zChunk : une stratégie générique de découpage sémantique basée sur Llama-70B
Introduction générale
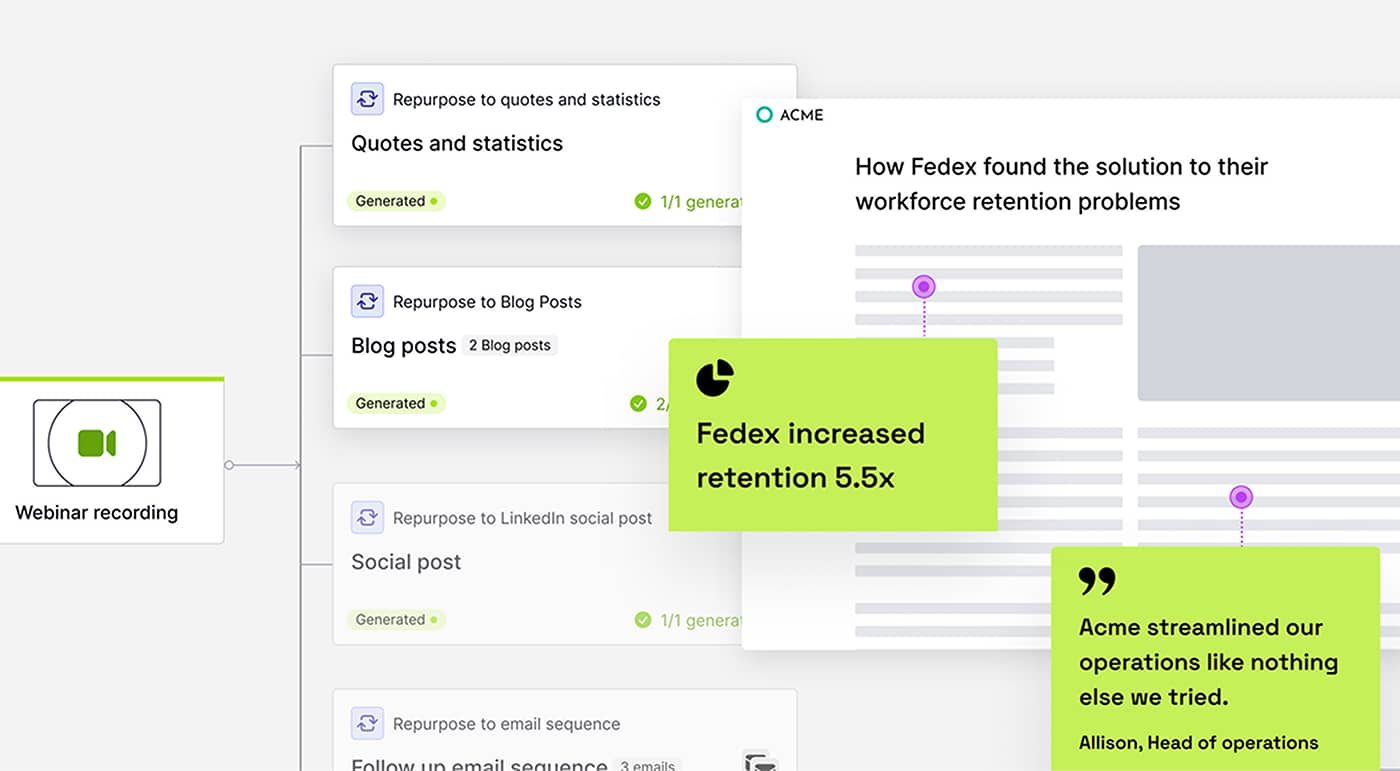
zChunk est une nouvelle stratégie de découpage développée par ZeroEntropy pour fournir une solution de découpage sémantique à usage général. La stratégie est basée sur le modèle Llama-70B, qui optimise le processus de découpage d'un document en invitant à la génération de morceaux, garantissant ainsi le maintien d'un rapport signal-bruit élevé lors de la recherche d'informations. zChunk est particulièrement adapté aux applications RAG (Retrieval Augmentation Generation) qui nécessitent une recherche de haute précision, et résout les limites des méthodes de découpage traditionnelles lorsqu'il s'agit de documents complexes. Avec zChunk, les utilisateurs peuvent plus efficacement segmenter les documents en morceaux significatifs, améliorant ainsi la précision et l'efficacité de la recherche d'informations.
Votre tâche consiste à agir en tant que chunker.
Vous devez insérer le "paragraphe" tout au long de la saisie.
Votre objectif est de séparer le contenu en groupes sémantiquement pertinents.
méthodologie et Limites de l'OCR LLM : les défis de l'analyse de documents sous les feux de la rampe Les PROMPTs mentionnés ont certains points communs.

Liste des fonctions
- Algorithme de découpage basé sur Llama-70B: Génération d'indices pour le découpage sémantique à l'aide du modèle Llama-70B.
- Regroupement à haut rapport signal/bruitOptimiser la stratégie de regroupement pour que les informations extraites aient un rapport signal/bruit élevé.
- Stratégies de découpage multiplesIl prend en charge diverses stratégies telles que le découpage en morceaux de taille fixe, le découpage en morceaux basé sur la similarité d'intégration, etc.
- réglage des hyperparamètresLe système de gestion de l'information de la Commission européenne : Il fournit un pipeline de réglage des hyperparamètres qui permet aux utilisateurs d'ajuster la taille des morceaux et les paramètres de chevauchement en fonction de leurs besoins spécifiques.
- source ouverteLe code source est fourni et peut être librement utilisé et modifié par l'utilisateur.
Utiliser l'aide
Processus d'installation
- entrepôt de clones: :
git clone https://github.com/zeroentropy-ai/zchunk.git
cd zchunk
- Installation des dépendances: :
pip install -r requirements.txt
Utilisation
- Préparation du fichier d'entréeEnregistrer le document à fragmenter sous la forme d'un fichier texte, par exemple.
example_input.txt. - Exécuter le script de découpage: :
python test.py --input example_input.txt --output example_output.txt
- Visualisation du fichier de sortieLes résultats du découpage seront sauvegardés dans le fichier
example_output.txtAu milieu.
Fonction détaillée du déroulement des opérations
- Choisir une stratégie de découpage: :
- NaiveChunkLes documents simples peuvent être regroupés en morceaux de taille fixe.
- SemanticChunkLe projet "Chunking", basé sur la similarité d'intégration pour les documents qui ont besoin de maintenir l'intégrité sémantique, est en cours de développement.
- Algorithme zChunkGénérer des chunks basés sur des indices du modèle Llama-70B pour les documents complexes.
- Ajustement des hyperparamètres: :
- Taille des morceauxLe réglage de ce paramètre peut être effectué par l'utilisateur.
chunk_sizepour définir la taille de chaque morceau. - taux de chevauchement: par l'intermédiaire du paramètre
overlap_ratioDéfinissez le pourcentage de chevauchement entre les morceaux afin d'assurer la continuité de l'information.
- Taille des morceauxLe réglage de ce paramètre peut être effectué par l'utilisateur.
- Exécution de l'ajustement des hyperparamètres: :
python hyperparameter_tuning.py --input example_input.txt --output tuned_output.txt
Le script ajuste automatiquement la taille des morceaux et le taux de chevauchement en fonction du document d'entrée afin de générer des résultats optimaux en matière de découpage en morceaux.
- Évaluer les effets du découpage en morceaux: :
- Évaluez les résultats du découpage à l'aide du script d'évaluation fourni afin de vous assurer de l'efficacité de la stratégie de découpage.
python evaluate.py --input example_input.txt --output example_output.txt
exemple typique
Supposons que nous ayons un texte de la Constitution américaine qui doit être découpé en morceaux :
Texte original :
Section. 1.
All legislative Powers herein granted shall be vested in a Congress of the United States, which shall consist of a Senate and House of Representatives.
Section. 2.
The House of Representatives shall be composed of Members chosen every second Year by the People of the several States, and the Electors in each State shall have the Qualifications requisite for Electors of the most numerous Branch of the State Legislature.
No Person shall be a Representative who shall not have attained to the Age of twenty five Years, and been seven Years a Citizen of the United States, and who shall not, when elected, be an Inhabitant of that State in which he shall be chosen.
Le découpage en morceaux à l'aide de l'algorithme zChunk :
- Sélectionner les mots-clés: Sélectionner un élément spécial (par exemple "paragraphe") qui ne figure pas dans le corpus.
- Insérer des repèresLlama insère le jeton dans le message de l'utilisateur.
SYSTEM_PROMPT (简化版):
你的任务是作为一个分块器。
你应该在输入中插入“段”标记。
你的目标是将内容分成语义相关的组。
- Générer des morceaux: :
Section. 1.
All legislative Powers herein granted shall be vested in a Congress of the United States, which shall consist of a Senate and House of Representatives.段
Section. 2.
The House of Representatives shall be composed of Members chosen every second Year by the People of the several States, and the Electors in each State shall have the Qualifications requisite for Electors of the most numerous Branch of the State Legislature.段
No Person shall be a Representative who shall not have attained to the Age of twenty five Years, and been seven Years a Citizen of the United States, and who shall not, when elected, be an Inhabitant of that State in which he shall be chosen.段
De cette manière, nous pouvons segmenter les documents en blocs sémantiquement liés, chacun d'entre eux pouvant être extrait indépendamment, ce qui améliore le rapport signal/bruit et la précision de la recherche d'informations.
optimisation
- Avec l'inférence locale Llama, des passages entiers peuvent être traités efficacement et les logprobs peuvent être examinés pour déterminer l'emplacement des morceaux.
- Il faut environ 15 minutes pour traiter 450 000 caractères, mais ce délai peut être considérablement réduit si le code est optimisé.
l'étalonnage des performances
- zChunk présente un taux de récupération et un rapport de signal supérieurs à ceux de NaiveChunk et des méthodes de découpage sémantique sur l'ensemble de données LegalBenchConsumerContractsQA.
Avec l'algorithme zChunk, nous pouvons facilement segmenter n'importe quel type de document sans avoir recours à des expressions régulières ou à des règles créées manuellement, ce qui améliore l'efficacité et la précision des applications RAG.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...