
AIエンジニアリング・アカデミー:2.3BM25 RAG(検索拡張世代)

簡単
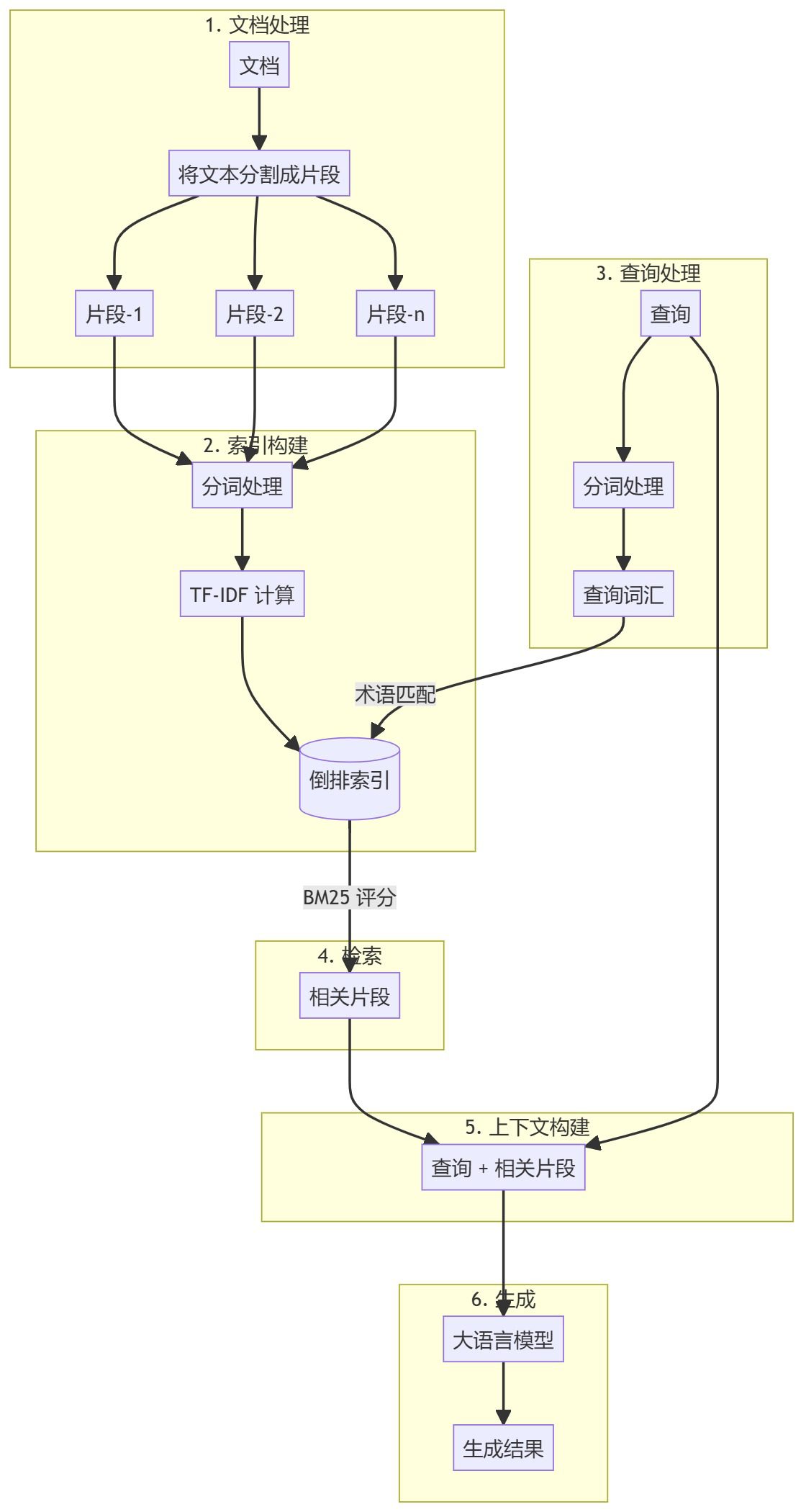
BM25 BM25 RAG (Retrieval Enhanced Generation) は、情報検索のためのBM25 (Best Matching 25) アルゴリズムと、テキスト生成のための大規模な言語モデルを組み合わせた高度な手法である。検証済みの確率的検索モデルを使用することで、この手法は生成された回答の精度と関連性を向上させます。
BM25 RAGワークフロー
クイックスタート
ノート
このコードベースで提供されているJupyterノートブックを実行して、BM25 RAGを詳しく調べることができます。https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_BM25_RAG
チャットアプリケーション
- 依存関係をインストールします:
pip install -r requirements.txt - アプリケーションを実行する:
python app.py - データの動的取り込み:
python app.py --ingest --data_dir /path/to/documents
サーバ
サーバーを動かす:
python server.py
サーバーには2つのエンドポイントがある:
/api/ingest新しい文書を取り込む/api/queryお問い合わせ:BM25 ラグ システム
BM25 RAGの主な特徴
- 確率的探索BM25は文書のランク付けに確率モデルを使用し、検索に理論的な根拠を提供する。
- ワード周波数飽和:: BM25は、重複語の限界利益の減少を考慮し、検索品質を向上させる。
- 文書の長さの正規化このアルゴリズムは文書の長さを考慮し、長い文書への偏りを減らす。
- 文脈的関連性検索された情報に基づいて回答を生成することで、BM25 RAGはより正確で適切な回答を提供します。
- スケーラビリティBM25検索ステップは、大規模な文書集合を効率的に処理する。
BM25 RAGの利点
- 精度の向上確率的検索とニューラル・テキスト生成の長所を組み合わせる。
- 解釈可能性BM25のスコアリングメカニズムは、密なベクトル検索法よりも解釈しやすい。
- ロングテールクエリへの対応特定の情報や希少な情報を必要とするクエリに優れています。
- 埋め込み不要ベクトルベースのRAGとは異なり、BM25は文書の埋め込みを必要としないため、計算オーバーヘッドを削減できる。
前提条件
- Python 3.7+
- Jupyter NotebookまたはJupyterLab(ノートブック実行用)
- 必要なPythonパッケージ
requirements.txt) - 選択した言語モデルのAPIキー(例:OpenAIのAPIキー)
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事




コメントはありません