
Un article pour vous aider à comprendre RAG (Retrieval Augmented Generation), le concept de l'introduction théorique + la pratique du code.
I. Les LLM ont déjà de fortes capacités, pourquoi avons-nous besoin de RAG (Retrieval Augmentation Generation) ?
Bien que le LLM ait démontré des capacités significatives, plusieurs défis restent à relever :
- Le problème de l'illusion : LLM utilise une approche probabiliste basée sur les statistiques pour générer un texte mot par mot, un mécanisme qui conduit intrinsèquement à la possibilité d'un résultat qui semble être logiquement rigoureux mais qui n'est pas basé sur des faits, ce que l'on appelle les "déclarations fictionnelles grandioses" ;
- (a) Problèmes d'actualité : au fur et à mesure que le LLM se développe, le coût et la durée du cycle de formation augmentent. Par conséquent, les données contenant des informations actualisées sont difficiles à incorporer dans le processus de formation du modèle, ce qui rend le LLM moins apte à traiter des questions temporelles telles que "veuillez suggérer le film préféré du moment" ;
- Problèmes de sécurité des données : le LLM générique n'a pas de données internes d'entreprise et de données d'utilisateur, alors les entreprises veulent utiliser le LLM dans l'optique de garantir la sécurité, la meilleure façon est de placer toutes les données localement, et tous les calculs commerciaux des données d'entreprise sont effectués localement. Le grand modèle en ligne ne remplit qu'une fonction de synthèse ;
II. la présentation de RAG ?
RAG (Retrieval Augmented Generation) est un cadre technologique dont le cœur réside dans le fait que lorsque le LLM est confronté à la tâche de répondre à une question ou de créer un texte, il recherche d'abord dans la bibliothèque de documents à grande échelle et filtre les documents qui sont étroitement liés à la tâche, puis guide avec précision le processus ultérieur de génération de réponses ou de construction de texte basé sur ces documents, dans le but d'améliorer la précision et la fiabilité des résultats du modèle de cette manière. L'objectif est d'améliorer ainsi la précision et la fiabilité des résultats du modèle.
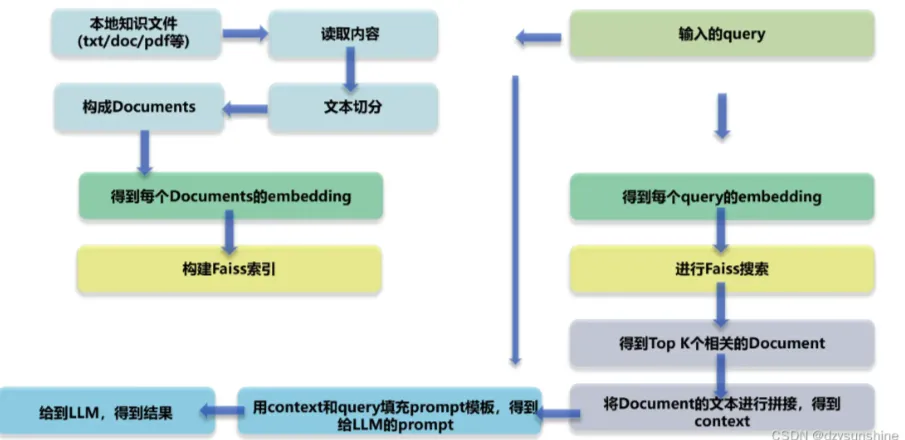
RAG Diagramme de l'architecture technique
III. quels sont les principaux modules du GCR ?
- Module 1 : Analyse de la mise en page
- Lecture de fichiers de connaissances locales (pdf, txt, html, doc, excel, png, jpg, voice, etc.)
- Récupération des documents de connaissance
- Module II : Construire la base de connaissances
- Segmentation des textes de connaissances et construction de textes de documents
- Incrustation de texte dans le document
- Doc Text Build Index
- Module 3 : Affiner le grand modèle
- Module IV : Quiz de connaissances basé sur le RAG
- Intégration des requêtes de l'utilisateur
- requête Rappel
- tri des requêtes
- Les K documents les plus pertinents ont été regroupés pour construire le contexte.
- Construire des messages-guides basés sur la requête et le contexte
- L'invite est transmise au grand modèle pour générer la réponse.
Quels sont les avantages de RAG par rapport à l'utilisation directe de LLM pour les quiz ?
L'approche RAG (Retrieval Augmented Generation) permet aux développeurs d'améliorer considérablement la précision de leurs réponses sans avoir à ré-entraîner de grands modèles pour chaque tâche spécifique, simplement en se connectant à une base de connaissances externe qui peut être injectée avec des ressources d'information supplémentaires. Cette approche est particulièrement adaptée aux tâches qui dépendent fortement de l'expertise. Voici les principaux avantages du modèle RAG :
- Évolutivité : réduire la taille du modèle et les frais généraux de formation, tout en simplifiant le processus d'expansion et de mise à jour de la base de connaissances.
- Précision : en citant les sources, les utilisateurs peuvent vérifier la crédibilité des réponses, ce qui renforce leur confiance dans les résultats du modèle.
- Contrôlabilité : permet une mise à jour flexible et une configuration personnalisée du contenu des connaissances.
- Interprétabilité : montrer les entrées de recherche dont dépendent les prédictions du modèle, afin d'améliorer la compréhension et la transparence.
- Polyvalence : RAG peut être affiné et personnalisé pour s'adapter à un large éventail de scénarios d'application, couvrant des domaines tels que les questions-réponses, le résumé de texte et les systèmes de dialogue.
- Rapidité : l'utilisation de techniques d'extraction pour saisir les derniers développements de l'information garantit que les réponses sont à la fois immédiates et précises, ce qui constitue un avantage certain par rapport aux modèles linguistiques qui reposent uniquement sur des données de formation intrinsèques.
- Personnalisation des domaines : en associant des ensembles de données textuelles à des industries ou des domaines spécifiques, RAG est en mesure de fournir un soutien ciblé en matière d'expertise.
- Sécurité : en mettant en œuvre le partitionnement des rôles et le contrôle de la sécurité au niveau de la base de données, RAG renforce efficacement la gestion de l'utilisation des données, démontrant une plus grande sécurité que l'ambiguïté potentielle des modèles de réglage fin pour la gestion des droits sur les données.
V. Comparez RAG et SFT et dites-nous quelles sont les différences ?
En fait, SFT est l'une des solutions les plus courantes et les plus fondamentales aux problèmes ci-dessus de LLM, et c'est aussi une étape fondamentale dans la réalisation d'applications LLM. Il est donc nécessaire de comparer les deux approches dans plusieurs dimensions :
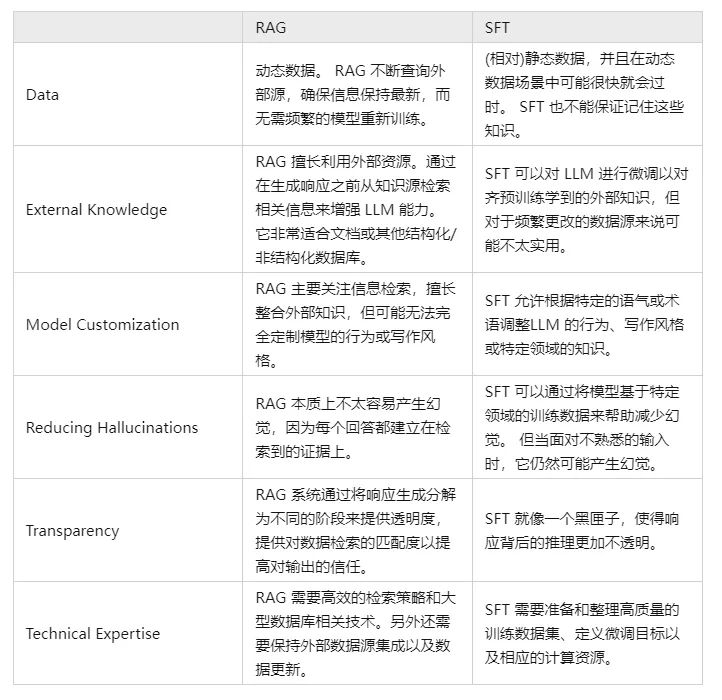
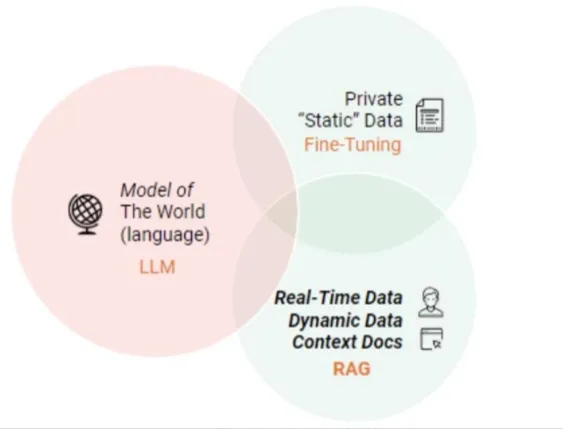
Bien entendu, ces deux méthodes ne sont pas l'une ou l'autre, et il est raisonnable et nécessaire de combiner les besoins de l'entreprise avec les avantages des deux méthodes et de les utiliser de manière raisonnable.
Module 1 : Analyse de la mise en page
Pourquoi ai-je besoin d'une analyse de la mise en page ?
Bien que la valeur fondamentale de la technologie RAG (Retrieval Augmented Generation) réside dans la combinaison de la recherche et de la génération pour améliorer la précision et la cohérence du contenu textuel, ses limites fonctionnelles peuvent être étendues pour inclure l'analyse de la mise en page dans des domaines d'application spécifiques, tels que l'analyse syntaxique de documents, la rédaction intelligente et la construction de dialogues, en particulier lorsqu'il s'agit de traiter des informations structurées ou semi-structurées.
En effet, ce type d'information est souvent intégré dans une structure de présentation spécifique et nécessite une compréhension approfondie des éléments de la page et de leurs relations.
En outre, lorsque le modèle RAG est confronté à des sources de données contenant des éléments multimédias ou multimodaux riches, tels que des pages web, des fichiers PDF, des enregistrements de texte riche, des documents Word, des données d'image, des clips vocaux, des données tabulaires et d'autres contenus complexes, il devient crucial de disposer d'une capacité d'analyse de base de la mise en page afin d'être en mesure d'ingérer et d'utiliser efficacement ces informations non textuelles. Cette capacité aide le modèle à analyser avec précision les différentes unités d'information et à les intégrer avec succès dans une interprétation globale significative.
étape 1 : acquisition de documents sur les connaissances locales
q1 : Comment procéder à l'acquisition de documents sur les connaissances locales ?
L'accès aux fichiers de connaissances locales implique le processus d'extraction d'informations à partir de sources de données multiples (par exemple, .txt, .pdf, .html, .doc, .xlsx, .png, .jpg, fichiers audio, etc.) Pour les différents types de fichiers, des stratégies d'accès et d'analyse spécifiques sont nécessaires pour obtenir efficacement les connaissances qu'ils contiennent. Dans ce qui suit, nous présentons les méthodes d'accès et les difficultés rencontrées pour les différentes sources de données.
q2 : Comment obtenir le contenu d'un texte enrichi ?
- Introduction : le texte enrichi est principalement stocké dans le fichier txt, parce que la mise en page est relativement soignée, de sorte que la manière d'obtenir le texte enrichi est relativement simple.
- Compétences pratiques :
- [Analyse de la mise en page - lecture de texte enrichi]
q3 : Comment obtenir le contenu d'un document PDF ?
- Introduction : Les documents PDF contiennent des données plus complexes, y compris du texte, des images, des tableaux et d'autres styles de données différents, de sorte que le processus d'analyse est plus complexe !
- Compétences pratiques :
- Analyse de la mise en page - PDF parser pdfplumber
- Analyse de la mise en page--PDF Parser PyMuPDF
q4 : Comment obtenir le contenu d'un document HTML ?
- Introduction : Les documents PDF contiennent des données plus complexes, y compris du texte, des images, des tableaux et d'autres styles de données différents, de sorte que le processus d'analyse est plus complexe !
- Compétences pratiques :
- Analyse de la mise en page - HTML Parsing BeautifulSoup
q5 : Comment obtenir le contenu d'un document Doc ?
- Introduction : Les données du document Doc sont plus complexes, incluant du texte, des images, des tableaux et d'autres styles de données différents, le processus d'analyse est donc plus complexe !
- Compétences pratiques :
- Analyse de la mise en page--Artéfact d'analyse documentaire python-docx]
q6 : Comment utiliser l'OCR pour obtenir le contenu d'une image ?
- Introduction : Reconnaissance Optique de Caractères (Optique) Caractère La reconnaissance optique de caractères (OCR) est le processus d'analyse et de reconnaissance de fichiers d'images contenant des informations textuelles afin d'obtenir des informations textuelles et de mise en page. Cela signifie également que le texte de l'image est reconnu et restitué sous forme de texte.
- Réflexions :
- Reconnaissance de texte : reconnaissance de zones de texte bien localisées, le problème principal étant de résoudre le problème de la nature de chaque texte, la zone de texte de l'image étant convertie en informations sur les caractères.
- Détection de texte : le problème résolu est de savoir où il y a du texte et quelle est l'étendue du texte ;
- Projet actuel d'OCR à code source ouvert
- Tesseract
- PaddleOCR
- EasyOCR
- chinoisocr
- chineseocr_lite
- TrWebOCR
- cnocr
- hn_ocr
- Études théoriques :
- Analyse de la mise en page - Picture Parser OCR]
- Compétences pratiques :
- [Analyse de la mise en page - OCR tesseract].
- [Analyse de la mise en page - OCR Magic PaddleOCR]
- [Analyse de la mise en page - Artéfacts OCR hn_ocr]
q7 : Comment utiliser l'ASR pour obtenir un contenu vocal ?
- Alias : Reconnaissance automatique de la parole Reconnaissance automatique de la parole (ASR)
- Introduction : la conversion d'un signal vocal en un message textuel correspondant est comme le "système auditif d'une machine", qui permet à la machine de transformer le signal vocal en un texte ou une commande correspondant par le biais de la reconnaissance et de la compréhension.
- Objectif : Convertir le contenu lexical de la parole humaine en données lisibles par l'ordinateur (par exemple : frappes de touches, codes binaires ou séquences de caractères).
- Réflexions :
- Prétraitement du signal acoustique : afin d'extraire les caractéristiques plus efficacement, il est souvent nécessaire de filtrer le signal sonore capturé, de le cadrer et d'effectuer d'autres travaux de prétraitement, le signal devant être analysé à partir de l'extraction du signal d'origine ;
- Extraction des caractéristiques : conversion du signal sonore du domaine temporel au domaine fréquentiel afin de fournir des vecteurs de caractéristiques appropriés pour le modèle acoustique.
- Modélisation acoustique : calcul d'un score pour chaque vecteur de caractéristiques sur les caractéristiques acoustiques basées sur les propriétés acoustiques.
- Modélisation du langage : calcul de la probabilité que le signal sonore corresponde à une séquence de phrases possibles, sur la base de théories linguistiques pertinentes.
- Dictionnaire et décodage : sur la base du dictionnaire existant, la séquence de phrases est décodée pour obtenir la représentation finale possible du texte.
- Tutoriel théorique :
- Reconnaissance vocale pour l'analyse de la mise en page
- Compétences pratiques :
- [Analyse de la mise en page du discours vers le texte]
- Analyse de la mise en page de WeTextProcessing
- [Analyse de la mise en page - Outil ASR Wenet]
- Analyse de la mise en page Formation ASR
étape 2 : récupération des documents de connaissance
q1 : Pourquoi est-il nécessaire de récupérer les documents de connaissance ?
L'acquisition de documents de connaissance locale contient après la lecture de données multi-sources (txt, pdf, html, doc, excel, png, jpg, voice, etc.), il est facile de diviser un paragraphe de plusieurs lignes en plusieurs paragraphes, ce qui conduit à des rencontres de paragraphes à diviser, il est donc nécessaire de réorganiser les paragraphes en fonction de la logique du contenu.
q2 : Comment puis-je récupérer des documents de connaissance ?
- Méthodologie I : Récupération des documents de connaissance basée sur des règles
- Méthode 2 : épissage contextuel basé sur la PSN de Bert
Étape 3 : Analyse de la présentation - Stratégies d'optimisation
- Études théoriques :
- [Analyse de la mise en page - Stratégies d'optimisation]
étape 4 : devoirs
- Description de la tâche : utiliser la méthodologie ci-dessus pour analyser la disposition du [ChatGLM Evaluation Challenge - Finance Track dataset] du [SMP 2023 ChatGLM Finance Big Model Challenge].
- Efficacité de la tâche : analyse de l'efficacité et de la performance des différentes méthodes
Module II : Construire la base de connaissances
Pourquoi avez-vous besoin de créer une base de connaissances ?
La construction d'une base de connaissances en RAG (Retrieval-Augmented Generation) est essentielle pour plusieurs raisons, dont les suivantes :
- Extension des capacités du modèle : bien que les modèles linguistiques à grande échelle tels que la famille GPT disposent de puissantes capacités de génération et de compréhension du langage, ils sont limités par la couverture de l'ensemble de données d'apprentissage et peuvent ne pas être en mesure de répondre avec précision à certaines questions basées sur des faits spécifiques ou des informations contextuelles détaillées. En construisant une base de connaissances, RAG peut compléter les limites de connaissances du modèle, permettant au modèle de récupérer les informations les plus récentes et les plus précises pour générer des réponses.
- Mise à jour des informations en temps réel : la base de connaissances peut être mise à jour et enrichie en temps réel pour garantir que le modèle a accès aux connaissances les plus récentes, ce qui est particulièrement important pour traiter les informations sensibles au temps, telles que les événements d'actualité, les avancées scientifiques et technologiques, etc.
- Précision accrue : le RAG combine les processus de recherche et de génération afin d'améliorer la précision des réponses aux questions en recherchant les documents pertinents avant de générer les réponses. Ainsi, les réponses générées par le modèle sont basées non seulement sur ses connaissances paramétrées internes, mais aussi sur une base de connaissances externe de sources fiables.
- Réduction de l'ajustement excessif et de l'hallucination : les grands modèles peuvent parfois souffrir d'une confiance excessive dans les modèles intrinsèques et souffrir d'hallucination, c'est-à-dire générer des réponses qui semblent raisonnables mais qui ne le sont pas. Les RAG peuvent réduire la probabilité de telles erreurs en citant des preuves définitives tirées de la base de connaissances.
- Interprétabilité améliorée : le RAG ne fournit pas seulement la réponse, mais indique également la source de la réponse, ce qui améliore la transparence et la crédibilité des résultats générés par le modèle.
- Prise en charge des besoins de personnalisation et de privatisation : les entreprises ou les utilisateurs individuels peuvent créer des bases de connaissances exclusives pour répondre aux besoins de domaines spécifiques ou de personnalisation privée, ce qui permet au grand modèle de mieux répondre à des scénarios et à des activités spécifiques.
En résumé, la construction d'une base de connaissances est l'un des principaux mécanismes permettant aux modèles RAG d'obtenir une recherche et une génération de réponses efficaces et précises, ce qui améliore considérablement les performances et la fiabilité du modèle dans les applications pratiques.
étape 1 : découpage du texte de connaissance
- Pourquoi dois-je découper le texte en morceaux ?
- Risque d'informations manquantes : en essayant d'extraire les vecteurs d'intégration pour l'ensemble du document en une seule fois, tout en saisissant le contexte général, on risque de passer à côté d'un grand nombre d'informations importantes qui sont spécifiques à un sujet, ce qui peut entraîner la production d'informations moins précises ou manquantes.
- Limitation de la taille des morceaux : la taille des morceaux est un facteur limitant essentiel lors de l'utilisation de modèles tels que OpenAI. Par exemple, le modèle GPT-4 a une limite de taille de fenêtre de 32K. Bien que cette limite ne soit pas un problème dans la plupart des cas, il est important de prendre en compte la taille des morceaux dès le début.
- Deux facteurs principaux sont à prendre en considération :
- Cas de restriction des jetons pour les modèles d'intégration ;
- L'effet de l'intégrité sémantique sur l'efficacité globale de la recherche ;
- Compétences pratiques :
- [Construction d'une base de connaissances - regroupement de textes de connaissances].
- [Construction de la base de connaissances - Stratégies d'optimisation du découpage des documents].
étape 2 : vectorisation des documents (embdeeing)
q1 : Qu'est-ce que la vectorisation des documents (embdeeing) ?
L'intégration est également une représentation à forte intensité d'information de la signification sémantique d'un texte, où chaque intégration est un vecteur de nombres à virgule flottante de sorte que la distance entre deux intégrations dans l'espace vectoriel est en corrélation avec la similarité sémantique entre les deux entrées dans le format d'origine. Par exemple, si deux textes sont similaires, leurs représentations vectorielles devraient également être similaires, et cet ensemble de représentations dans l'espace vectoriel décrit les différences subtiles entre les textes. En d'autres termes, l'intégration aide les ordinateurs à comprendre le "sens" de l'information humaine. L'intégration peut être utilisée pour obtenir la "pertinence" des caractéristiques d'un texte, d'une image, d'une vidéo ou d'autres informations, ce qui est couramment utilisé au niveau de l'application dans la recherche, la recommandation, la classification et d'autres applications. Ce type de corrélation est couramment utilisé dans la recherche, la recommandation, la classification et le regroupement.
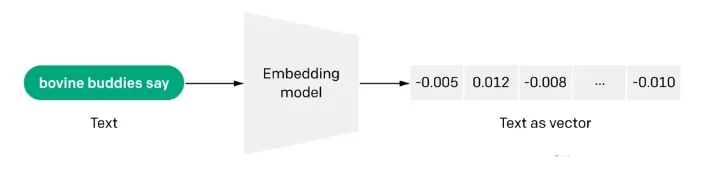
q2 : Comment fonctionne l'intégration ?
A titre d'exemple, voici trois phrases :
- "Le chat poursuit la souris.
- "Le chaton chasse les rongeurs".
- "J'aime les sandwichs au jambon." J'aime les sandwichs au jambon.
Si les êtres humains devaient classer ces trois phrases, la phrase 1 et la phrase 2 auraient presque le même sens, tandis que la phrase 3 serait complètement différente. Mais nous constatons que dans les phrases anglaises originales, seul "The" est identique dans la phrase 1 et la phrase 2, et qu'aucun autre mot n'est identique. Comment un ordinateur peut-il comprendre la pertinence des deux premières phrases ? L'intégration comprime des informations discrètes (mots et symboles) en données distribuées à valeur continue (vecteurs). Si l'on représentait la phrase précédente sur un graphique, cela pourrait ressembler à ceci :
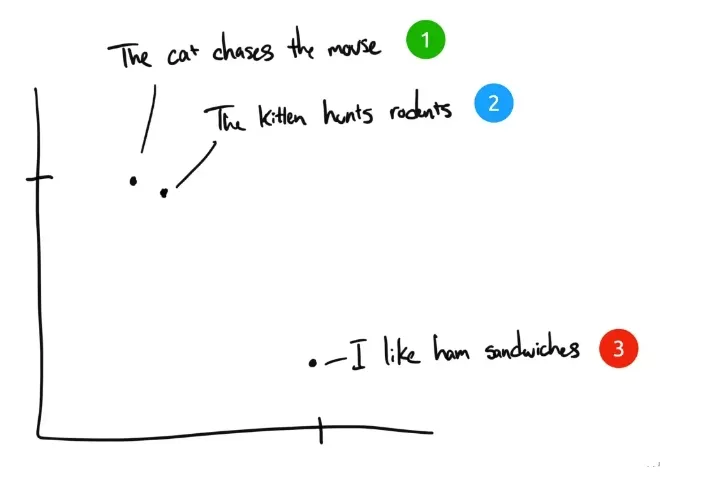
Une fois le texte compressé par Embedding dans un espace vectoriel multidimensionnel compréhensible par l'ordinateur, les phrases 1 et 2 sont représentées l'une près de l'autre parce qu'elles ont des significations similaires. La phrase 3 est plus éloignée parce qu'elle n'est pas liée à ces deux phrases. Si nous avions une quatrième phrase, "Sally a mangé du fromage suisse", elle existerait probablement quelque part entre la phrase 3 (le fromage va sur les sandwichs) et la phrase 1 (les souris aiment le fromage suisse).
q3 : Avantages de l'approche de recherche sémantique d'Embedding par rapport à la recherche par mots-clés ?
- Compréhension sémantique : les méthodes d'extraction basées sur l'intégration représentent le texte par des vecteurs de mots, ce qui permet au modèle de saisir les associations sémantiques entre les mots, contrairement à l'extraction basée sur les mots-clés qui tend à se concentrer sur la correspondance littérale et peut ignorer les connexions sémantiques entre les mots.
- Tolérance aux erreurs : comme les méthodes basées sur l'intégration sont capables de comprendre la relation entre les mots, elles sont plus avantageuses pour traiter des cas tels que les fautes d'orthographe, les synonymes et les quasi-synonymes. Les méthodes de recherche basées sur les mots-clés sont relativement peu efficaces dans ce cas.
- Prise en charge de plusieurs langues : de nombreuses méthodes d'intégration peuvent prendre en charge plusieurs langues, ce qui facilite la recherche de textes dans plusieurs langues. Par exemple, vous pouvez utiliser une entrée en chinois pour interroger un contenu textuel en anglais, alors que les méthodes de recherche basées sur des mots-clés sont difficiles à mettre en œuvre.
- Compréhension contextuelle : les méthodes basées sur l'intégration sont plus avantageuses dans le cas de significations multiples d'un mot, car elles sont capables d'attribuer différentes représentations vectorielles aux mots en fonction du contexte. En revanche, les méthodes d'extraction basées sur les mots-clés peuvent ne pas être en mesure de distinguer correctement le sens d'un même mot dans différents contextes.
q4 : Quelles sont les limites de la recherche par incorporation ?
- Contraintes liées au nombre de mots en entrée : même si les fragments de texte qui correspondent le mieux à la requête sont sélectionnés à l'aide de la technologie d'incorporation pour servir de référence au modèle à grande échelle, la contrainte liée au nombre de mots existe toujours. Lorsque la recherche couvre un large éventail de textes, afin de contrôler la quantité de vocabulaire contextuel injecté dans le modèle, un seuil TopK K est généralement fixé pour les résultats de la recherche, mais cela pose inévitablement le problème de l'omission d'informations.
- Données textuelles uniquement : le GPT-3.5 et de nombreux modèles linguistiques à grande échelle ne disposent pas encore de capacités de reconnaissance d'images. Cependant, dans le processus de recherche de connaissances, de nombreuses informations clés dépendent souvent de la combinaison de graphiques et de textes pour être pleinement comprises. Par exemple, il est difficile de saisir avec précision la signification des diagrammes schématiques dans les documents universitaires et des tableaux de données dans les rapports financiers en se basant uniquement sur le texte.
- (b) Improvisation d'un grand modèle : lorsque la littérature pertinente extraite est insuffisante pour permettre à un grand modèle de répondre avec précision à une question, le modèle peut être soumis à un certain degré d'"improvisation", c'est-à-dire de spéculation et d'ajouts basés sur des informations limitées, afin de compléter la réponse au mieux de ses capacités.
- Études théoriques :
- [Construction de la base de connaissances - Vectorisation des documents]
- Compétences pratiques :
- [Docs Vectorisation - Tencent Word Vector]
- [Docs vectorisation - sbt]
- [Docs vectorisation - SimCSE]
- [Docs vectorisation - text2vec]
- [Docs vectorisation - SGPT]
- [Docs vectorisation -- BGE -- Smart Source open source le modèle vectoriel sémantique le plus fort]
- [Docs vectorisation - M3E : une intégration hybride à grande échelle].
étape 3 : création d'un index des documents
- présenter (qqn pour un emploi, etc.)
- Compétences pratiques :
- [Index de construction des documents - Faiss]
- [Docs build index - milvus]
- [Docs Construire des index - Elasticsearch]
Module 3 : Affiner le grand modèle
Pourquoi devons-nous affiner les grands modèles ?
En général, il y a plusieurs raisons d'affiner un grand modèle :
- La première raison est que le nombre de paramètres d'un grand modèle étant très élevé, le coût de sa formation est très important, et chaque entreprise se charge de former son propre grand modèle à partir de zéro, ce qui est très rentable ;
- La deuxième raison est que l'approche de l'ingénierie des invites est un moyen relativement facile de commencer avec les grands modèles, mais elle présente des inconvénients évidents. Étant donné que les principes de mise en œuvre des grands modèles imposent généralement des restrictions sur la longueur de la séquence d'entrée, l'approche de l'ingénierie des invites peut rendre l'invite très longue.
Plus la Prompt est longue, plus le coût d'inférence du grand modèle est élevé, car le coût d'inférence est positivement corrélé au carré de la longueur de la Prompt. En outre, si l'invite est trop longue, elle sera tronquée parce qu'elle dépasse la limite, ce qui entraînera une réduction de la qualité de sortie du grand modèle. Pour les utilisateurs individuels, s'ils résolvent certains problèmes dans leur vie quotidienne et leur travail, l'utilisation directe de Prompt Engineering ne pose généralement pas de problème majeur. Cependant, pour les entreprises qui fournissent des services au monde extérieur, pour accéder à la capacité des grands modèles dans leurs propres services, le coût de raisonnement est un facteur qui doit être pris en compte, et le réglage fin est relativement une meilleure solution.
- La troisième raison est que l'effet de l'ingénierie rapide n'est pas à la hauteur des exigences, et que l'entreprise dispose de meilleures données propres, qui peuvent être utilisées pour améliorer la capacité du grand modèle dans le domaine spécifique. C'est à ce moment-là que la mise au point est très utile.
- La quatrième raison est l'utilisation de la puissance des grands modèles dans les services personnalisés, lorsque la formation d'un modèle léger et adapté aux données de chaque utilisateur est une bonne solution.
- La cinquième raison est la sécurité des données. Si les données ne doivent pas être transmises à un service de big model tiers, il est indispensable de créer son propre big model. En général, ces modèles de grande envergure à source ouverte doivent être affinés avec leurs propres données afin de répondre aux besoins de l'entreprise.
Comment affiner un grand modèle ?
q1 : La question de la mise au point des itinéraires techniques pour les grands modèles
La mise au point des grands modèles du point de vue de l'échelle des paramètres est divisée en deux itinéraires techniques :
- Itinéraire technique 1 : Pour l'ensemble des paramètres, l'ensemble de la formation, cet itinéraire est appelé réglage fin complet FFT (Full Fine Tuning).
- Voie technique II : seuls certains paramètres sont entraînés, cette voie est appelée PEFT (Parameter-Efficient Fine Tuning).
q2 : Quels sont les problèmes posés par la technique de réglage fin du volume complet pour les grands modèles ?
La FFT pose également certains problèmes, les plus importants étant les deux principaux suivants :
- Problème 1 : Le coût de la formation sera plus élevé parce que le nombre de paramètres pour le réglage fin est le même que pour le pré-entraînement ;
- Problème 2 : Oubli catastrophique (Catastrophic Forgetting), où le réglage fin avec des données de formation spécifiques peut améliorer les performances dans ce domaine, mais peut également détériorer les capacités dans d'autres domaines qui étaient performants.
q3 : Quels sont les problèmes résolus par PEFT (Parameter-Efficient Fine Tuning) pour les grands modèles ?
Le principal problème que PEFT cherche à résoudre est celui des deux problèmes susmentionnés de la FFT, et PEFT est également le programme de mise au point le plus répandu à l'heure actuelle. Du point de vue de la source des données d'entraînement et de la méthode d'entraînement, il existe plusieurs voies techniques pour le réglage fin des grands modèles :
- Voie technique 1 : Supervised Fine Tuning SFT (Supervised Fine Tuning), ce schéma se concentre sur le réglage fin de grands modèles avec des données étiquetées manuellement en utilisant l'approche traditionnelle de l'apprentissage supervisé dans l'apprentissage automatique ;
- Voie technique II : Apprentissage par renforcement avec retour d'information humain (RLHF), dont la principale caractéristique est d'introduire un retour d'information humain, par le biais de l'apprentissage par renforcement, dans le réglage fin du grand modèle, de sorte que les résultats générés par le grand modèle puissent être plus conformes à certaines des attentes humaines ;
- Route technologique III : Apprentissage par renforcement avec retour d'information de l'IA (RLAIF), le principe est à peu près similaire à RLHF, mais la source du retour d'information est l'IA. Il s'agit ici de résoudre le problème de l'efficacité du système de retour d'information, parce que la collecte d'un retour d'information humain, relativement parlant, sera plus coûteuse et moins efficace.
Les différentes perspectives de classification sont simplement des priorités différentes, et le réglage fin du même grand modèle n'est pas limité à un scénario particulier, mais peut concerner plusieurs scénarios à la fois. L'objectif ultime du réglage fin est de pouvoir améliorer les capacités du grand modèle dans un domaine particulier autant que possible à un coût gérable.
Qu'apprennent les grands modèles LLM lorsqu'ils effectuent des opérations SFT ?
- Pré-entraînement -> pré-entraînement sur de grandes quantités de données non supervisées pour obtenir un modèle de base -> utilisation du modèle pré-entraîné comme point de départ pour SFT et RLHF.
- SFT --> Effectuer la formation SFT sur des ensembles de données supervisés et optimiser le modèle en utilisant des signaux supervisés tels que des informations contextuelles --> Utiliser le modèle formé par SFT comme point de départ pour RLHF.
- RLHF --> Apprentissage par renforcement en utilisant le retour d'information humain pour optimiser le modèle afin qu'il corresponde mieux aux intentions et aux préférences humaines --> Évaluation et validation du modèle formé par RLHF et réalisation des ajustements nécessaires.
étape 1 : construction de données d'entraînement pour le réglage fin des grands modèles
- Introduction : Comment construire des données de formation ?
- Compétences pratiques :
- [Modèles à grande échelle (MGE) Méthodologie MGE pour la génération de données SFT].
Étape 2 : Mise au point des instructions du grand modèle
- Introduction : Comment construire des données de formation ?
- Compétences pratiques :
- [Pré-entraînement continu des grands modèles (LLM)].
- [Mise au point des instructions LLM].
- [Formation au modèle de récompense LLMs]
- Apprentissage par renforcement pour les grands modèles (LLM) - Chapitre de formation de l'OPP
- Apprentissage par renforcement pour les grands modèles (LLM) - Chapitre de formation de l'OPH
Module 4 : Recherche de documents
Pourquoi avez-vous besoin de Document Retrieval ?
Récupération de documents Comme il s'agit du travail central du RAG, son efficacité est cruciale pour le travail en aval. Bien qu'il soit possible d'améliorer la qualité de la réponse du modèle en rappelant des fragments de documents liés à la question de l'utilisateur à partir du référentiel de documents au moyen d'un rappel vectoriel et en les introduisant dans le LLM en même temps, il est possible d'améliorer la qualité de la réponse du modèle en rappelant des documents liés à la question de l'utilisateur. Une façon courante de rappeler des documents consiste à utiliser directement la question de l'utilisateur. Cependant, très souvent, la question de l'utilisateur est très familière et vaguement décrite, ce qui affecte la qualité du rappel vectoriel et donc la réponse du modèle. Ce chapitre présente principalement certains problèmes et les solutions correspondantes dans le processus de recherche de documents.
étape 1 : extraction de documents échantillon négatif échantillon minier
- INTRODUCTION : Dans tous les types de tâches de recherche, afin de former un modèle de recherche de bonne qualité, il est souvent nécessaire d'échantillonner des exemples négatifs de haute qualité à partir d'un large ensemble d'échantillons candidats, ainsi que des exemples positifs.
- Compétences pratiques :
- [Document Retrieval - Negative Sample Sample Mining] (en anglais)
étape 2 : stratégie d'optimisation de la recherche de documents
- Introduction : stratégies d'optimisation de la recherche documentaire
- Compétences pratiques :
- Recherche de documents - Stratégies d'optimisation pour la recherche de documents
Module V : Reranker
Pourquoi avez-vous besoin de Reranker ?
L'application RAG de base se compose de quatre éléments techniques clés :
- Modèles d'intégration : utilisés pour convertir les documents externes et les requêtes des utilisateurs en vecteurs d'intégration.
- base de données vectorielles: Utilisé pour stocker les vecteurs d'intégration et effectuer des recherches de similarité vectorielle (récupérer les éléments d'information Top-K les plus pertinents).
- Ingénierie des invites : entrées pour combiner les questions des utilisateurs et les contextes récupérés dans des modèles plus vastes
- Large Language Modelling (LLM) : pour générer des réponses
L'architecture RAG de base décrite ci-dessus résout efficacement le problème des LLM qui créent des "illusions" et génèrent un contenu peu fiable. Toutefois, certaines entreprises utilisatrices ont besoin d'architectures plus sophistiquées pour assurer la pertinence contextuelle et la précision des questions-réponses. Une approche éprouvée et populaire consiste à intégrer Reranker dans les applications RAG.
Qu'est-ce que le Reranker ?
Le Reranker est un élément important de l'écosystème de la recherche d'information (RI) pour évaluer les résultats de la recherche et les réorganiser afin d'améliorer la pertinence de la requête. Dans les applications RAG, le Reranker est principalement utilisé après avoir obtenu les résultats d'une requête vectorielle (ANN), ce qui permet une détermination plus efficace de la pertinence sémantique entre les documents et les requêtes, un reclassement plus fin des résultats et, en fin de compte, une amélioration de la qualité de la recherche.
Étape 1 : Reranker partiel
- Études théoriques :
- Recherche de documentation RAG - Section Reranker
- Compétences pratiques :
- [Reranker - chapitre bge-reranker]
Module 6 : Surfaces d'évaluation RAG
Pourquoi dois-je revoir le RAG ?
Dans le cadre de l'exploration et de l'optimisation des RAG (générateurs d'augmentation de la recherche), la question de l'évaluation efficace de leurs performances est devenue cruciale.
étape 1 : Examen du GCR
- Études théoriques :
- [Revue RAG]
Module 7 : Projet RAG Open Source Apprentissage recommandé
Pourquoi ai-je besoin de l'apprentissage recommandé du projet RAG Open Source ?
Après vous avoir fait découvrir les différents processus de RAG, voici quelques projets open source de RAG recommandés pour aider les grands garçons à assimiler et à apprendre.
Recommandations du projet Open Source RAG - Article RAGFlow
- Introduction : RAGFlow est un moteur RAG (Retrieval-Augmented Generation) open source basé sur une compréhension approfondie des documents. RAGFlow fournit un ensemble rationalisé de flux de travail RAG pour les entreprises et les individus de toutes tailles, combiné avec un Large Language Model (LLM) pour fournir des questions fiables, des réponses et des citations justifiées pour un large éventail de formats de données complexes. RAGFlow fournit un ensemble rationalisé de flux de travail RAG pour les organisations et les individus de toutes tailles, combiné à un Large Language Model (LLM) pour fournir des questions, des réponses et des citations justifiées fiables pour une large gamme de formats de données complexes.
- Projet d'apprentissage :
- Recommandations du projet RAG - RagFlow Partie I - Déploiement de RagFlow sur docker
- Recommandation du projet RAG - RagFlow Partie (2) - Construction de la base de connaissances RagFlow].
- Recommandation du projet RAG - RagFlow Partie III - Sélection du fournisseur du modèle RagFlow
- Recommandation du projet RAG - RagFlow Partie (4) - Dialogue RagFlow]
- Recommandation du projet RAG - RagFlow Part (V) - RAGFlow Api Access (to) ollama (par exemple)]
- Recommandation du projet RAG - RagFlow Partie (VI) - Apprentissage du code source de RAGFlow
Recommandations du RAG sur les projets Open Source - QAnything
- Introduction : QAnything (Question and Answer based on Anything) est un système de questions-réponses de base de connaissances locale conçu pour prendre en charge un large éventail de formats de fichiers et de bases de données, permettant une installation et une utilisation hors ligne. En utilisant QAnything, vous pouvez simplement supprimer des fichiers stockés localement dans n'importe quel format et obtenir des réponses précises, rapides et fiables.QAnything prend actuellement en charge les formats de fichiers de la base de connaissances, notamment : PDF(pdf) , Word(docx) , PPT(pptx) , XLS(xlsx) , Markdown(md) , Email (eml) , TXT (txt), Image (jpg, jpeg, png), CSV (csv), liens web (html) et ainsi de suite.
- Projet d'apprentissage :
- [Recommandations du projet open source RAG -- QAnything [Texte de référence].
Recommandations du projet Open Source RAG -- Article ElasticSearch-Langchain
- INTRODUCTION : Inspiré par le projet langchain-ChatGLM, puisque Elasticsearch peut réaliser des requêtes mixtes à la fois textuelles et vectorielles et est plus largement utilisé dans les scénarios d'entreprise, ce projet remplace Faiss par Elasticsearch en tant que référentiel de connaissances, et utilise Langchain+Chatglm2 pour mettre en œuvre un quiz intelligent basé sur la base de connaissances de Langchain+Chatglm2, en utilisant Langchain+Chatglm2. Q&A intelligent basé sur sa propre base de connaissances en utilisant Langchain+Chatglm2.
- Projet d'apprentissage :
- [LLMs Getting Started] Efficace 🤖ElasticSearch-Langchain-Chatglm2 Basé sur la Base de Connaissances Locale]
Recommandations du projet Open Source RAG - Article Langchain-Chatchat
- Introduction : Langchain-Chatchat (anciennement Langchain-ChatGLM) QA app with local knowledge based LLM (like ChatGLM) | Langchain-Chatchat (anciennement langchain-ChatGLM), QA app with local knowledge based LLM (like ChatGLM) LLM basé sur la connaissance locale (comme ChatGLM) QA app avec langchain
- Projet d'apprentissage :
- [LLMs Getting Started] Efficient 🤖Langchain-Chatchat Based on Local Knowledge Base] (en anglais)
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...