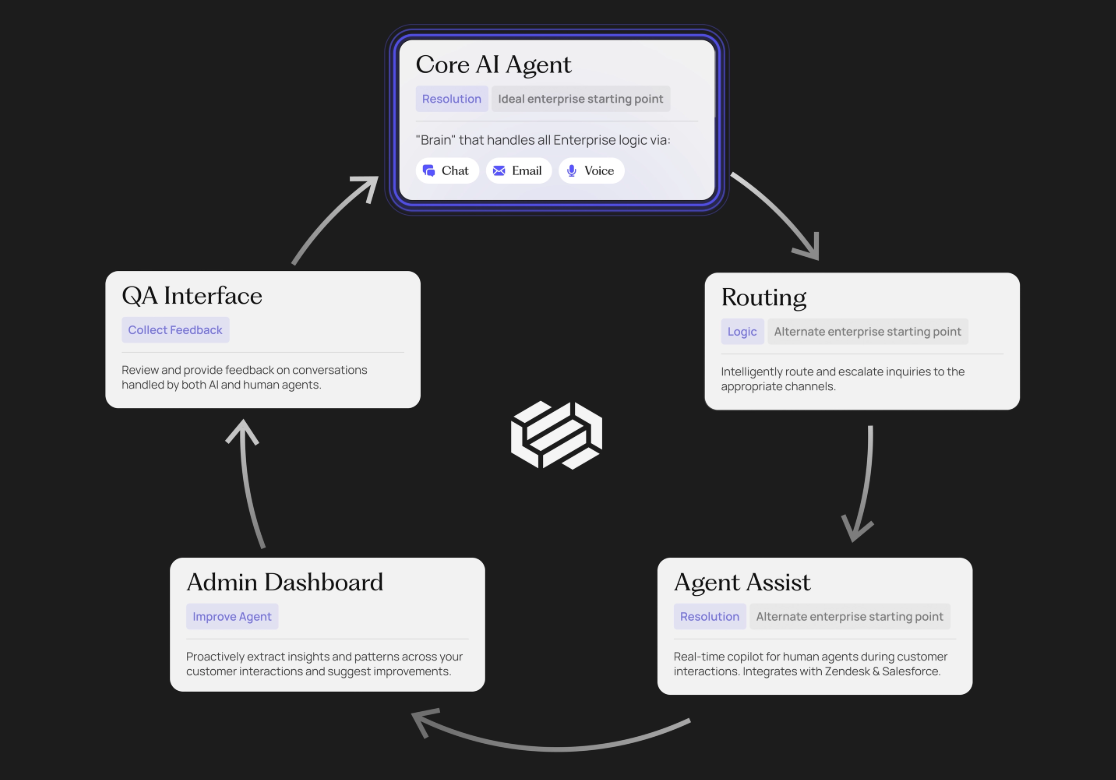
X-R1 : Formation à faible coût de modèles 0,5B dans des appareils courants
Introduction générale
X-R1 est un cadre d'apprentissage par renforcement ouvert sur GitHub par l'équipe dhcode-cpp, visant à fournir aux développeurs un outil efficace et peu coûteux pour former des modèles basés sur l'apprentissage par renforcement de bout en bout. Le projet est soutenu par Profondeur de l'eau-R1 Inspiré par X-R1 et open-r1, X-R1 se concentre sur la construction d'un environnement de formation facile à démarrer et peu gourmand en ressources. Le produit phare de X-R1 est R1-Zero, un modèle avec une covariance de 0,5B qui prétend être capable de se former efficacement sur du matériel courant. Il prend en charge plusieurs modèles de base (0,5B, 1,5B, 3B) et améliore l'inférence du modèle et le respect du format grâce à l'apprentissage par renforcement. Le projet est développé en C++ et combine vLLM Moteurs d'inférence et GRPO Algorithmes pour le raisonnement mathématique, le traitement des tâches chinoises et d'autres scénarios. Que vous soyez un développeur individuel ou un chercheur, X-R1 est une option open source qui vaut la peine d'être essayée.

Liste des fonctions
- Formation au modèle à faible coûtSupport pour l'entraînement de modèles R1-Zéro avec 0.5B paramètres sur du matériel commun (par exemple, 4 3090 GPUs).
- Optimisation de l'apprentissage renforcéAméliorer la capacité d'inférence et la précision du format de sortie des modèles grâce à l'apprentissage par renforcement (RL) de bout en bout.
- Prise en charge de plusieurs modèlesCompatible avec les modèles 0,5B, 1,5B, 3B et d'autres modèles de base, flexible pour s'adapter aux différentes exigences des tâches.
- Échantillonnage accéléré par le GPULe projet de loi sur la protection de l'environnement a été adopté par le Parlement européen.
- Raisonnement mathématique en chinoisLe programme d'enseignement de la langue chinoise : il soutient les tâches de raisonnement mathématique dans un environnement de langue chinoise, en générant des processus de réponse clairs.
- Évaluation comparative: Fournit des scripts benchmark.py pour évaluer la précision et les capacités de sortie de format du modèle.
- Configuration Open SourceLes paramètres de formation sont définis par l'utilisateur dans un fichier de configuration détaillé (par exemple, zero3.yaml).
Utiliser l'aide
X-R1 est un projet open source basé sur GitHub, les utilisateurs ont besoin de quelques bases de programmation et d'un environnement matériel pour l'installer et l'utiliser. Ce qui suit est un guide d'installation et d'utilisation détaillé pour vous aider à démarrer rapidement.
Processus d'installation
- Préparation de l'environnement
- exigences en matière de matérielAu moins 1 GPU NVIDIA (par exemple, 3090), 4 recommandés pour des performances optimales ; le CPU supporte le jeu d'instructions AVX/AVX2 ; au moins 16 Go de RAM.
- système d'exploitationLinux (par exemple Ubuntu 20.04+), Windows (nécessite la prise en charge de WSL2) ou macOS.
- Outils dépendantsInstaller Git, Python 3.8+, CUDA Toolkit (pour correspondre au GPU, par exemple 11.8), compilateur C++ (par exemple g++).
sudo apt update sudo apt install git python3 python3-pip build-essential - Pilote GPUPour plus d'informations sur les pilotes NVIDIA, reportez-vous à la section "Pilotes NVIDIA" du site Web de NVIDIA.
nvidia-smiVérifier.
- projet de clonage
Exécutez la commande suivante dans un terminal pour télécharger le référentiel X-R1 localement :git clone https://github.com/dhcode-cpp/X-R1.git cd X-R1 - Installation des dépendances
- Installer les dépendances de Python :
pip install -r requirements.txt - Installer Accelerate (pour la formation distribuée) :
pip install accelerate
- Installer les dépendances de Python :
- Environnement de configuration
- Modifiez le profil en fonction du nombre de GPU (par ex.
recipes/zero3.yaml), fixernum_processes(par exemple, 3, indiquant que 3 des 4 GPU sont utilisés pour l'entraînement et 1 pour l'inférence vLLM). - Exemple de configuration :
num_processes: 3 per_device_train_batch_size: 1 num_generations: 3
- Modifiez le profil en fonction du nombre de GPU (par ex.
- Vérifier l'installation
Exécutez la commande suivante pour vérifier que l'environnement est correctement configuré :accelerate configSuivez les invites pour sélectionner les paramètres de matériel et de distribution.
Principales fonctions
1. formation au modèle
- formation d'amorçageFormation du modèle R1-Zéro à l'aide de l'algorithme GRPO. Exécutez la commande suivante :
ACCELERATE_LOG_LEVEL=info accelerate launch \ --config_file recipes/zero3.yaml \ --num_processes=3 \ src/x_r1/grpo.py \ --config recipes/X_R1_zero_0dot5B_config.yaml \ > ./output/x_r1_0dot5B_sampling.log 2>&1 - Description fonctionnelleCette commande lance l'entraînement du modèle 0.5B et les enregistrements sont sauvegardés dans la base de données de la base de données.
outputDossier. Le processus de formation utilisera l'apprentissage par renforcement pour optimiser la capacité de raisonnement du modèle. - mise en gardeLa taille du lot global est de 1,5 million d'euros : assurez-vous que la taille du lot global (
num_processes * per_device_train_batch_size) peut êtrenum_generationsIntégrer, sinon une erreur sera signalée.
2. le raisonnement mathématique chinois
- Configuration des tâches mathématiquesPour le chinois : utiliser le fichier de configuration conçu pour le chinois :
ACCELERATE_LOG_LEVEL=info accelerate launch \ --config_file recipes/zero3.yaml \ --num_processes=3 \ src/x_r1/grpo.py \ --config recipes/examples/mathcn_zero_3B_config.yaml \ > ./output/mathcn_3B_sampling.log 2>&1 - flux de travail: :
- Préparez un ensemble de données de problèmes de mathématiques chinoises (par exemple au format JSON).
- Modifier le chemin d'accès au jeu de données dans le fichier de configuration.
- Exécutez la commande ci-dessus et le modèle générera le processus d'inférence et l'affichera dans le journal.
- Fonctions vedettesLes réponses en chinois sont détaillées et peuvent être utilisées dans des scénarios éducatifs.
3. l'étalonnage des performances
- Évaluation opérationnelle: Utilisation
benchmark.pyTester les performances du modèle :CUDA_VISIBLE_DEVICES=0,1 python ./src/x_r1/benchmark.py \ --model_name='xiaodongguaAIGC/X-R1-0.5B' \ --dataset_name='HuggingFaceH4/MATH-500' \ --output_name='./output/result_benchmark_math500' \ --max_output_tokens=1024 \ --num_gpus=2 - Interprétation des résultatsLe script produit les paramètres de précision et de format et enregistre les résultats sous la forme d'un fichier JSON.
- Scénarios d'utilisationLe projet a pour but d'améliorer la qualité de l'enseignement et de la formation dans le domaine des sciences de la vie.
compétence opérationnelle
- Vue du journalAprès la formation ou le test, vérifiez le fichier journal (par exemple, le fichier
x_r1_0dot5B_sampling.log) pour déboguer le problème. - Optimisation multi-GPUSi plus de GPU sont disponibles, vous pouvez ajuster le nombre de GPU.
num_processesrépondre en chantantnum_gpusafin d'améliorer l'efficacité parallèle. - détection des erreursEn cas d'erreur sur la taille du lot, ajuster la valeur de l'indicateur.
per_device_train_batch_sizerépondre en chantantnum_generationsFaites-le correspondre.
Recommandations d'utilisation
- Pour une première utilisation, il est recommandé de commencer par un modèle à petite échelle (par exemple 0,5B), puis de passer à un modèle 3B une fois que l'on s'est familiarisé avec le processus.
- Consultez régulièrement votre dépôt GitHub pour les mises à jour, les nouvelles fonctionnalités et les correctifs.
- Pour obtenir de l'aide, contactez le développeur à l'adresse dhcode95@gmail.com.
Grâce à ces étapes, vous pouvez facilement mettre en place un environnement X-R1 et commencer à former ou à tester des modèles. Que ce soit pour la recherche ou le développement, ce cadre offre un soutien efficace.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...