2024 中国大型モデルベンチマーキングレポート(SuperCLUE)

コンテキスト
2023年以降、AIビッグモデルは世界規模で過去最大のAIの波を生み出してきた。2024年に入り、世界的なビッグ・モデルの競争力学はますます激化しそら」「GPT-4o」「o1」の発売により、2024年の国産ビッグモデルの追撃は波紋を広げた。

中国ビッグモデル評価ベンチマーク「SuperCLUE」は、国内外のビッグモデルの発展動向と総合的な効果をリアルタイムで継続的に追跡し、正式に発表した。中国大型モデルベンチマーク2024年版年次報告書。
報告書全文は89ページで構成されているが、本稿では報告書の主要な内容のみを紹介する:
www.cluebenchmarks.com/superclue_2024
SuperCLUEリーダーボードのアドレス:
www.superclueai.com
報告書の主な内容
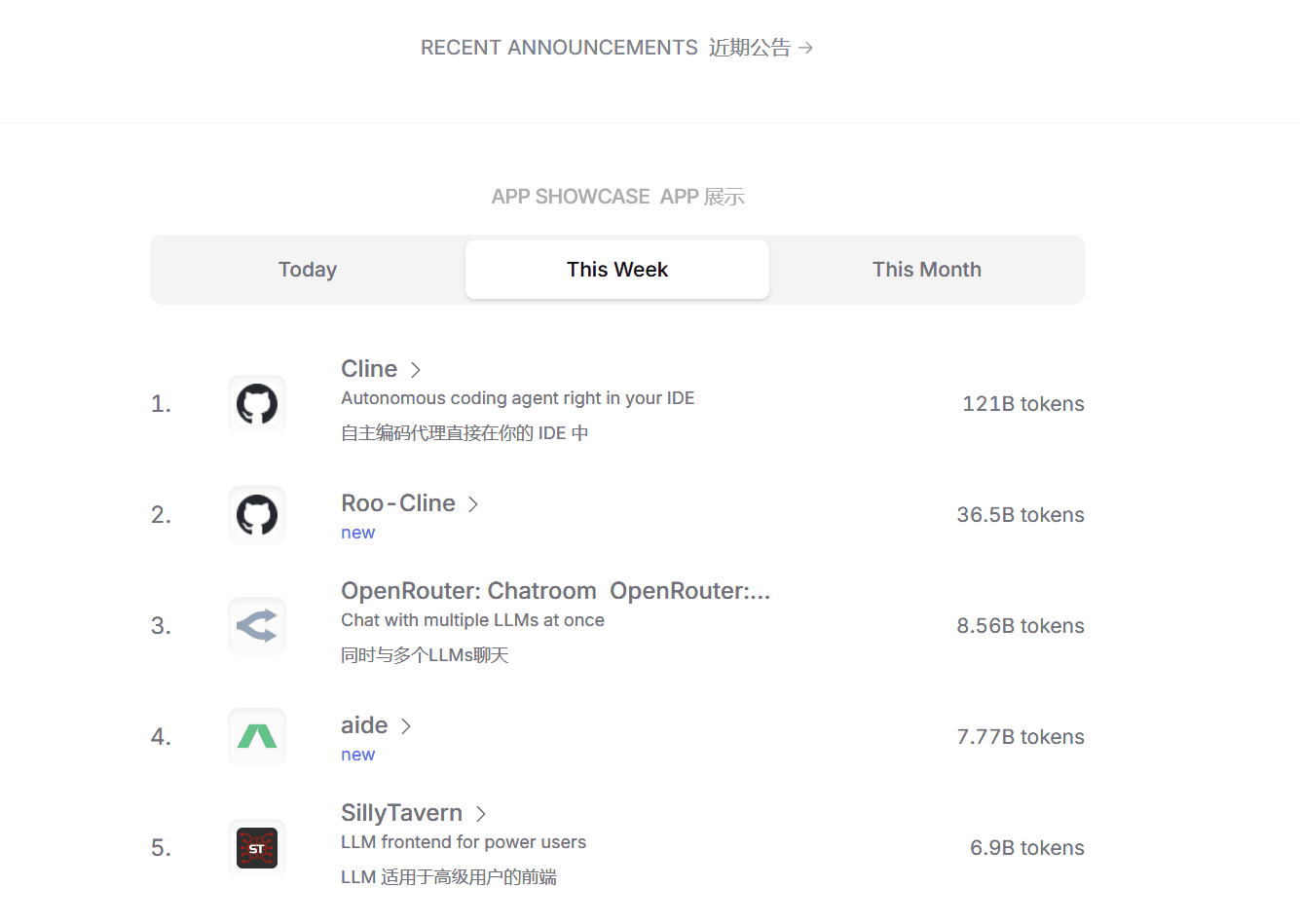
キーコンポーネント1:2024年の最も注目すべきビッグモデルのパノラマ

主要コンポーネント2:年間総合ランキングとモデリング・クワドラント
評価入門
この年次報告は、「科学」「芸術」「ハード」の3つの側面から構成される一般能力評価に焦点を当てている。問題はすべてオリジナルの新問題合計1,325問の複数ラウンドの記述式問題が出題された。
[サイエンスタスク]は、コンピューティング、論理的推論、コード評価セット、[アートタスク]は、言語理解、ジェネレーティブクリエーション、セキュリティ評価セット、[ハードタスク]は、インストラクションフォロー、ディープ推論、エージェント評価セットに分かれている。

本評価のデータはSuperCLUE-12月版の評価結果から、モデルは12月版の国内外の代表的な42の大型モデルから選定した。

リーグテーブル

年間モデルの象限

主要要素3:バリュー・フォー・マネー・ゾーンの配分

価格性能比(価格+効果)では国産大型モデルの優位性が大きい
DeepSeek-V3、Qwen2.5-72B-Instruct、Qwen2.5-32B-Instructなどの国内大型モデルは、価格性能比の面で大きな競争力を示しています。比較的高いレベルの能力に基づいて、非常に低いアプリケーションコストを維持することができ、着陸のアプリケーションでは、フレンドリーな使いやすさを示しています。
ほとんどのモデルが中価格帯にある
高い能力を維持するため、ほとんどのモデルはまだ高価格帯だ。例えば、GLM-4-Plus、Qwen-Max-latest、Claude 3.5 Sonnet、Grok-2-1212はいずれも100万トークンあたり30ドルを超える価格設定だ。
o1やその他の推論モデルの費用対効果は、まだまだ最適化の余地がある。
o1やo1-previewは高い能力を示しているが、価格的には他のモデルより数倍高い。いかにコストを下げるかが、推論モデルを普及させるための必須条件になるかもしれない。
キーコンポーネント4:効率間隔の分布に関する推論

総合的な効果で競争力のある国産モデルもある
国産モデルの中では、DeepSeek-V3とQwen2.5-32B-Instructが、1問あたりの平均推論時間が10秒以下と推論速度に優れ、同時にベンチマークスコアも60点以上と「ハイパフォーマンスゾーン」に並び、非常に高いアプリケーションの有効性を示している。
Gemini-2.0-Flash-Exp、ビッグモデルアプリケーションのパフォーマンスで世界をリード
海外モデルのGemini-2.0-Flash-Exp、Claude 3.5 Sonnet(20241022)、Grok-2-1212、GPT-4o-miniが「ハイパフォーマンス・ゾーン」に該当し、推論時間とベンチマークスコアの複合効果ではGemini-2.0-Flash-Expが最も優れている。GPT-4o-miniは、推論速度の点で最も優れている。
推論モデルパフォーマンスの面では最適化の余地が大きい。
o1-previewに代表される推論モデルは、ベンチマークスコアでは良好な結果を示しているが、1問あたりの平均推論時間は約40秒であり、全体的な性能は「低性能ゾーン」に一致している。幅広い適用シーンを想定するためには、推論モデルの推論速度の向上に注力する必要がある。
主要部品5:国内および国際的な大型モデルのギャップと傾向(2024年

一般的な傾向として、中国ドメインにおける国内と海外のビッグモデルの第一層の汎用能力の差は広がっている。
2023年5月から現在に至るまで、国内外の大型モデルの実力は発展を続けている。なかでもGPTシリーズに代表される海外最高峰モデルは、GPT3 . 5、GPT4、GPT4ターボ、GPT4o、o1と複数のバージョンアップを繰り返してきた。
国内モデルも1年8ヶ月のサイクルを繰り返し、2023年5月の0.12%から2024年8月には1.29%まで差を縮めた。

DeepSeek-V3に代表される国内モデルは、GPT-4o-latestに極めて近づきつつある。
この2年間、国内代表モデルはいくつかのバージョンを繰り返し、DeepSeek-V3、Doubao-pro、GLM-4-Plus、Qwen2.5は中国語タスクでGPT-4oに迫る性能を発揮しており、中でもDeepSeek-V3は12月の評価でクロード3.5ソネットの性能を上回る好成績を収めている。
o1 強化学習という新しいパラダイムに基づく推論モデルが80点を突破し、国内外のトップモデルとの差を広げた。
12月のSuperCLUEの評価では、SuperCLUEベンチマークのスコアで、国内外の主な頭の大きなモデルは60〜70点に集中している。o1とo1-previewは、強化学習推論モデルの新しいパラダイムに基づいて、70点のボトルネックのブレークスルーの重要な技術の代表となり、特に80点台のブレークスルーのo1正式版は、大きなリード優位性を示しています。
主要要素6:その他のサブディメンションリスト
ハードリスト

科学科目リスト

リベラルアーツ一覧

各次元で中国トップ3

オープンソースモデル一覧

10Bまでのモデル一覧

5Bまでのエンド側モデル一覧

セカンダリー・ファイン・グレイン・スコアのリスト

紙面の都合上、本稿では報告書の一部のみを紹介する。全内容には、評価方法、評価例、サブタスクリスト、マルチモダリティ、アプリケーション、推論ベンチマークの紹介が含まれる。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません