XTuner V1 - Moteur d'entraînement de grands modèles open source du Shanghai AI Lab

Qu'est-ce que XTuner V1 ?
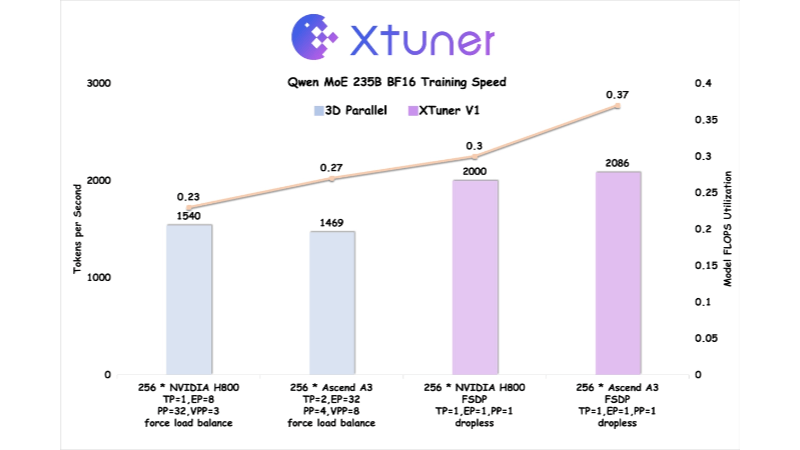
XTuner V1 est une nouvelle génération de moteur d'entraînement de grands modèles en libre accès par le laboratoire d'intelligence artificielle de Shanghai, conçu pour l'entraînement de modèles experts mixtes (MoE) à très grande échelle. Développé sur la base de PyTorch FSDP, XTuner V1 permet un apprentissage de haute performance grâce à l'optimisation multidimensionnelle de la mémoire, de la communication et de la charge, etc. XTuner V1 prend en charge l'apprentissage de modèles MoE comportant jusqu'à 1 000 milliards de paramètres, et dépasse pour la première fois la solution parallèle 3D traditionnelle en termes de débit d'apprentissage sur des modèles de plus de 200 milliards d'échelles. Il prend en charge l'apprentissage de séquences longues de 64k sans technologie de parallélisme de séquences, ce qui réduit considérablement la dépendance au parallélisme d'experts et améliore l'efficacité de l'apprentissage de séquences longues.
Caractéristiques de XTuner V1
- formation non destructiveLes modèles MoE à l'échelle de 200 milliards peuvent être formés sans parallélisme expert, et les modèles à l'échelle de 600 milliards ne nécessitent qu'un parallélisme expert à l'intérieur des nœuds.
- Prise en charge des longues séquencesLe système de gestion des séquences : Il permet l'apprentissage de 200 milliards de modèles MoE avec une longueur de séquence de 64k sans parallélisme des séquences.
- haute efficacitéLa nouvelle version de l'outil d'apprentissage des modèles MoE permet de prendre en charge l'apprentissage des modèles MoE avec 1 000 milliards de paramètres et un débit d'apprentissage de plus de 200 milliards de modèles par rapport au parallélisme 3D traditionnel.
- Optimisation de la mémoire vidéoLa technologie de la mémoire graphique : elle réduit les pics de mémoire graphique grâce au mécanisme de perte automatique de morceaux et à la technologie d'échange de points de contrôle asynchrone.
- couverture des communicationsLa technologie Domino-EP à l'intérieur des nœuds permet de réduire la consommation de temps de communication grâce à l'optimisation de la mémoire et à la technologie Domino-EP à l'intérieur des nœuds.
- Équilibrage de la charge DPLa recherche d'un équilibre de charge dans la dimension parallèle des données : atténuer le problème de la bulle vide informatique causée par l'attention de longueur variable et maintenir l'équilibre de la charge dans la dimension parallèle des données.
- Co-optimisation du matérielOptimisé sur le supernode Ascend A3 NPU en collaboration avec Huawei Rise, l'efficacité de l'entraînement dépasse celle du NVIDIA H800.
- Soutien aux logiciels libres et aux chaînes d'outilsXTuner V1, DeepTrace et ClusterX open source pour une prise en charge complète.
Principaux avantages de XTuner V1
- Une formation efficaceLa solution de formation de modèles MoE : elle prend en charge la formation de modèles MoE jusqu'à 1 000 milliards de paramètres, avec un débit de formation qui surpasse les solutions parallèles 3D traditionnelles pour les modèles à plus de 200 milliards d'échelles.
- Traitement des longues séquencesLa formation de 200 milliards de modèles MoE sur une longueur de séquence de 64k, sans parallélisme de séquence, convient aux scénarios de traitement de textes longs, tels que l'apprentissage par renforcement.
- faible besoin en ressourcesLes modèles paramétriques : 200 milliards de modèles paramétriques ne nécessitent pas de parallélisme expert, et 600 milliards de modèles ne nécessitent qu'un parallélisme expert dans le nœud, ce qui réduit les besoins en ressources matérielles.
- Optimisation de la mémoire vidéoLe dernier ajout au système est une nouvelle technologie qui réduit considérablement les pics de mémoire grâce à la perte automatique de morceaux et à l'échange asynchrone de points de contrôle, ce qui permet d'entraîner des modèles plus importants.
- optimisation des communicationsRéduire l'impact des frais généraux de communication sur l'efficacité de la formation en masquant la consommation de temps de communication grâce à l'optimisation de la mémoire et aux techniques Domino-EP intra-nœud.
- équilibrage de la chargeLe projet a pour objectif de : atténuer le problème de la bulle de calcul nulle causée par l'attention de longueur variable, assurer l'équilibre de la charge dans la dimension parallèle des données, et améliorer l'efficacité de la formation.
Quel est le site officiel de XTuner V1 ?
- Site web du projet: : https://xtuner.readthedocs.io/zh-cn/latest/
- Dépôt GitHub: : https://github.com/InternLM/xtuner
Personnes auxquelles XTuner V1 est destiné
- Chercheurs de grands modèlesXTuner V1 : Pour les chercheurs qui ont besoin d'entraîner des modèles d'expertise mixte (MoE) à très grande échelle, XTuner V1 fournit un moteur d'entraînement très performant qui prend en charge l'entraînement de modèles comportant jusqu'à 1 000 milliards de paramètres.
- Ingénieur en apprentissage profondPour les ingénieurs qui travaillent sur des formations distribuées à grande échelle, XTuner V1 offre des fonctions optimisées de communication et de gestion de la mémoire qui améliorent considérablement l'efficacité de la formation.
- Développeurs d'infrastructures d'IAPour les développeurs qui se concentrent sur la co-optimisation matérielle et le calcul de haute performance, XTuner V1 travaille avec l'équipe technologique Rise de Huawei pour fournir des optimisations profondes spécifiques au matériel.
- Les contributeurs de la communauté Open SourceLe code source ouvert de XTuner V1 offre de nombreuses possibilités de développement et d'optimisation aux développeurs qui s'intéressent aux projets open source et souhaitent y contribuer.
- Équipe Enterprise AIXTuner V1 fournit un support de chaîne d'outils facile à utiliser et très performant pour les équipes d'entreprise qui ont besoin d'une solution efficace et à bas seuil pour l'entraînement de grands modèles.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes

Pas de commentaires...