AI工学アカデミー:2.4 検索拡張世代(RAG)システムのためのデータチャンキング技術

簡単
データチャンキングは、検索拡張世代(RAG)システムにおける重要なステップである。これは、効率的な索引付け、検索、処理のために、大きな文書を管理可能な小さな断片に分解するものである。このREADMEは以下を提供する。 ラグ パイプラインで利用可能な様々なチャンキング方法の概要。
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_Data_Ingestion
RAGにおけるチャンキングの重要性
効果的なチャンキングはRAGシステムにとって非常に重要である:
- 首尾一貫した自己完結型の情報単位を作成することで、検索精度を向上させる。
- 埋め込み生成と類似検索の効率化。
- 応答を生成する際に、より正確なコンテキストを選択できるようにする。
- の言語モデルと組み込みシステムの管理を支援する。 トークン 制限。
チャンキング方式
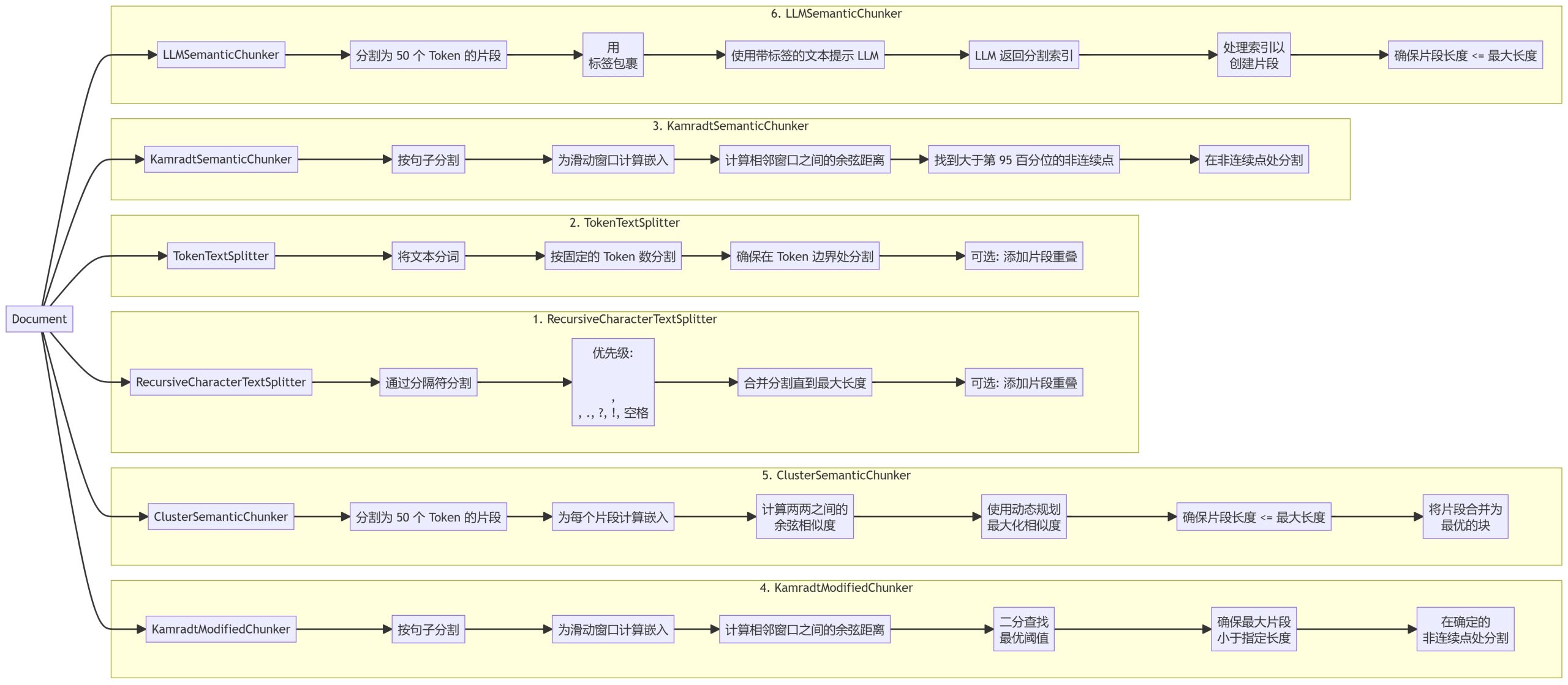
私たちは6つの異なるチャンキング方法を実装し、それぞれ異なる利点と利用シーンを持っている:
- 再帰的文字テキスト分割器
- トークン テキスト スプリッタ
- カムラット・セマンティック・チャンカー
- カムラット・モディファイド・チャンカー
- クラスターセマンティックチャンカー
- LLMSemanticChunker
チャンキング
1.再帰的文字テキスト分割器
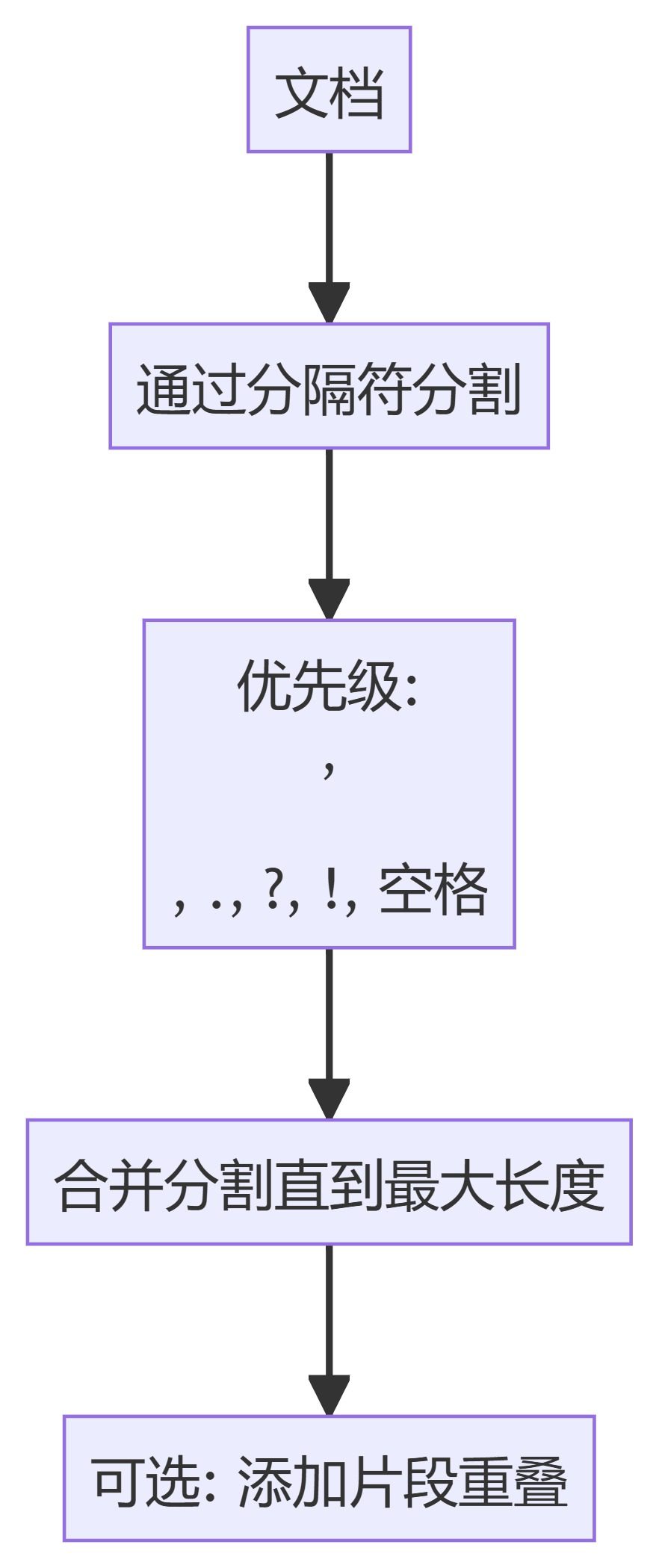
2.トークン テキスト スプリッター

3.KamradtSemanticChunker(カムラット・セマンティック・チャンカー
