エージェント」という言葉は憂鬱であり、GPT-4モデルはもはや言及する価値もなく、偉大なプログラマーたちは「ビッグモデル2024」を見定めている。

専門家の間では、2024年はAGIの年になるというのが一般的な見方だ。大きなモデル産業が永遠に変わる年である:
OpenAIのGPT-4はもはや手の届かないものではなくなり、画像・映像生成モデルの研究はますます現実的になり、マルチモーダルな大規模言語モデル、推論モデル、インテリジェンス(エージェント)でブレークスルーがもたらされ、人間はますますAIを気にするようになっている......。
では、ベテランの業界関係者から見て、この1年でビッグモデル業界はどのように変化したのだろうか?
数日前、著名な独立系プログラマーであり、ソーシャル・カンファレンス・ディレクトリーLanyrdの共同設立者であり、Djangoウェブ・フレームワークの共同開発者である サイモン・ウィリソン と題する報告書の中で 2024年のLLMについて学んだこと この記事では 2024年のビッグモデル業界の変化、驚き、そして欠点.

以下にその一部を紹介する:
- 2023年、GPT-4に格付けされたモデルをトレーニングすることは大変なことだ。しかし、2024年には、これは特筆すべき成果ですらない。
- この1年で、トレーニングや推論のパフォーマンスは驚くほど向上した。
- 競争激化と効率化である。
- LLMの進歩が遅いと文句を言う人は、マルチモーダルモデリングの大きな進歩を無視しがちだ。
- プロンプト主導のアプリ生成はコモディティとなった。
- SOTAモデルを無料で入手できる時代は終わった。
- インテリゲンチアはまだ誕生していない。
- LLM駆動システムの優れた自動評価を書くことは、これらのモデルの上に有用なアプリケーションを構築するために最も必要なスキルである。
- o1 拡張モデルへの新しいアプローチをリードする:推論により多くの計算を費やすことで、より難しい問題を解決する。
- 中国製GPUの輸出に対するアメリカの規制は、非常に効果的なトレーニングの最適化を促したようだ。
- 過去数年間で、プロンプトの運転によるエネルギー消費と環境への影響は大幅に削減された。
- 人工知能によって生成された未承諾・無修正のコンテンツは「ドロボー」である。
- LLMを最大限に活用する鍵は、頼りないが強力なテクニックの使い方を学ぶことだ。
- LLMには真の価値があるが、その価値に気づくには直感的ではなく、指導が必要だ。
原文の大意は変えないが、全体的な内容は以下のように凝縮されている:
2024年のラージ・ランゲージ・モデリング(LLM)分野では、多くのことが起きている。ここでは、過去12ヶ月間にこの分野で発見されたことを振り返り、主要なテーマや重要な瞬間を特定する試みとともに紹介する。以下を含む 19 側面:
1.GPT-4の堀は「破られた」。
2023年12月のレビューで私はこう書いた。GPT-4の作り方はまだわからない。-- 当時、GPT-4は発売からほぼ1年が経過していたが、他のAIラボはまだそれ以上のモデルを作っていなかった。
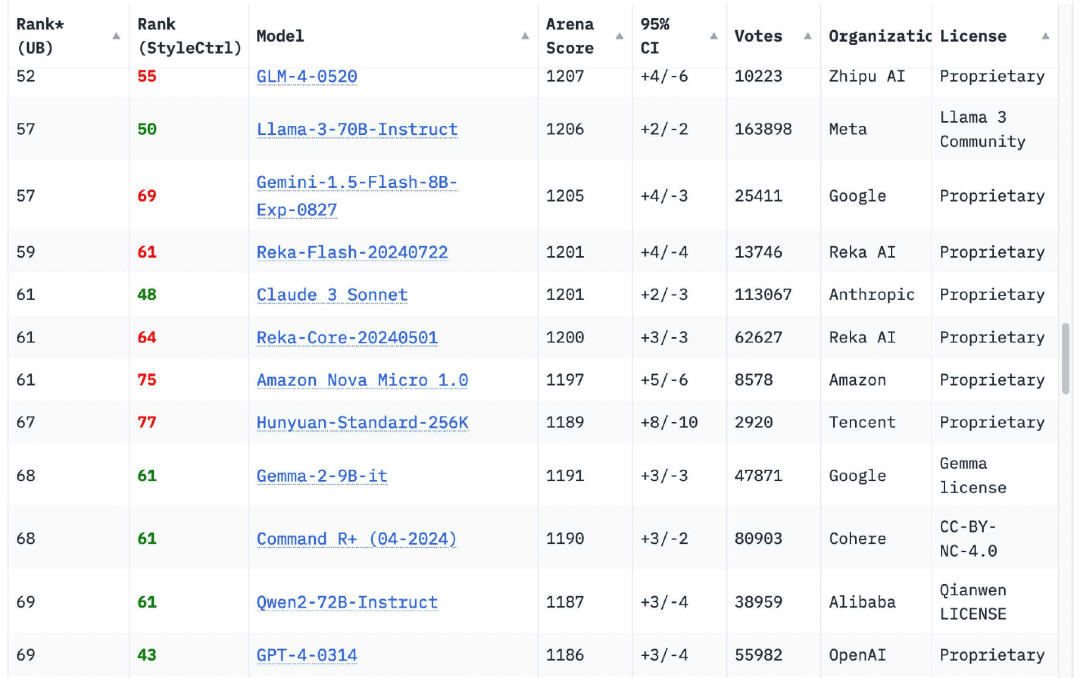
安心したことに、この12ヶ月ですっかり変わってしまった。チャットボット・アリーナのリーダーボードは現在18団体のモデル2023年3月にリリースされたGPT-4のオリジナルバージョン(GPT-4-0314)よりもランクが高く、この数字は70に達する。
最も早い挑戦者は、グーグルが2024年2月に発表した ジェミニ 1.5プロは、GPT-4レベルの出力を提供するだけでなく、いくつかの新機能をこの分野にもたらします。最も注目すべきは、100万トークン(後に200万トークン)の入力コンテキストの長さと、ビデオ入力機能である。.
ジェミニ1.5プロは、2024年の主要テーマのひとつである「コンテキストの長さの増加」の引き金となる。2023年には、ほとんどのモデルが4096または8192トークンしか受け付けなくなるだろうリビア・アラブ・ジャマーヒリーヤ クロード 例外は、20万トークンを受け入れる2.1である。今日、どのモデルプロバイダーも10万トークンを超えるトークンを受け入れるモデルを持っている。 トークン モデル、GoogleのGeminiシリーズは最大200万トークンを受け入れることができる。
長い入力は、LLMを使用して解決できる問題の範囲を大幅に広げます。本全体を入力して、その内容に関する質問をすることもできますが、さらに重要なのは、モデルがコーディング問題を正しく解決できるように、大量のサンプルコードを入力することです。私にとって、長い入力を伴うLLMの使用例は、純粋にモデルの重みに関する情報に依存する短いプロンプトよりもはるかに興味深い。私のツールの多くは、このモデルを使って作られている。
GPT-4を "打ち負かした "モデルに話を移すと、AnthropicのClaude 3シリーズは3月に発売され、Claude 3 Opusはすぐに私のお気に入りのモデルになった!半年経った今でも、私のお気に入りです。
もちろん、他にもいる。今日のチャットボット・アリーナ・リーダーボードを見てみるとGPT-4-0314は約70位まで落ちた。.モデルスコアが高い18の組織は、Google、OpenAI、Alibaba、Anthropic、Meta、Reka AI、Zero One Thing、Amazon、Cohere、DeepSeek、NVIDIA、Mistral、NexusFlow、Smart Spectrum、xAI、AI21 Labs、Princeton University、Tencentである。
2023年にGPT-4レベルのモデルを育成するのは大変なことだ。しかし2024年には、それは特筆すべき業績ですらないしかし、個人的には、新しい組織がリストに加わるたびに祝福している。
2.ノートパソコン、GPT-4レベルのモデルを実行する準備ができている。
私の個人的なラップトップは、2023年製の64GB M2 MacBook Proだ。パワフルなマシンだが、2年近く前のものでもある。さらに重要なのは、私が初めて自分のコンピューターでLLMを実行した2023年3月から使っているのと同じラップトップだということだ。
2023年3月になっても、このノートパソコンはGPT-3レベルのモデルを1台しか動かすことができない。GPT-4モデルは、複数のGPT-4レベルのモデルを実行できるようになった!
これにはまだ驚いている。GPT-4の機能と出力品質を実現するには、4万ドル以上のGPUを搭載したデータセンター級のサーバーが1台かそれ以上必要だと思っていたからだ。
このモデルは私のメモリーの64GBを占有するので、あまり実行しない。
これが機能するということは、我々がこの1年間でトレーニングや推論のパフォーマンスを驚くほど向上させたことの証だ。結局のところ、モデルの効率という点で、目に見える果実をたくさん得ることができた。今後さらに多くの成果が出ることを期待している。
メタのラマ3.2シリーズは特筆に値する。GPT-4規格ではないかもしれないが、1Bと3Bサイズでは期待以上の結果を示している。
3.競争と効率化により、LLMの価格は大幅に下落した。
過去12ヶ月の間に、LLMの利用料は劇的に下がった。
2023年12月、OpenAIはGPT-4に3000万ドル/投入トークンを課金(mTok)コストさらに、当時導入されたばかりのGPT-4ターボにはUS$10/mTok、GPT-3.5ターボにはUS$1/mTokの手数料が課された。
今日、OpenAIの最も高価なo1モデルは30ドル/mTokで入手可能だ!GPT-4oは$2.50(GPT-4の12倍安い)、GPT-4o miniは$0.15/mTokで、GPT-3.5の7倍近く安く、よりパワフルだ。
AnthropicのClaude 3 Haikuは$0.25/mTok、GoogleのGemini 1.5 Flashは$0.075/mTok、Gemini 1.5 Flash 8Bは$0.0375/mTokで、2023年のGPT-3.5 Turboより27倍安い。2023年のターボ
競争激化と効率化である。.効率改善は、LLMの環境への影響を懸念するすべての人々にとって重要である。これらの価格引き下げは、プロンプトを動かすために消費されるエネルギーに直接関係している。
AIデータセンター建設による環境への影響については、まだ心配すべきことがたくさんあるが、個々のプロンプトのエネルギーコストに関する懸念は、もはや信用できない。
面白い計算をしてみよう。グーグルの最も安価なジェミニ1.5フラッシュ8Bを使って、私の個人的なフォトライブラリーにある68,000枚の写真それぞれに短い説明文を生成するのに、どれくらいのコストがかかるだろうか?
各写真は260の入力トークンと約100の出力トークンを必要とする。
260 * 68000 = 17680000 トークン入力
17680000ドル * 0.0375ドル/ミリオン = 0.66ドル
100 * 68000 = 6800,000 出力トークン
6800000 * $0.15/ミリオン = $1.02
68,000枚の画像を処理するための総コストは1.68ドル.あまりに安かったので、念のため3回計算したほどだ。
これらの説明はどの程度良いのでしょうか?私はこのコマンドから情報を得た:
llm -m gemini-1.5-flash-8b-latest describe -a IMG_1825.jpeg
これはカリフォルニア科学アカデミーの蝶の写真:

写真には赤い浅い皿が写っているが、これはハチドリか蝶の餌入れだろう。皿にはオレンジ色の果物のスライスが乗っている。
フィーダーには2匹の蝶がおり、1匹は濃い茶色と黒の蝶で、白とクリームの模様がある。もう1匹はもっと大きな茶色の蝶で、薄い茶色、ベージュ、黒のマーキングがあり、目の斑点も目立つ。この大きめの茶色の蝶は、皿から果物を食べているように見える。
入力トークン260個、出力トークン92個で、コストは約0.0024セント(400分の1セント以下)。
2024年のトレンドとして私が気に入っているのは、効率の向上と低価格化である。LLMのユーティリティをわずかなエネルギーコストで実現したい。
4.マルチモーダル視覚が一般的になり、音声と映像が「出現」し始めている
上記の私の蝶の例は、2024年のもうひとつの重要なトレンド、マルチモーダル大型言語モデル(MLLM)の台頭も示している。
1年前の2023年11月にOpenAIのDevDayで発表されたGPT-4 Visionは、その最も顕著な例である。一方グーグルは、2023年12月7日にマルチモーダルGemini 1.0をリリースした。
2024年には、ほぼすべてのモデルプロバイダーがマルチモーダルモデルをリリースしている。3月に見たんだ。 アンソロピック のクロード3シリーズ、4月にはジェミニ1.5プロ(画像、オーディオ、ビデオ)、そして9月には ミストラル のPixtral 12B、MetaのLlama 3.2 11Bと90Bの視覚モデル。10月にはOpenAIから音声入力と出力を、11月にはHugging FaceからSmolVLMを、12月にはAmazon Novaから画像とビデオモデルを入手した。
私はそう思う。LLMの進歩が遅いと文句を言う人は、こうしたマルチモーダルモデルの大きな進歩を無視しがちだ。.音声やビデオだけでなく)画像に対してプロンプトを実行する機能は、これらのモデルを適用する魅力的な新しい方法である。
5.SFを現実にする音声とリアルタイムのビデオモード
特に注目すべきは、オーディオとリアルタイムのビデオモデルが登場し始めていることだ。
とともに チャットGPT 対話機能は2023年9月にデビューするが、これはほとんど幻想である。 ウィスパー ChatGPTとの対話を可能にするために、Speech-to-Textモデルと新しいText-to-Speechモデル(tts-1と命名)が追加されたが、実際のモデルはテキストしか見ることができない。
5月13日にリリースされたOpenAIのGPT-4oには、新しい音声モデルのデモンストレーションが含まれています。TTSやSTTモデルを別途用意することなく、驚くほどリアルな音声を出力することができます。
ChatGPTアドバンスド・ボイス・モードがついに導入されたとき、その結果は驚くべきものでした。私は犬の散歩のときにこのモードをよく使うのですが、音色がとても良くなったので驚いています!.OpenAI Audio APIを使うのも楽しかった。
マルチモーダル音声モデルを持つチームはOpenAIだけではない。グーグルのGeminiも音声入力を受け付け、ChatGPTのような話し方もできる。アマゾンも予定より早くAmazon Novaの音声モデルを発表したが、そのモデルは2025年の第1四半期に利用可能になる予定だ。
グーグル ノートブックLM 9月にリリースされたこの製品は、音声出力を新たなレベルに引き上げ、2人の「ポッドキャスト・ホスト」が入力した内容についてリアルな会話をすることができ、後にカスタム・コマンドも追加された。
ChatGPTボイスモードでは、カメラの映像をモデルと共有し、リアルタイムで見ているものについて話すことができる。GoogleのGeminiも同じ機能を備えたプレビュー版を発表している。
6.コモディティ化したプロンプト主導のアプリ生成
GPT-4は2023年にはすでにこれを達成できるが、その価値が明らかになるのは2024年になってからだ。
LLMはコードを書く才能に優れていることで知られている。もしあなたがプロンプトを正しく書くことができれば、彼らはHTML、CSS、JavaScriptを使って完全なインタラクティブ・アプリを作ることができる。
Anthropicは、Claude Artifactsのリリースで、このアイデアを次のレベルに引き上げた。Artifactsは画期的な新機能です。Artifactsを使えば、Claudeはあなたのためにオンデマンドでインタラクティブなアプリを書き、それをClaudeのインターフェイスで直接使うことができます。
これはURLを抽出するためのアプリで、すべてクロードによって生成される:
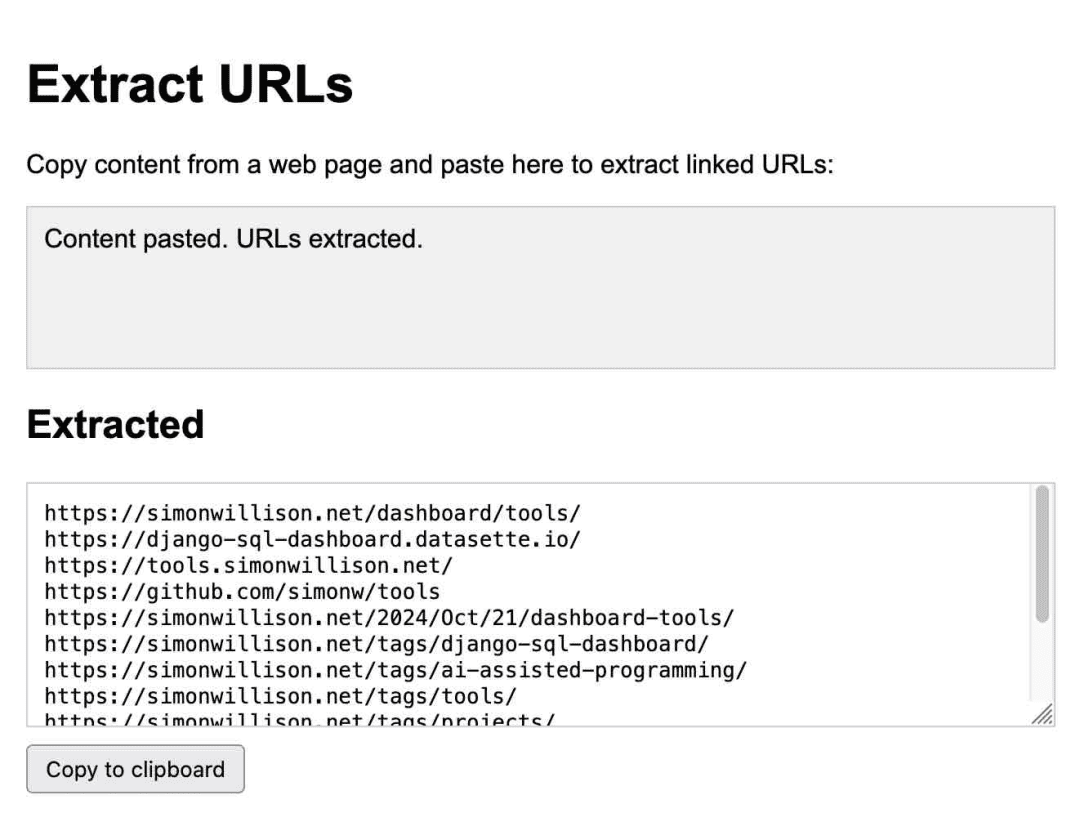
普段から使っている。10月になって、自分がどれだけこの製品に頼っていたかに気づいた。アーティファクトを使って7日間で14のガジェットを作った!.

10月にはGitHubがGitHub Sparkをリリースし、11月にはMistral ChatがCanvasという機能として追加した。
ヴァル・タウンのスティーブ・クラウスが次のように答えた。 セレブラ 毎秒2000トークンのLLMがどのようにアプリを繰り返し、1秒以内に変化を確認できるかを示すバージョンが作られた。
そして12月、チャットボット・アリーナ・チームは、この機能のための全く新しいリーダーボードを立ち上げました。これは、ユーザーが2つの異なるモデルを使用して同じ対話型アプリを2回構築し、その答えに投票するというものです。この機能が今やすべての主要モデルと効果的に競争できる商品であることを、これ以上説得力のある形で主張するのは難しいだろう。
ユーザがプロンプトを使ってカスタムガジェットを作成し、繰り返し実行することで、自分のデータに基づいてデータを視覚化することを目的としている。また、uvを使って単発のPythonプログラムを書くための同様のパターンも見つけた。
このようなプロンプト主導のカスタム・インターフェイスは、(ブラウザのサンドボックス化の複雑さを理解すれば)非常に強力かつ簡単に構築できるので、2025年までにはさまざまな製品の機能として登場することになるだろう。
7.わずか数ヶ月で、強力なモデルが普及した
わずか数カ月後の2024年には、世界中のほとんどの国でパワフルなモデルが無料で利用できるようになるだろう。
OpenAIは5月にGPT-4oを全ユーザーに無料化し、6月にはクロード3.5ソネットを無料化した。過去1年間、無料ユーザーはほとんどGPT-3.5レベルのモデルしか使えなかったので、これは重要な変化です。過去には、LLMの実際の能力について、新規ユーザーにとって明確さを欠くことにつながっていたでしょう。
オープンAIがChatGPT Proを発表したことで、この時代は終わりを告げた!この月額200ドルのサブスクリプション・サービスは、最もパワフルなモデルであるo1 Proにアクセスする唯一の方法です。この月額200ドルのサブスクリプション・サービスは、最もパワフルなモデルであるo1 Proにアクセスする唯一の方法です。
o1シリーズ(そして間違いなくそれに触発されるであろう将来のモデル)の背後にある鍵は、より良い結果を得るために、より多くの計算時間を費やすことです。そのため、SOTAモデルを無料で利用できる時代は終わったと思います。
8.まだ生まれていない知性体
私は個人的に次のように考えている。エージェント」という言葉がとても悔しい。.それは、単一の、明確で広く理解される意味を欠いている......。しかし、この言葉を使う人々は、このことを決して認めないようだ。
もしあなたが私に「エージェント」を作っていると言うなら、あなたは私に何も伝えていないことになる。あなたの心を読まなければ、あなたが話しているのが何十通りもある定義のうちのどれなのか、私には知る術がない。
私が目にする人々には、大きく分けて2つのタイプがある。一方のグループは、エージェントを明らかにあなたの代わりに行動するもの、つまり旅行代理人と考え、もう一方は、エージェントを、問題解決の一環としてループで実行できるツールにアクセスできるLLMと考える。自律性」という言葉もよく使われるが、これも明確な定義はない。(数ヶ月前、私はエージェントの211の定義をツイートし、gemini-exp-1206に要約してもらいました)。
その言葉が何を意味するかは別として。エージェントは、まだ永遠の "coming soon "感がある。.用語はさておき。実用性についてはまだ懐疑的だLLMはあなたの言うことを何でも信じる。旅行代理店やデジタルアシスタント、あるいはリサーチツールでさえ、何が真実で何が嘘かを見分けることができなければ、どれほど役に立つだろうか?
つい数日前、グーグル検索で、実在しない映画『エンカント2』に関するまったく誤った記述が見つかった。
適時注入は、この騙されやすさの当然の帰結である。2022年9月から議論してきたこの問題への取り組みが、2024年にはほとんど進展していないと私は見ている
プロンプト・インジェクション攻撃は、この「騙されやすさ」の当然の帰結である。2022年9月から議論してきたこの問題への取り組みが、2024年に業界で進展することはほとんどないと私は見ている。
最も一般的なエージェントのコンセプトは、AGIに依存するのではないかと思い始めている。騙されやすさ」に強いモデルを作るのは、実に難しい注文だ!.
9.評価、非常に重要
Anthropicのアマンダ・アスケル(クロードのために)。 キャラクター その背後にあるほとんどの仕事)はこう言っていた:
優れたシステム・プロンプトの裏には、退屈だが重要な秘密がある。システム・プロンプトを書いてから、それをテストする方法を考えるのではない。テストを書き、そのテストに合格するシステムプロンプトを見つけるのだ。
2024年の間に、以下のことが明らかになった。LLM駆動システムの優れた自動評価を書くこれらのモデルの上に有用なアプリを構築するために最も必要とされるスキルである。強力な評価スイートを持っていれば、競合他社よりも早く新しいモデルを採用し、より良い反復を行い、より信頼性が高く有用な製品機能を構築することができる。
ヴェルセルの最高技術責任者であるマルテ・ウブルはこう考えている:
v0(ウェブ開発エージェント)が最初に導入されたとき、私たちはあらゆる種類の複雑な前処理と後処理でプロンプトを保護することに偏執的だった。
私たちは完全に自由にさせることにした。評価やモデリング、特にUXプロンプトがないのは、説明書のない壊れたASMLマシンのようなものです。
私はまだ自分の仕事にとってより良いモデルを見つけようとしている。査定が重要であることは誰もが知っていることだが、そのためにアセスメントを達成するための最良の方法に関する適切なガイダンスがまだ不足している。.
10.アップル・インテリジェンスは最悪だが、MLXは素晴らしい!
マックユーザーとして、私は今、自分の選択したプラットフォームについてより良い気分だ。
2023年には、NVIDIA GPUを搭載したLinux/Windowsマシンを持っていないような気がして、新しいモデルを試すには大きなハンデになる。
理論的には、CPUとGPUが同じ量のメモリを共有できるため、64GBのMacはモデルを実行するのに適したマシンであるはずだ。実際には、多くのモデルがモデルウェイトやライブラリとして公開されており、他のプラットフォームよりもNVIDIAのCUDAが好まれている。
ラマ.cpp エコシステムにも助けられたが、本当のブレークスルーはアップルのMLXライブラリだ。
Appleのmlx-lm Pythonサポートは、私のMac上で様々なmlx互換モデルを素晴らしいパフォーマンスで動かしている。Hugging Faceのmlxコミュニティは、必要なフォーマットに変換された1000以上のモデルを提供している。Prince Canumaのmlx-vlmプロジェクトは素晴らしく、迅速に進んでおり、またAppleにビジュアルLLMをもたらしている。カヌマ王子のmlx-vlmプロジェクトは素晴らしく、急速に進んでおり、Apple SiliconにもビジュアルLLMをもたらした。
MLXはゲームチェンジャーだったが、アップル独自のアップル・インテリジェンス機能はほとんど期待外れだった。.私は6月に最初のリリースについての記事を書いたが、その時はアップルがユーザーのプライバシーの保護に注力し、LLMアプリについて惑わされるユーザーを最小限に抑えたと楽観視していた。
これらの機能が利用できるようになった今、それらはまだ比較的非効率的である。LLMのヘビーユーザーである私は、これらのモデルの能力を知っているが、アップルのLLM機能は、最先端のLLM機能の模倣に過ぎない。その代わり、ニュースの見出しを歪めるような通知サマリーが表示され、ライティング・アシスタント・ツールが役に立つとはまったく思わない。それでも、Genmojiはかなり楽しい。
11.推論スケーリング、「推論」モデルの台頭
2024年の最後の四半期で最も興味深い進展は、OpenAIのo1モデル(9月12日にリリースされたo1-previewとo1-mini)に代表される、新しいLLM形態の出現だった。これらのモデルについて考える1つの方法は、思考の連鎖を促すテクニックの延長として考えることだ。
トリックは主に次のようなものだ。モデルが解いている問題について、モデルに一生懸命考えさせれば(声に出して話させれば)、たいていの場合、モデルがそうしなければ得られなかった結果が得られるだろう.
o1はこのプロセスをモデル内にさらに埋め込む。詳細は少し曖昧ですが、o1モデルは問題を考えるために "推論トークン "を消費し、ユーザーはそれを直接見ることはできません(ChatGPT UIは要約を表示しますが)。
ここでの最大の革新は、モデルを拡張する新しい方法を切り開いたことだ。モデルは推論により多くの計算量を費やすことで、より難しい問題を解決できるようになった。純粋にトレーニング時の計算量を増やすことでモデルの性能を向上させるのではなく.
o1の後継であるo3は12月20日にリリースされ、100万ドル以上の計算時間コストがかかったにもかかわらず、ARC-AGIベンチマークで素晴らしい結果を残した!
o3は1月にリリースされる予定だ。このレベルの計算能力から恩恵を受けられる現実的な問題を抱えている人がたくさんいるとは思えない!しかし、より困難な問題を解決するためのLLMアーキテクチャーの真の次のステップになりそうだ。
12月19日、グーグルはこの分野への最初の参入者であるgemini-2.0-flash-thinking-expをリリースした。
アリババのQwenチームは、11月28日にQwQモデルをApache 2.0ライセンスの下でリリースした。続いて12月24日には、QvQと呼ばれる視覚的推論モデルをリリースした。
ディープシーク DeepSeek-R1-Lite-Previewモデルは、11月20日にチャット・インターフェースを通じて試用できるようになった。
編集部注:ウィズダムスペクトラムは2024年最後の日にもリリースされた。ディープ推論モデル GLM-Zero.
アントロピックとメタはまだ何も進歩していないが、もし彼ら独自の推論拡張モデルがないのであれば、私はとても驚いている。
12.現在、最高のLLMは中国で訓練されているのか??
正確ではないが、ほとんど!目を引く素晴らしい見出しにはなる。
DeepSeek v3は、685Bの巨大なパラメトリックモデルである。これは、公開されているライセンスモデルの中で最大級のもので、MetaのLlamaファミリーの中で最大級のLlama 3.1 405Bよりもはるかに大きい。
ベンチマークでは、クロード3.5ソネットと同等であり、Vibeベンチマークでは、ジェミニ2.0とOpenAI 4o/o1モデルに次いで、現在7位にランクされている。これは、現在までのところ、公的にライセンスされたモデルとしては最高ランクである。
本当に印象的なのはDeepSeek v3トレーニング費用このモデルは2788000 H800 GPU時間で学習され、推定コストは5576000ドルでした。Llama 3.1 405Bは、DeepSeek v3の11倍にあたる30840000GPU時間で学習しましたが、モデルのベースライン性能はやや低下しました。
中国製GPUの輸出に対するアメリカの規制は、非常に効果的なトレーニングの最適化を促したようだ。
13.操作プロンプトが環境に与える影響を改善。
ホスティング・モデルであれ、私がローカルで運営しているものであれ、効率化の歓迎すべき結果のひとつは、プロンプトの運営にかかるエネルギー消費と環境への影響がここ数年で大幅に削減されたことだ。
OpenAI独自のプロンプト料金は、当時のGPT-3の100分の1。私が確かな筋から聞いたところでは、グーグル・ジェミニもアマゾン・ノバ(最も安いモデルプロバイダー2社)も、赤字で敏速な運営をしていないそうだ。
つまり、個々のユーザーとしては、大半のプロンプトが消費するエネルギーについて罪悪感を感じる必要はまったくないのだ。通りを車で走ったり、YouTubeでビデオを見たりするのに比べれば、その影響はごくわずかかもしれない。
ディープシークv3のトレーニング費用は600万ドル以下である。
14.新しいデータセンターはまだ必要か?
さらに大きな問題は、これらのモデルが将来必要とするインフラを構築するために、大きな競争圧力がかかるということだ。
グーグル、メタ、マイクロソフト、アマゾンなどの企業は、新しいデータセンターに何十億ドルも費やしており、電力網や環境に大きな影響を与えている。新しい原子力発電所を建設するという話もあるが、それには何十年もかかるだろう。
このインフラは必要なのだろうか?ディープシークv3の600万ドルのトレーニング費用と、LLMの継続的な価格引き下げは、そう主張するには十分かもしれない。しかし、あなたはこのインフラに反対を唱え、数年後にその間違いが証明されることになった大手ハイテク企業の重役になりたいだろうか?
対照的で興味深いのは、19世紀に世界中で行われた鉄道の発展である。これらの鉄道建設には莫大な投資が必要で、環境に大きな影響を及ぼし、建設された路線の多くが不必要であることが判明した。
その結果、バブルは何度かの金融崩壊を引き起こし、有用なインフラを大量に残しただけでなく、多くの破産と環境破壊をもたらした。
15.2024年、"ドロドロ "の年
2024年は「ドロドロ」という言葉が芸術用語になる年だ。と@deepfatesはツイッターで書いている:
スパム」が不要な電子メールの固有名詞になったように、「ドロボー」はAIが生成する不要なコンテンツの固有名詞として辞書に載るだろう。
私は5月にこの定義を少し拡大した記事を書いた:
「スロップ」とは、人工知能によって生成された未承諾・無修正のコンテンツを指す。
私が「ドロドロ」という言葉を気に入っているのは、生成AIを使うべきでない方法のひとつを簡潔に要約しているからだ!
16.合成トレーニングデータ、非常に効果的
意外なことに、「モデル崩壊」、つまり、再帰的に生成されたデータでAIモデルを学習させるとAIモデルが崩壊するという概念は、人々の意識に深く根付いているようだ。.
AIが生成した "ドロドロしたもの "がインターネット上に溢れれば、モデル自体が劣化し、自らの出力を糧に、必然的に終焉を迎えるというのだ!
明らかに、これは起こらなかった.その代わりに、AIラボが合成コンテンツで訓練することが増えている。つまり、モデルを正しい方向に導くのに役立つ人工的なデータを作成することである。
私が見た中で最も良い説明のひとつは、ファイ-4のテクニカルレポートにある。これには以下が含まれる:
合成データは事前学習の重要な一部として一般的になりつつあり、Phiファミリーのモデルは常に合成データの重要性を強調してきた。合成データは、実データの安価な代替というよりも、実データと比較していくつかの直接的な利点があります。
構造化漸進学習。実際のデータセットでは、トークン間の関係は複雑で間接的であることが多い。現在のトークンと次のトークンを関連付けるために多くの推論ステップが必要になる場合があり、モデルが次のトークンの予測から効果的に学習することが難しくなる。対照的に、言語モデルによって生成される各トークンは、前のトークンによって予測されるため、モデルは結果として得られる推論パターンに従うことが容易になる。
もうひとつの一般的なテクニックは、より小さな、より安価なモデルのためのトレーニングデータを作成するために、より大きなモデルを使用することである。
DeepSeek v3 は以下を使用します。 ディープシーク-R1 メタのラマ3.3 70Bの微調整は、2500万以上の合成的に生成された例を使用しています。
LLMに使用するトレーニングデータを慎重に設計することが、これらのモデルを作成する鍵のようだ。ウェブからあらゆるデータを収集し、無差別にトレーニングに投入する時代はとっくに終わった。
17.LLMを適切に使用することは容易ではない!
私は常に、LLMは強力なユーザーツールであり、チョッパーに見せかけたチェーンソーだと強調してきた。チャットボットにメッセージを入力するのがどれほど難しいことか。しかし、実際にはそれらを最大限に活用し、多くの落とし穴を避けるためには、それらを深く理解し、多くの経験を積む必要がある。.
この問題は2024年にはさらに悪化する。
私たちは人間の言葉で話しかけられるコンピューターシステムを構築し、あなたの質問に答えることができる。質問の内容、質問のされ方、そして未記録の秘密のトレーニングセットに正確に反映できるかどうかによる。
今日、利用可能なシステムの数は急増している。Python、JavaScript、ウェブ検索、画像生成、さらにはデータベース・クエリなどなど......。そこで、これらのツールがどのようなもので、何ができるのか、そしてLLMがそれらを使っているかどうかを見分ける方法を、よりよく理解する必要がある。
ChatGPTには、Pythonを実行する2つの異なる方法があることをご存知ですか?
外部APIと対話するクロード・アーティファクトを構築したいのであれば、CSPとCORS HTTPヘッダーについて学ぶのが良いだろう。
OpenAIのo1はようやくイチゴの "r "を計算できるようになったが、LLMとしての性質とランタイム・ハーネスによって、その機能はまだ制限されている。o1はウェブ検索やコード・インタプリタを使えないが、GPT-4oは使える - どちらも同じChatGPT UIにある。GPT-4oはできます - 両方とも同じChatGPT UIにあります。
私たちはそれに対して何をしたのか?何もしていない。ほとんどのユーザーは "初心者 "です。デフォルトのLLMのチャットUIは、Linuxのターミナルに真新しいコンピュータユーザーを放り込んで、彼らが自分ですべてを処理することを期待しているようなものだ。
同時に、エンドユーザーがこれらのデバイスがどのように動作し、機能するかについて不正確なメンタル・モデルを構築することがますます一般的になってきている。ChatGPTのスクリーンショットを使って議論に勝とうとする人たちは、このような例をたくさん見てきた。このようなモデルの本質的な信頼性の低さと、適切なプロンプトを与えれば何でも言わせることができるという事実を考えると、これはおかしな提案だ。
裏を返せば、多くの "古参者 "がLLMを完全にあきらめているということでもある。LLMを最大限に活用する鍵は、この信頼できないが強力なテクニックの使い方を学ぶことだ。これは明らかなスキルではない!
世の中に有益な教育コンテンツがたくさんある一方で、私たちは、猛烈にツイートするAIのシルにすべてをアウトソーシングするよりも、もっと良い仕事をする必要がある。
18.認知力の低下、まだある
今すぐだ。ほとんどの人がChatGPTの名前を聞いたことがあると思いますが、クロードの名前を聞いたことがある人はどれくらいいるでしょうか?
このような問題に積極的に関心を持つ人と、そうでない人の間に、99%は存在する。大きな知識格差.
先月は、携帯電話のカメラを何かに向けると、それについて音声で話してくれるリアルタイム・インターフェイスの人気を目にした。ファーザー・クリスマスのふりをさせるオプションもある。ほとんどの自称 "オタク "はまだ試していない。
このテクノロジーが社会に及ぼし続ける(そして潜在的な)影響を考えると、私は現在のこの溝は不健康だ.この状況を改善するために、もっと努力してほしい。
19.LLM、より良い批評が必要
LLMを嫌う人は本当に多い。私がよく利用するいくつかのサイトでは、「LLMはとても役に立つ」という提案でさえ、戦争を始めるには十分だ。
私は理解している。環境への影響、トレーニングデータの信頼性の欠如、積極的でないアプリケーション、人々の仕事への潜在的な影響など、人々がこの技術を好まない理由はたくさんある。
LLMは間違いなく批判に値する。私たちは、これらの問題について議論し、それを軽減する方法を見つけ、人々が責任を持ってこれらのツールを使用する方法を学ぶのを支援する必要がある。
私はこの技術に懐疑的な人々が大好きだ。この2年以上、誇大広告は拡大し、多くの誤った情報が世間を埋め尽くしてきた。この誇大広告に基づいて、多くの間違った決断がなされてきた。批判は美徳だ。
意思決定権を持つ人々に、これらのツールの適用方法について正しい決断をしてもらいたいのであれば、私たちはまず、実際に良い適用方法があることを認識し、次に、多くの非実用的な落とし穴を避けながら、それらを実践する方法を説明する手助けをする必要がある。
私はそう思う。この分野全体が、常にでっち上げを行う環境破壊的な盗作マシーンであると人々に伝えることは、それがどれほど真実であろうとも、これらの人々に対する冒涜である。..ここには真の価値があるが、その価値に気づくには直感的ではなく、指導が必要だ。
このようなことを理解している私たちには、他の人が理解できるように手助けする責任がある。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません