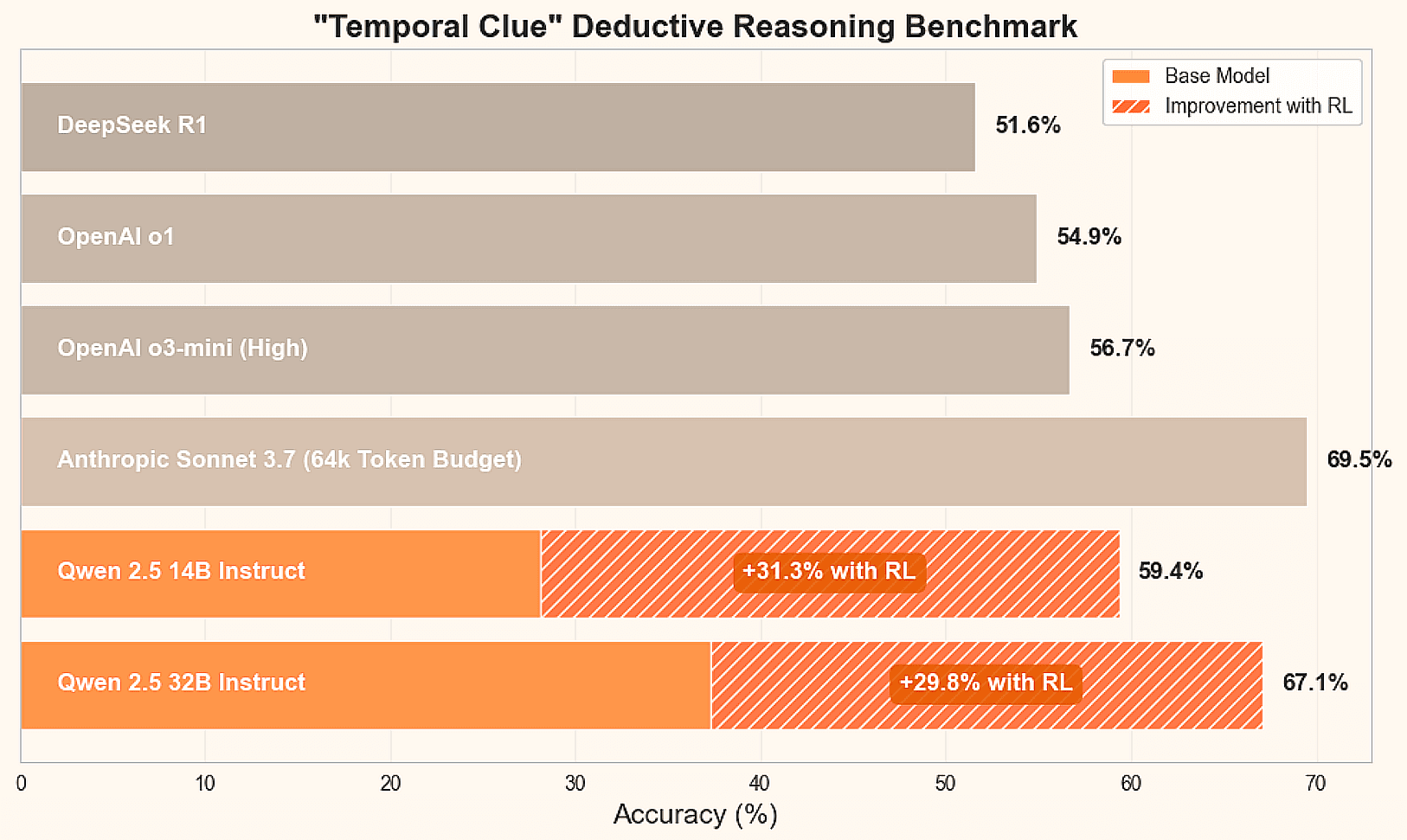
エージェンティック・チャンキング:AIエージェント駆動型意味論的テキストチャンキング

紹介
大規模言語モデル(LLM)の応用領域では、特に検索強化生成(ラグ)システムでは、テキストのチャンキングが重要な役割を果たす。 テキスト・チャンキングの質は文脈情報の妥当性に直結し、ひいてはLLMが生成する解答の正確性と完全性に影響する。 固定サイズの文字チャンキングや再帰的テキスト分割といった従来のテキストチャンキング手法では、文や意味単位の途中で切れてしまい、文脈の喪失や意味の不統一を引き起こすなど、その本質的な限界が明らかにされている。 本論文では、よりインテリジェントなチャンキング戦略であるAgentic Chunkingについて掘り下げていく。 このアプローチは、人間の判断プロセスを模倣し、意味的に首尾一貫したテキストの塊を作成することを目的としており、RAGシステムのパフォーマンスを大幅に向上させる。 さらに、読者が始めるのに役立つ詳細なコード例も提供する。
参考図書シンプルで効果的なRAG検索戦略:疎+密のハイブリッド検索と並べ替え、そしてテキストチャンクの全体的な文書関連コンテキストを生成するための「キューキャッシング」の使用。
エージェンティック・チャンキングとは?
エージェント・チャンキング は最先端のLLMベースのチャンキングアプローチであり、テキストセグメンテーション時の人間の理解と判断を模倣し、意味的に首尾一貫したテキストの塊を生成することを目的としている。 核となる考え方は、テキスト中の文字や組織などの「エージェント的」要素に注目し、これらのエージェント的要素に関連する文章を集約して意味のある意味単位を形成することである。
核となる考え方 Agentic Chunkingの本質は、単に文字数や定義済みの区切り文字に頼ってテキストを分割するのではないということだ。 その代わりに、LLMの意味理解能力を活用し、意味的に密接に関連する文章を、たとえこれらの文章が元のテキストで連続した位置にあっても、チャンクに結合する。 このアプローチは、テキストの本質的な構造と意味的な関連性をより正確に捉える。
なぜエージェンティック・チャンキングが必要なのか?
従来のテキストチャンキング手法には、無視できない限界がある:
- 固定サイズの文字チャンク(固定サイズ キャラクター チャンキング):
- この方法では、テキストをあらかじめ定義された一定の長さのブロックに機械的に分割する。 そのため、文の途中の文字間や単語内でも切り捨てられ、テキストの意味的整合性が大きく損なわれることがある。
- 見出しやリストなど、文書に内在する構造を完全に無視するため、文書の論理構造から切り離されたチャンキング結果となる。
- また、恣意的なセグメンテーションは、同じテキストブロックの中に無関係な主題を混在させ、文脈の一貫性をさらに損なうこともある。
- 再帰的テキスト分割:
- 再帰的テキストセグメンテーションは、セグメンテーションのために、段落、文、単語など、あらかじめ定義された階層的なセパレータに依存する。
- このアプローチでは、複数レベルの見出しや表など、複雑な文書構造を効果的に扱えない可能性があり、その結果、構造情報が失われてしまう。
- 段落や箇条書きリストのような意味的単位の途中で切り捨てが起こり、意味的整合性に影響を与える可能性はまだある。
- 重要なのは、再帰的なテキストセグメンテーションには、テキストの意味論に対する深い理解が欠けており、セグメンテーションのために表面的な構造だけに頼っていることである。
- セマンティック・チャンキング:
- セマンティック・チャンキングは、埋め込みベクトルの類似性に基づいて文章をグループ化し、意味的に関連性のあるチャンクを作成しようとするものである。
- しかし、段落内のセンテンスが意味論的に大きく異なる場合、セマンティック・チャンキングはこれらのセンテンスを異なるチャンクに誤って分類し、段落内の一貫性が損なわれる可能性がある。
- さらに、セマンティック・チャンキングは通常、大量の類似度計算を必要とし、特に大規模な文書を処理する場合には計算コストが著しく増大する。
エージェンティック・チャンキングは、以下のような利点により、上記のような従来の方法の限界を効果的に克服している:
- 意味の一貫性:エージェンティック・チャンキングは、意味的に意味のあるテキストの塊を生成することができ、関連情報の検索精度が大幅に向上します。
- 文脈の保持:テキストブロック内の文脈の一貫性をよりよく保持し、LLMがより正確で文脈に沿った応答を生成できるようにする。
- 柔軟性:Agentic Chunkingメソッドは高い柔軟性を示し、より幅広い用途のために、異なる長さ、構造、コンテンツタイプのドキュメントに適応することができる。
- 堅牢性:エージェント・チャンキングは完璧な保護機構とフォールバック機構を備えており、異常に複雑な文書構造やLLMのパフォーマンス制約の場合でも、チャンキングの有効性と安定性を確保することができる。
エージェント・チャンキングの仕組み
エージェンティック・チャンキングのワークフローは、以下の主要なステップで構成される:
- ミニ・チャンク・クリエーション
- まず、Agentic Chunkingでは、再帰的なテキスト分割技術を使い、入力文書をより小さなマイクロ・チャンクに分割する。 例えば、各マイクロ・チャンクのサイズは約300文字に制限される。
- セグメンテーションの過程で、エージェント・チャンキングは、基本的な意味的整合性を保つために、ミニチュア・チャンクが文の途中で切り捨てられないように特別な注意を払う。
- ミニチャンクに印をつける
- 次に、各マイクロブロックに固有のマーカーが付けられる。 このマーカーは、その後の処理でLLMが各マイクロブロックの境界を識別するのに役立つ。
- LLMがテキストを処理する際に、より重要なのは、そのテキストが、より多くのことを考慮に入れていることである。 トークン LLMは、正確な文字数ではなく、テキストの構造的・意味的パターンを認識するのが得意です。 マイクロブロックをマークすることで、LLMは文字を正確にカウントできなくても、ブロックの境界を認識することができる。
- LLMによるチャンク・グルーピング:
- 具体的な指示とともに、タグを付けた文書をLLMに提出する。
- この時点で、LLMのタスクは、ミニチュアのチャンクのシーケンスを詳細に分析し、意味的な関連性に基づいて、それらをより大きな、意味的に首尾一貫したテキストのチャンクに結合することである。
- グループ化プロセスでは、各ブロックに含まれるマイクロブロックの最大数などの制約を設定し、実際の要件に応じてブロックのサイズを制御することができる。
- チャンク・アセンブリー
- LLMによって選択されたマイクロブロックを組み合わせて、エージェンティック・チャンキングの最終出力であるテキストブロックを形成する。
- これらのテキストブロックをより適切に管理・利用するために、各ブロックに関連するメタデータを追加することができる。例えば、元の文書のソース情報、文書内のテキストブロックのインデックス位置などである。
- コンテキスト保存のためのチャンクのオーバーラップ:
ブロック間の文脈の一貫性を確保するため、最終的に生成されるブロックは通常、前後のマイクロブロックとある程度の重複を持つ。 この重複メカニズムにより、LLMは隣接するテキストブロックを処理する際に文脈情報をより理解しやすくなり、情報の断片化を避けることができる。 - ガードレールとフォールバックメカニズム:
- ブロック・サイズ制限:最大ブロック・サイズを強制的に設定し、生成されるテキスト・ブロックが常にLLMの入力長制限内に収まるようにし、長すぎる入力による問題を回避する。
- コンテキスト・ウィンドウの管理: LLMのコンテキスト・ウィンドウの制限を超える非常に長いドキュメントの場合、Agentic Chunkingはインテリジェントに管理可能な複数の部分に分割し、バッチで処理することで、処理の効率と効果を保証します。
- 検証:チャンキングが完了すると、Agentic Chunkingは検証プロセスも実行し、すべてのマイクロチャンクが最終的なテキストブロックに正しく含まれていることを確認し、情報の欠落を防ぎます。
- 再帰的チャンキングへのフォールバック: LLM処理が何らかの理由で失敗したり、利用できない場合、Agentic Chunkingは、従来の再帰的テキスト・チャンキング・メソッドに優雅にフォールバックし、基本的なチャンキング機能がすべてのケースで提供されることを保証します。
- 並列処理:Agentic Chunkingは並列処理モードをサポートし、マルチスレッドと他の技術を使用することにより、テキストチャンキングの処理速度を大幅に加速することができます。
エージェント・チャンキングの応用
エージェンティック・チャンキング・テクノロジーは、多くの分野で応用できる強い可能性を示している:
1.強化された学習
- 定義と説明:Agentic RAGは、複雑な情報を管理しやすい単位に分解することで学習プロセスを最適化し、学習者の理解と定着を高めます。 このアプローチでは、テキストの「エージェント的」要素(登場人物や組織など)に特に注意を払い、これらのコア要素を中心に情報を整理することで、エージェント的RAGはより首尾一貫した、利用しやすい学習コンテンツを作成することができます。
- 学習プロセスにおける役割:エージェント型RAGフレームワークは、現代の教育方法においてますます重要な役割を果たしている。 RAG技術に基づくインテリジェント・エージェントを使用することで、教育者は、様々な学習者の個々のニーズに的確に応えるために、より柔軟にコンテンツを調整することができる。
- 教育への応用:ますます多くの教育機関がAgentic RAGテクノロジーを利用して、教育戦略を革新し、より魅力的でパーソナライズされたカリキュラムを開発し、教育と学習の成果を向上させています。
- 生徒の学習意欲への影響:エージェンティック・チャンキングは、情報を明確に構成された理解しやすいテキストブロックで提示することで、生徒の学習への集中力、意欲、関心を高めるのに効果的である。
- 効果的なパターン認識:教育におけるエージェント型RAGシステムの使用における効果的なパターンの詳細な分析と識別は、教育成果を継続的に最適化するために不可欠である。
2.情報保持の改善
- 認知プロセス:エージェントRAGテクノロジーは、情報を整理し関連付けるという人間の認知プロセスの自然な傾向を利用し、情報の保持を強化します。 脳はデータを管理しやすい単位に整理することを好むため、情報の検索と想起のプロセスが大幅に簡素化されます。
- 記憶想起の向上:テキストに関係する「エージェント的」要素(例:個人や組織)に焦点を当てることで、学習者は学習教材を自分の既存の知識体系とより容易に結びつけることができ、その結果、学習した情報をより効果的に想起し、定着させることができる。
- 長期的な定着戦略:Agentic RAGテクノロジーを日常の学習習慣に組み込むことで、継続的な学習と知識の蓄積のための効果的な戦略を構築し、長期的な知識の定着と発展を可能にする。
- 実用的なアプリケーション:教育やビジネストレーニングなどの分野では、Agentic RAGのコンテンツプレゼンテーションは、最適な情報配信と取り込みのために、特定の聴衆のニーズに合わせてカスタマイズすることができます。
3.効率的な意思決定
- ビジネスへの応用:ビジネスの世界では、Agentic RAGシステムは、意思決定のための構造化されたフレームワークを提供することで、ビジネスリーダーの意思決定パラダイムに革命をもたらしている。 それは、戦略的プランニングと業務効率の科学を大幅に強化するフレームワークを提供します。
- 意思決定のフレームワーク:Agentic RAGは、複雑なビジネスデータや情報をより小さく管理しやすい断片に分解することができ、組織の意思決定者が重要な要素に集中し、大量の情報の中で迷子になるのを防ぎ、意思決定の効率を向上させるのに役立ちます。
- ビジネスリーダーにとってのメリット:Agentic RAGは、ビジネスリーダーが市場動向や顧客ニーズをより深く理解することを支援し、企業の戦略調整や市場対応のより正確な意思決定をサポートします。
- 実施ステップ
- Agentic RAGテクノロジーがお客様の組織に付加価値を与えることができる主要なビジネス分野を特定します。
- 組織の戦略目標に高度に合致したAgentic RAGのカスタマイズされた実装を開発する。
- エージェントRAGシステムの効果的な導入と適用を確実にするために、エージェントRAGシステムのアプリケーションについてスタッフをトレーニングする。
- Agentic RAGシステムの運転効果を継続的に監視し、実際のアプリケーション状況に応じて最適化戦略を調整し、システムの最大性能を確保します。
エージェント・チャンキングの利点
- 意味の一貫性: Agentic Chunkingは、テキストの意味的により意味のあるチャンクを生成し、検索される情報の精度を大幅に向上させます。
- 文脈の保持:エージェンティック・チャンキングは、テキストブロック内の文脈の一貫性を効果的に維持し、LLMがより正確で文脈に沿った応答を生成できるようにする。
- 柔軟性: Agentic Chunkingは、様々な長さ、構造、コンテンツタイプのドキュメントに適応する優れた柔軟性を発揮します。
- 堅牢性:エージェンティック・チャンキングには、文書構造の異常やLLMの性能制限の場合でも安定したシステム運用を保証するための保護とフォールバックのメカニズムが組み込まれている。
- 適応性:エージェンティック・チャンキングは、さまざまなLLMとシームレスに統合され、特定のアプリケーションの要件に合わせて微調整された最適化をサポートします。
エージェント・チャンキングの実際
- 誤った思い込みを92%削減:従来のチャンキング手法の欠点は、不正確なチャンキングがAIシステムによる誤った思い込みにつながることです。 Agentic Chunkingは、このようなエラーを92%も削減することに成功しました。
- 回答の完全性の向上: エージェントチャンキングは、回答の完全性を大幅に向上させ、より包括的で正確な回答をユーザーに提供し、ユーザーエクスペリエンスを大幅に改善します。
エージェント・チャンキングの実装(Pythonの例)
このセクションでは、LangchainフレームワークをベースとしたAgentic Chunking Pythonコードのサンプル実装を提供し、読者がすぐに始められるようにコードをステップバイステップで詳しく説明します。
前提条件
- LangchainとOpenAIのPythonライブラリがインストールされていることを確認する:
pip install langchain openai - OpenAI API キーを設定します。
サンプルコード:
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain import hub
# 1. 文本命题化 (Propositioning)
# 示例文本
text = """
On July 20, 1969, astronaut Neil Armstrong walked on the moon.
He was leading NASA's Apollo 11 mission.
Armstrong famously said, "That's one small step for man, one giant leap for mankind" as he stepped onto the lunar surface.
Later, he planted the American flag.
The mission was a success.
"""
# 从 Langchain hub 获取命题化提示模板
obj = hub.pull("wfh/proposal-indexing")
# 使用 GPT-4o 模型
llm = ChatOpenAI(model="gpt-4o")
# 定义 Pydantic 模型以提取句子
class Sentences(BaseModel):
sentences: list[str]
# 创建结构化输出的 LLM
extraction_llm = llm.with_structured_output(Sentences)
# 创建句子提取链
extraction_chain = obj | extraction_llm
# 将文本分割成段落 (为简化示例,本文假设输入文本仅包含一个段落,实际应用中可处理多段落文本。)
paragraphs = [text]
propositions = []
for p in paragraphs:
sentences = extraction_chain.invoke(p)
propositions.extend(sentences.sentences)
print("Propositions:", propositions)
# 2. 创建 LLM Agent
# 定义块元数据模型
class ChunkMeta(BaseModel):
title: str = Field(description="The title of the chunk.")
summary: str = Field(description="The summary of the chunk.")
# 用于生成摘要和标题的 LLM (这里可以使用温度较低的模型)
summary_llm = ChatOpenAI(temperature=0)
# 用于块分配的 LLM
allocation_llm = ChatOpenAI(temperature=0)
# 存储已创建的文本块的字典
chunks = {}
# 3. 创建新块的函数
def create_new_chunk(chunk_id, proposition):
summary_prompt_template = ChatPromptTemplate.from_messages(
[
(
"system",
"Generate a new summary and a title based on the propositions.",
),
(
"user",
"propositions:{propositions}",
),
]
)
summary_chain = summary_prompt_template | summary_llm
chunk_meta = summary_chain.invoke(
{
"propositions": [proposition],
}
)
chunks[chunk_id] = {
"chunk_id": chunk_id, # 添加 chunk_id
"summary": chunk_meta.summary,
"title": chunk_meta.title,
"propositions": [proposition],
}
return chunk_id # 返回 chunk_id
# 4. 将命题添加到现有块的函数
def add_proposition(chunk_id, proposition):
summary_prompt_template = ChatPromptTemplate.from_messages(
[
(
"system",
"If the current_summary and title is still valid for the propositions, return them."
"If not, generate a new summary and a title based on the propositions.",
),
(
"user",
"current_summary:{current_summary}\ncurrent_title:{current_title}\npropositions:{propositions}",
),
]
)
summary_chain = summary_prompt_template | summary_llm
chunk = chunks[chunk_id]
current_summary = chunk["summary"]
current_title = chunk["title"]
current_propositions = chunk["propositions"]
all_propositions = current_propositions + [proposition]
chunk_meta = summary_chain.invoke(
{
"current_summary": current_summary,
"current_title": current_title,
"propositions": all_propositions,
}
)
chunk["summary"] = chunk_meta.summary
chunk["title"] = chunk_meta.title
chunk["propositions"] = all_propositions
# 5. Agent 的核心逻辑
def find_chunk_and_push_proposition(proposition):
class ChunkID(BaseModel):
chunk_id: int = Field(description="The chunk id.")
allocation_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You have the chunk ids and the summaries. "
"Find the chunk that best matches the proposition. "
"If no chunk matches, return a new chunk id. "
"Return only the chunk id.",
),
(
"user",
"proposition:{proposition}\nchunks_summaries:{chunks_summaries}",
),
]
)
allocation_chain = allocation_prompt | allocation_llm.with_structured_output(ChunkID)
chunks_summaries = {
chunk_id: chunk["summary"] for chunk_id, chunk in chunks.items()
}
# 初始chunks可能为空,导致allocation_chain.invoke报错
if not chunks_summaries:
# 如果没有已存在的块,直接创建新块
next_chunk_id = 1
create_new_chunk(next_chunk_id, proposition)
return
best_chunk_id = allocation_chain.invoke(
{"proposition": proposition, "chunks_summaries": chunks_summaries}
).chunk_id
if best_chunk_id not in chunks:
# 如果返回的 chunk_id 不存在,创建新块
next_chunk_id = max(chunks.keys(), default=0) + 1 if chunks else 1
create_new_chunk(next_chunk_id, proposition)
else:
add_proposition(best_chunk_id, proposition)
# 遍历命题列表,进行分块
for i, proposition in enumerate(propositions):
find_chunk_and_push_proposition(proposition)
# 打印最终的块
print("\nFinal Chunks:")
for chunk_id, chunk in chunks.items():
print(f"Chunk {chunk_id}:")
print(f" Title: {chunk['title']}")
print(f" Summary: {chunk['summary']}")
print(f" Propositions: {chunk['propositions']}")
print("-" * 20)
コードの説明
- 命題化:
- このコード例では、まずhub.pull("wfh/proposal-indexing")を使って、Langchain Hubから定義済みのプロポジションテンプレートをロードする。
- 次に、ChatOpenAI(model="gpt-4o")を使ってLLMインスタンスを初期化した。
- LLMから出力された文のリストを構造化構文解析するためのSentences Pydanticモデルを定義する。
- プロンプトテンプレートとLLM extraction_chainの間にコネクションチェーンを構築する。
- 例を簡単にするため、この記事では入力テキストに含まれる段落は1つだけと仮定していますが、実際のアプリケーションでは複数の段落を扱うことができます。 コードは、サンプルテキストが段落のリストに分割されます。
- パラグラフをループし、extraction_chainを使ってパラグラフを命題のリストに変換する。
- LLMエージェントを作成します:
- ChunkMeta Pydanticモデルを定義し、ブロックのメタデータ構造(タイトルと要約)を定義する。
- summary_llmとallocation_llmの2つのLLMインスタンスを作成する。 summary_llmはテキストのブロックの要約とタイトルを生成するのに使われ、allocation_llmは命題がどの既存のブロックに入るべきかを決定したり、新しいブロックを作成したりする。
- 作成されたテキスト・ブロックを格納するためのチャンク辞書を初期化する。
- create_new_chunk関数:
- この関数は、chunk_idとpropositionを入力パラメータとして受け取る。
- 命題に基づいて、ブロックのタイトルと要約がsummary_prompt_templateとsummary_llmを使って生成される。
- そして、新しいブロックをチャンク辞書に格納する。
- add_proposition関数:
- この関数はまた、chunk_idとpropositionを入力として受け取る。
- チャンク辞書から既存のブロック情報を取得する。
- 現在のブロックの命題リストを更新する。
- ブロックのタイトルと要約を再評価し、更新する。
- そして、チャンク辞書の対応するブロックのメタデータを更新する。
- find_chunk_and_push_proposition 関数(エージェントのコアロジック):
- LLM出力用のブロックIDを解析するためのChunkID Pydanticモデルを定義する。
- LLMに、現在の命題に最もマッチする既存のブロックを見つけるか、新しいブロックIDを返すように指示するallocation_promptを作成する。
- allocation_chainをビルドし、プロンプトテンプレートとallocation_llmを接続する。
- 既存のブロックの ID と概要情報を格納する chunks_summaries 辞書を構築する。
- チャンク辞書が空の場合(つまり、テキストのチャンクがまだない場合)、新しいチャンクが直接作成される。
- allocation_chainを使ってLLMを呼び出し、ベストマッチするブロックのIDを取得する。
- LLMが返すchunk_idがchunks辞書にない場合、つまり新しいテキストチャンクを作成する必要がある場合、create_new_chunk関数が呼ばれる。
- 返された chunk_id がすでに chunks 辞書内に存在し、現在の命題が既存のテキストブロックに追加されるべきことを示す場合、 add_proposition 関数を呼び出します。
- メインループ:
- 命題リストをループする。
- それぞれの命題について、find_chunk_and_push_proposition関数が呼ばれ、命題が適切なテキストブロックに割り当てられる。
- 出力結果:
- タイトル、抄録、含まれる命題のリストを含む、生成されたテキストブロックの最終出力。
コード改善メモ:
- find_chunk_and_push_proposition関数を改良し、チャンク辞書が空のときにcreate_new_chunk関数を直接呼び出すことで、潜在的なエラーを回避。
- create_new_chunk関数では、chunks[chunk_id]辞書にchunk_idキーと値のペアが追加され、ブロックIDが明示的に記録される。
- next_chunk_id生成ロジックを最適化することで、ID生成ロジックのロバスト性が向上し、さまざまなシナリオにおいて正しいID生成が保証される。
ビルドとバイ
エージェンティック・チャンキングは、AIエージェントのワークフローの一部に過ぎませんが、意味的に一貫性のあるテキストの塊を生成するために重要です。 独自のAgentic Chunkingソリューションを構築することと、既製のソリューションを購入することには、利点と欠点があります:
セルフビルドの利点
- 高度なコントロールとカスタマイズ:自作ソリューションでは、プロンプトの設計からアルゴリズムの最適化まで、ユーザーが特定のニーズに応じて詳細なカスタマイズを行うことができ、そのすべてが実際のアプリケーション・シナリオに完璧に適合する。
- 的確なターゲティング:企業独自のデータ特性やアプリケーションのニーズに基づいて、最適なパフォーマンスを実現する最適なテキストチャンキング戦略をカスタマイズできます。
セルフビルドのデメリット
- 高いエンジニアリング・コスト:独自のエージェンティック・チャンキング・ソリューションを構築するには、自然言語処理技術に関する専門的な知識と、多大な開発時間を投資する必要があり、コストがかかります。
- LLMの挙動の予測不可能性:LLMの挙動は時に予測や制御が難しく、自作ソリューションにとって技術的な課題となる。
- 継続的なメンテナンス・オーバーヘッド:ジェネレーティブAI技術は急速に進化しており、自作ソリューションは、技術開発のペースに追いつくために、メンテナンスやアップデートに継続的な投資を必要とする。
- 生産上の課題:プロトタイピングの段階で良い結果を得ることは一つのポイントですが、99%以上の高い精度を持つAgentic Chunkingソリューションを実際に生産に導入するには、まだ大きな課題があります。
概要
Agentic Chunkingは、人間の理解と判断を模倣し、意味的に首尾一貫したテキストチャンクを作成する強力なテキストチャンキング手法であり、RAGシステムのパフォーマンスを大幅に向上させる。 Agentic Chunkingは、従来のテキストチャンキング手法の制限の多くを克服し、LLMがより正確で、完全で、文脈に沿った回答を生成することを可能にします。
この記事は、詳細なコード例とステップバイステップの説明を通して、読者がAgentic Chunkingの動作原理と実装を理解するのに役立ちます。 確かに、Agentic Chunkingの実装にはある程度の技術投資が必要ですが、それがもたらすパフォーマンスの向上とアプリケーションの価値は明らかです。 Agentic Chunkingは、大量のテキストデータを処理する必要があり、RAGシステムに高いパフォーマンスが要求されるアプリケーションシナリオにとって、間違いなく効果的な技術ソリューションです。
今後の方向性:エージェンティック・チャンキングの今後の方向性としては、以下のようなものが考えられる:
- 知識グラフを構築するためのグラフデータベースとの深い統合と、より深い知識マイニングと活用を実現するためのグラフ構造ベース検索拡張生成(グラフRAG)技術のさらなる開発。
- LLMのヒント工学と命令設計を継続的に最適化し、テキストチャンキングの精度と処理効率をさらに向上させる。
- より複雑で多様な文書構造に効果的に対処し、Agentic Chunkingの汎用性を向上させるために、よりスマートなテキストブロックのマージと分割戦略を開発する。
- 私たちは、エージェント・チャンキングの応用範囲を広げるため、知的文章要約、高品質機械翻訳など、より幅広い分野への応用を積極的に模索しています。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません