2025 AIエージェント上陸の展望:プランニング、インタラクション、メモリーの3要素の分析


AIエージェントは、急速に進化するAI技術分野において、待望のパラダイムシフトとなりつつあります。 AI技術レビューの主要組織であるAI Shareは、最近、AIエージェントのトレンドを深く掘り下げ、読者がエージェントの未来をよりよく理解できるように、Langchainチームが発表した一連の詳細な記事を参照しました。
この記事は、Langchainが発表した「AIエージェントの現状」レポートの主要な調査結果を統合したものです。このレポートでは、開発者、プロダクトマネージャー、企業幹部、その他の役割を担う業界関係者1,300人以上を対象に調査を行いました。調査結果は、AIエージェント開発の現状と2024年におけるボトルネックを明らかにしています。90%の企業がAIエージェントを積極的に計画・適用していますが、ユーザーは現在の能力の限界から、特定のプロセスやアプリケーションシナリオにしかエージェントを導入できません。 人々は、コストやレイテンシといった要素よりも、エージェントの能力とその行動の観測可能性と信頼性を向上させることに関心を寄せています。エージェントの動作の観測可能性と制御可能性は、コストや待ち時間よりも重要である。
さらにこの記事では、LangChainの公式ウェブサイトに掲載されている「In the Loop」シリーズから、AIエージェントの主要な要素について、以下の点を中心に詳しく分析します。 プランニング、UI/UXインタラクティブ・イノベーション、メモリー。 これら3つの中核的要素である。 本稿では、ラージ・ランゲージ・モデル(LLM)に基づき、5つのネイティブ・プロダクトのインタラクション・パターンを深く分析し、人間の3つの複雑な記憶メカニズムを類推することで、AIエージェントの本質と重要な要素を理解するための有益な洞察を読者に提供することを目的としている。 また、本稿では、より実務に近づけるため、以下のセクションで重要な要素の分析も行っている。 リフレクション AI創業者へのインタビューやその他の実例から、2025年にAIエージェントに訪れるかもしれない重要なブレークスルーを展望する。
上記の分析フレームワークに基づいて、AIシェアは、AIエージェントのアプリケーションは2025年に爆発的な成長を遂げ、人間とコンピュータのコラボレーションの新しいパラダイムに徐々に移行していくと考えている。 AI Agentのプランニング能力に関しては、o3モデルに代表される新興モデルは強い反射能力と推論能力を示しており、モデル技術の開発がReasonerからAgentの段階へと急速に進化していることを示している。 推論能力の継続的な向上により、AIエージェントが本当に大規模な着陸を達成できるかどうかは、製品の相互作用と記憶メカニズムの革新にかかっており、新興企業が差別化とブレークスルーを達成する重要な機会にもなる。 インタラクションのレベルでは、業界はAI時代の「GUIの瞬間」のような人間とコンピュータのインタラクション革命を待ち望んでいる。記憶のレベルでは、個人レベルのコンテキスト・パーソナライゼーションであれ、企業レベルのコンテキスト統一であれ、コンテキストがAgent上陸の核心キーワードになるだろう。コンテキスト(文脈)は、個人レベルでのパーソナライゼーションであれ、企業レベルでの統一であれ、エージェント・ランディングの核となるキーワードになるだろう。
01 AIエージェントの現状:AIエージェント開発の現状
エージェントの導入動向:どの企業も積極的にエージェント導入を計画している
Agentスペースの競争は日に日に熱くなっています。 この1年で、多くの人気Agentフレームワークが出現しました。 例えば リ・アクト 推論とアクションのためのLLM、マルチエージェント・フレームワークを使ったタスク・オーケストレーション、そして以下のような手法を組み合わせたフレームワークである。 ラングラフ これはより扱いやすい枠組みだ。
Agentの話題はソーシャルメディア上の話題にとどまりません。 調査によると、調査対象組織のうち約51%がすでに本番環境でAgentを使用しています。 Langchainの調査では、企業規模別にもデータを分類しており、従業員数100~2,000人の中堅企業がAgentの本番導入に最も積極的で、その数はなんと63%にのぼります。
さらに、回答者のうち78%が、近い将来に本番環境にAgentを導入する予定であると回答している。 このことは、業界を問わずAIエージェントに強い関心が寄せられていることを明確に示していますが、真にAIエージェントを構築するにはどうすればよいのでしょうか? プロダクション・レディ(本番環境で使用可能) エージェントは、多くの企業にとって依然として課題である。
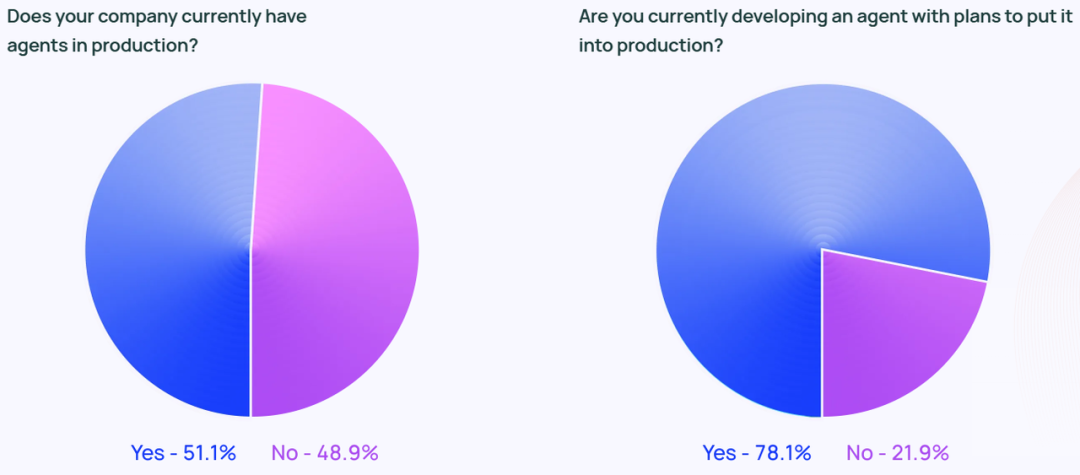
テクノロジー業界は、Agent テクノロジーの先駆者と考えられがちですが、Agent への関心は、すべての業界で急速に高まっています。 非テクノロジー企業で働く回答者のうち、90%の組織が生産環境にAgentを導入しているか、導入する予定であり、これはテクノロジー企業(89%)とほぼ同じ割合である。
エージェントの使用例
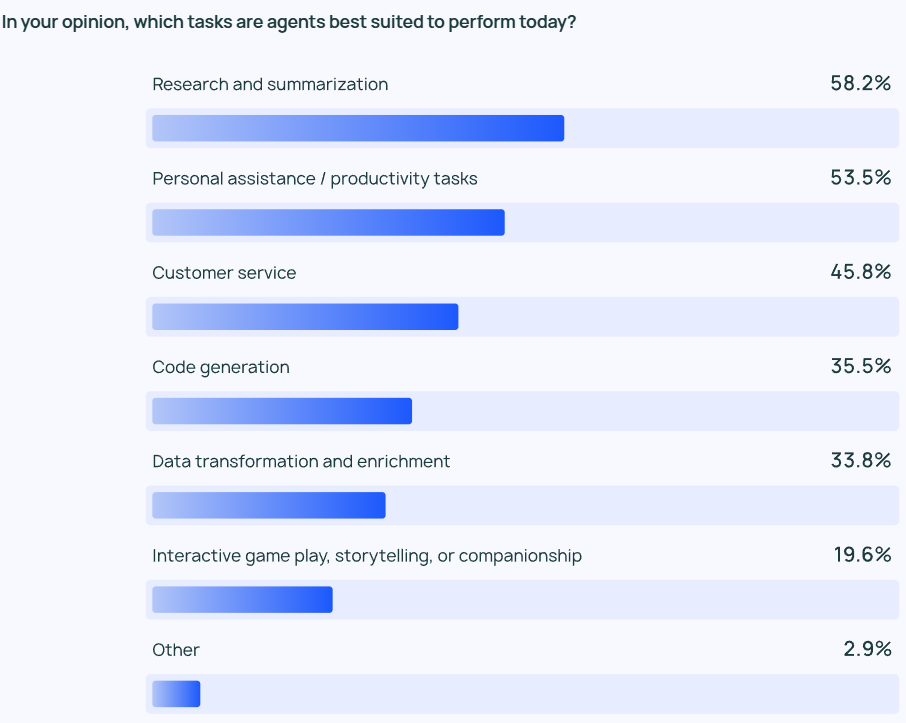
調査の結果、最も一般的なエージェントは以下の通りであった。 ユースケース 情報調査やコンテンツの要約(58%)、そしてカスタマイズされたエージェントによるワークフローの合理化(53.5%)である。
これは、ユーザーがエージェント製品に、時間と労力のかかる作業を手助けしてくれることを期待しているという事実を反映している。 ユーザーは、大量のデータをふるいにかけてデータレビューや調査分析を自分で行うのではなく、大量の情報から重要な情報や洞察を素早く抽出するAIエージェントに頼ることができる。 同様に、AIエージェントは日常業務を支援することで、個人の生産性を向上させ、ユーザーはより重要な業務に集中することができます。
効率化を必要としているのは個人ユーザーだけでなく、組織やチームも同様です。 カスタマーサービス(45.8%)もAgentの主要なアプリケーション分野です。 エージェントは、組織が顧客からの問い合わせを処理し、問題を解決し、チーム全体の顧客対応時間を短縮するのに役立ちます。 4番目と5番目に人気のあるアプリケーションシナリオは、より低レベルのコードとデータ処理です。
モニタリング: エージェントアプリケーションは、観察および制御可能である必要があります。
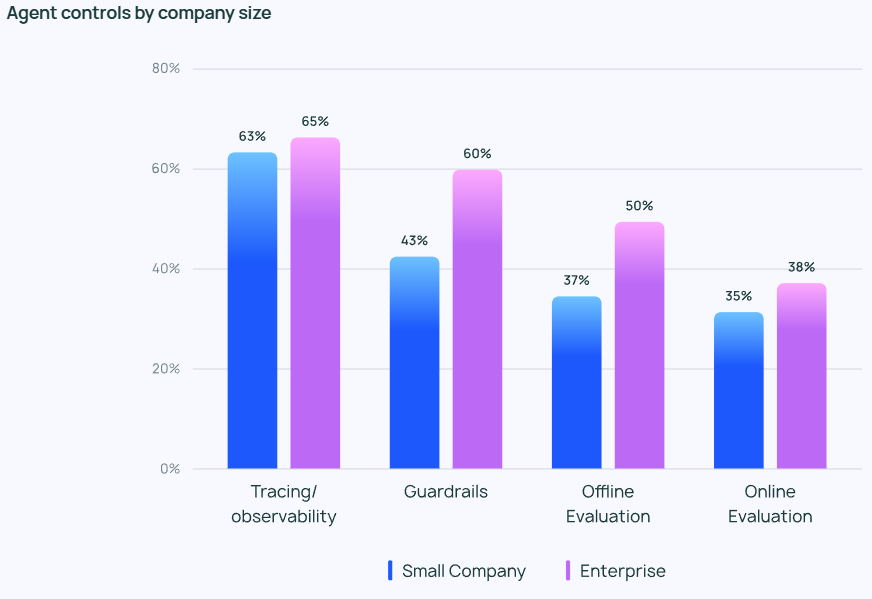
Agentがより強力になるにつれ、その挙動を効果的に管理・監視することが重要になります。 追跡・監視ツールは、企業ユーザのAgentテクノロジースタックに必須のオプションとなりつつあり、開発者がAgentの動作とパフォーマンスを把握するのに役立っています。 また、多くの企業が ガードレール エージェントの行動が事前に定義された軌道から逸脱するのを防ぐためです。
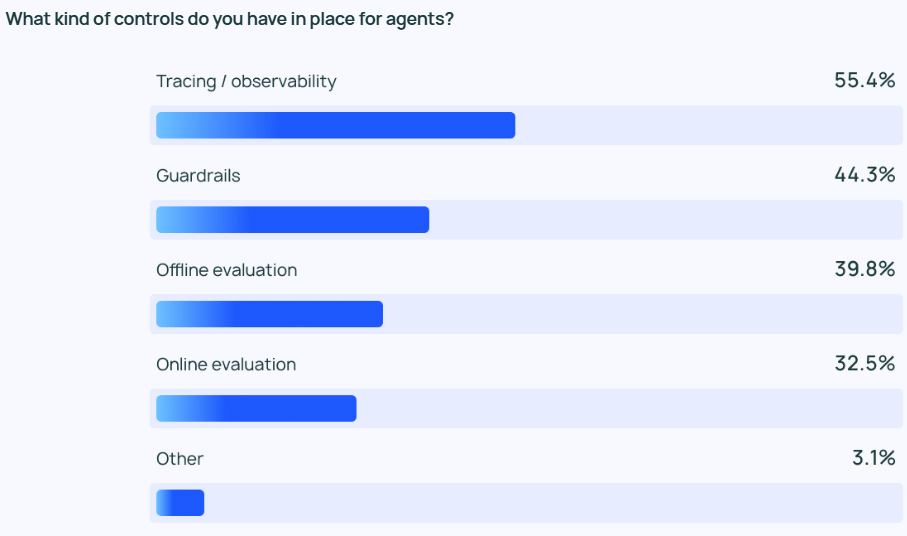
LLMアプリケーションをテストする場合オフライン評価 (39.8%)の方が使用頻度が高かった。 オンライン評価 (32.5%)であり、LLMをリアルタイムで監視する上でまだ多くの課題があることを反映しています。 LangChainのオープンエンドアンケートへの回答では、多くの企業が、セキュリティの追加レイヤーとして、人間の専門家がエージェントの回答結果を手動でチェックまたは評価することも手配すると回答しています。
エージェントに対する熱意とは裏腹に、エージェントの権限管理に関しては一般的に保守的である。 エージェントに読み取り、書き込み、削除を自由に許可している回答者はほとんどいません。 その代わりに、ほとんどのチームはエージェントに「読み取り専用」の権限のみを与えたり、エージェントが書き込みや削除のようなリスクの高い操作を行う際に手動での承認を求めています。
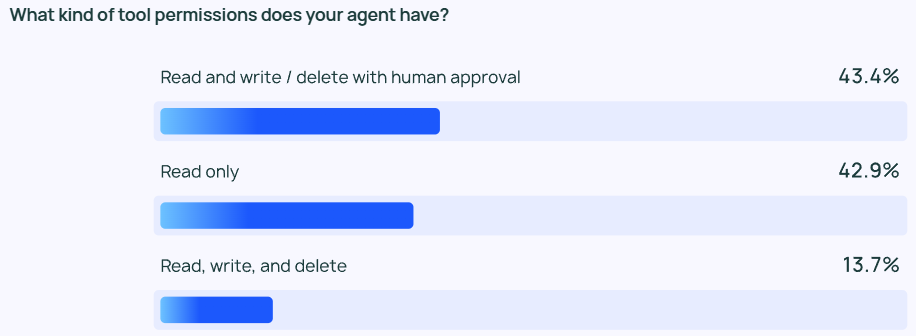
エージェント管理の重点は、企業規模によって異なる。 大規模な組織(従業員数 2,000 人以上)では、不必要なリスクを最小限に抑えるために「読み取り専用」の権限に大きく依存し、より慎重な姿勢をとることが多い。 また ガードレール オフラインの査定と組み合わせることで、クライアントに悪影響を及ぼす可能性のある問題を回避しようとする。
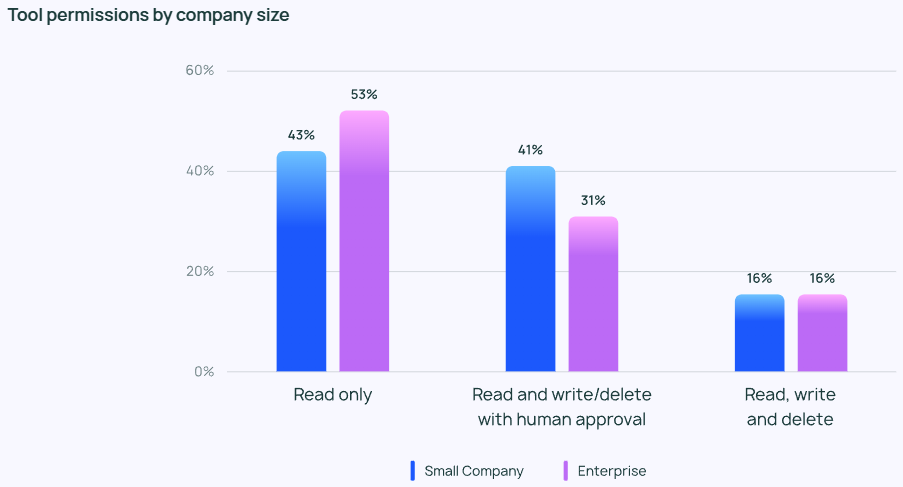
一方、小規模企業や新興企業(従業員数100人未満)は、エージェントアプリケーションの実際のパフォーマンスを把握するためにエージェントを追跡することに関心があります(他の管理よりも)。 LangChainの調査によると、中小企業は結果を理解するためにデータを分析する傾向があるのに対し、大企業は全体的な管理システムの構築に重点を置いています。
エージェントを生産に投入するための障壁と課題
LLMのアウトプットが高品質であることを保証する。 パフォーマンス は依然として困難な課題である。 エージェントの応答は非常に正確である必要があるだけでなく、スタイル的にも正しい必要があります。 これはエージェント開発者にとって大きな関心事であり、コストやセキュリティといった他の要因の2倍以上重要です。
LLMエージェントは、基本的に確率ベースのコンテンツ出力モデルであるため、その出力はある程度予測不可能です。 この予測不可能性によりエラーの可能性が高まり、開発チームはエージェントが一貫して正確で文脈に沿った応答を提供することを保証することが難しくなります。
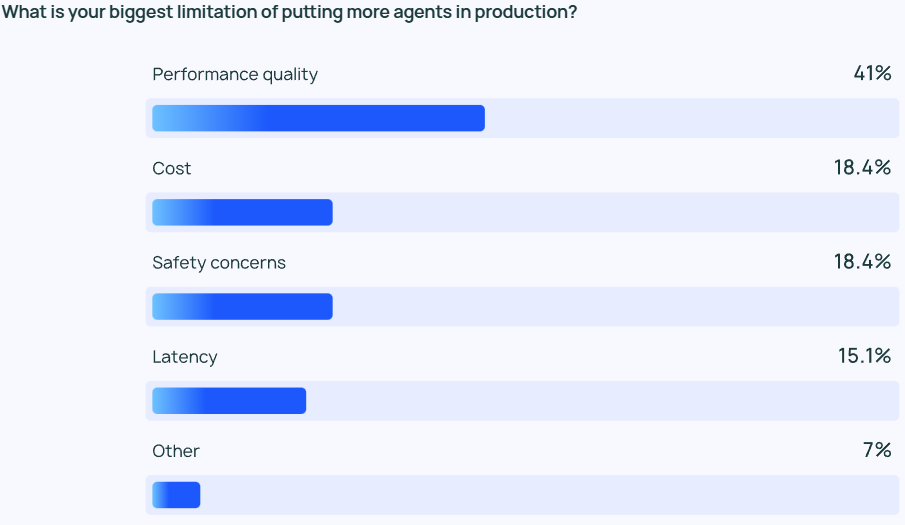
中小企業向けパフォーマンスの質 この重要性は特に強く、中小企業では45.8%がこれを第一の懸念事項としているのに対し、コスト(第二の懸念事項)は22.4%であった。 この格差は、信頼できる高品質のパフォーマンスが、開発段階から生産段階へのエージェントの移行を推進する上で非常に重要であるという事実を浮き彫りにしている。
セキュリティは、厳格なコンプライアンス要件を遵守し、顧客データを慎重に扱う必要がある大企業にとっても重要だ。
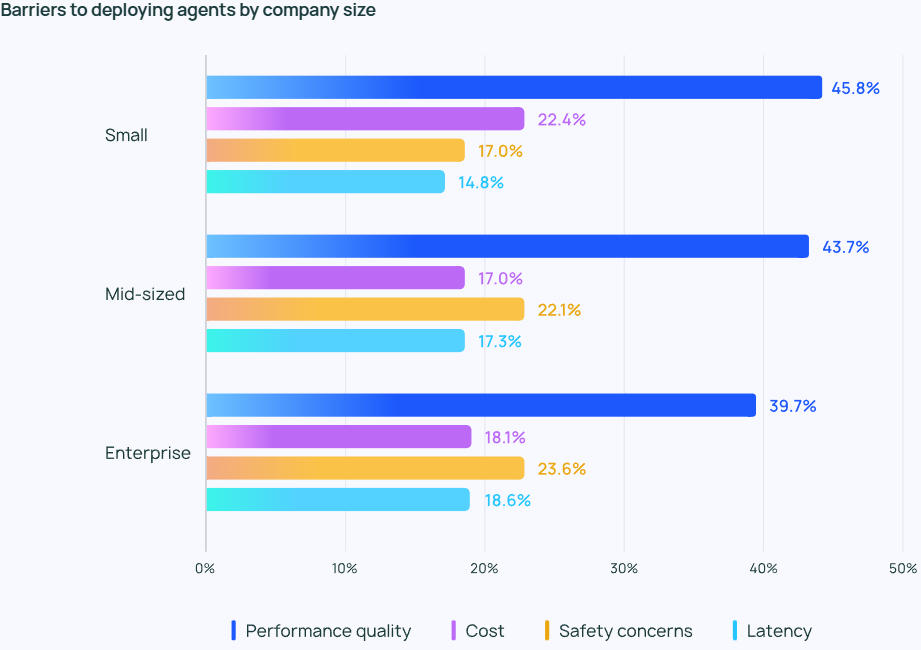
品質の課題に加え、LangChainの自由記述式アンケートへの回答から、多くの組織がエージェントの開発とテストに投資し続けることにまだ不安を抱いていることが明らかになった。 第一に、エージェントの開発には多くの専門知識が必要であり、最先端の技術を常に把握する必要があること、第二に、エージェントの開発と展開にかかる時間的コストは高いが、信頼性の高い運用と期待される利益を提供する能力についてはまだ不確実であることです。
その他の新たなテーマ
自由形式の質問セッションでは、回答者はAIエージェントが以下の能力を発揮していることを高く評価した:
- 複数ステップのタスクを管理する AIエージェントは、より深い推論とコンテキスト管理が可能で、より複雑なタスクを実行できる。
- 反復作業の自動化。 AIエージェントは、自動化されたタスクを処理するための重要なツールであり、ユーザーがより創造的な仕事に集中するための時間を確保するのに役立っている。
- ミッションの計画と協力。 より優れたタスクプランニング機能により、適切なエージェントを適切なタイミングで適切な問題に取り組ませることができ、これはマルチエージェントシステムにおいて特に重要です。
- 人間のような推論。 従来のLLMとは異なり、AIエージェントは、新しい情報に基づいて過去の決定を見直し、修正することを含め、その意思決定プロセスを追跡することができる。
さらに、回答者はAIエージェントの将来について、2つの重要な期待を挙げている:
- オープンソースのAIエージェントに期待すること。 オープンソースのAIエージェントに多くの関心が寄せられ、集合知がエージェント技術の革新ペースを加速させると多くの人が信じている。
- よりパワフルなモデルへの期待。 より大きく、より強力なモデルによってAIエージェントが次の飛躍を遂げ、エージェントがより複雑なタスクをより効率的かつ自律的に処理できるようになることを、多くの人が期待している。
Q&Aセッションでは、多くの回答者がAgent開発における最大の課題であるAgentの動作理解についても言及しました。 エンジニアの中には、Agentの挙動を会社にプレゼンする際に理解するのに苦労したという人もいました。 ステークホルダー AIエージェントの能力や挙動を説明する際に困難が生じる。 視覚化プラグインはエージェントの動作をある程度説明するのに役立ちますが、LLMは多くの場合「ブラックボックス」のままです。 解釈可能性という付加的な負担は、依然としてエンジニアリング・チームにのしかかります。
02 AIエージェントのコア要素の分析
State of AI Agentレポートが発表される前に、Langchainチームはすでに自分たちが開発したLangraphフレームワークに基づいてエージェント領域を調査し、In the Loopブログを通じてAIエージェントの主要コンポーネントの分析に関する記事をいくつか発表していました。 本記事では、In the Loopシリーズの記事の核となる内容をまとめ、Agentの主要要素を深く分析します。
エージェントの核となる要素をよりよく理解するためには、まず、以下のことをよく理解する必要がある。 エージェント・システム 定義 LangChainの創設者であるハリソン・チェイスは、AIエージェントの定義を次のように述べています:
💡
AIエージェントは、LLMを使ってアプリケーションの制御フロー決定を制御するシステムである。
AIエージェントは、LLMを使ってアプリケーションの制御フローを決定するシステムである。
Agentの導入方法について、記事では次のように紹介している。 認知アーキテクチャ コンセプトだ。 認知アーキテクチャ エージェントがどのように考え、システムがどのようにコードやプロンプトを編成するかが、LLMの原動力となります。 認知アーキテクチャを理解することは、エージェントがどのように動作するかを理解するのに役立ちます:
- 認知的だ。 エージェントはLLMを意味推論に使用し、LLMのコーディング方法またはプロンプトを決定する。
- 建築。 エージェント・システムには、従来のシステム・アーキテクチャに類似した工学的慣行が依然として多く含まれている。
下図は、各レベルを示したものである。 認知アーキテクチャ 例
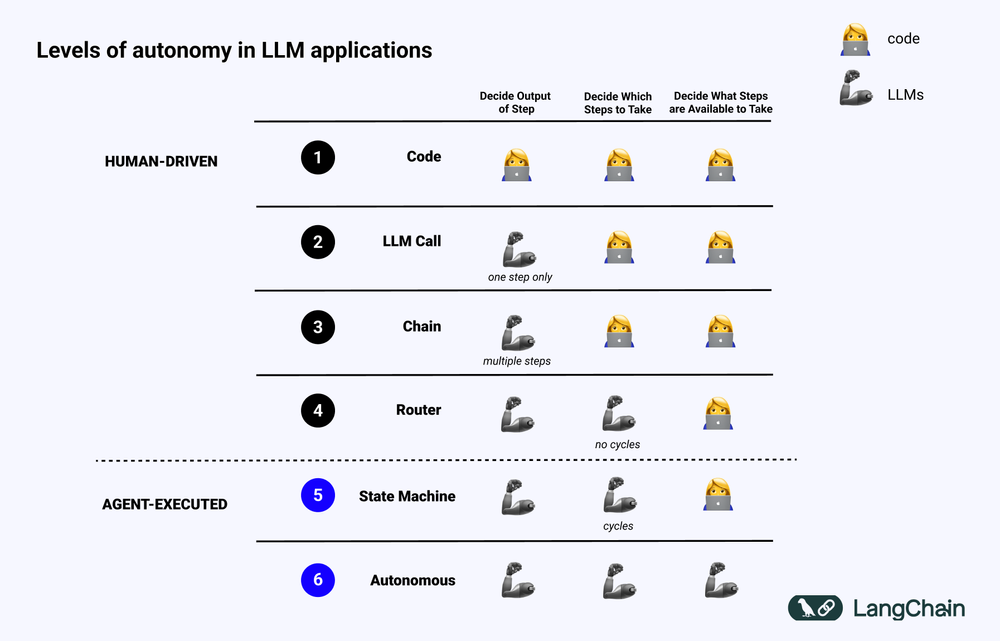
- 標準化されたソフトウェアコード(Code)。 すべてのロジックは ハードコード の実装では、入力と出力のパラメータはソースコードで直接固められる。 このアプローチは、次のような欠点があるため、コグニティブ・アーキテクチャにはならない。 認知 パート
- LLMコール 少量のデータ前処理を除いて、アプリケーションのほとんどの機能は、単一のLLM呼び出しに依存しています。 シンプルなチャットボットは、通常このカテゴリーに入ります。
- チェーン。 チェインが複雑な問題をステップに分解し、異なるLLMを1つずつ呼び出して解決しようとする一連のLLM呼び出し。 複雑な ラグ (例えば、最初のLLMは検索と問い合わせのために呼び出され、2番目のLLMは答えを生成するために呼び出される。
- ルーターだ。 これら3つのシステムすべてにおいて、ユーザーはプログラムが実行するすべてのステップを事前に知っている。 しかし、ルーター・アーキテクチャでは、LLMはどのLLMを呼び出し、どのステップを実行するかを自律的に決定できる。 これにより、システムのランダム性と予測不可能性が高まる。
- ステートマシン。 LLMをルーターと組み合わせることで、システムの予測不可能性はさらに高まる。 この組み合わせはループを作るため、システムは理論上、LLMを無限に呼び出すことができる。
- エージェントシステム。 と呼ばれることもある。 "自律エージェント(Autonomous Agent)" ステートマシンを使用する場合、システムが実行できる操作とそれに続く処理にはまだ制限がある。 ステートマシンを使う場合、システムが実行できる操作や操作実行後のフローにはまだ制限がある。 しかし、自律エージェント(Autonomous Agent)を使用する場合、これらの制限は解除される。 LLMは、どのステップを踏むか、どのように異なるLLMをプログラムするかを決定する完全な自律性を持ち、それは異なるプロンプト、ツール、コードの使用によって達成できる。
要するに、システムほど "エージェント的" LLMがシステムの挙動を決定する役割を果たせば果たすほど、LLMの役割は大きくなる。
エージェントの主な要素:プランニング能力
エージェントの信頼性は、現在のアプリケーションの実践におけるペインポイントです。 多くの企業がLLMに基づいてAgentを構築していますが、Agentの計画と推論能力が不十分であるというフィードバックがあります。 では、Agentの計画と推論能力とは何を意味するのでしょうか?
エージェント プランニング 歌で応える 推論 コンピテンスとは、LLMがどのような行動を取るべきかを考え、決断する能力を指す。 これには、短期的なものと長期的なものの両方が含まれる。 推論 . LLMは、入手可能なすべての情報を評価した上で、次のことを決定する必要がある。 現時点で最も重要な最初のステップは何か?
実際には、開発者は通常 関数呼び出し LLMに実行するアクションを選択させるテクニック。 関数呼び出し は、OpenAIによって2023年6月に初めてLLM APIに追加された機能である。 関数呼び出しでは、ユーザーは異なる関数に対してJSON構造を提供し、LLMはそれらの構造の1つ(または複数)にマッチさせることができる。
複雑なタスクを成功裏に完了させるために、エージェントシステムは通常、一連の操作を逐次的に実行する必要がある。 長期的な計画と推論 LLMにとって非常に複雑な課題です。第一に、LLMは長期的な行動計画を検討し、それを今取るべき短期的な行動に絞り込む必要があります。第二に、エージェントがより多くの操作を実行すると、操作の結果がLLMに継続的にフィードバックされ、その結果、コンテキストウィンドウが継続的に大きくなり、LLMが "注意散漫 "になり、パフォーマンスが低下する可能性があります。「パフォーマンスを低下させることになります。
プランニング能力を向上させる最も簡単な方法は、LLMが理性的に推論し、プランニングするために必要なすべての情報を確保することである。 これは簡単なことのように聞こえるが、現実には、LLMに伝えられる情報は、LLMが適切な判断を下すには不十分であることが多い。 検索ステップを追加したり、プロンプトを最適化したりすれば、簡単に改善できるかもしれません。
さらに一歩進んで、アプリケーションの 認知アーキテクチャ . エージェントの推論能力を向上させるために使用できる認知アーキテクチャには、主に2つのクラスがあります: 一般的な認知アーキテクチャ 歌で応える ドメイン固有の認知アーキテクチャ.
1.一般的な認知アーキテクチャ
一般的な認知アーキテクチャ は、さまざまな異なるタスクシナリオに適用できる。 代表的な2つの汎用アーキテクチャが学者によって提案されている: 「計画と解決」アーキテクチャ 歌で応える リフレクション・アーキテクチャー.
「計画と解決」アーキテクチャ これはPlan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Modelsという論文で初めて発表された。 このアーキテクチャでは、エージェントは最初に詳細な計画を立て、次に計画の各ステップを一歩ずつ実行する。
リフレクション・アーキテクチャー は、論文 Reflexion: Language Agents with Verbal Reinforcement Learning で発表された。 このアーキテクチャでは、エージェントはタスクを実行し、そのタスクに明示的な強化学習を加える。 "反省" ステップで、タスクが正しく実行されているかどうかを評価する。 これら2つのアーキテクチャの具体的な詳細には触れないが、興味のある読者は、前述の2つの原著論文を参照されたい。
Plan and Solve" と Reflexion アーキテクチャは、理論的には改善の可能性を示しているが、Agent の実運用に役立てるには一般的すぎることが多い。(訳者注:この論文の時点では、o1ファミリーのモデルはまだリリースされていなかった)
2.ドメイン固有の認知アーキテクチャ
一般的なコグニティブ・アーキテクチャとは対照的に、多くのエージェント・システムは、次のようなアーキテ クチャを使用することを選択します。 ドメイン固有の認知アーキテクチャ . これは通常、ドメイン固有の分類または計画ステップ、およびドメイン固有の検証ステップに反映される。 一般的な認知アーキテクチャーで提示された計画および反映のアイデアは、ドメイン固有の認知アーキテクチャーで借用および適用することができますが、通常は、よりドメイン固有の方法で適応および最適化する必要があります。
AlphaCodiumによる論文は、ドメイン固有の認知アーキテクチャの典型的な例を示している。 AlphaCodiumチームは、彼らが 「フローエンジニアリング (コグニティブ・アーキテクチャの別の表現方法)で、当時最先端の性能を達成した。
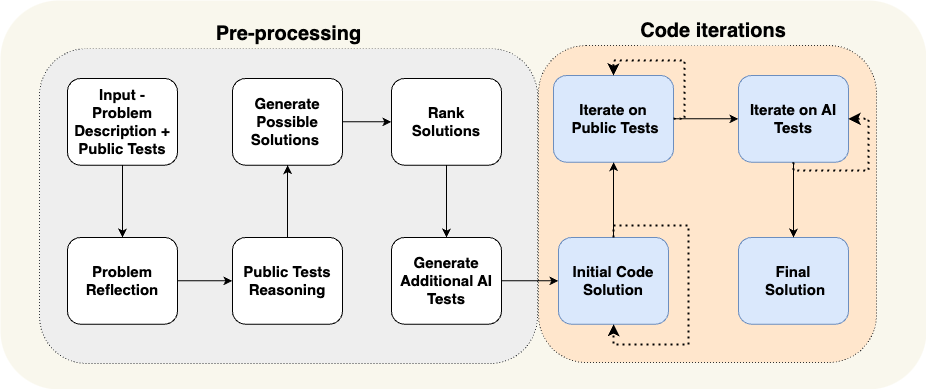
上図に示すように、AlphaCodium Agentのプロセス設計は、それが解決しようとしているプログラミング問題に高度に関連しています。 まずテストケースを提案し、次にソリューションを提案し、さらにテストケースを反復する、といったように、ステップで実行する必要があるタスクを詳細にエージェントに通知します。 この認知アーキテクチャは、非常にドメイン固有であり、汎用的ではなく、他のドメインに直接一般化することは困難である。
ケーススタディ:Reflection AI創設者ラスキンが考えるエージェントの未来
セコイア・キャピタルのReflection AI創業者ミーシャ・ラスキン氏へのインタビューでは、ミーシャ・ラスキン氏がエージェントの未来について次のようなビジョンを語っている。 RL(強化学習)の探索能力 LLMと連携して、リフレクションAIは優れた性能を持つエージェントモデルの構築に注力している。 ミーシャ・ラスキンと共同設立者のイオアニス・アントノグルー(AlphaGo、AlphaZero、Gemini RLHFの責任者)は、LLMのために特別に設計されたエージェントモデルのトレーニングに重点を置いています。 エージェント型ワークフロー デザインのモデル化 インタビューから得られた核となる考えを以下に示す:
- 奥行きはAIエージェントに欠けている重要な要素だ。 現在の言語モデルは知識の幅という点では優れているが、複雑なタスクを確実にこなすのに必要な深さには欠けている。 ミーシャ・ラスキンは、「深さの問題」を解決することが、真に有能なAIエージェントを作るために重要であると主張している。 ここでいう「能力」とは、複雑なタスクを複数のステップで計画・実行するエージェントの能力のことである。
- ラーンとサーチを組み合わせることが、超人的なパフォーマンスを発揮する鍵なのだ。 ミーシャ・ラスキンは、アルファ碁の成功を引き合いに出し、AIにおける最も深遠な考え方は、**学習**(LLMに依存)と**探索**(最適な経路を見つける)の効果的な組み合わせであると強調した。 このアプローチは、複雑なタスクにおいて人間を凌駕するエージェントを生み出すために不可欠である。
- ポストトレーニングと報酬のモデル化は大きな課題である。 明示的な報酬メカニズムがあるゲームとは異なり、実世界のタスクには通常、明示的な報酬シグナルがない。 信頼できる 報酬モデル 重要な課題は、信頼できるAIエージェントを作ることだ。
- ユニバーサル・エージェントは、私たちが考えているよりも近いかもしれない。 ミーシャ・ラスキンは、私たちがこの目標を達成するのはあと3年先かもしれないと予測している。 "デジタルAGI(デジタル総合人工知能)" この加速されたタイムラインは、セキュリティと信頼性の問題に同時に取り組みながら、エージェント能力を急速に開発することの緊急性を強調している。 この加速されたタイムラインは、セキュリティと信頼性の問題に同時に取り組みながら、エージェント能力を急速に開発することの緊急性を強調している。
- ユニバーサル・エージェントへの道にはメソッドが必要だ。 Reflection AIは、ブラウザ、コードエディタ、コンピュータオペレーティングシステムなどの特定の環境から、エージェントの機能境界を拡張することに重点を置いています。 最終的な目標は ユニバーサル・エージェント そのため、特定の業務に限定されることなく、さまざまな分野で仕事をこなすことができる。
UI/UX インタラクション・イノベーション
ヒューマン・コンピュータ・インタラクション(HCI)は、今後AIにおける重要な研究方向となるだろう。 エージェントシステムは従来のコンピュータシステムとは大きく異なり、待ち時間や信頼性の低さ、自然言語インターフェースといった新しい特徴が新たな課題となる。 したがって、新しい種類の UI/UX(ユーザーインターフェース/ユーザーエクスペリエンス) パラダイムが出現する。 エージェントシステムはまだ開発の初期段階にありますが、いくつかの新しいUXパラダイムが出現しています。 それぞれについて以下に説明します。
1.会話型インタラクション(チャットUI)
会話型インタラクション(チャットUI) 通常、大きく分けて2つのタイプがある: ストリーミング・チャット 歌で応える 非ストリーミング・チャット .
ストリーミング・チャット は、今日最も一般的なUXパラダイムです。 これは基本的にチャットボットであり、エージェントの思考プロセスや行動を人間のような対話形式でステップアップさせます。 ストリーム スタイルをユーザーに返す。 チャットGPT 典型的なストリーミング・チャットである。 第一に、ユーザーは自然言語を用いてLLMと直接対話することができ、ユーザーとLLMの間にコミュニケーション上の障壁がほとんどないこと、第二に、LLMがタスクを完了するには通常時間がかかるが、ストリーミング処理により、家計はバックグラウンドタスクの実行状況をリアルタイムで知ることができること、第三に、LLMは時にミスを犯すことがあるが、チャットインターフェースは、LLMがミスを犯さないように、ユーザーがLLMを自然に訂正し、指導する方法を提供すること、第四に、LLMは時にミスを犯すことがあるが、チャットインターフェースは、LLMがミスを犯さないように、ユーザーがLLMを自然に訂正し、指導する方法を提供することである。第三に、LLMは時に間違いを犯すことがあるが、チャット・インターフェースは、ユーザーが自然にLLMを訂正し、指導するフレンドリーな方法を提供する。LLMは、チャット・プロセスでフォローアップ会話や反復を行い、徐々に要件を明確にし、問題を解決することに非常に慣れている。
しかしだ。ストリーミング・チャット また、いくつかの制限もある。 第一に、ストリーミングチャットはまだ比較的新しいユーザエクスペリエンスであり、一般的なチャットプラットフォーム(iMessage、Facebook Messenger、Slackなど)ではまだ一般的に採用されていません。第二に、ストリーミングチャットのユーザエクスペリエンスは、実行時間の長いタスクには少し不十分であり、ユーザはエージェントがタスクを完了するのを待つために、長い時間チャットインターフェースに留まる必要があるかもしれません。第三に、ストリーミングチャットは通常、人間のユーザによってトリガされる必要があり、タスクの実行中に大量の人間の関与(Human-in-the-tray)がまだ必要であることを意味します。第三に、ストリーミングチャットは通常人間のユーザによってトリガされるため、エージェントの実行プロセスにおいて、まだ多くの人間の関与(Human-in-the-loop)があることを意味します。
非ストリーミング・チャット ストリーミングチャットとの主な違いは、エージェントの応答がバッチで返されることです。 LLM はバックグラウンドで静かに動作するため、ユーザーはエージェントからの即時応答を待ち焦がれて待つ必要はありません。 これは、非ストリーミングチャットが既存のワークフローに統合しやすいことを意味します。 ユーザーは友達にメールを送ることに慣れている。 ノン・ストリーミング・チャットは、より複雑なエージェント・システムとの対話をより自然で簡単なものにするでしょう。 複雑なAgentシステムの実行には長い時間がかかることが多いため、Agentからの即時応答を期待すると、ユーザはフラストレーションを感じるかもしれません。 ノン・ストリーミング・チャットは、即座の応答に対する期待の一部を取り除き、より複雑なタスクの実行を容易にします。
以下の表はその要約である。 ストリーミング・チャット 歌で応える 非ストリーミング・チャット のメリットとデメリット

2.背景環境(アンビエントUX)
前述のように、ユーザーはAIに積極的にメッセージを送ることができる。 チャットUI(チャットインターフェース) しかし、もしAgentがバックグラウンドで黙って動いているだけなら、どうやって対話するのでしょうか? しかし、もしエージェントがバックグラウンドで黙って動いているだけなら、どうやってエージェントと対話するのでしょうか?
エージェント・システムの潜在能力をフルに発揮するためには、HCIパラダイムを、以下のようなAIを許容するものへとシフトさせる必要がある。 バックエンド環境(アンビエントUX) をバックグラウンドで実行する。 タスクがバックグラウンドで処理される場合、ユーザーは通常、タスクの完了時間が長くなることを許容することができる(なぜなら、タスクの完了時間が長くなることで、タスクがバックグラウンドで処理される必要性が減るからだ)。 レイテンシー 期待値)。 これにより、エージェントはより多くのタスクを実行する時間を持つことができ、一般的にチャットUXよりもより多くの推論をより慎重かつ効率的に行うことができます。
さらに バックエンド環境(アンビエントUX) チャットインターフェイスでエージェントを実行することは、人間のユーザ自身の能力を拡張するのに役立ちます。 チャットインターフェースは通常、ユーザを一度に一つのタスクに制限します。 しかし、エージェントがバックグラウンド環境で動作している場合、同時に複数のタスクに取り組む複数のエージェントをサポートすることが可能です。
Agentをバックグラウンドで確実に動作させる鍵は、Agentに対するユーザの信頼を築くことです。 どのようにして信頼を築くのでしょうか? 一つの簡単なアイデアは、ユーザにAgentが何をしているかを正確に見せることです。 Agentが実行しているすべてのステップをリアルタイムで表示することで、ユーザは何が起こっているかを観察することができます。 これらのステップは、レスポンスのストリーミングほど即座ではないかもしれませんが、ユーザがいつでもクリックし、エージェントの実行の進捗を確認できるようにする必要があります。 さらに、ユーザがエージェントの実行内容を確認できるだけでなく、ユーザがエージェントのエラーを修正できるようにすることも重要です。 例えば、ユーザがエージェントが(10のうち)ステップ4で間違った判断をしたことを発見した場合、ユーザはステップ4に戻り、何らかの方法でエージェントの動作を修正するオプションがあります。
このアプローチは、ユーザーとエージェントの相互作用モデル イン・ザ・ループ」から「オン・ザ・ループ」へ。 . "オン・ザ・ループ" このモデルでは、エージェントが実行するすべての中間ステップをユーザーに表示できるシステムが必要です。ユーザーは、タスクの実行中にワークフローを一時停止し、フィードバックを提供し、ユーザーのフィードバックに基づいてエージェントが後続のタスクを実行し続けることができます。
AIソフトウェア・エンジニア デヴィン は、UXライクなアプリケーションの実装の代表です。 Devinの実行時間は通常長いですが、ユーザはAgentが実行するすべてのステップを明確に見ることができ、特定の時点で開発状態に戻り、その状態から修正指示を出すことができます。 エージェントがバックグラウンドで動作しているからといって、完全に自律的にタスクを実行する必要はありません。 エージェントは、次に何をすればよいかわからなかったり、ユーザの質問にどう答えればよいかわからなかったりすることがあります。 このような場合、エージェントは積極的に人間のユーザの注意を引き、人間のユーザに助けを求める必要があります。
アシスタント・エージェントにEメールを送る アンビエントUX(背景環境) LangChainのもう一つの使用例。 LangChainの創設者であるHarrison Chaseは、Eメールアシスタントエージェントを構築しています。 このエージェントは、簡単なEメールには自動的に返信できますが、場合によっては、Harrisonが手作業で以下のような自動化に向かないタスクに従事する必要があります:複雑なLangChainバグレポートの確認、複雑なLangChainのバグレポートの確認、複雑なLangChainのエラーレポートの確認、会議に出席するかどうかの判断など。 このような場合、メールアシスタントエージェントは、タスクを完了し続けるために人間の支援が必要であることをハリソンに伝える効率的な方法が必要です。 Harrison に直接回答を求める代わりに、Agent は特定のタスクについて Harrison に意見を求め、Agent はその人間からのフィードバックを使って、質の高いメールを書いたり、ミーティングカレンダーの招待をスケジュールしたりすることができます。
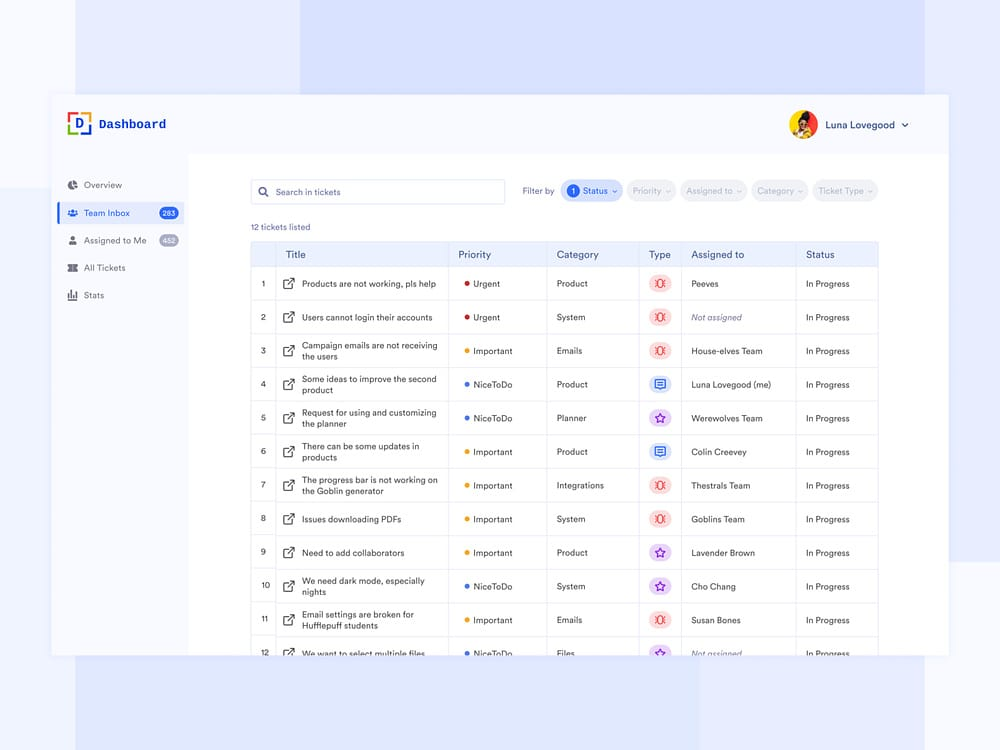
現在、ハリソンはこのメールアシスタントエージェントをSlackワークスペースに設定している。 エージェントが人的支援を必要とする場合、ハリソンのSlackに質問を送信し、ハリソンはダッシュボードで回答することができ、このやりとりはハリソンの日々のワークフローとシームレスに統合されている。このタイプのインタラクションは、ハリソンの日々のワークフローとシームレスに統合されている。 このタイプのUXは、顧客がダッシュボードをサポートするために使用するUXに似ている。 ダッシュボードのインターフェイスには、アシスタントが人的支援を必要とするすべてのタスク、リクエストの優先度、およびその他の関連データが明確に表示される。
3.スプレッドシートのUX

スプレッドシートのUX 非常に直感的でユーザーフレンドリーなインタラクションで、特にバッチ処理ジョブに適しています。 スプレッドシートインタフェースでは、各テーブル、あるいは各列を、特定のタスクを調査・処理するための個別のエージェントとして扱うことができます。 このバッチ処理機能により、ユーザは複数のエージェントとのインタラクションを簡単に拡張することができます。
スプレッドシートのUX 他にも利点がある。 スプレッドシート形式は、ほとんどのユーザーが慣れ親しんでいるUXであるため、既存のワークフローへの統合が容易である。 このタイプのUXは、スプレッドシートの各列が、拡張が必要な異なるデータ属性を表すことができる、データエンリッチメントのシナリオに最適である。
エクサ AI、クレイAI、マナフローなどは スプレッドシートのUX 以下はManaflowの例です。 以下はManaflowの例です。 スプレッドシートのUX エージェントとの対話ワークフローへの適用方法
ケーススタディ:Manaflowはどのようにエージェントのインタラクションにスプレッドシートを使用していますか?
Manaflowは、創業者であるローレンスが勤めていたMinion AI社にインスパイアされた。 Minion AI社の主力製品はウェブ・エージェントである。 ウェブ・エージェントは、ローカル・ネットワーク・アプリケーションを制御することができる。 グーグル・クローム ブラウザを使用して、オンライン航空券の予約、電子メールの送信、洗車の予約など、ウェブエージェントを通じてさまざまなウェブアプリケーションと対話することができます。 ManaflowはMinion AIに触発され、Agentにスプレッドシートなどのツールを直接操作させることにした。 Manaflowチームは、Agentは人間のUIインターフェイスを直接操作することは得意ではなく、Agentが本当に得意なのは以下のようなことだと考えています。 コーディング Manaflowはこの種のものとしては世界初です。 その結果、ManaflowはエージェントがUIインターフェースから直接Pythonスクリプト、データベースインターフェース、APIインターフェースを呼び出し、データの読み込み、スケジューリング、メール送信など、データベース上で直接操作することができます。
Manaflowのメイン インタラクティブ インターフェースはスプレッドシート(Manasheet)である。 Manasheetの各列はワークフローのステップを表し、各行は特定のタスクを実行するAIエージェントに対応する。 Manasheetの各ワークフローは自然言語でプログラム可能である(非技術系ユーザが自然言語でタスクやステップを記述できる)。 各マナシートには、各列の実行順序を決定する内部依存関係グラフがあります。 これらの実行順序は各列のエージェントに割り当てられ、エージェントは並行してタスクを実行し、データ変換、APIコール、コンテンツ検索、メッセージングなどのプロセスを処理します:
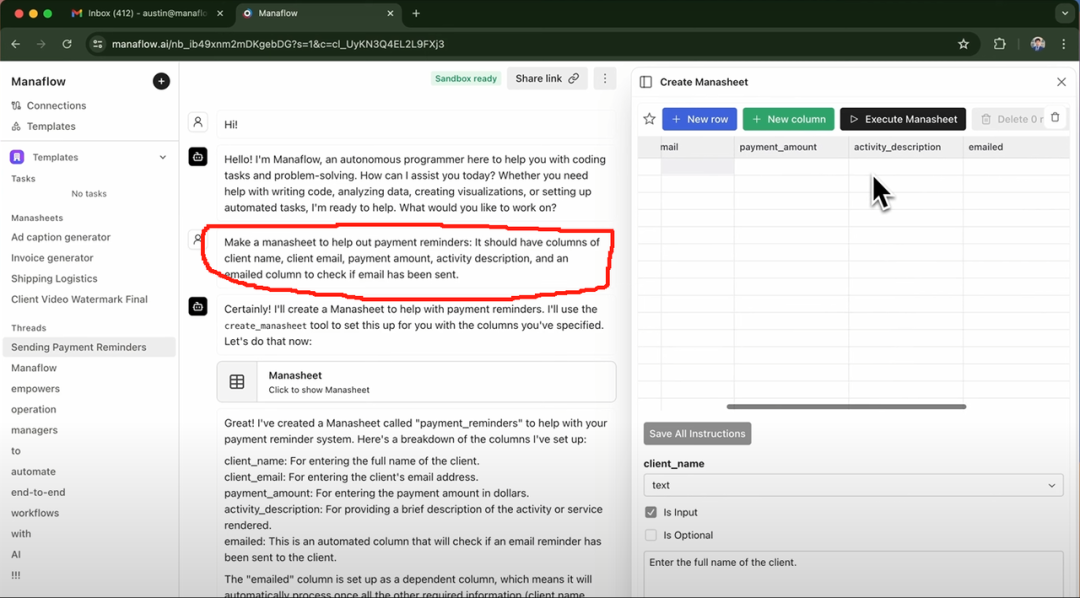
マナシートは様々な方法で生成することができます。 最も一般的な方法は、上の赤枠のような自然言語コマンドを入力することです。 マナシートは、顧客の名前、メールアドレス、業種、メール送信の有無などの重要な情報を表示します。 ユーザは「マナシート実行」ボタンをクリックするだけで、一括メール送信タスクを実行することができます。
4.ジェネレーティブUI
"ジェネレーティブUI" 主に2つの異なる実装がある。
最初の方法は、モデルが自律的に必要なものを生成することである。 UIコンポーネント . と似ている。 ウェブシム およびその他の製品に対応しています。 バックグラウンドでは、エージェントは主に生のHTMLコードを記述し、ユーザインターフェイスの表示内容を完全に制御します。 しかし、このアプローチの欠点は、出来上がったウェブアプリの品質が非常に不確かであり、ユーザエクスペリエンスが変化しやすいことです。
別の、より制約の多いアプローチとしては、よく使われるUIコンポーネントのセットをあらかじめ定義しておき、それらを ツール・コール を呼び出して、UIコンポーネントを動的にレンダリングする。 例えば、LLMが天気APIを呼び出すと、天気図のUIコンポーネントがレンダリングされる。 レンダリングされるUIコンポーネントはあらかじめ定義されているため(そしてユーザーにはより多くの選択肢がある)、結果として得られるUIはより洗練されたものになるが、柔軟性はやや制限される。
ケーススタディ:パーソナルAI製品ドット
パーソナルAI製品 ジェネレーティブUI その最たる例だ。 dotは2024年に「最高のパーソナルAI製品」と称されている。
ドット はい 新規 コンピューター 同社のスター製品。 dotの目標は、単なる効率的なタスク管理ツールではなく、ユーザーにとって長期的なデジタル・コンパニオンとなることだ。 ニュー・コンピュータ社の共同設立者であるジェイソン・ユアン氏が言うように、dotの利用シーンは「どこに行けばいいのか、何をすればいいのか、何を言えばいいのかわからないときに、dotに頼る」というものだ。 dotの典型的な使用例をいくつか紹介しよう:
- ニュー・コンピュータの創業者ジェイソン・ユアンは、「酔いたい」という思いから、よくドットにお勧めの深夜バーを尋ねる。 深夜のバーでの会話が数ヶ月続いたある日、ジェイソン・ユアンはドットにも同じような質問をし、ドットはジェイソンに「このままではいけない」と言い始めた。
- ファスト・カンパニーのマーク・ウィルソン記者もまた、ドットとともに数カ月を過ごした。 ある時、彼はカリグラフィーのクラスで書いた手書きの「O」をdotに見せた。 驚いたことに、dotはすぐに数週間前のマーク・ウィルソンの手書きの「O」の写真を引っ張り出し、カリグラフィーの「素晴らしい上達ぶり」を褒めた。
- ユーザーがドットを長時間利用するにつれ、ドットはユーザーの興味や嗜好をより深く理解できるようになる。 例えば、あるユーザーがカフェ巡りが好きであることがわかると、dotはユーザーに近隣の良質なカフェを積極的にプッシュし、推薦の理由を詳しく説明し、最後にナビゲートする必要があるかどうかをユーザーに尋ねる。
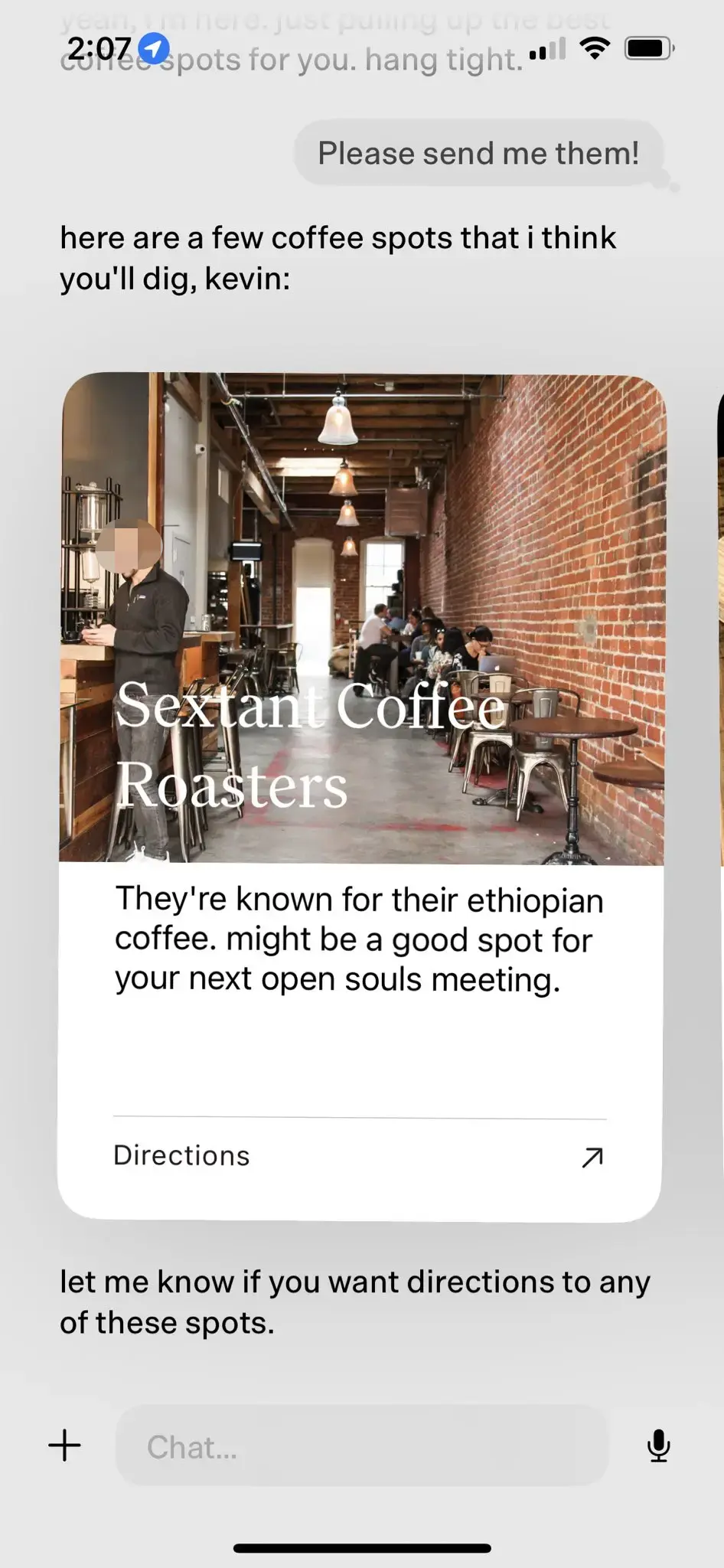
上記のカフェ推薦の場合、dotはLLM-nativeに基づき、あらかじめ定義されたUIコンポーネントを通じて、人間とコンピュータの自然なインタラクション効果を実現する。
5.コラボレーティブUX
エージェントと人間のユーザが一緒に作業すると、どのような人間とコンピュータのインタラクションパターンが生まれるのでしょうか? Googleドキュメントと同様に、複数のユーザーが同じドキュメントをリアルタイムで共同編集することができます。 もし共同作業者の一人がエージェントだったらどうでしょう?
ジェフリー・リットとインク・アンド・スイッチ パッチワーク・プロジェクト マン・マシンだ。 コラボレーションUX Patchworkプロジェクトは、OpenAIのすべてを示す素晴らしい例です。(訳者注:OpenAIが最近リリースしたCanvas製品のアップデートは、Patchworkプロジェクトにインスパイアされたのかもしれない)。
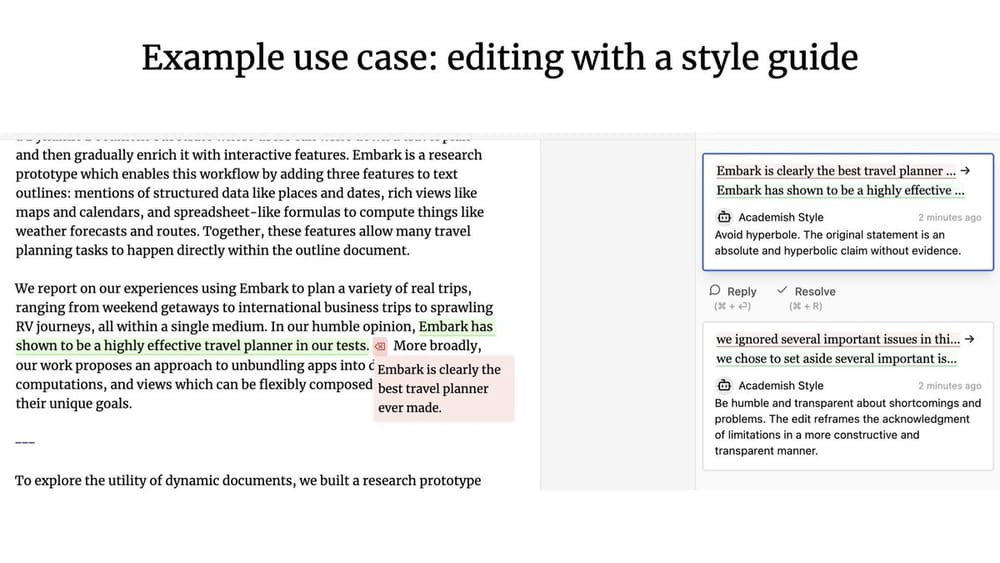
コラボレーションUX 先に述べたのとは対照的だ。 アンビエントUX(背景環境) 何が違うのか? LangChainの創業エンジニアであるヌーノは、この2つの主な違いは、次のものが利用できるかどうかだと強調する。 コンカレンシー ::
- ある コラボレーションUX この場合、人間のユーザーとLLMは通常同時に作業し、互いの作業成果を入力として使用する必要がある。
- ある アンビエントUX(背景環境) この場合、LLMはバックグラウンドで継続的に実行され、ユーザーはエージェントの状態をリアルタイムで監視することなく、他のタスクに集中することができます。
メモリー
メモリー Agentのユーザーエクスペリエンスを向上させることは非常に重要です。 もしあなたの同僚が、あなたが話したことを全く覚えておらず、何度も何度も同じことを繰り返すように要求してきたらと想像してみてください。 おそらくLLMはある意味人間の認知に非常に近いからでしょう。 しかし、LLMには本来記憶能力はない。
エージェント メモリー デザインは、製品自体の特定のニーズに合わせる必要がある。 UXパラダイムが異なれば、情報収集やフィードバックの更新方法も異なります。 エージェント製品の記憶メカニズムから、人間の記憶タイプをある程度模倣した、さまざまなタイプの高レベルの記憶パターンを観察することができます。
CoALA: Cognitive Architectures for Language Agents(言語エージェントのための認知アーキテクチャ)」という論文では、人間の記憶の種類をエージェントの記憶メカニズムにマッピングし、下図のように分類している:
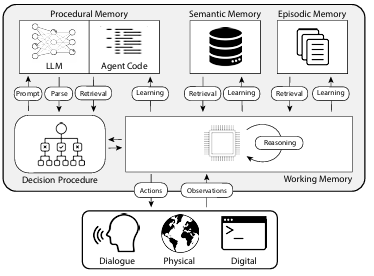
1.手続き記憶
手続き記憶 について語る方法だ。 タスクの進め方 長期記憶の、人間の脳における中核的な命令セットに似ている。
- 人間の手続き記憶。 例えば、自転車の乗り方を覚えておく。
- エージェントの手続き記憶 CoALAの論文では、手続き記憶はLLMの重みとエージェントコードの組み合わせであり、エージェントがどのように動作するかを根本的に決定するものであるとしている。
実際、Langchainチームは、自動的にLLMを更新したり、コードを書き換えたりするエージェントシステムを発見していません。 しかし、動的にLLMを更新するエージェントシステムは存在します。 システムプロンプト のケース。
2.意味記憶
意味記憶 それは、事実に基づいた知識を蓄えるための長期的な知識予備軍である。
- 人間の意味記憶。 学校で学んだ事実や概念、それらの関係性など、さまざまな情報から構成される。
- エージェントのための意味記憶。 CoALAの論文では、意味記憶は事実知識のリポジトリと説明されている。
実際には、エージェントのセマンティック記憶は、通常、LLMを使用してエージェントのダイアログや対話プロセスから情報を抽出することで実現されます。 情報を記憶する正確な方法は、通常、特定のアプリケーションに依存します。 その後のダイアログで、システムはこの記憶された情報を取り出し、それを システムプロンプト エージェントの反応に影響を与える。
3.エピソード記憶
エピソード記憶 特定の過去の出来事を思い出すのに使う。
- 人間の状況記憶。 状況記憶は、人が過去に経験した特定の出来事(または「エピソード」)を思い出すときに使われる。
- エージェントの状況記憶 CoALA の論文では、状況記憶をエージェントの過去の行動を記憶するシーケンスと定義している。
シナリオメモリは主に、エージェントが期待通りのパフォーマンスをすることを保証するために使用される。 実際には、状況記憶は通常 プロンプト メソッドで実現できる。 もし初期段階で、システムを プロンプト もしエージェントが正しく操作を完了するように指示されれば、今後同じような問題に直面したときに、この操作方法を直接再利用することができます。 逆に、エージェントが正しく操作できるように導く効果的な方法がない場合や、エージェントが新しい操作方法を試す必要がある場合は 意味記憶 はさらに重要になるだろう。エピソード記憶 このようなシナリオでの役割は比較的限られている。
Agentで更新が必要なメモリの種類を考慮することに加えて、開発者は以下を考慮する必要があります。 エージェントメモリの更新方法 . 現在、エージェントメモリの更新には主に2つの方法があります:
最初の方法は "ホット・パスで(ホット・パス・アップデート)" . このモデルでは、エージェントシステムは、応答を生成する前に、関連する事実情報をリアルタイムで記憶します(通常、ツールの呼び出しによって実現されます)。 ChatGPTは現在この方法でメモリを更新しています。
つ目の方法は "イン・ザ・バックグラウンド(バックグラウンド・アップデート)" . このモードでは、バックグラウンドプロセスがセッション終了時に非同期で実行され、バックグラウンドでエージェントのメモリを更新します。
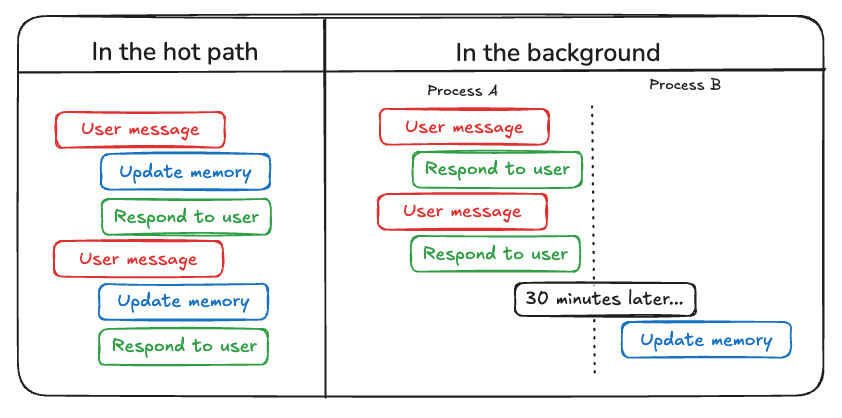
"ホット・パスで(ホット・パス・アップデート)" このメソッドの欠点は、何らかのレスポンスが返される前に、一定量の レイテンシー . 加えて、次のような要素を盛り込む必要がある。 メモリーロジック とともに エージェントロジック 緊密に統合されている。
"イン・ザ・バックグラウンド(バックグラウンド・アップデート)" メソッドは上記の問題を効果的に回避し、応答待ち時間を増加させず、また メモリーロジック は比較的独立性を保つことができる。 しかし "イン・ザ・バックグラウンド(バックグラウンド・アップデート)" また、メモリが即座に更新されるわけではなく、バックグラウンドの更新プロセスを開始するタイミングを決定するために追加のロジックが必要になるという欠点もある。
記憶を更新するもう1つのアプローチは、ユーザーからのフィードバックである。 エピソード記憶 特に関連性が高い。 例えば、ユーザがエージェントとのインタラクションに高い評価(ポジティブ・フィードバック)、エージェントはそのフィードバックを保存して、将来同じようなシナリオで呼び出すことができます。
以上のまとめから、AIシェアは、プランニング能力、インタラクションの革新性、記憶メカニズムという3つの重要な要素の同時開発と継続的な進歩が、2025年により実用的なAIエージェントアプリケーションを生み出し、人間と機械の協働作業の新時代へと私たちを導いてくれることを期待している。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません