
AI工学アカデミー:2.1 RAGをゼロから実装する

中抜き
このガイドでは、純粋なPython (ラグ)システムである。埋め込みモデルと大規模言語モデル(LLM)を使って、関連文書を検索し、ユーザのクエリに基づいて応答を生成する。
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/00_RAG_from_Scratch
ステップ
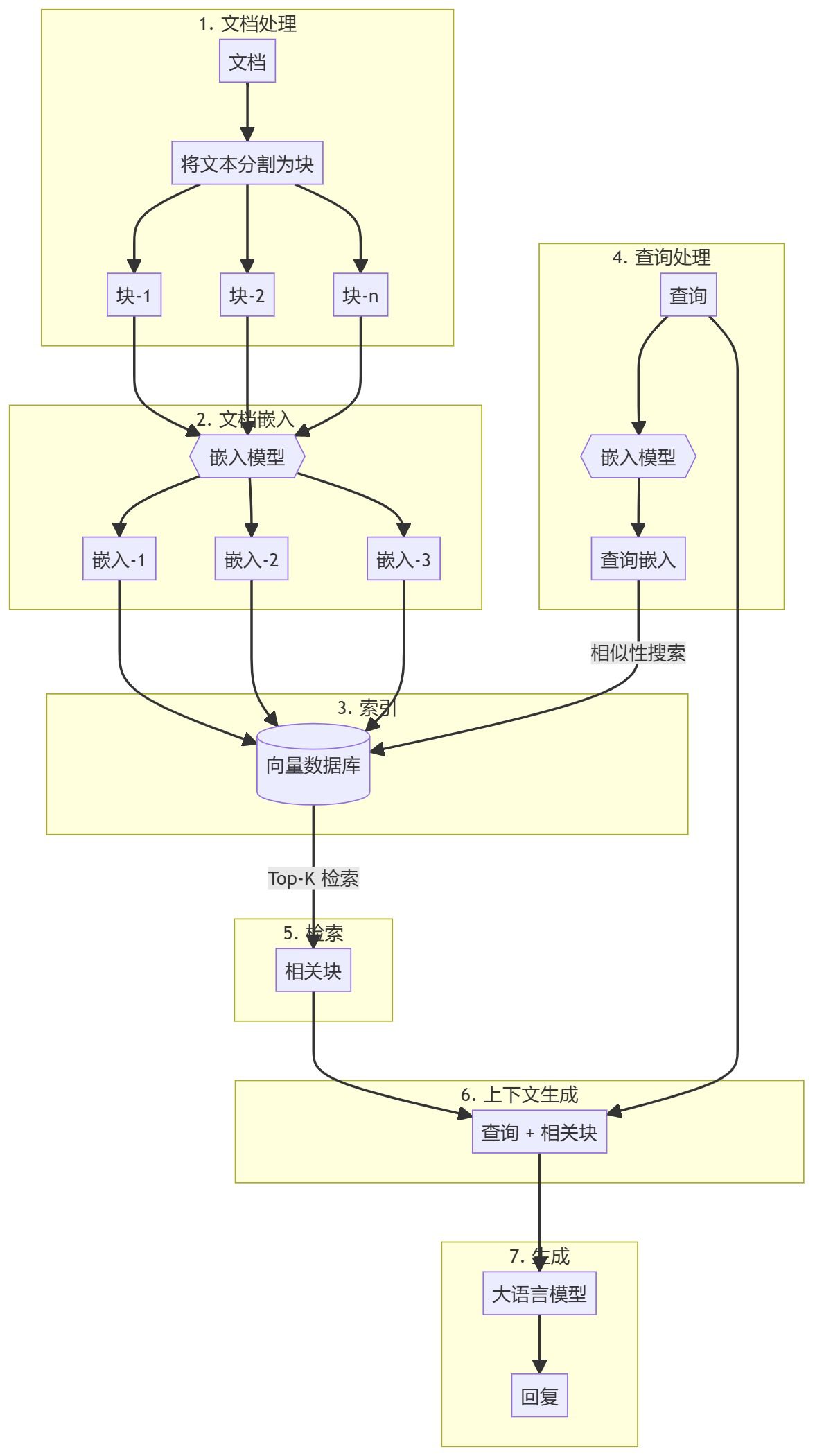
プロセス全体は大きく2つのステップに分けられる:
- ナレッジベースの作成
- 生成部分
ナレッジベースの作成
まず、知識ベース(文書、PDF、Wikiページ)を準備する必要があります。これらは言語モデル(LLM)のベースデータとなります。具体的なプロセスとしては
- チャンクテキストを小さな文書チャンクに分割し、処理を簡素化します。
- 埋め込みクエリの意味的類似性を理解するために、各サブ文書ブロックの数値埋め込みを計算する。
- ざいここれらの埋め込みを、素早く検索できるように保存します。ベクターストア/データベースを使用するのが一般的ですが、このチュートリアルではその必要はないことを示します。
生成部分
ユーザクエリが入力されると、クエリに対する埋め込みが計算され、最も関連性の高いサブ文書ブロックが知識ベースから検索される。これらの関連するチャンクは、コンテキストを形成するためにユーザクエリに追加され、応答を生成するためにLLMに供給される。
1.環境設定
始める前にインストールする必要があるパッケージがいくつかある。
sentence-transformers文書やクエリの埋め込みを生成するために使用される。numpy類似性比較のため。scipy高度な類似性計算のために。wikipedia-apiウィキペディアのページを知識ベースとして読み込むために使用します。textwrap出力テキストの書式設定に使用。
!pip install -q sentence-transformers
!pip install -q wikipedia-api
!pip install -q numpy
!pip install -q scipy
2.埋め込みモデルの読み込み
組み込みモデルをロードしてみましょう。このチュートリアルでは gte-base-en-v1.5.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("Alibaba-NLP/gte-base-en-v1.5", trust_remote_code=True)
モデルについて
gte-base-en-v1.5 モデルはAlibaba NLPチームが提供するオープンソースの英語モデルです。GTE (Generic Text Embedding) ファミリーの一部で、様々な自然言語処理タスクのための高品質な埋め込みを生成するように設計されています。このモデルは英語テキストの意味的捕捉に最適化されており、文の類似性、意味検索、クラスタリングなどのタスクに使用できます。trust_remote_code=True パラメータは、モデルが期待通りに動作することを保証するために、モデルに関連するカスタムコードを使用することを可能にします。
3.ウィキペディアからテキストコンテンツを入手し、準備する。
- ウィキペディアの記事はまず知識ベースとして読み込まれる。テキストは管理しやすいかたまり(サブドキュメント)に、通常はパラグラフごとに分割されます。
from wikipediaapi import Wikipedia wiki = Wikipedia('RAGBot/0.0', 'en') doc = wiki.page('Hayao_Miyazaki').text paragraphs = doc.split('\n\n') # 分块 - 多くのチャンキング戦略がありますが、その多くは適用できないかもしれません。ナレッジ・ベース(KB)をチェックして、最も適切な戦略を決定するのがベストです。この例では、段落ごとにチャンクします。
- これらのブロックがどのように見えるかを見たい場合は、インポートすることができます。
textwrap図書館で段落ごとに印刷する。import textwrap for i, p in enumerate(paragraphs): wrapped_text = textwrap.fill(p, width=100) print("-----------------------------------------------------------------") print(wrapped_text) print("-----------------------------------------------------------------") - 文書に画像や表が含まれている場合は、それらを個別に抽出し、ビジュアルモデルを使って埋め込むことをお勧めします。
4.ドキュメントの埋め込み
- 次に、モデルのモデルは
encodeメソッドは、テキスト・データ(たとえばparagraphs)が埋め込まれている。docs_embed = model.encode(paragraphs, normalize_embeddings=True) - これらの埋め込みは、テキストの密なベクトル表現であり、意味的な意味を捉え、モデルがテキストを数学的な形で理解し、処理することを可能にする。
- ここでは埋め込みを正規化する。
- ノーマライゼーションとは何か? 正規化とは、埋め込み値が単位パラダイム(つまりベクトルの長さが1)になるように調整するプロセスである。
- なぜノーマライズするのか? 正規化された埋め込みは、ベクトル間の距離がサイズよりもむしろ方向の違いを主に反映することを保証する。これにより、テキスト間の「近さ」や「類似性」が比較される類似検索タスクにおけるモデルの性能が向上する。
- 結局
docs_embedはテキストデータのベクトル表現の集まりであり、各ベクトルは以下に対応する。paragraphsリストの段落。 - 利用する
shapeコマンドを実行すると、各埋め込みベクトルのブロック数と次元が表示されます(埋め込みベクトルのサイズは埋め込みモデルの種類によって異なります)。docs_embed.shape - また、正規化された値の集合である実際の埋め込みがどのようなものかを見ることもできる。
docs_embed[0]
5.クエリーの埋め込み
埋め込みドキュメントと同様の方法で、ユーザークエリの例を埋め込みます。
query = "What was Studio Ghibli's first film?"
query_embed = model.encode(query, normalize_embeddings=True)
を確認することができる。 query_embed シェイプを使用して、埋め込まれたクエリの次元を確認する。
query_embed.shape
6.クエリに最も近い段落を見つける
最も関連性の高いコンテンツの塊を検索する最も簡単な方法の一つは、文書埋め込みとクエリ埋め込みのドット積を計算することである。
a. ドット積の計算
内積は、2つのベクトル(または行列)の対応する要素を掛け合わせ、合計する数学演算である。2つのベクトルの類似度を測るのによく使われる。
(ドット積は query_embed (ベクトルの転置)。
import numpy as np
similarities = np.dot(docs_embed, query_embed.T)
b. ドット積とその形状を理解する
のNumPy配列 .shape プロパティは、配列の次元を表すタプルを返す。
similarities.shape
このコードで期待される形は以下の通りである:
- 万が一
docs_embedは(n_docs, n_dim)の形をしている:- n_docsはドキュメントの数。
- n_dimは各文書に埋め込まれた次元である。
query_embed.Tは(n_dim, 1)の形になる。- ドットプロダクト
similarities配列の形状は(n_docs,)となり、n_docs個の要素を含む1次元配列(ベクトル)であることを示す。各要素は、クエリと特定の文書との類似度スコアを表す。 - なぜ形状をチェックするのか? 形状が期待通り(n_docs,)であることを確認することは、ドット積が正しく実行され、各文書の類似度スコアが正しく計算されたことを確認する。
印刷できる similarities 配列で類似スコアをチェックし、それぞれの値がドット積の結果に対応する:
print(similarities)
c. ドット積の解釈
2つのベクトル(埋め込み)の間のドット積は、それらの類似度を測定します:値が大きいほど、クエリとドキュメントの間の類似度が高いことを示します。埋め込みが正規化されている場合、これらの値はベクトル間の余弦類似度に正比例する。正規化されていない場合、これらの値は類似性を示すが、埋め込みの大きさも反映する。
d. 最も類似した3つの文書を特定する
類似度スコアに基づいて最も類似した3つの文書を見つけるには、次のコードを使用します:
top_3_idx = np.argsort(similarities, axis=0)[-3:][::-1].tolist()
- np.argsort(similarities, axis=0). この関数は
similarities配列のインデックスがソートされる。例えばsimilarities = [0.1, 0.7, 0.4]属np.argsortを返します。[0, 2, 1]最小値と最大値のインデックスはそれぞれ0と1である。 - [-3:]: このスライス操作は、類似度スコアが最も高い3つのインデックス(ソート後の最後の3要素)を選択する。
- [::-1]: この操作は順序を逆にするので、インデックスは類似度の降順にソートされる。
- tolist(). インデックス付き配列を Python のリストに変換します。結果は以下の通りです:
top_3_idx類似度の降順で、最も類似した3つの文書を含むインデックス。
e. 最も類似した文書の抽出
most_similar_documents = [paragraphs[idx] for idx in top_3_idx]
- リストの派生物: この行は
most_similar_documentsのリストである。paragraphsに対応するリスト。top_3_idxインデックスの実際の段落。 - パラグラフ[idx]。 に関して
top_3_idxこの操作は、以下の各インデックスに対応する段落を検索する。
f. 最も類似した文書の書式設定と表示
CONTEXT この変数は最初は空文字列で初期化され、その後、列挙ループの中で最も類似した文書の改行テキストが追加される。
CONTEXT = ""
for i, p in enumerate(most_similar_documents):
wrapped_text = textwrap.fill(p, width=100)
print("-----------------------------------------------------------------")
print(wrapped_text)
print("-----------------------------------------------------------------")
CONTEXT += wrapped_text + "\n\n"
7.応答を生成する
これで、クエリーと関連するコンテンツ・ブロックができあがり、これらは一緒にラージ・ランゲージ・モデル(LLM)に渡される。
a. 捜索宣言
query = "What was Studio Ghibli's first film?"
b. プロンプトを作成する
prompt = f"""
use the following CONTEXT to answer the QUESTION at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
CONTEXT: {CONTEXT}
QUESTION: {query}
"""
c. OpenAIのセットアップ
- OpenAIをインストールして、Large Language Model (LLM)にアクセスし、使用する。
!pip install -q openai - OpenAI APIキーへのアクセスを有効にする(Google Colabのsecretsで設定可能)。
from google.colab import userdata userdata.get('openai') import openai - OpenAI クライアントを作成します。
from openai import OpenAI client = OpenAI(api_key=userdata.get('openai'))
d. APIを呼び出してレスポンスを生成する。
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": prompt},
]
)
- client.chat.completion.create。 このメソッドは、大規模なチャットベースの言語モデルを呼び出して、新しい返信を作成する(生成する)。
- クライアント サービス(この場合は OpenAI)に接続する API クライアントオブジェクトを表します。
- chat.completions.create. チャットベースのジェネレーションの作成をリクエストしていることを指定します。
メソッドに渡されるパラメーターの詳細については
- model="gpt-4o"。 応答を生成するために使用されるモデルを指定する。"gpt-4o "はGPT-4モデルの特定の変種です。モデルが異なると、動作や微調整の方法、機能が異なることがあるため、モデルを指定することは、望ましい出力が得られるようにするために重要です。
- のメッセージがある。 このパラメータは対話履歴を表すメッセージオブジェクトのリストです。これにより、モデルはチャットのコンテキストを理解することができます。この例では、リストにメッセージを1つだけ指定しています:
{"role": "user", "content": prompt}. - の役割を果たす。 「user "は、メッセージ送信者の役割、つまりモデルと対話するユーザーを示す。
- の内容だ。 ユーザーによって送信されたメッセージの実際のテキストを含む。変数 prompt はこのテキストを保持し、モデルはこれを入力として応答を生成します。
e. 受け取った回答について
OpenAI GPTモデルのようなAPIにチャット応答を生成するリクエストを行うと、通常、応答は構造化された形式、通常は辞書で返されます。
この構造には通常、以下が含まれる:
- を選択した。 モデルによって生成された複数の可能なレスポンスを含むリスト (配列)。このリストの各項目は、可能なレスポンスまたは完了を表します。
- というメッセージを送った。 モデルによって生成されたメッセージの実際の内容を含む、各セレクションのオブジェクトまたはディクショナリ。
- の内容だ。 メッセージのテキストコンテンツ、つまりモデルによって生成された実際の返信や完了。
f. 印刷された回答
print(response.choices[0].message.content)
を選ぶ。 choices リストの最初の項目にアクセスする。 message オブジェクトにアクセスする。最後に message 正鵠を得る content フィールドがあり、これはモデルによって生成された実際のテキストを含みます。
評決を下す
これで、RAGシステムをゼロから構築する説明は終わりです。これらのシステムがどのように動作するかをよりよく理解するために、最初に純粋なPythonで最初のRAGセットアップを構築することを強くお勧めします。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事




コメントはありません