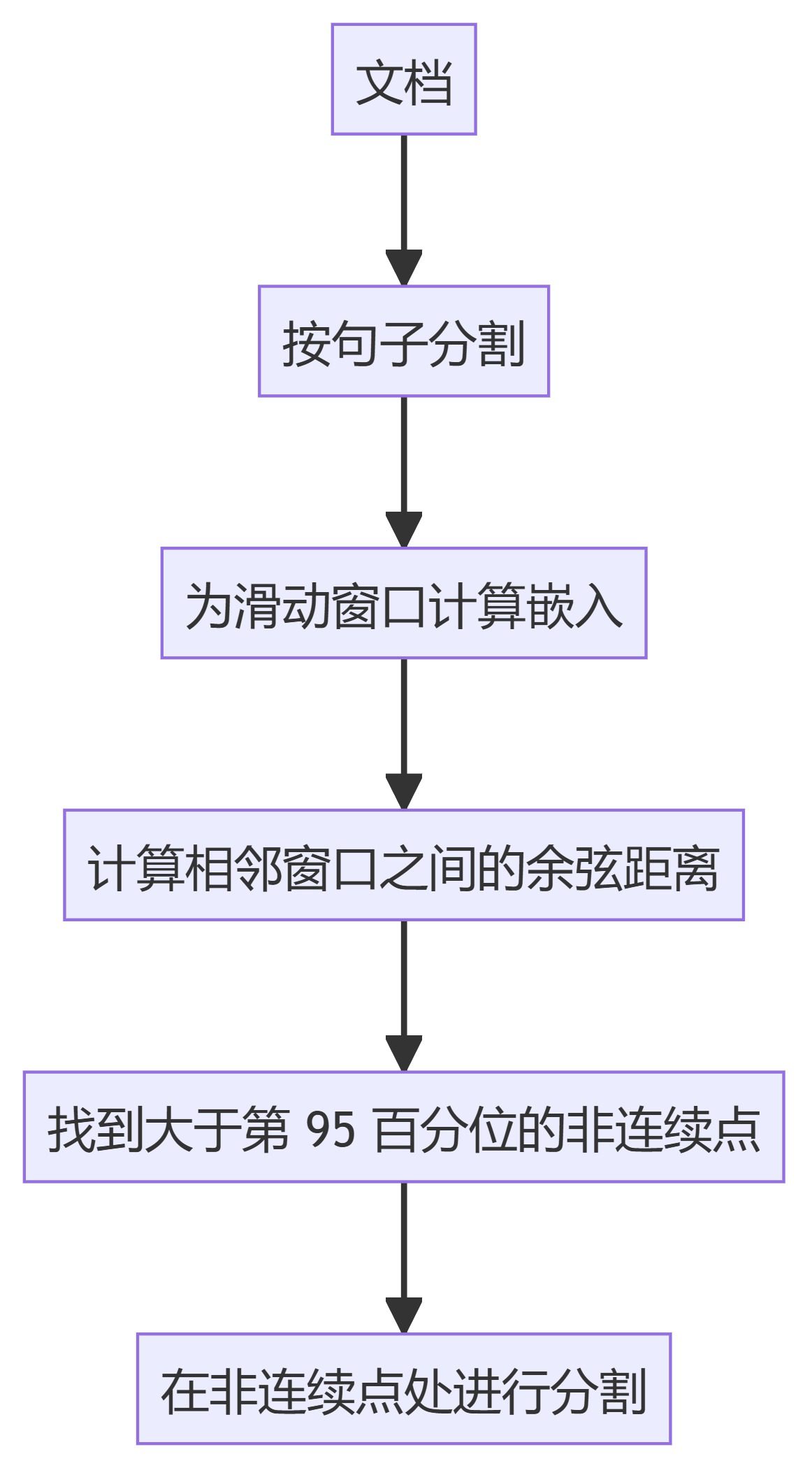
4.カムラット・モディファイド・チャンカー
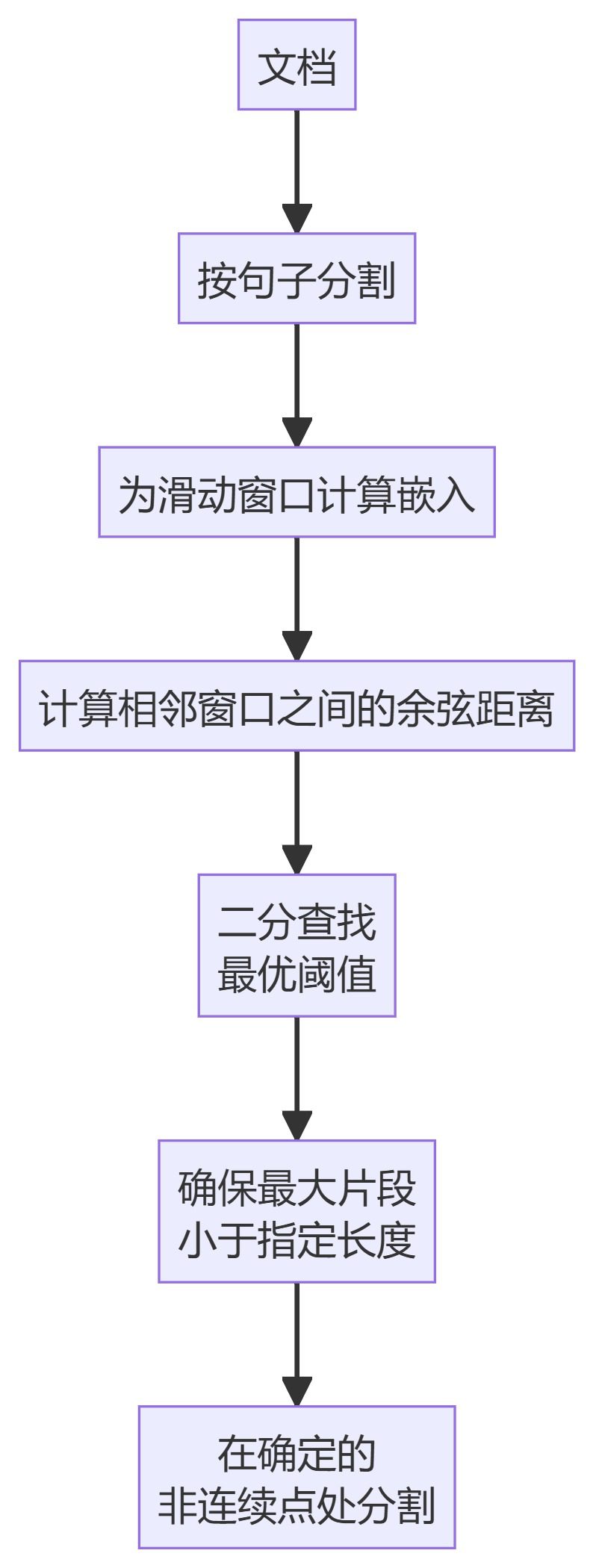
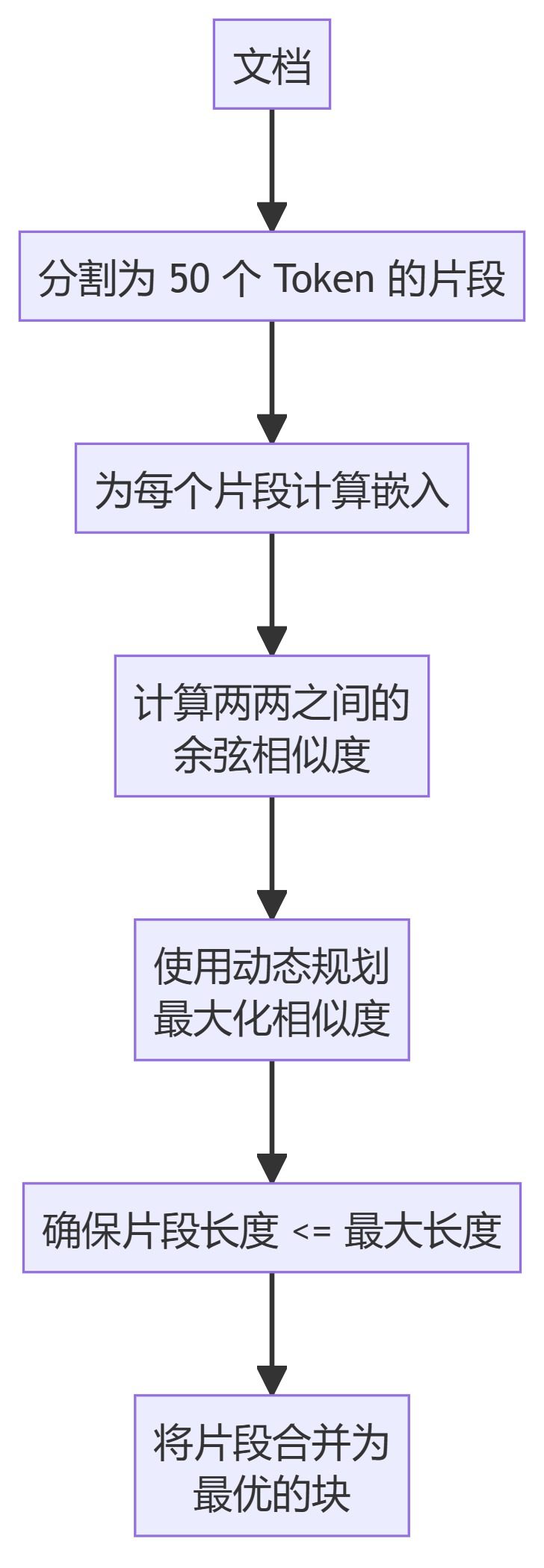
5.クラスターセマンティックチャンカー
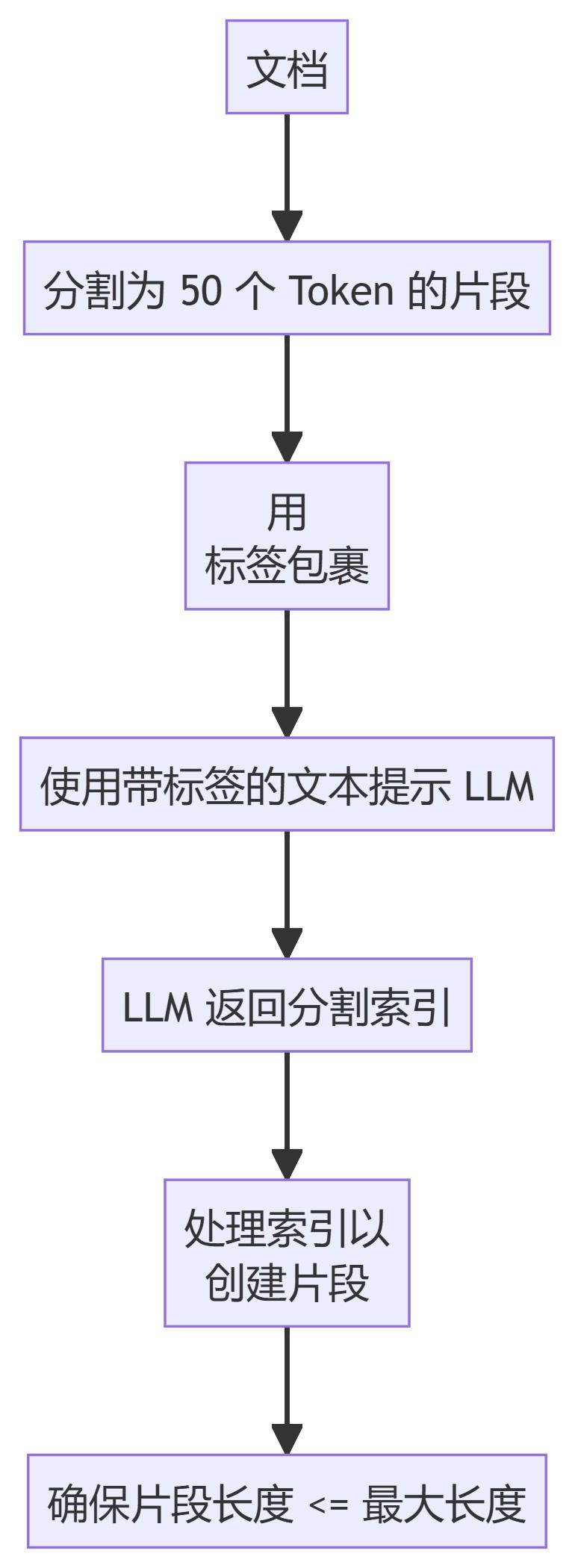
6.LLMSemanticチャンカー
メソッドの説明
- 再帰的文字テキスト分割器区切り文字の階層に基づいてテキストを分割し、文書内の自然な区切り位置を優先します。
- トークン テキスト スプリッタトークンの境界で分割が行われるようにします。
- カムラット・セマンティック・チャンカースライディングウィンドウ埋め込みを使用して、意味的な不連続性を識別し、それに応じてテキストを分割します。
- カムラット・モディファイド・チャンカーKamradtSemanticChunkerの改良版で、セグメンテーションに最適な閾値を見つけるために二分探索を使用する。
- クラスターセマンティックチャンカーテキストをチャンクに分割し、埋め込みを計算し、動的計画法を使って意味的類似性に基づいた最適なチャンクを作成する。
- LLMSemanticChunker言語モデリングを使用して、テキスト内の適切なセグメンテーションポイントを決定します。
使用方法
RAGプロセスでこれらのチャンキング法を使うには:
- をとおして
chunkersモジュールを使って必要なチャンカーをインポートする。 - 適切なパラメータ(最大チャンクサイズ、オーバーラップなど)を使ってチャンカーを初期化する。
- チャンキング結果を得るためにチャンカーに文書を渡す。
例
from chunkers import RecursiveCharacterTextSplitter
chunker = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = chunker.split_text(your_document)
チャンキング方式の選び方
チャンキング方法の選択は、特定のユースケースに依存する:
- 単純なテキスト分割には RecursiveCharacterTextSplitter や TokenTextSplitter が使えます。
- セマンティックを考慮したセグメンテーションが必要な場合は、KamradtSemanticChunkerまたはKamradtModifiedChunkerを検討する。
- より高度なセマンティック・チャンキングには、ClusterSemanticChunkerまたはLLMSemanticChunkerを使用する。
方法を選択する際に考慮すべき要素:
- 文書の構造とコンテンツの種類
- 必要なチャンクサイズとオーバーラップ
- 利用可能なコンピューティング・リソース
- 検索システムの具体的な要件(ベクトルベース、キーワードベースなど)
さまざまな方法を試してみて、文書化や検索のニーズに最も適した方法を見つけることができる。
RAGシステムとの統合
チャンキングが完了すると、通常は以下のステップを踏む:
- 各チャンクの埋め込みを生成する(ベクトルベースの検索システムの場合)。
- これらのチャンクを選択した検索システム(ベクトルデータベース、転置インデックスなど)でインデックス化する。
- クエリに答える際には、検索ステップでインデックス・チャンクを使用する。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません