
AIエンジニアリング・アカデミー:2.2 基本的なRAGの実装

挙げる
検索強化世代 (ラグ)は、大規模言語モデルの利点と知識ベースから関連情報を検索する能力を組み合わせた強力な手法です。このアプローチは、特定の検索された情報を基にすることで、生成される応答の品質と精度を向上させる。a このノートブックは、RAGの明確で簡潔な紹介を提供することを意図しており、このテクニックを理解し実装したい初心者に適している。
RAGプロセス
開始
ノート
このリポジトリで提供されているノートブックを実行することができます。https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_Basic_RAG
チャットアプリケーション
- 依存関係をインストールします:
pip install -r requirements.txt - アプリケーションを実行する:
python app.py - データの動的インポート:
python app.py --ingest --data_dir /path/to/documents
サーバ
以下のコマンドを使用してサーバーを実行する:
python server.py
サーバーは2つのエンドポイントを提供する:
/api/ingest/api/query
機関車
従来の言語モデルは、学習データから学習したパターンに基づいてテキストを生成する。RAGは、より正確な回答を生成するために、言語モデルに関連するコンテキストを提供する検索ステップを導入することで、この制限に対処している。
方法論の詳細
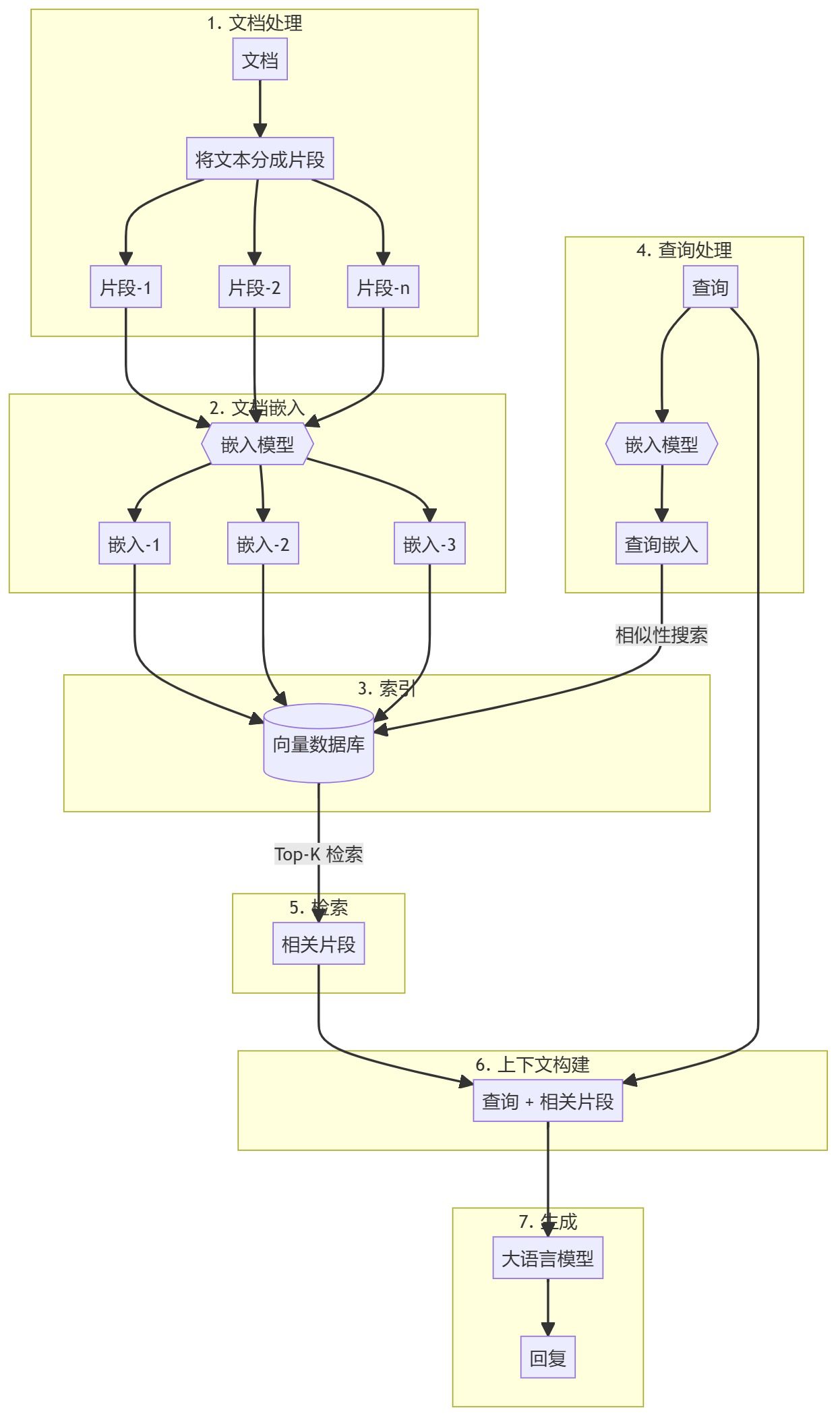
ドキュメントの前処理とベクトルストアの作成
- ドキュメントのチャンキング知識ベースの文書(PDFや記事など)を前処理し、管理しやすい塊に分割します。これにより、効率的な検索プロセスのための検索可能なコーパスが作成されます。
- エンベッディングの生成各ブロックは、事前に訓練された埋め込み(OpenAIの埋め込みなど)を使ってベクトル表現に変換されます。これらのドキュメントはベクトルデータベース(例:Qdrant)に格納され、効率的な類似検索が可能になる。
検索補強生成(RAG)ワークフロー
- お問い合わせ入力:: ユーザーは、回答が必要なクエリを提供する。
