
HuggingFaceはo1の背後にある技術的な詳細を明らかにし、それをオープンソース化した!

小さなモデルに考える時間を長く与えれば、大きなモデルを凌駕することができる。
ここ最近、業界では小型モデルに対する熱意がかつてないほど高まっており、性能面で大型モデルを凌駕することを可能にするいくつかの「実用的なトリック」が登場している。
より小さなモデルの性能向上に注力することには、副次的な意味があると言える。大規模な言語モデルの場合、学習時間計算のスケーリングがその開発を支配してきた。このパラダイムは非常に効果的であることが証明されているが、より大規模なモデルの事前学習に必要なリソースは法外に高価になり、数十億ドル規模のクラスタが出現している。
その結果、この傾向は、別の補完的なアプローチ、すなわちテスト時間の計算スケーリングに大きな関心を呼び起こした。テスト時間の手法では、事前学習バジェットをどんどん大きくしていく代わりに、動的推論ストラテジーを使用することで、より難しい問題に対してモデルが「より長く考える」ことを可能にする。この顕著な例がOpenAIのo1モデルであり、テスト時間の計算量が増えるにつれて、難しい数学的問題に対して一貫した進歩を示している。
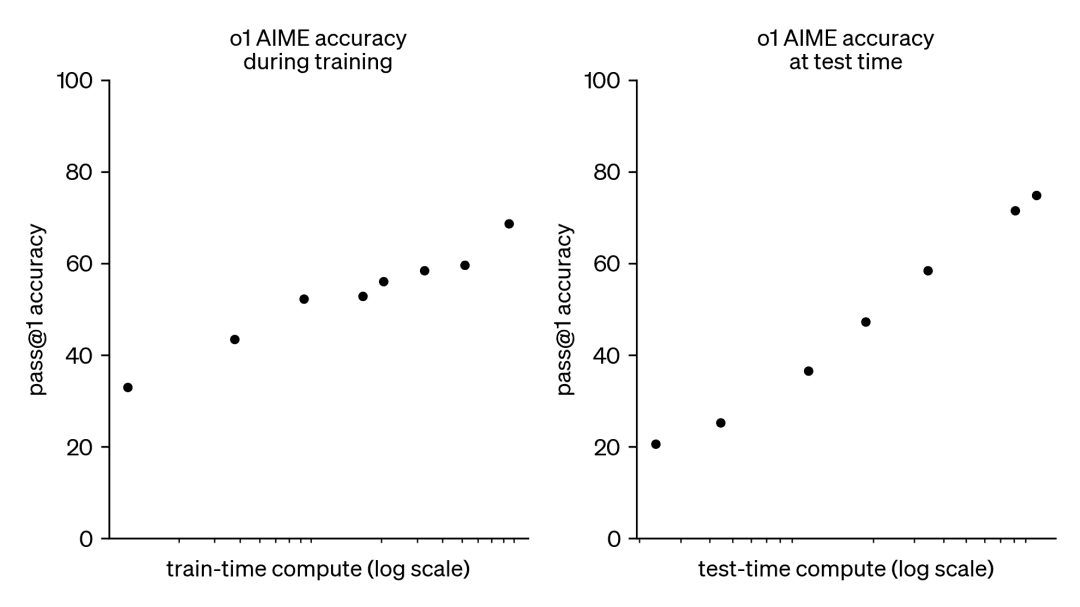
o1がどのように学習されるかは正確には分からないが、DeepMindの最近の研究によると、テスト時間計算の最適なスケーリングは、反復的な自己改善や、報酬モデルを使用した解空間の探索などの戦略によって達成できることが示唆されている。テスト時間の計算をプロンプトごとに適応的に割り当てることで、小規模なモデルでも大規模でリソース集約的なモデルに匹敵し、時にはそれを上回ることさえできる。計算時間のスケーリングは、メモリが限られており、利用可能なハードウェアがより大きなモデルを実行するには不十分である場合に特に有益である。しかし、この有望なアプローチはクローズドソースのモデルを用いて実証されたものであり、実装の詳細やコードは公開されていない。
ディープマインド論文:https://arxiv.org/pdf/2408.03314
過去数ヶ月間、HuggingFaceはこれらの結果をリバースエンジニアリングし、再現することに取り組んできた。彼らはこのブログ記事でそれを紹介するつもりだ:
- コンピュート・オプティマル・スケーリング(計算最適化スケーリング):DeepMindのトリックを実装することで、テスト時にオープンモデルの数学的能力を強化する。
- 多様性検証ツリー探索(DVTS):これはバリデータのブートストラップ木探索手法のために開発された拡張である。このシンプルで効率的なアプローチは、多様性を増加させ、特に大きな計算予算でテストする場合に、より良い性能を提供する。
- 検索して学ぶ:LLMを使った検索ストラテジーを実装するための軽量ツールキット。 ブイエルエルエム スピードアップを達成する。
では、計算上最適なスケーリングは実際にどの程度機能するのだろうか?下のグラフでは、MATH-500ベンチマークにおいて、十分な「思考時間」を与えれば、非常に小さな1Bと3Bのラマ・インストラクト・モデルが、はるかに大きな8Bと70Bのモデルを凌駕している。
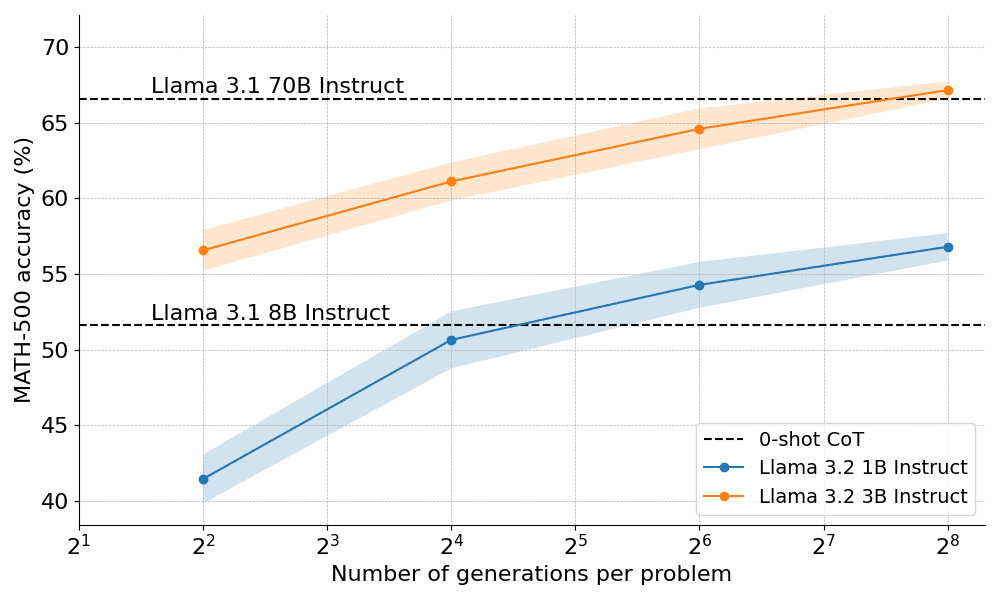
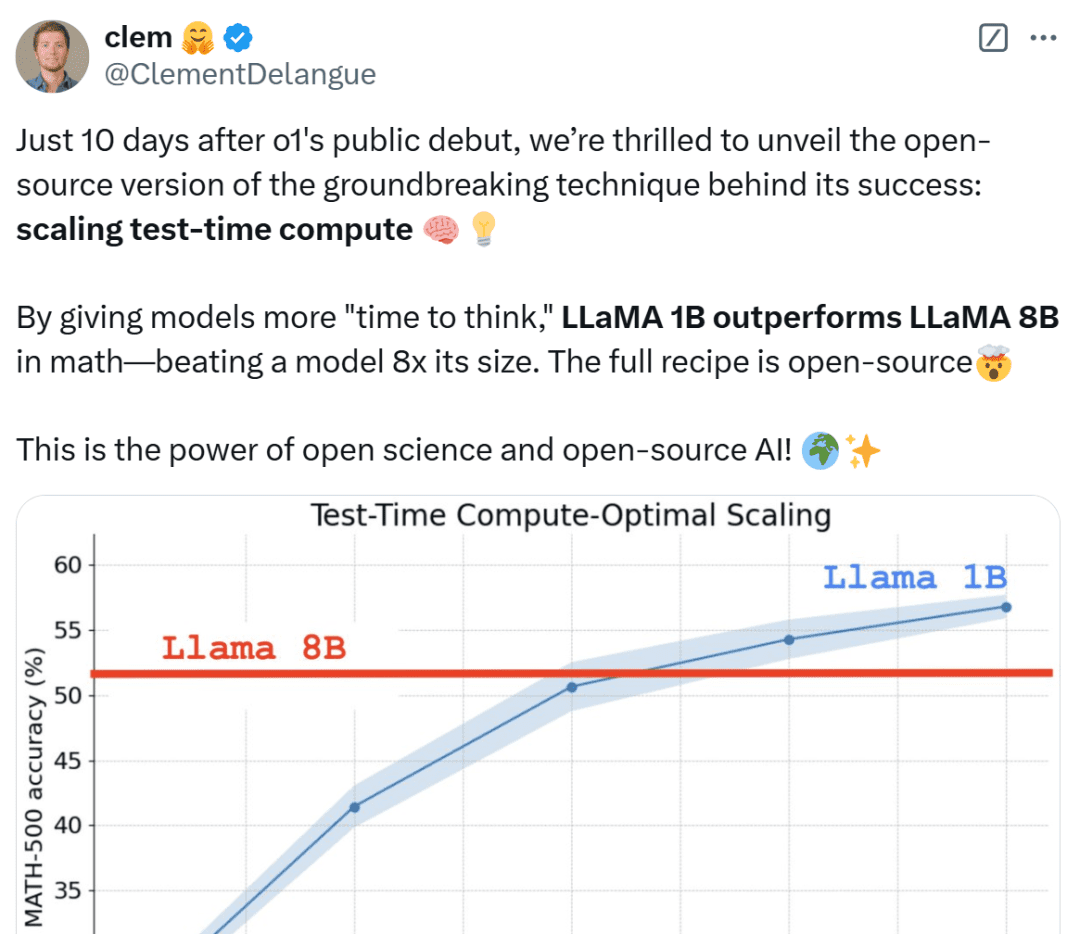
OpenAI o1の公開からわずか10日後、その成功の背景にある画期的な技術、拡張テストタイム・コンピューティングのオープンソース版を発表できることをうれしく思います。モデルに長い "思考時間 "を与えることで、1Bモデルは8Bを、3Bモデルは70Bを打ち負かすことができる。
この結果を見た各界のネットユーザーは、信じられない、ミニチュアの勝利だと冷静さを欠いている。

次に、HuggingFaceはこれらの結果の背後にある理由を掘り下げ、読者がテスト中に計算スケーリングを実装するための実践的な戦略を理解するのを助ける。
拡張テスト時間計算戦略
テスト時間の計算を拡張するには、主に2つの戦略がある:
- 自己改善:モデルは、後続の反復でエラーを特定し修正することで、出力または「アイデア」を反復的に改善する。このストラテジーは、タスクによっては効果的ですが、通常、モデルに自己改善メカニズムが組み込まれている必要があるため、適用が制限される場合があります。
- バリデータに対する検索:このアプローチは、複数の回答候補を生成し、バリデータを使用して最良の回答を選択することに重点を置く。バリデータは、ハードコードされたヒューリスティックに基づくものと、学習された報酬モデルに基づくものがある。本稿では、Best-of-Nサンプリングやツリーサーチなどの技術を含む、学習されたバリデータに注目する。このような探索戦略はより柔軟であり、問題の難易度に適応させることができるが、その性能はバリデータの質によって制限される。
HuggingFaceは、テスト時の計算最適化のための実用的でスケーラブルなソリューションである検索ベースの手法を専門としています。ここでは3つの戦略をご紹介します:
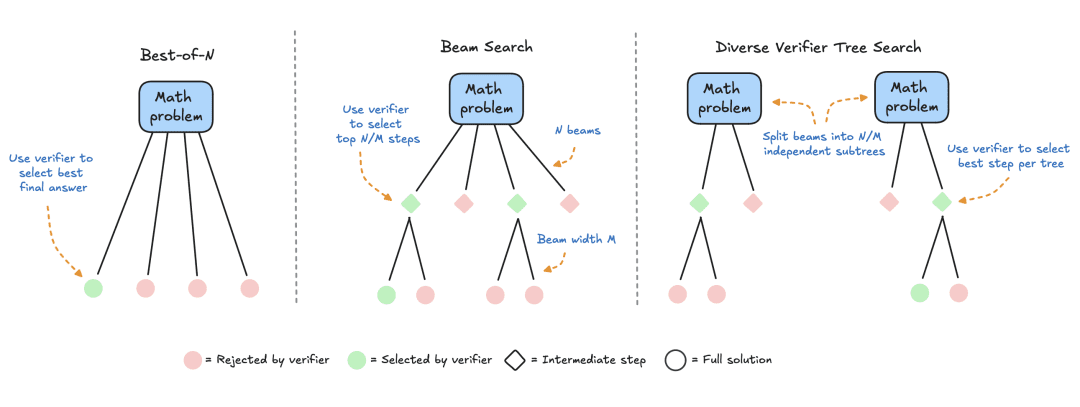
- Best-of-N:通常、報酬モデルを使用して、各質問に対して複数の回答を生成し、各回答候補にスコアを割り当てます。このアプローチは頻度よりも回答の質を重視します。
- クラスター探索:解空間を探索するための体系的な探索手法で、問題解決における中間ステップのサンプリングと評価を最適化するために、プロセス報酬モデル(PRM)と組み合わせて使用されることが多い。最終的な解答に対して単一のスコアを生成する従来の報酬モデルとは異なり、PRMは推論プロセスの各ステップに対して1つずつ、一連のスコアを提供する。このきめ細かなフィードバック機能により、PRMはLLM探索手法の自然な選択肢となる。
- Diversity Validator Tree Search (DVTS): HuggingFaceによって開発されたクラスタ探索の拡張で、初期クラスタを別々のサブツリーに分割し、PRMを使用してこれらのサブツリーを貪欲に拡張する。このアプローチは、特にテスト時の計算予算が大きい場合に、解の多様性と全体的な性能を向上させる。
実験セットアップ
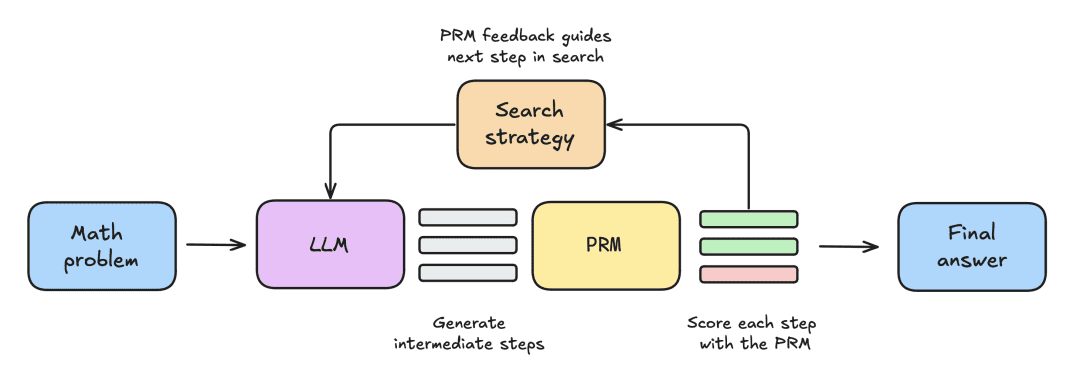
実験のセットアップは以下の手順で行われた:
- LLMはまず、N個の部分解を生成する数学的問題を与えられる。
- 各ステップはPRMによって採点され、PRMは各ステップが正解に行き着く確率を推定する。
- 探索戦略が完了すると、最終的な解答候補がPRMによってソートされ、最終的な解答が生成される。
様々な検索戦略を比較するために、本稿では以下のオープンソースモデルとデータセットを使用した:
- モデル:拡張テスト時間計算の主要モデルとしてmeta-llama/Llama-3.2-1B-Instructを使用する;
- プロセス報酬モデルPRM:検索戦略を導くために、本稿ではプロセス監視付き学習済み80億報酬モデルであるRLHFlow/Llama3.1-8B-PRM-Deepseek-Dataを使用する。プロセス監視とは、最終結果だけでなく、推論プロセスの各ステップでモデルがフィードバックを受ける訓練方法である;
- データセット:本論文は、プロセス教師付き研究の一環としてOpenAIによって公開されたMATHベンチマークデータセットであるMATH-500サブセットで評価された。これらの数学問題は7つの主題をカバーし、人間と大規模言語のほとんどのモデルの両方にとって挑戦的である。
この記事では、シンプルなベースラインから始め、徐々に他のテクニックを取り入れてパフォーマンスを向上させていく。
多数決
多数決は、LLMの出力を集計する最も簡単な方法である。与えられた数学的問題に対して、N個の解答候補が生成され、出現頻度が最も高い解答が選択される。全ての実験において、本論文は温度パラメータT=0.8で最大N=256の候補解をサンプリングし、各問題に対して最大2048のトークンを生成する。
ラマ3.2 1Bのインストラクターに適用された場合の多数決の結果は以下の通り:
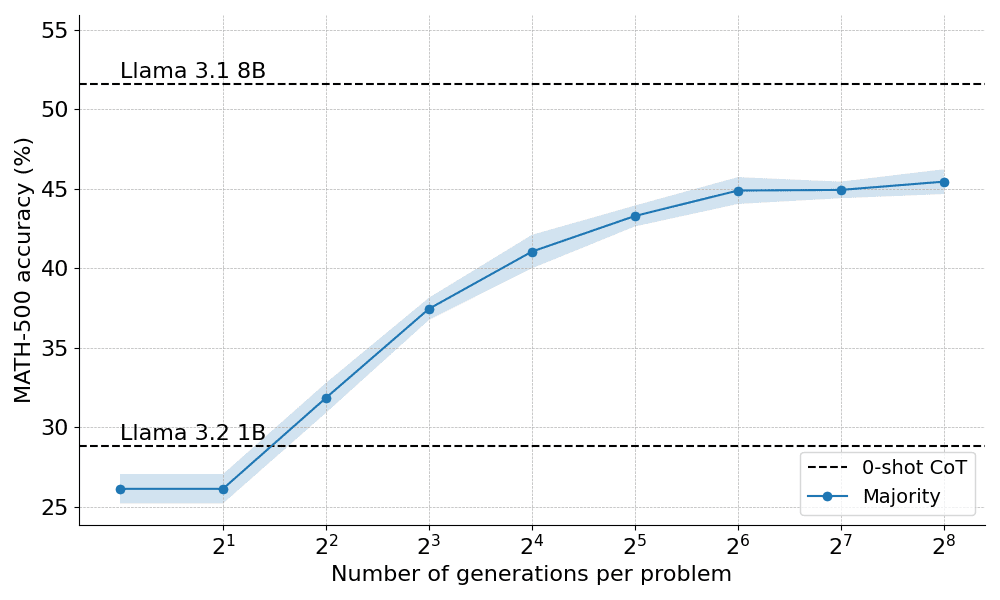
その結果、多数決は貪欲な復号化ベースラインに対して有意な改善をもたらすが、その利益はN=64世代程度で横ばいになり始めることが示された。この限界は、多数決が慎重な推論を必要とする問題を解くのが難しいために生じる。
多数決の限界に基づき、パフォーマンスを向上させるために報酬モデルをどのように組み込めるか見てみよう。
ビヨンド・マジョリティー:ベスト・オブ・N
Best-of-Nは、最も妥当な答えを決定するために報酬モデルを使用する、多数決アルゴリズムのシンプルで効率的な拡張である。この方法には2つの主なバリエーションがある:
通常のBest-of-N: N個の独立した回答を生成し、RM報酬が最も高いものを最終的な回答として選択する。これは最も信頼度の高い回答が選ばれることを保証するが、回答間の一貫性は考慮しない。
Weighted Best-of-N:すべての同一の回答のスコアを合計し、総報酬が最も高いものを選択します。この方法では、繰り返し出現することでスコアを増加させ、質の高い回答を優先します。数学的には、回答は a_i で重み付けされます:
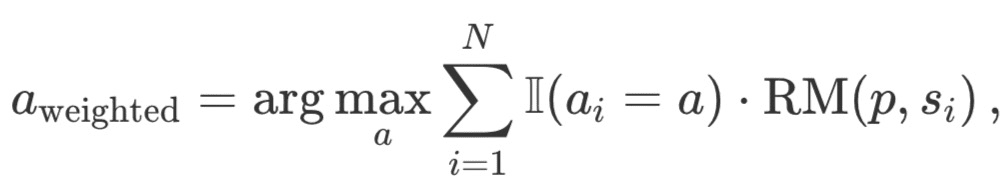
ここでRM (p,s_i) は問題pに対する解s_iに対する報酬モデルのスコアである。
通常、個々の解レベルのスコアを得るために、Outcome Reward Model (ORM)を用いる。しかし、他の探索戦略と公平に比較するために、同じPRMをBest-of-N解のスコア付けに使用する。下図に示すように、PRMは各解のステップレベル得点の累積列を生成するので、個々の解レベル得点を得るためには、ステップを統計的に(還元的に)得点化する必要がある:
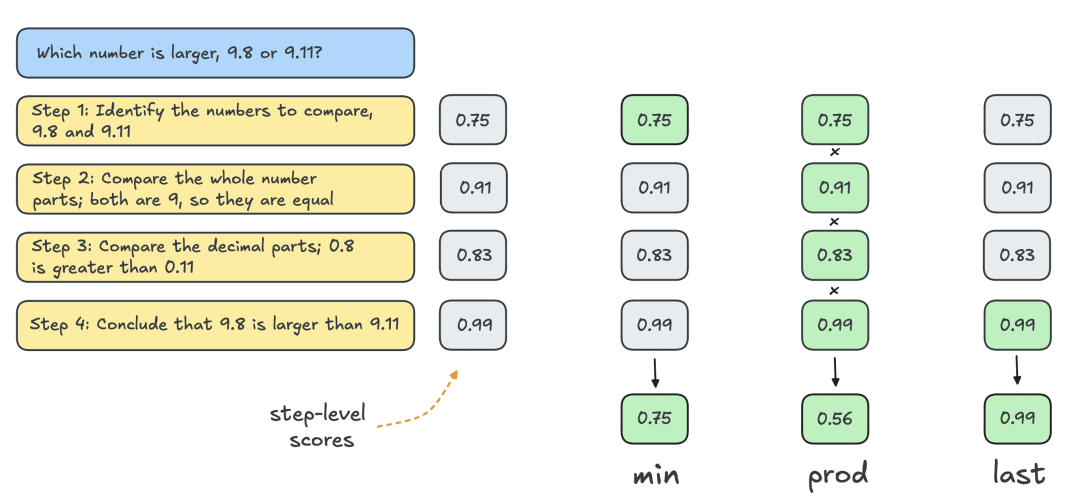
最も一般的な法令を以下に挙げる:
- 最小:すべてのステップの中で最も低いスコアを使用する。
- Prod:ステップ分数の積を使う。
- 最後:そのステップの最終スコアを使用する。このスコアはそれまでのすべてのステップからの累積情報を含むので、PRM を部分解をスコアリングできる ORM として効果的に扱うことができる。
以下は、Best-of-Nの2つのバリエーションを適用した結果である:
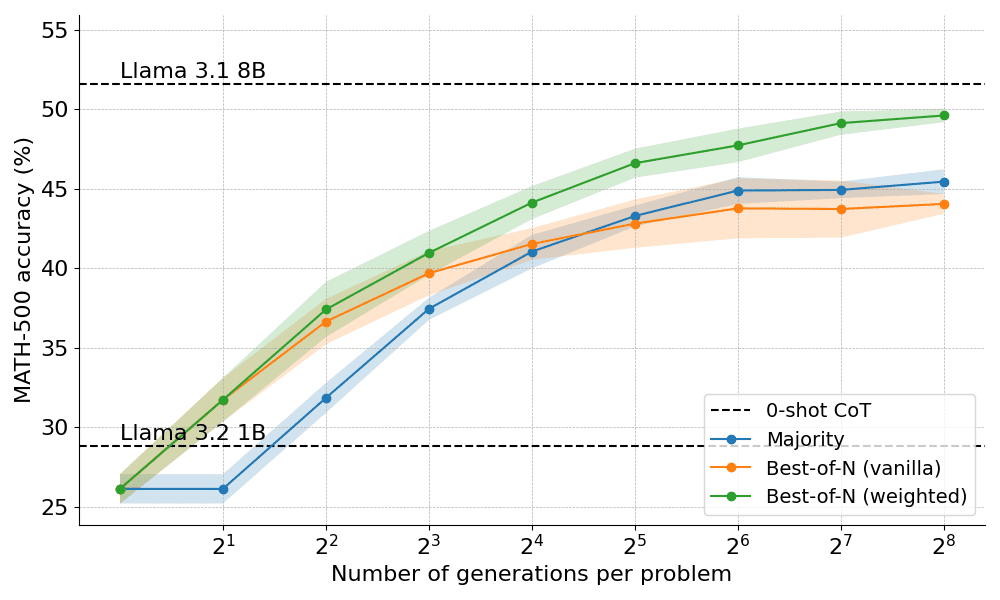
その結果、重み付きBest-of-Nは、特に世代予算が大きい場合、常に通常のBest-of-Nを上回るという明確な利点が明らかになりました。加重Best-of-Nは、同一の解答のスコアを集約することができるため、解答の頻度が低くても、質の高い解答を効果的に優先順位付けすることができます。
しかし、これらの改善にもかかわらず、Llama 8Bモデルが達成したパフォーマンスにはまだ及ばず、Best-of-N法はN=256で安定し始める。
検索プロセスを徐々に監視することで、境界線をさらに押し広げることは可能か?
PRMによるクラスタ探索
構造化された探索手法であるクラスター探索は、解空間の系統的な探索を可能にし、テスト時のモデル出力を改善する強力なツールとなる。PRMと併用することで、クラスター探索は問題解決の中間ステップの生成と評価を最適化することができる。クラスター探索は次のように機能する:
- 複数の解の候補は、一定の「クラスタ」またはアクティブなパスの数 N を保つことによって、繰り返し生成される。
- 最初の反復では、応答に多様性を導入するために、温度TのLLMからN個の独立したステップが取られる。これらのステップは通常、新しい行nや2倍の行nnで終了するなどの停止基準によって定義される。
- 各ステップはPRMを用いてスコアリングされ、上位N/M個のステップが次の生成ラウンドの候補として選択される。ここでMは与えられた活動パスの「クラスタ幅」を示す。Best-of-Nと同様に、「最後の」制定法は各反復の部分解をスコアリングするために使用される。
- ステップ(3)で選択されたステップを、溶液中の後続のM個のステップをサンプリングすることによって拡張する。
- EOSが達成されるまで、ステップ(3)と(4)を繰り返す。 トークン または最大サーチ深度を超える。
PRMに中間ステップの正しさを評価させることで、クラスタ探索はプロセスの早い段階で有望な経路を特定し、優先順位をつけることができる。この段階的な評価戦略は、部分的な解を検証することで最終的な結果を大幅に改善できるため、数学のような複雑な推論タスクに特に有効である。
実施内容
実験では、HuggingFaceはDeepMindのハイパーパラメータ選択に従い、以下のようにクラスタ探索を実行した:
- 4,16,64,256にスケーリングした場合のNクラスタの計算
- 固定クラスター幅 M=4
- 温度T=0.8でのサンプリング
- 最大40回の反復、つまり最大40ステップの深さのツリー
下図に示すように、その結果は驚くべきものである。N=4のテスト時間バジェットで、クラスタ探索はN=16のBest-of-Nと同じ精度を達成し、すなわち計算効率が4倍向上している!さらに、クラスタ探索の性能はLlama 3.1 8Bの性能に匹敵し、問題あたりN=32の解しか必要としない。コンピュータ・サイエンスの博士課程の学生の数学の平均性能は約40%なので、1Bモデルでは55%近くあれば十分である!
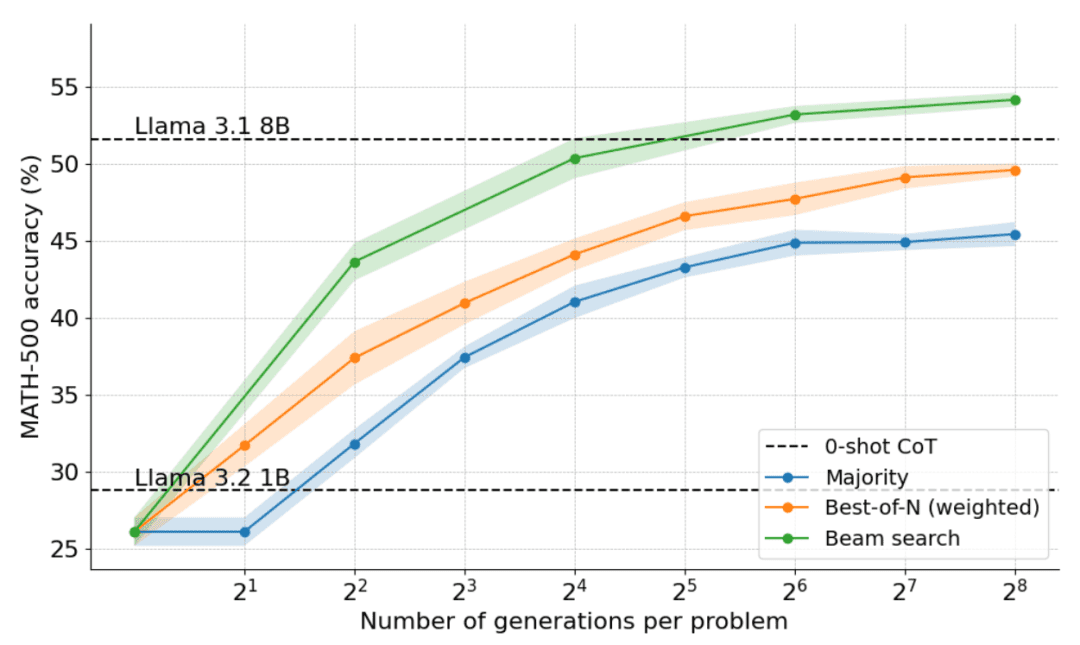
クラスタ探索によって最もよく解決される問題は何か
クラスタ探索がBest-of-Nや多数決よりも優れた探索戦略であることは全体的に明らかだが、DeepMindの論文は、問題の難易度やテスト時の計算予算に応じて、各戦略にトレードオフがあることを示している。
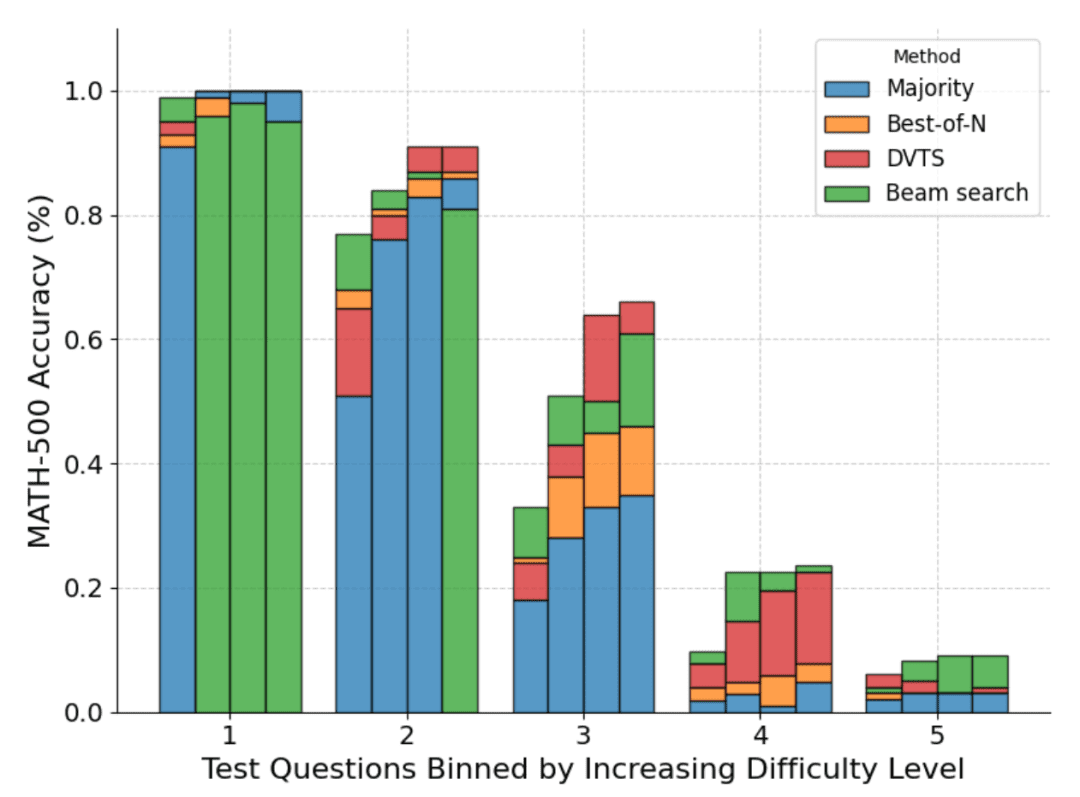
どの問題がどの戦略に最も適しているかを理解するために、DeepMindは推定された問題の難易度の分布を計算し、その結果を五分位に分けた。言い換えると、各問題は 5 つのレベルのいずれかに割り当てられ、レベル 1 は簡単な問題、レベル 5 は最も難しい問題を示す。問題の難易度を推定するために、DeepMind は標準的なサンプリングで各問題について 2048 個の解答候補を生成した後、以下のヒューリスティックを提案した:
- オラクル: 基本的なファクト・ラベルを使用して各問題の合格@1スコアを推定し、合格@1スコアの分布を分類して五分位を決定する。
- モデル化:各問題の平均PRM得点の分布を使って五分位を決定する。ここでの直感は、より難しい問題はより低い得点になるということです。
下図は、パス@1スコアと、4つのテストにわたって計算された予算N=[4,16,64,256]に基づく様々な方法の内訳を示している:
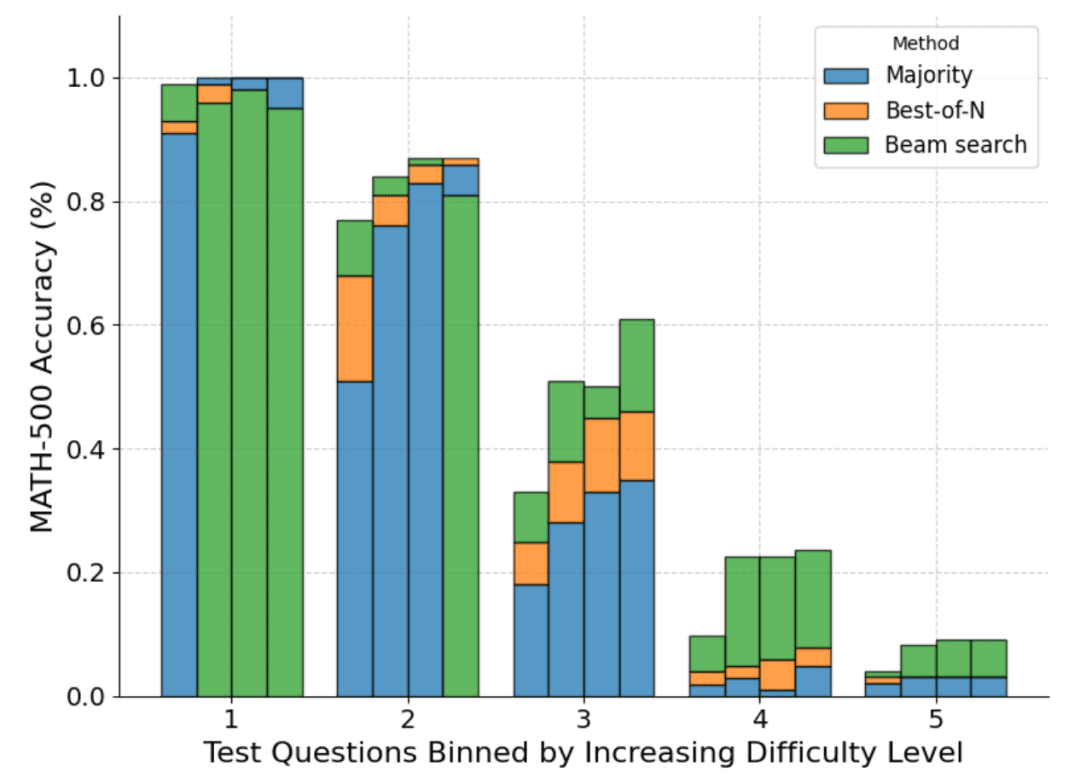
ご覧のように、各バーはテスト時に算出された予算を表し、各バー内に各手法の相対的な精度が示されている。例えば、難易度2の4つのバーでは、以下のようになる:
多数決は、N=256(クラスター探索が最も悪い)を除いて、すべての計算予算で最もパフォーマンスの悪い方法である。
N=[4,16,64]ではクラスター探索が最適であるが、N=256ではBest-of-Nが最適である。
クラスター探索は、中難度や難易度の高い問題(レベル3〜5)では一貫した進歩を遂げているが、より単純な問題、特に計算予算が大きい問題では、Best-of-N(あるいは多数決)よりも成績が悪くなる傾向があることに注意すべきである。
クラスタ探索によって生成された結果ツリーを見ることで、HuggingFaceは、1つのステップに高い報酬が割り当てられた場合、ツリー全体がその軌跡上で崩壊し、多様性に影響を与えることに気づいた。このことが、多様性を最大化するクラスター探索の拡張を探求する動機となった。
DVTS:多様性によるパフォーマンスの向上
上で見たように、クラスタ探索はBest-of-Nよりも優れた性能を発揮するが、単純な問題やテスト時の計算予算が大きい問題を扱う場合には性能が劣る傾向がある。
この問題に対処するため、HuggingFaceは、Nが大きい場合に多様性を最大化することを目的とした「多様性検証ツリーサーチ」(DVTS)と呼ばれる拡張機能を開発した。
DVTSはクラスターサーチと似たような働きをするが、次のような改良が加えられている:
- 与えられたNとMに対して、初期集合はN/M個の独立した部分木に展開される。
- 各サブツリーについて、PRMスコアが最も高いステップを選択する。
- ステップ(2)で選択したノードから新しいステップをM個生成し、PRMスコアが最も高いステップを選択する。
- EOSトークンまたは最大ツリー深度に達するまで、ステップ(3)を繰り返します。
以下のグラフは、ラマ1BにDVTSを適用した結果である:
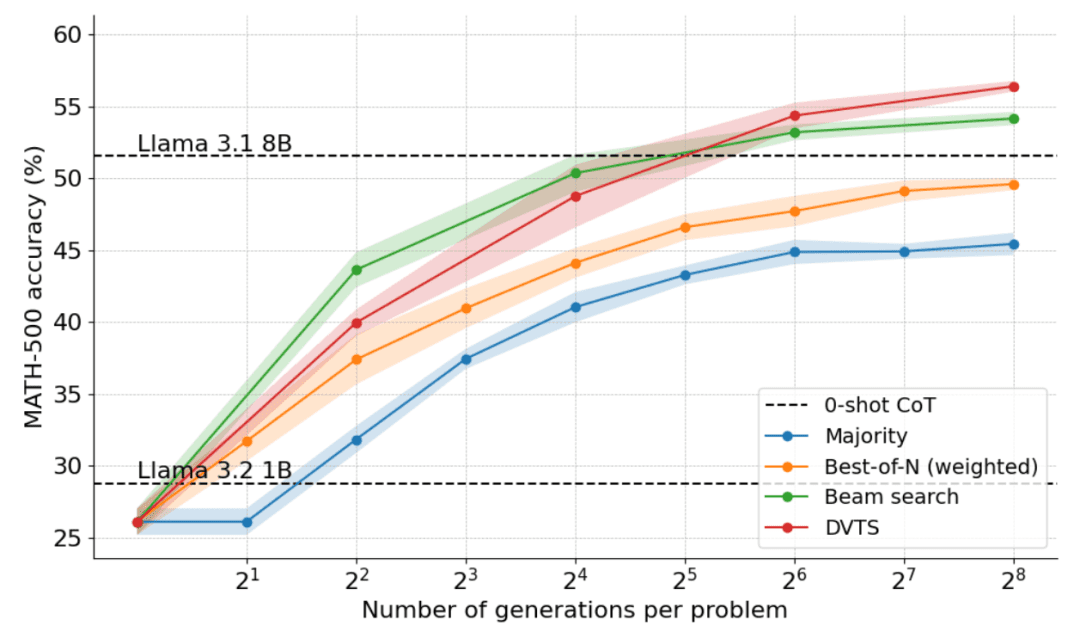
DVTSは、クラスタ探索を補完する戦略を提供することがわかる。Nが小さい場合は、クラスタ探索の方が正しい解を見つけるのに効果的だが、Nが大きくなると、DVTS候補の多様性が発揮され、より良いパフォーマンスを達成することができる。
また、問題の難易度の内訳では、DVTSはNが大きいほど単純/中程度の問題の性能を向上させるが、クラスタ探索はNが小さいときに最も良い性能を発揮する。
計算最適スケーリング(計算最適スケーリング)
様々な探索戦略がある中で、どれが最適なのかというのは当然の疑問である。DeepMindの論文(Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters )では、与えられた計算予算Nに対して最適な性能を達成するために、探索手法とハイパーパラメータθを選択する計算上最適なスケーリング戦略を提案している。パラメータθを選択する、計算上最適なスケーリング戦略を提案している:
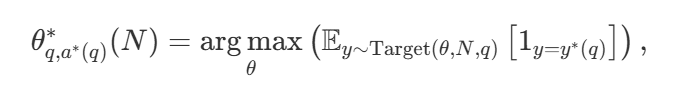
この中には 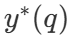 は質問qの正解である。
は質問qの正解である。 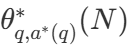 表現コンピューティング - 最適なスケーリング戦略。を計算するのは簡単である。
表現コンピューティング - 最適なスケーリング戦略。を計算するのは簡単である。 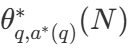 ややトリッキーだが、ディープマインドは問題の難易度に基づく近似を提案している。つまり、与えられた難易度でどの探索戦略が最高のパフォーマンスを達成するかに基づいて、テスト中の計算リソースを割り当てるのだ。
ややトリッキーだが、ディープマインドは問題の難易度に基づく近似を提案している。つまり、与えられた難易度でどの探索戦略が最高のパフォーマンスを達成するかに基づいて、テスト中の計算リソースを割り当てるのだ。
例えば、より単純な問題で計算予算が少ない場合は、Best-of-Nのような戦略を使うのが良く、より難しい問題ではセット・シュウ・サーチを使うのが良い選択である。下図は計算最適化曲線を示している!
大型モデルへの拡張
この論文では、計算最適化アプローチをLlama 3.2 3B Instructモデルに拡張し、ポリシー自体の容量と比較してPRMがどの時点で弱くなり始めるかを調べる。その結果、3BモデルはLlama 3.1 70Bインストラクト(これは前者の22倍のサイズである!)を凌駕し、計算最適化拡張が非常にうまく機能することが示された。.

次はどうする?
テスト時間計算スケーリングの探求は、探索ベースのアプローチを利用することの可能性と課題を明らかにする。本論文は、将来に向けて、いくつかのエキサイティングな方向性を示唆している:
- 強力なバリデーター:強力なバリデーターはパフォーマンスを向上させる上で重要な役割を果たし、バリデーターの堅牢性と汎用性を向上させることは、これらのアプローチを進歩させる上で極めて重要である;
- 自己検証:究極の目標は自己検証を達成すること、つまりモデルが自律的に自身の出力を検証できるようになることである。このアプローチは、o1のようなモデルが行っているように見えるが、実際にはまだ難しい。標準的な教師ありファインチューニング(SFT)とは異なり、自己検証はより微妙な戦略を必要とする;
- (a)プロセスへの思考の統合:生成プロセスに明示的な中間ステップや思考を組み込むことで、推論や意思決定をさらに強化することができる。構造化された推論を探索プロセスに組み込むことで、複雑なタスクにおいてより良いパフォーマンスを達成することができる;
- データ生成ツールとしてのサーチ:この手法は、高品質のトレーニングデータセットを作成するための強力なデータ生成プロセスとしても機能する。例えば、Llama 1Bのようなモデルを、サーチによって生成された正しい軌道に基づいて微調整することで、大きな利点を得ることができる。このストラテジーベースのアプローチは、ReSTやV-StaRのような手法に似ているが、サーチという利点が追加されており、反復的な改善のための有望な方向性を提供する;
- より多くのPRMを呼ぶ:PRMの数は比較的少なく、その応用範囲は限られている。さまざまな領域でより多くのPRMを開発し共有することは、コミュニティが大きく貢献できる重要な分野である。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません