
Tutoriel sur le corps intelligent Wenxin : (4) Traitement des documents et synchronisation avec la base de connaissances

Introduction à la base de connaissances
La base de connaissances est la base de données pour les réponses de l'organisme intelligent. Elle convient aux développeurs qui accumulent des données de manière professionnelle, ainsi qu'à ceux qui ont des exigences en matière de précision et de professionnalisme pour les résultats des sorties.
Charger ses propres données dans le module de base de connaissances, le grand modèle et le processus d'interaction avec l'utilisateur, en fonction de la base de connaissances récupérée, le grand modèle est modifié pour générer les résultats, ce qui permet de limiter efficacement la portée de la génération de modèles.
Wenxin Intelligent Body Platform respecte et protège pleinement la sécurité de vos données propriétaires, et n'utilisera pas les données soumises pour former ou améliorer de grands modèles à usage général, et n'a pas ouvert de capacités de formation de modèles propriétaires pour l'instant.
文档同步到知识库-1")
1. scénario d'utilisation
- Développement des intelligences en code zéro avec des références à des bases de connaissances et une récupération limitée ;
- Citer la base de connaissances lors du développement des intelligences en code bas ;
- Citez la base de connaissances et développez rapidement des modules d'extension de données.
2. le portail de la base de connaissances
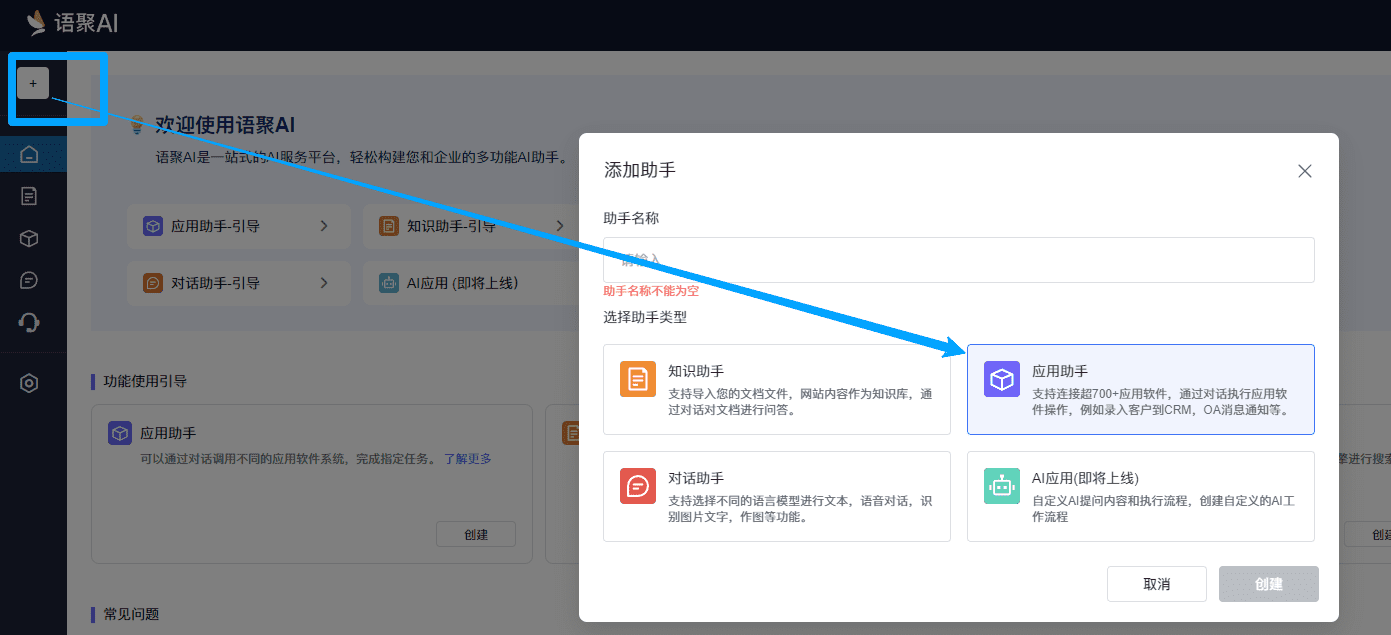
Entrée 1 : Après vous être connecté à la plateforme, cliquez sur la navigation de gauche pour accéder au module Base de connaissances.
文档同步到知识库-1")
Entrée 2 : Pour développer des intelligences à code zéro, sur la page Créer une intelligence, cliquez sur "Nouvelle base de connaissances" pour ajouter des données ;
加工文档并同步到知识库-1")
加工文档并同步到知识库-1")
Entrée 3 : Low-code development of intelligences, dans la page d'arrangement visuel, glisser-déposer le kit de base de connaissances, cliquer sur "New Knowledge Base" pour entrer dans le module de base de connaissances ;
加工文档并同步到知识库-1")
Entrée 4 : Pour développer un plugin de données, sur la page Modifier le plugin, cliquez sur "Nouvelle base de connaissances" pour accéder au module Base de connaissances.
加工文档并同步到知识库-1")
3. création d'une base de connaissances
Étape 1 : Téléchargement des données.
Il y a 3 façons de télécharger les données de la base de connaissances, ①upload local files, ②submit web address, ③Baidu.com.hk import. 1 compte peut créer 100 bases de connaissances, la capacité totale de toutes les bases de connaissances ne peut pas être plus de 1G, 1 base de connaissances peut être ajoutée à 100 fichiers ou URLs, et la capacité totale ne peut pas dépasser 200M.
①Les fichiers locaux
- Actuellement, seuls les types de texte et d'image sont pris en charge, notamment txt, md, docx, pdf, xlsx, csv, png, jpg, jpeg, m4a, mp3, mp4, mov, mpeg.Seul le téléchargement de vidéos est pris en charge, la reconnaissance de contenu vidéo n'est pas prise en charge pour le moment.
| type de données | surnom | Instructions de téléchargement |
|---|---|---|
| copies | texte | Taille du fichier n'excédant pas 50M |
| md | Taille du fichier n'excédant pas 50M | |
| docx | Taille du fichier n'excédant pas 50M | |
| Les graphiques ne sont pas pris en charge pour le moment ; les images contenues dans le fichier seront filtrées et seul le texte sera conservé. | ||
| Taille du fichier n'excédant pas 50M | ||
| Les graphiques ne sont pas pris en charge pour le moment ; les images contenues dans le fichier seront filtrées et seul le texte sera conservé. | ||
| La numérisation de documents jusqu'à 50 pages est possible. | ||
| xlsx | Taille du fichier n'excédant pas 50M | |
| Il est recommandé de télécharger les fichiers de données au format xlsx. Pour que le modèle puisse comprendre la signification des données après le fractionnement du fichier au format xlsx et qu'il puisse effectuer des recherches de données et des statistiques plus précises, le fichier xlsx téléchargé doit contenir des en-têtes de tableau. | ||
| csv | Taille du fichier n'excédant pas 50M | |
| photographie | png | 30px ≤ longueur du côté ≤ 4096px, dans un rapport 3:1, la taille ne peut pas dépasser 20M. |
| Jusqu'à 500 images peuvent être téléchargées dans une base de connaissances. | ||
| Des résultats de reconnaissance plus précis lorsque des objets physiques sont inclus dans l'image | ||
| jpg | 30px ≤ longueur du côté ≤ 4096px, dans un rapport 3:1, la taille ne peut pas dépasser 20M. | |
| Jusqu'à 500 images peuvent être téléchargées pour un ensemble de bases de connaissances. | ||
| Des résultats de reconnaissance plus précis lorsque des objets physiques sont inclus dans l'image | ||
| jpeg | 30px ≤ longueur du côté ≤ 4096px, dans un rapport 3:1, la taille ne peut pas dépasser 20M. | |
| Jusqu'à 500 images peuvent être téléchargées dans une base de connaissances. | ||
| Des résultats de reconnaissance plus précis lorsque des objets physiques sont inclus dans l'image | ||
| fréquence du son | m4a | Taille du fichier n'excédant pas 50M |
| Convertit l'audio en texte grâce à une reconnaissance intelligente | ||
| mp3 | Taille du fichier n'excédant pas 50M | |
| Convertit l'audio en texte grâce à une reconnaissance intelligente | ||
| vidéo | mp4 | Taille du fichier n'excédant pas 200M |
| Convertit la vidéo en texte grâce à une reconnaissance intelligente | ||
| déplacer | Taille du fichier n'excédant pas 200M | |
| Convertit la vidéo en texte grâce à une reconnaissance intelligente | ||
| mpeg | Taille du fichier n'excédant pas 200M | |
| Convertit la vidéo en texte grâce à une reconnaissance intelligente |
加工文档并同步到知识库-1")
②Soumission de site web
- Après avoir saisi l'adresse de la page web, cliquez sur le bouton "Identifier" pour identifier les données textuelles de la page web ; l'identification de l'adresse de la page web n'est possible que si elle est accessible au public et a été indexée par Baidu ; si vous devez vous connecter et accéder à la page, ou si vous n'êtes pas autorisé à être indexé par Baidu, l'identification de l'adresse de la page web échouera.
- Vous pouvez définir la fréquence de mise à jour de la base de connaissances par reconnaissance automatique en fonction de la fréquence de mise à jour des pages web.
加工文档并同步到知识库-1")
③Baidu.com Importation
- Pour la première fois, vous devez autoriser les données du compte Baidu.com, et vous pouvez sélectionner les fichiers dans le netbook une fois l'autorisation réussie.
- La durée de l'importation du netbook est limitée par la vitesse de téléchargement des fichiers du netbook. Si la durée est longue, vous pouvez choisir le traitement en arrière-plan.
加工文档并同步到知识库-1")
Étape 2 : Traitement des données.
Étant donné que le grand modèle impose des limites strictes aux caractères d'entrée et de sortie à ce stade et que la base de connaissances est également un type de contenu d'entrée, qui doit également respecter les limites du grand modèle quant au nombre de caractères d'entrée, l'objectif de la segmentation du texte est de découper le long texte en courts paragraphes, d'éliminer les informations non pertinentes et d'entrer le contenu le plus pertinent en veillant à ce que les caractères d'entrée ne dépassent pas la limite fixée. Afin de permettre au grand modèle de comprendre plus précisément le contenu de l'image, le modèle sera d'abord appelé à annoter intelligemment le contenu de l'image. Actuellement, 2 à 3 paragraphes de la base de connaissances peuvent être introduits dans le grand modèle, et le contenu pertinent doit être divisé en 3 paragraphes ou moins, dans la mesure du possible.
- Segmentation du texte : La plateforme propose une "segmentation par défaut" et une "segmentation personnalisée", qui permettent aux développeurs de découper un texte long en plusieurs segments de contenu textuel au moyen de texte, de ponctuation, d'espace, de retour à la ligne, etc. Lors du traitement de la segmentation, les caractères de segmentation maximum sont garantis d'être coupés selon la méthode de segmentation définie.
Romans, service clientèle et autres scénarios de contenu de questions-réponses, données et autres contenus, comment configurer des segments voir comment configurer des segments de fichiers (avec exemples)
加工文档并同步到知识库-1")
- Configuration du formulaire : L'en-tête du tableau du fichier de formulaire sera utilisé comme information clé pour que le grand modèle comprenne le contenu du tableau. Par défaut, la première ligne du tableau sera définie comme l'en-tête, qui peut être personnalisé en fonction de la structure réelle du tableau.
加工文档并同步到知识库-1")
- Paramètres multimédia : L'appel par défaut au grand modèle de l'image, au contenu audio pour une reconnaissance intelligente, et la génération d'une annotation textuelle, facilitant la récupération du lien vers l'image, la compréhension du contenu audio ainsi qu'une récupération plus précise du rappel. Si les informations d'annotation générées sont erronées, vous pouvez modifier manuellement le contenu erroné.Restez à l'écoute pour connaître les capacités de reconnaissance vidéo à venir !
加工文档并同步到知识库-1")
4. utilisation de la base de connaissances
Méthode 1 : Développement d'intelligences en code zéro, dans la page Créer un organisme de renseignement, sélectionnez Base de connaissances. Vous pouvez observer l'appel à la base de connaissances et optimiser l'effet de rappel de la base de connaissances en déboguant les paramètres d'extraction. Pour plus de détails, voir : AQ commun de l'appel de la base de connaissances
加工文档并同步到知识库-1")
Méthode 2 : Développement d'intelligences en code bas, dans la page d'orchestration visuelle, glisser-déposer la suite de bases de connaissances pour sélectionner la base de connaissances qui a été créée.
加工文档并同步到知识库-1")
Méthode 3 : Développer un plugin de données et sélectionner la base de connaissances qui a été créée.
加工文档并同步到知识库-1")
Comment mettre en place une segmentation des documents (avec des exemples)
1) Quand dois-je modifier un segment de document ?
- Données structurées
- Les résultats de Smartbody ou du plugin permettent d'accéder avec succès à la base de connaissances, mais contiennent trop d'informations non pertinentes.
2. comment configurer la segmentation des fichiers
L'objectif du traitement de la segmentation des données est de découper un texte long en paragraphes courts, en éliminant autant que possible les informations non pertinentes du contenu récupéré, afin qu'il puisse être traité et compris plus efficacement par le modèle.
Wenxin Intelligent Body Platform propose une segmentation par défaut et une segmentation personnalisée. Pour différents types de documents, différentes configurations de segmentation doivent être modifiées.
- Maximum Segment Characters : le nombre maximum de caractères dans un paragraphe après avoir coupé un long texte, au lieu du nombre de caractères dans chaque paragraphe, vous pouvez indiquer n'importe quel nombre entre 50 et 512 ;
加工文档并同步到知识库-1")
- Caractères de chevauchement des paragraphes : le nombre maximal de caractères répétables au début de chaque segment et à la fin du segment précédent, vous pouvez saisir un nombre compris entre 0 et 500. Notez que le nombre de caractères de chevauchement doit être inférieur au nombre maximal de caractères de paragraphe, afin de conserver autant que possible la sémantique originale des segments coupés, d'éviter l'expression d'une incomplétude due à la segmentation de l'énoncé, et d'aider le modèle à comprendre le modèle de manière plus précise et plus complète ;
加工文档并同步到知识库-1")
- Mode de segmentation : symboles de segmentation pour la découpe de textes longs, vous pouvez choisir les symboles de segmentation couramment utilisés ou saisir n'importe quel symbole, lors de la découpe du texte, la position de découpe sera sélectionnée en fonction du classement des symboles de segmentation.
加工文档并同步到知识库-1")
Note : Le nombre de segments d'une même base de connaissances ne peut excéder 700w, il convient donc de fixer le nombre de segments de manière raisonnable.
3. cas segmentés
Cas 1 : segmentation du contenu d'un texte long
Champ d'application : les cas sont applicables aux romans, aux livres électroniques, aux textes, aux présentations d'entreprises, aux thèses, aux documents de brevet, etc., qui nécessitent que le modèle comprenne la sémantique dans le contexte du contenu du texte long.
Exemple de fichier :L'homme en costume.docx
Pensées segmentées :
Segmentation par défaut recommandéeLes résultats spécifiques de la segmentation peuvent être visualisés en téléchargeant le fichier d'exemple et en créant une base de connaissances.
- Nombre maximal de caractères de paragraphe : les paragraphes d'un texte long sont généralement plus longs, et il existe des relations entre les paragraphes, de sorte que le nombre maximal de caractères de paragraphe peut être légèrement augmenté, afin de s'assurer que le paragraphe contient une sémantique complète et que le modèle peut être mieux compris et plus précis.
- Caractères de chevauchement de paragraphe : lorsque les paragraphes doivent être compris dans leur contexte, les caractères de chevauchement de paragraphe peuvent être remplis si nécessaire pour tenter d'afficher dans un seul paragraphe le contenu pertinent entre les contextes.
- Segmentation : la segmentation par défaut des symboles de segmentation contient essentiellement la plupart de la segmentation du texte, les résultats de la segmentation ne sont pas appropriés, vous pouvez visualiser le document approprié pour couper l'emplacement des symboles, sélectionner ou taper pour ajouter les symboles de segmentation, sera conforme à l'ordre des symboles de segmentation pour sélectionner la coupe.
Idées d'optimisation du suivi : essayez de faire en sorte que le texte ayant la même sémantique soit coupé dans un seul paragraphe.Si un paragraphe ne peut être divisé en un seul paragraphe en raison de la limitation du nombre de caractères dans le paragraphe, la corrélation entre les paragraphes peut être effectuée par le biais des caractères qui se chevauchent dans les paragraphes, de sorte que le modèle peut augmenter la probabilité d'être récupéré en même temps lors de la récupération et de la compréhension globale des résultats de sortie.
Résultats de la recherche de modèles :
加工文档并同步到知识库-1") Résultats de l'extraction du modèle :
Résultats de l'extraction du modèle :
加工文档并同步到知识库-1")
Cas 2 : Segmentation structurelle du contenu
Champ d'application : le cas s'applique aux enregistrements de chat du service clientèle, aux entretiens de vente et à d'autres scénarios de questions et réponses, aux formulaires de texte, etc.Le contenu des caractéristiques structurelles distinctivesBesoin de modèlesComprendre la sémantique du contenu au sein d'une structure.
Exemple de fichier :Wenxin Intelligent Body Platform FAQ.docx
Pensées segmentées :
Il est recommandé d'utiliser la segmentation personnalisée, pour essayer de garantir que la même structure au sein du texte soit coupée dans un paragraphe.Les résultats spécifiques de la segmentation peuvent être visualisés en téléchargeant le fichier d'exemple et en créant une base de connaissances.
- Nombre maximal de caractères de paragrapheLe nombre maximum de caractères sera fixé à combien de paragraphes. Il est probable que l'on choisisse quelques paragraphes représentatifs pour calculer le nombre moyen de caractères. Par exemple, le document d'exemple est une structure de questions-réponses, il y a 2 paragraphes, le nombre moyen de caractères est de 340 caractères, le nombre maximum de caractères du paragraphe est fixé à 340 caractères.
- paragraphe caractère superposéSi les paragraphes ne peuvent être divisés en un seul paragraphe en raison de la limitation du nombre de caractères, les caractères qui se chevauchent peuvent être utilisés pour associer les paragraphes, de sorte que le modèle puisse augmenter la probabilité d'être récupéré en même temps lors de la récupération de la compréhension globale des résultats de sortie.
- segmentationLa structure du document est plus distincte, chaque groupe de questions et de réponses est marqué "question", "réponse", et nous espérons être en accord avec la structure de segmentation d'une question et d'une réponse, vous pouvez "question" comme symbole de segmentation, et dans le symbole "question" avant la segmentation, vous pouvez obtenir les résultats de la structure de la segmentation d'une question et d'une réponse.
Résultats de la recherche de modèles :
加工文档并同步到知识库-1") Résultats de l'extraction du modèle :
Résultats de l'extraction du modèle :
加工文档并同步到知识库-1")
Cas 3 : Segmentation du contenu d'une classe de données Excel
Champ d'application : les cas s'appliquent à desRequête de données, catégorie de statistiques de donnéesde la classe de données du tableau Excel, ligne par ligne, sans corrélation autre que statistique.
Exemple de fichier :Données sur le box-office des films pour 2023.xlsx
Pensées segmentées :
Si une analyse statistique est nécessaire, les données à calculer ensemble doivent être divisées en 1~3 segments autant que possible (le modèle actuel limite la base de connaissances à un maximum de 2 000 caractères), et essayer de garantir l'exhaustivité des données originales introduites dans le modèle, afin que les résultats statistiques finaux aient un taux d'exactitude élevé ;
Il est recommandé d'utiliser des segments personnalisés pour tenter de garantir l'exhaustivité des données brutes introduites dans le modèle, afin que les statistiques finales soient correctes.Les résultats spécifiques de la segmentation peuvent être visualisés en téléchargeant le fichier d'exemple et en créant une base de connaissances.
- Nombre maximal de caractères de paragraphe : pour garantir l'intégrité des paragraphes extraits, il est nécessaire de fixer le nombre maximal de caractères de paragraphe à la limite maximale de 512 caractères.
- Caractères de chevauchement de paragraphe : Afin de réduire le nombre de caractères d'un paragraphe occupés par des caractères de chevauchement, le caractère de chevauchement de paragraphe doit être fixé à zéro.
- Segmentation : les données de type tableau peuvent être coupées directement par ligne, le mode de segmentation sélectionne "line feed".
Optimisation ultérieure des idées de segmentationSi le modèle limite la base de connaissances à un maximum de 2 000 caractères, les données à calculer doivent être divisées en 1 à 3 paragraphes dans la mesure du possible. Pour les statistiques plus importantes, il est recommandé de télécharger une feuille de calcul Excel ne comportant pas plus de 2 colonnes afin de s'assurer que toutes les données requises pour les statistiques sont incluses dans les 3 paragraphes introduits dans le modèle.
Résultats de la recherche de modèles :
加工文档并同步到知识库-1") Permet de retoucher les résultats de la sortie :
Permet de retoucher les résultats de la sortie :
加工文档并同步到知识库-1")
Attention :
- Les en-têtes de tableaux sont importants pour la récupération des résultats segmentés.L'en-tête de la table de données doit donc avoir une sémantique claire et éviter d'utiliser des mots bizarres que le modèle ne peut pas comprendre.
- Pour les plug-ins ou les intelligences qui ont besoin d'une analyse statistique, vous devez ajouter les plug-ins ou les intelligences à l'analyse statistique.Des invites de commande indiquant des étapes de calcul détaillées peuvent améliorer la précision des résultats statistiques du modèle.
La base de connaissances appelle l'assurance qualité commune
Q1 : Lors de la prévisualisation de l'effet de l'appel à la base de connaissances, les messages "Exception de système" et "Exception de service" apparaissent, que dois-je faire ?
A : Désolé d'affecter votre expérience, "exception système", "exception de service" est juste une situation occasionnelle, vous pouvez essayer d'actualiser après l'invite, quitter la page actuelle pour la revisiter, vider le cache et d'autres moyens de réessayer, vous pouvez reprendre l'utilisation.
Q2 : Que faire si ma base de connaissances n'est pas rappelée ?
A : Il se peut qu'il n'y ait rien dans la base de connaissances qui corresponde à la question.Page de gestion de la base de connaissancesS'il n'y a pas de contenu pertinent, la base de connaissances peut être enrichie en fonction de la question ; s'il y a un contenu pertinent mais qu'il n'est pas rappelé, il peut être transféré à la Q3.
Q3 : J'ai du contenu pertinent dans ma base de connaissances, mais je reçois toujours un message disant "Aucune base de connaissances pertinente n'a été rappelée", comment puis-je rappeler ma base de connaissances ?
A : Ce problème peut être résolu par.
Tout d'abord, vous pouvez entrer dans lePage de gestion de la base de connaissancesS'il y a des problèmes sémantiques, le contenu peut être édité en premier lieu pour optimiser les problèmes sémantiques ;
加工文档并同步到知识库-1")
Deuxièmement, l'effet de rappel peut être débogué en abaissant le [seuil de pertinence de la recherche] par le biais de la fonction de configuration du rappel de la base de connaissances.Note : [Retrieve Relevance Threshold] prendra effet globalement pour le corps intelligent actuel, il est nécessaire d'intégrer la plupart des scénarios de demande pour effectuer la configuration, comme il suffit d'optimiser les cas individuels du problème, vous pouvez soumettre la réponse idéale par le biais du [Feedback] pour modifier le modèle afin de générer la réponse.
加工文档并同步到知识库-1")
加工文档并同步到知识库-1")
Q4 : Les résultats du rappel de la base de connaissances ne correspondent pas à la question de l'utilisateur, mais la valeur de pertinence donnée par le système est assez élevée.
A : Il y a trois façons d'essayer de résoudre ce problème :
1) Modifier le contenu du paragraphe relatif au rappel, supprimer la description correspondante, puis réexaminer la question de savoir s'il y a lieu de procéder à un rappel ;
2. déboguer la configuration de rappel de la base de connaissances, lorsque le rappel de résultats non pertinents dans les résultats de rappel, classés dans les derniers, vous pouvez essayer d'améliorer le [seuil de pertinence de récupération], de réduire le [nombre maximum de paragraphes rappelés], le [nombre maximum de caractères de paragraphe] ;
3) Si vous avez seulement besoin d'optimiser un exemple de problème, vous pouvez soumettre la réponse idéale via [Feedback] afin de modifier le modèle pour générer la réponse.
A : Il y a trois façons d'essayer de résoudre ce problème :
1) Modifier le contenu du paragraphe relatif au rappel, supprimer la description correspondante, puis réexaminer la question de savoir s'il y a lieu de procéder à un rappel ;
2. déboguer la configuration de rappel de la base de connaissances, lorsque le rappel de résultats non pertinents dans les résultats de rappel, classés dans les derniers, vous pouvez essayer d'améliorer le [seuil de pertinence de récupération], de réduire le [nombre maximum de paragraphes rappelés], le [nombre maximum de caractères de paragraphe] ;
3) Si vous avez seulement besoin d'optimiser un exemple de problème, vous pouvez soumettre la réponse idéale via [Feedback] afin de modifier le modèle pour générer la réponse.
加工文档并同步到知识库-1")
Q5 : Que faire lorsque seule une partie des résultats pertinents de la base de connaissances a été rappelée et que d'autres résultats souhaitent également être rappelés ?
A : Il y a deux façons d'essayer de résoudre ce problème :
1. en déboguant la configuration de rappel de la base de connaissances, vous pouvez essayer de réduire le [seuil de pertinence de la recherche], d'améliorer le [nombre maximum de paragraphes rappelés], le [nombre maximum de caractères de paragraphe] ;
2) Si vous avez seulement besoin d'optimiser un exemple de problème, vous pouvez modifier le modèle pour générer la réponse en soumettant la réponse idéale via [Feedback].
A : Il y a deux façons d'essayer de résoudre ce problème :
1. en déboguant la configuration de rappel de la base de connaissances, vous pouvez essayer de réduire le [seuil de pertinence de la recherche], d'améliorer le [nombre maximum de paragraphes rappelés], le [nombre maximum de caractères de paragraphe] ;
2) Si vous avez seulement besoin d'optimiser un exemple de problème, vous pouvez modifier le modèle pour générer la réponse en soumettant la réponse idéale via [Feedback].
加工文档并同步到知识库-1")
Q6 : Les résultats du rappel sont tous corrects, mais le résultat final n'a rien à voir avec ma base de connaissances, n'est-ce pas ?
A : Ce problème survient parce que le modèle filtre les résultats du rappel de la base de connaissances lorsqu'il embellit les réponses. Pour résoudre ce problème, essayez de compléter les paramètres de caractère des intelligences avec les exigences relatives à l'application de la base de connaissances. Exemple :
- Modèle 1 : Lorsque l'utilisateur pose une question, la base de connaissances doit être consultée, et si aucun résultat n'est obtenu, le message "Je suis désolé, je ne connais pas grand-chose à ce sujet, nous pouvons parler d'autre chose~" est affiché.
- Modèle 2 : Lorsqu'un utilisateur pose une question, la réponse est générée en classant par ordre de priorité les résultats tirés de la base de connaissances récupérée.
A : Ce problème survient parce que le modèle filtre les résultats du rappel de la base de connaissances lorsqu'il embellit les réponses. Pour résoudre ce problème, essayez de compléter les paramètres de caractère des intelligences avec les exigences relatives à l'application de la base de connaissances. Exemple :
- Modèle 1 : Lorsque l'utilisateur pose une question, la base de connaissances doit être consultée, et si aucun résultat n'est obtenu, le message "Je suis désolé, je ne connais pas grand-chose à ce sujet, nous pouvons parler d'autre chose~" est affiché.
- Modèle 2 : Lorsqu'un utilisateur pose une question, la réponse est générée en classant par ordre de priorité les résultats tirés de la base de connaissances récupérée.
加工文档并同步到知识库-1")
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...