- 検索ステップ文書と同じ埋め込みモデルを用いて、クエリをベクトルとして埋め込む。その後、ベクトルデータベース内で類似検索を行い、最も関連性の高い文書ブロックを見つける。
- 生成ステップ例:検索された文書の塊は、大規模な言語モデル(例:GPT-4)に追加コンテキストとして渡される。モデルはこのコンテキストを利用して、より正確で適切な応答を生成する。
RAGの主な特徴
- 文脈的関連性実際に検索された情報に基づいて回答を生成することで、RAGモデルはより文脈に即した正確な回答を生成することができます。
- スケーラビリティ検索ステップは、大規模な知識ベースを扱うように拡張することができ、大量の情報からコンテンツを抽出することができる。
- ユースケースの柔軟性RAGは、Q&A、要約生成、レコメンダー・システムなど、様々なアプリケーション・シナリオに適応することができる。
- 精度の向上検索と生成を組み合わせることで、より正確な結果が得られることが多い。
この方法の利点
- 検索と生成の利点を組み合わせるRAGは、正確な事実発見と自然言語生成のために、検索ベースのアプローチと生成モデルを効果的に融合させている。
- ロングテールクエリへの対応を強化この方法は、特に特殊で珍しい情報を必要とするクエリに適しています。
- ドメイン適応検索メカニズムは、生成される応答が最も関連性の高い正確なドメイン固有の情報に基づいていることを保証するために、特定のドメイン用に調整することができます。
評決を下す
検索拡張生成(RAG)は、検索技術と生成技術の革新的な融合であり、関連する外部情報に基づいて出力を行うことで、言語モデルの能力を効果的に拡張する。このアプローチは、正確で文脈を認識した回答を必要とする応答シナリオ(カスタマーサポート、学術研究など)において特に価値がある。AIが進化し続ける中、RAGは、より信頼性が高く、文脈に敏感なAIシステムを構築する可能性がある点で際立っている。
前提条件
- Python 3.11を推奨
- JupyterノートブックまたはJupyterLab
- LLM APIキー
- このノートでは、OpenAIとGPT-4o-miniを使っています。
これらのステップを踏むことで、実世界の最新情報を取り入れた基本的なRAGシステムを実装し、さまざまなアプリケーションで言語モデルの効率を高めることができる。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません