確さは20%を占める。客観問題の採点基準は5点満点で、情報の正確さと表現の明確さの2つの側面から評価され、そのうち情報の正確さは80%、表現の明確さは20%を占める。 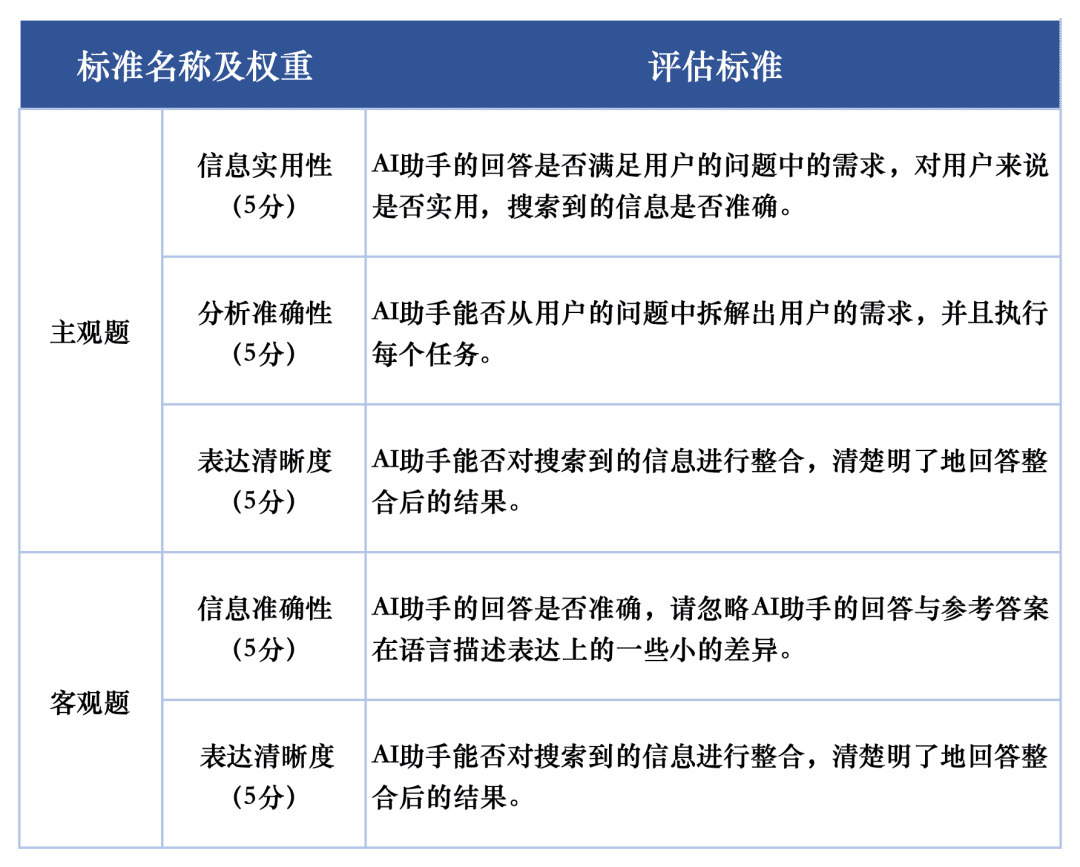
評価例
プロンプトword プロンプト:神舟19号有人宇宙船はいつ、どこで打ち上げられ、この時の宇宙飛行士は誰でしたか?
答え:10月30日未明、九泉衛星発射センターからの有人宇宙船「神舟19号」の打ち上げは完全な成功を収めた。有人宇宙船「神舟19号」の乗組員は、蔡旭喆、宋玲東、王海沢の3名。
模範解答:
スーパーモデル(chatgpt-4o-latest)のレフェリー:
この答えを次のように評価する:
AIアシスタントの回答は、有人宇宙船「神舟XIX」の打ち上げ時刻と場所、宇宙飛行士のリストを正確に伝えていた。しかし、その回答はミッションの主な目的やミッション内容には触れておらず、ミッションの詳細を知りたいというユーザーのニーズを十分に満たすことができなかった。また、宇宙飛行士の個人的なプロフィールの項目は、詳細ではあるものの、ユーザーの関心の範囲を超えていた可能性がある。したがって、ミッションの目的と主な任務についての簡単な説明を回答に加えることで、ユーザーのニーズをより十分に満たすことが推奨される。1.情報の有用性(5点):
AIアシスタントは、神舟XIXの打ち上げ時間、場所、宇宙飛行士のリストを提供し、この基本的な情報に対するユーザーのニーズを満たした。しかし、ミッションの主な目的とミッションの内容については言及されず、ミッションの詳細を知りたいというユーザーのニーズを十分に満たすことはできなかった。したがって、情報の有用性のスコアは 4 となった。
スコア:4/52 分析の正確さ(5点):
AIアシスタントは、ユーザーの質問から打ち上げ時刻、場所、宇宙飛行士のリストなどの重要な情報を正確に抽出し、詳細な個人プロフィールを提供した。しかし、ミッションの目的や主なミッション内容には対応しておらず、ユーザーのニーズを十分に満たすことはできなかった。そのため、分析精度は4点とした。
スコア:4/53。表現の明確さ(5点):
AIアシスタントの回答は明確に構成されており、理解しやすいように情報が整理されている。個人プロフィールの項目は詳細で、ユーザーは宇宙飛行士の経歴を理解しやすい。よって、表現のわかりやすさは5点。
スコア:5/5 合成スコア = 4*0.6 + 4*0.2 + 5*0.2 = 4.2 上記を組み合わせると、AIアシスタントの回答の合成スコアは4.2となる。(5点満点)
参加モデル
AI検索能力における国内外のビッグモデルの現在の発展レベルを総合的に測定するため、今回の評価では海外モデル4機種と国内代表モデル10機種を選定した。
国内外の多くの大型モデルが、一般的に通常版と詳細探索版の2つ以上のバージョンを提供していることに鑑み、今回のモデル選定プロセスでは、より詳細な探索版や分析版を備えているモデルについては、最も探索能力の高いバージョンを選択して総合的に評価するという統一基準を採用する。 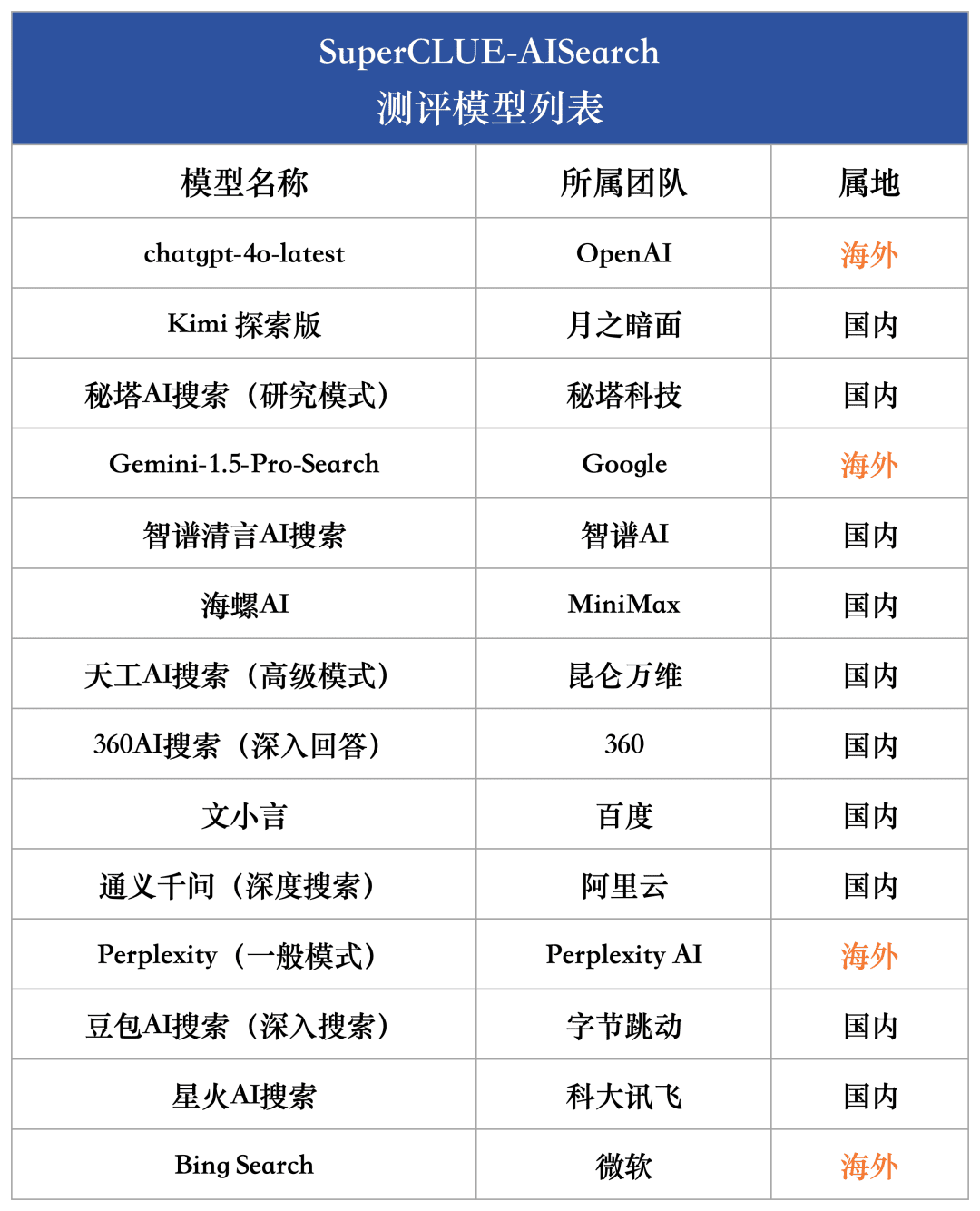
評価結果
全体リスト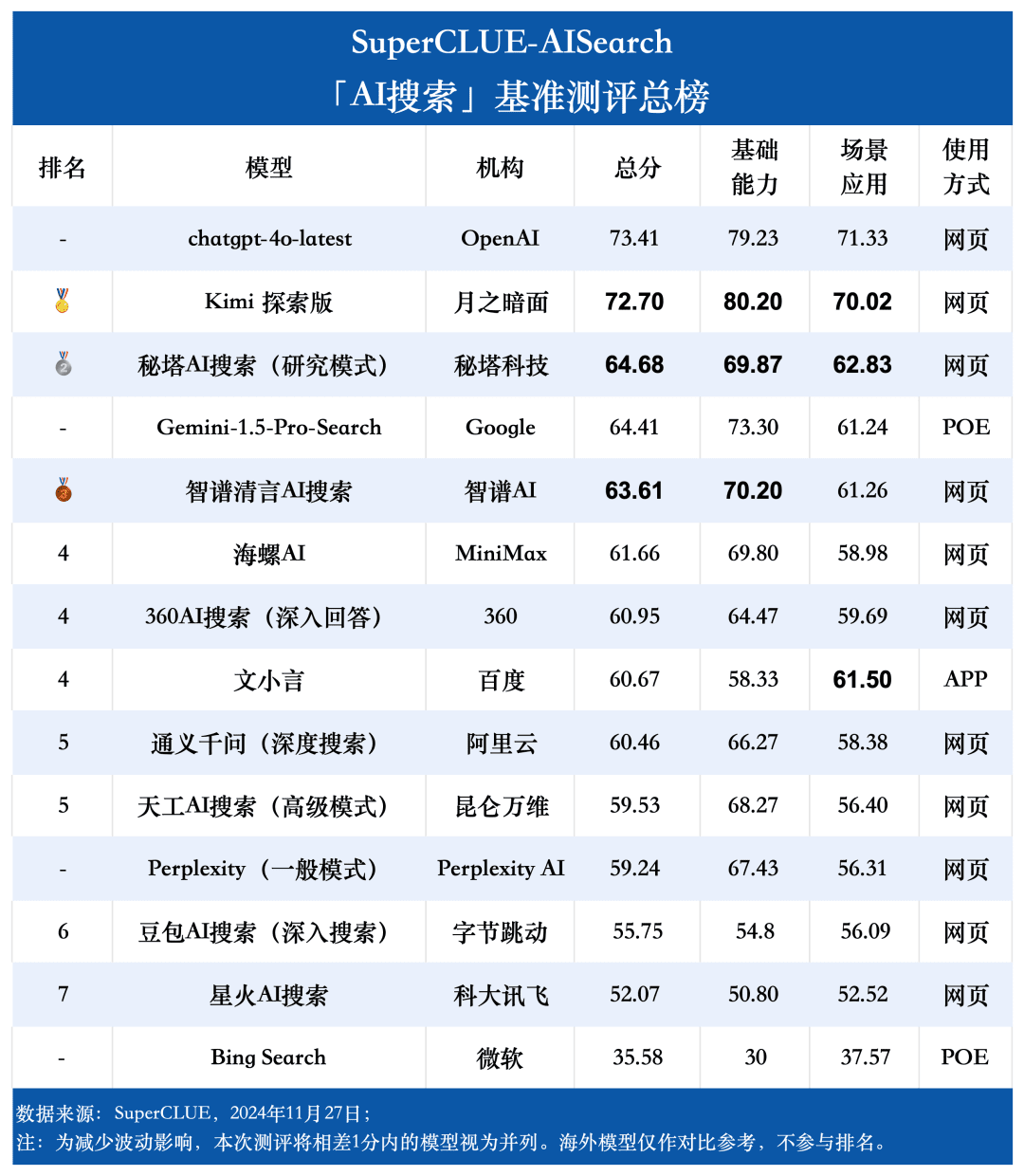
基本能力一覧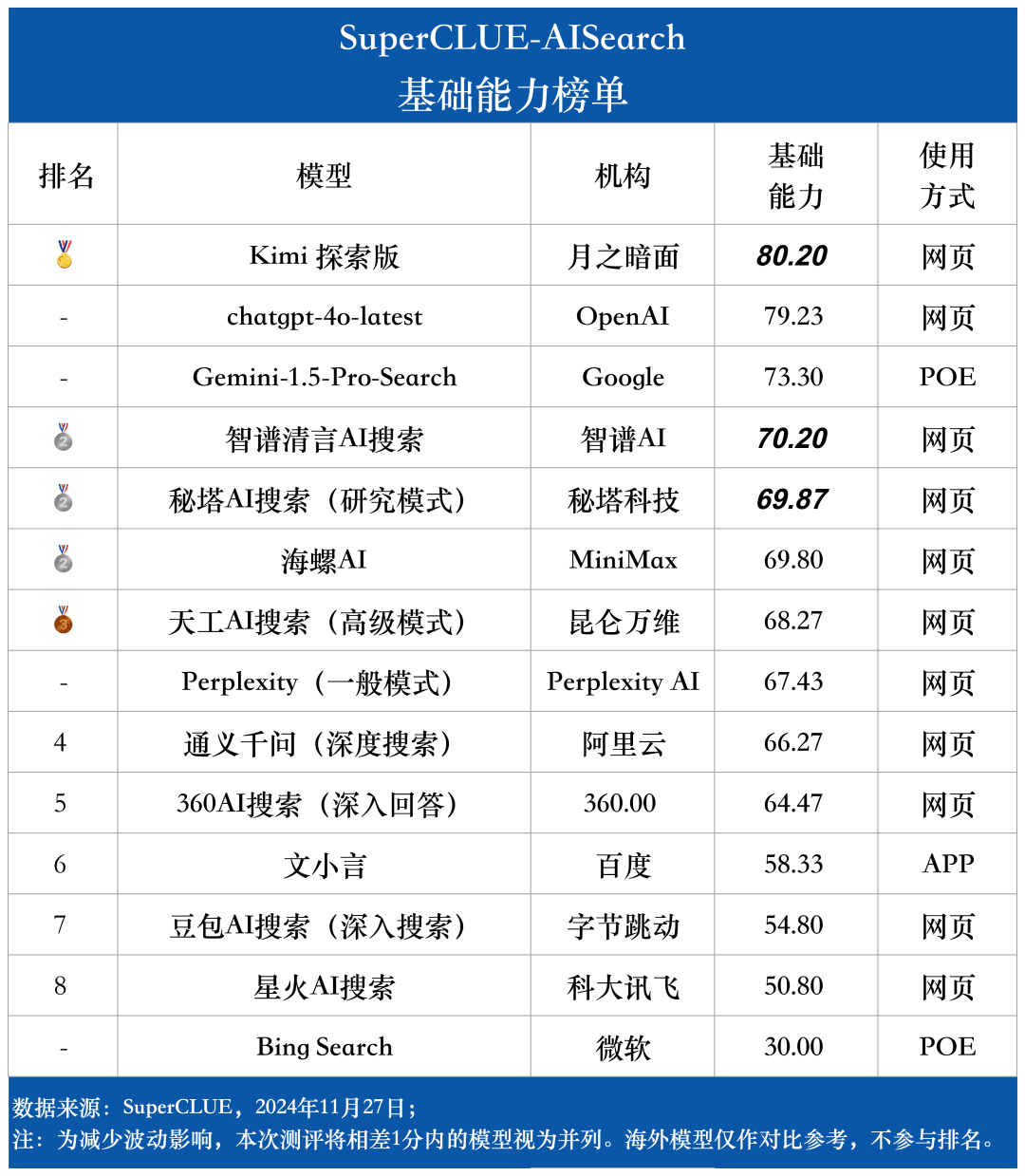
シナリオ応募一覧
主観的質問リスト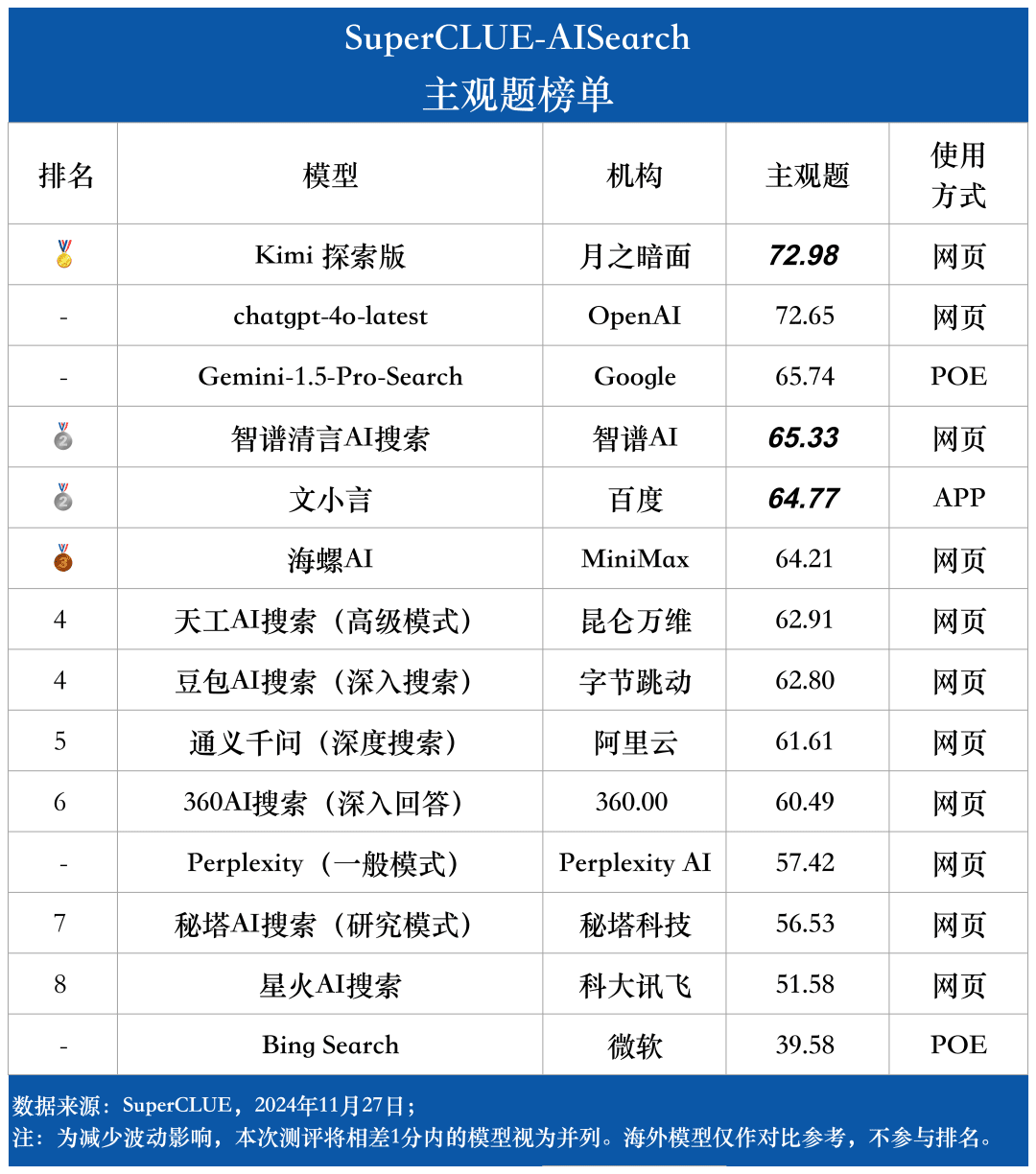
客観的問題のリスト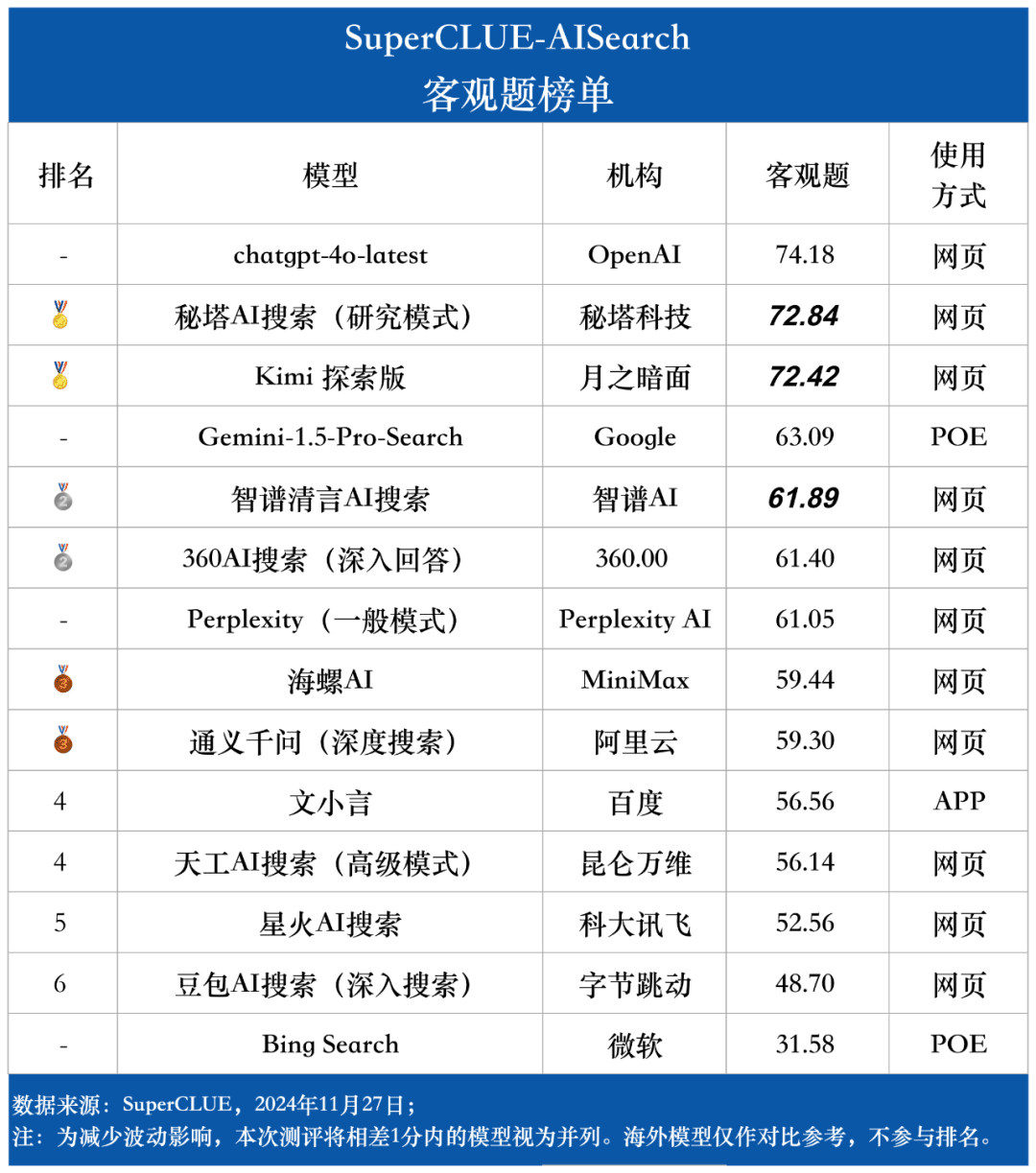
モデルの比較例
例1 基本的なスキル - 推論力と分析力
プロンプト:「なぜGPT-1モデルの構造が使われているのですか? 変圧器 LSTMの代わりに?
モデルの回答の比較(5点満点):
[キミ・エクスプローラー】:4点 
[chatgpt-4o-latest】:3.9点 
[スカイワークスAIサーチ(アドバンスモード)】:3.4点 
例2 基本コンピテンシー - 分野横断的なつながり
プロンプトPrompt: "農業におけるコンピュータ・ビジョン技術の応用例について調べて、その中から3つを選び、それぞれについて簡単に説明してください。"
モデルの回答の比較(5点満点):
[秘密のタワーAI探索(リサーチ・モード)】:4点 
[温小燕】:3.4点 
[スターファイアAIサーチ】:3点 
例3 シナリオの適用 - 株式
プロンプトPrompt: "近年の A 株におけるいくつかの重要な強気相場とその関連データ(開始時期、期間、上昇率、最高値と最安値など)について教えてください。"モデル回答の比較(5点満点): [Gemini-1.5-Pro-Search]: 3.2点 
[スマートスペクトル明瞭音声AI検索】:3.3点 
ビングサーチ】:2.6ポイント 
例4 シーン・アプリケーション-ライフ
プロンプト:"今年1月から10月までの中国の自動車生産台数と販売台数はそれぞれ何百万台に達し、前年同期比で何%増加したか?"
モデルの回答の比較(5点満点):
[とんぎ千題(徹底検索)】:4.2点 
[360AI検索(詳細回答)】:3.8点 
人間の一貫性評価
大規模モデルの自動評価の科学的妥当性を確保するため、AI検索評価タスクでGPT-4o-0513の人間による一貫性を評価した。
具体的な操作方法は以下の通りです:5つのモデルを選択し、主観的質問と客観的質問の異なる次元について、各モデルをそれぞれ1人の人間が独立して採点し、採点基準に従って重み付けして平均化します。各質問について、人間の得点とモデルの得点の差を計算し、合計して平均し、各質問の平均ギャップを人間の一貫性評価の評価結果とします。
最終的に得られた平均結果は以下の通りである:平均分散結果(単位:パーセント):5.1ポイント
この自動評価は信頼性が高いからだ。
評価分析と結論
1.AI検索総合能力、chatgpt-4o-latestはリードし続ける。
評価結果からわかるように、chatgpt-4o-latest(73.41点)は総合力に優れ、SuperCLUE-AISearchベンチマークをリードしている。国産最高機種であるキミエクスプローラーとの差はわずか0.71ポイントである。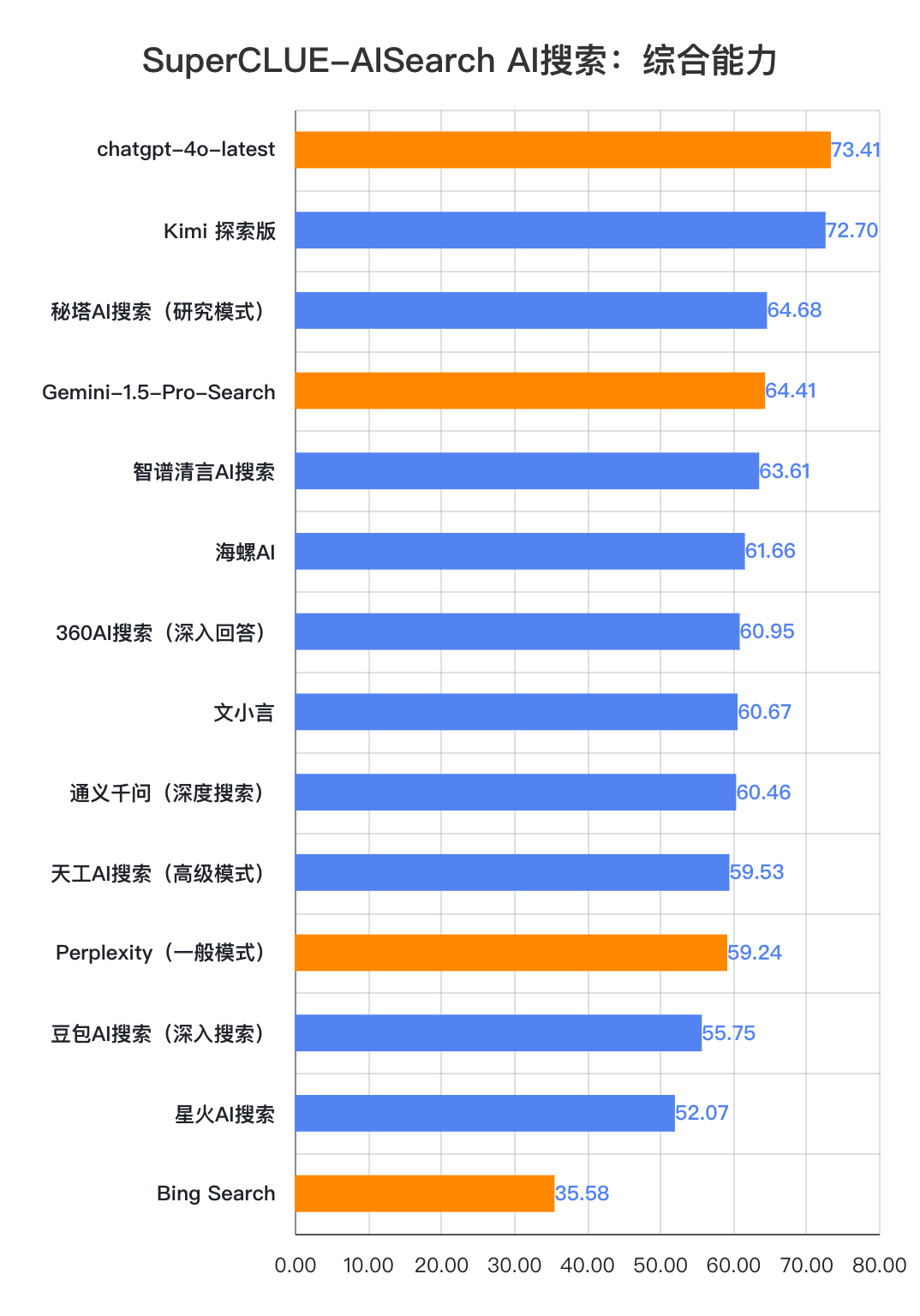
2.国内の大型モデルの総合的なパフォーマンスは非常に素晴らしく、モデル間の差は比較的小さい
評価結果から、秘密塔AI探索(研究モデル)、智慧スペクトル明瞭音声AI探索、コンクAIなどの国産モデルは、基本性能の面で比較的良好であり、海外の大型モデルGemini-1.5-Pro-Searchに追いつく勢いがある。全体的には、Conch AI、Wen Xiaoyin、Tongyi Qianqian(ディープサーチ)など、総合成績の中位に位置するいくつかの国内モデルの性能は、モデル間で遜色なく、わずかな差を見せている。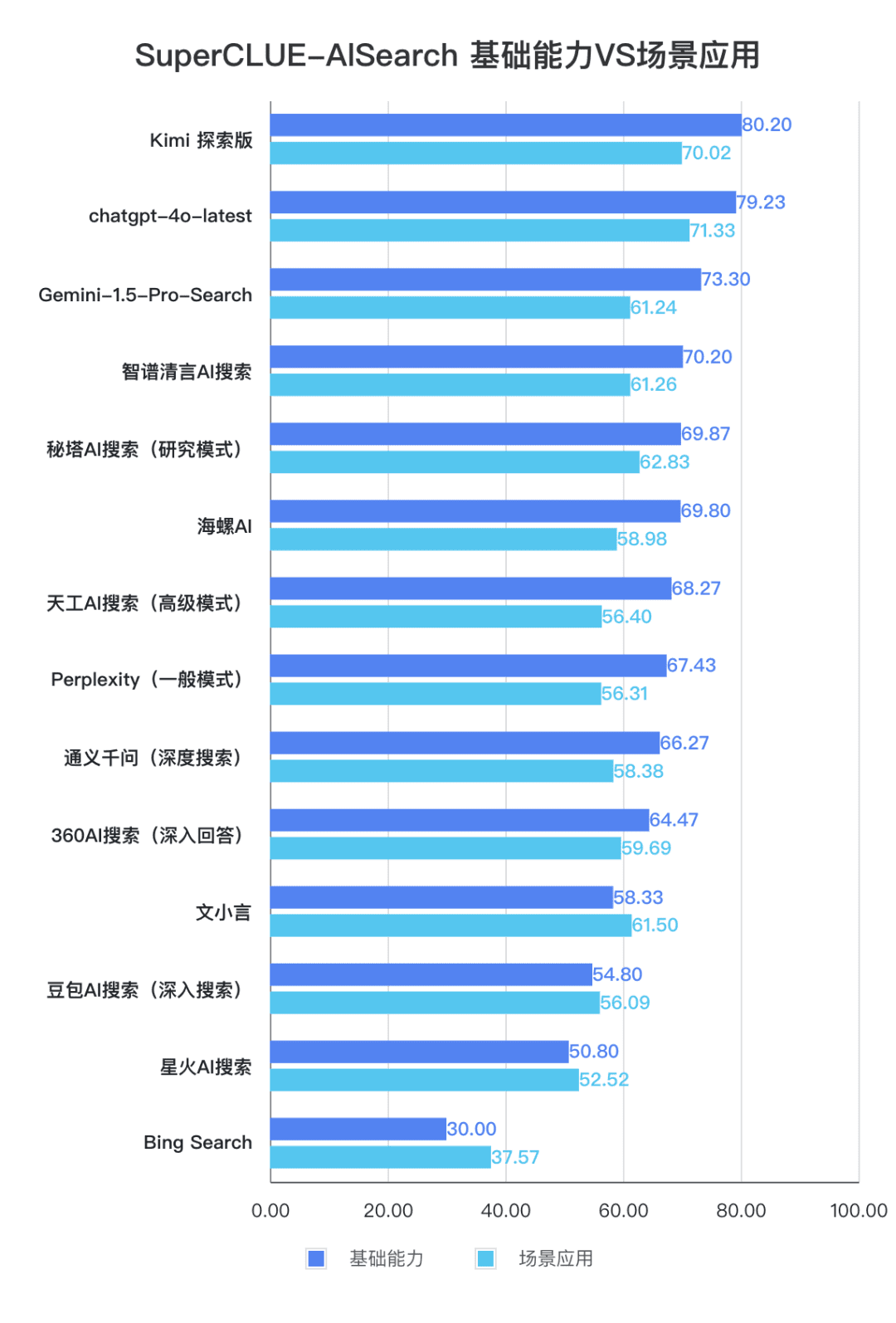
3.モデルは、異なるシナリオのアプリケーションで異なるレベルの性能を示す。
AI検索の検討では、様々な適用シーンにおけるモデルの性能に注目した。国産ビッグモデルは、科学技術、文化、ビジネス、エンターテインメントの各シナリオで優れた性能を発揮し、情報の適時性を正確に把握するとともに、情報の検索と統合に優れた能力を示した。しかし、株式やスポーツのシナリオでは、国産ビッグモデルにはまだ明らかな改善の余地がある。
例えば、AI検索の過程では、モデルはユーザーの検索ニーズを正確に分解し、正確な時間的情報を持つ正しい関連ウェブページを検索し、最後に情報を統合して、ユーザーにとって実用的な回答結果のコピーを形成する必要がある。現在の観察によると、国産ビッグモデルは検索ニーズを正確に分析できないことがあり、情報を統合する過程で関連性のないウェブコンテンツを参照することがある。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません