
Le nouveau modèle de Microsoft : Phi-4 est là, avec des paramètres 14B comparables à des modèles à plus grande échelle

Avec seulement 14 milliards de paramètres (14B), Phi-4 démontre des performances comparables, voire supérieures, à certains modèles à plus grande échelle grâce à des méthodes d'apprentissage innovantes et à des données de haute qualité. Cet article décrit en détail l'architecture, les caractéristiques, la méthodologie d'apprentissage et les performances de Phi-4 dans des applications et des repères du monde réel.
https://github.com/xinyuwei-david/david-share.git
I. Examiner les indicateurs pour mesurer la capacité

Mesurer trois questions comparant o1 et Phi-4
Première question :
phi-4

o1

Deuxième question :
Phi-4.

o1 :
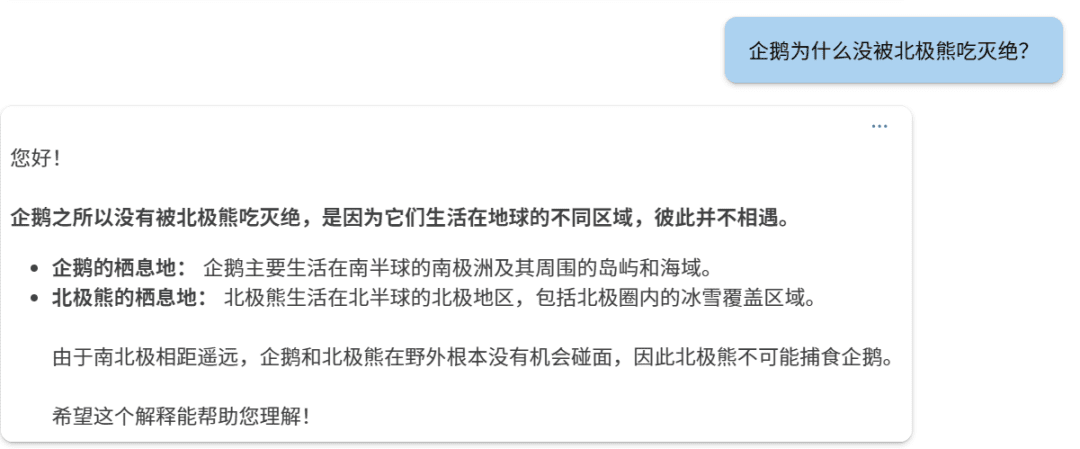
Troisième question :
Phi-4

o1.
要求五个连续偶数的平均数,已知它们的和为90,下面我们逐步解答。步骤1:设未知数设这五个连续的偶数为:第一个偶数:( n - 4 )第二个偶数:( n - 2 )第三个偶数:( n )第四个偶数:( n + 2 )第五个偶数:( n + 4 )(因为偶数之间相差2,所以相邻的偶数可以这样表示)步骤2:列方程求和根据题目,五个数的和为90:[(n - 4) + (n - 2) + n + (n + 2) + (n + 4) = 90]步骤3:简化方程合并同类项:[5n = 90]步骤4:求解 n[n = frac{90}{5} = 18]步骤5:求出五个偶数第一个偶数:( 18 - 4 = 14 )第二个偶数:( 18 - 2 = 16 )第三个偶数:( 18 )第四个偶数:( 18 + 2 = 20 )第五个偶数:( 18 + 4 = 22 )步骤6:计算平均数平均数等于总和除以数量:[text{平均数} = frac{14 + 16 + 18 + 20 + 22}{5} = frac{90}{5} = 18]答案:这五个连续的偶数的平均数是 18。
Si l'on considère les choses sous cet angle, le raisonnement de Phi-4 reste valable.
II. Phi-4 architecture du modèle
1. architecture du décodeur à transformateur
Phi-4 utilise un système basé sur la Transformateur (utilisé comme expression nominale) Décodeur uniquement Cette architecture est similaire à la famille de modèles GPT. Elle utilise le mécanisme d'auto-attention pour capturer efficacement les dépendances à long terme dans les séquences de texte et excelle dans les tâches de génération de langage naturel.
2. la taille des paramètres et le nombre de couches
- Nombre total de paramètres : 14 milliards d'euros (14B) Paramètres.
- Nombre d'étages du modèle : 40
3. longueur du texte
- Longueur initiale du contexte : 4,096 Jeton.
- Extension de la formation à moyen terme : Lors de la phase de formation intermédiaire, la longueur du contexte de Phi-4 a été étendue à 16,000 Token (16K), qui améliore la capacité du modèle à traiter les textes longs.
4. le glossaire et le lexateur
- Séparateurs : L'utilisation de l'outil Séparateur de tiktokenL'entreprise prend en charge le multilinguisme et offre un meilleur effet de sous-texte.
- Taille du glossaire : 100,352Cela inclut certains jetons réservés et non utilisés.
Mécanismes d'attention et codage de la localisation
1. les mécanismes d'attention globale
Phi-4 utilise Mécanisme de pleine attentionc'est-à-dire que l'auto-attention est calculée pour l'ensemble de la séquence de contextes. Cela contraste avec le modèle précédent, Phi-3-medium, qui utilise 2 048 Jeton de la fenêtre coulissante, tandis que Phi-4 effectue le calcul de l'attention globale directement sur les contextes de 4 096 tokens (initial) et de 16 000 tokens (étendu), améliorant ainsi la capacité du modèle à capturer les dépendances à longue portée.
2. le codage de la position rotative (RoPE)
Pour prendre en charge des contextes plus longs, Phi-4 a été adapté en milieu de formation pour Intégration de la position rotative (RoPE) de la fréquence de base :
- Réglage de la fréquence de base : Augmenter la fréquence de base de RoPE à 250,000pour tenir compte de la longueur de contexte de 16K.
- Rôle : Le RoPE aide le modèle à maintenir l'efficacité du codage positionnel dans les longues séquences, ce qui lui permet de conserver de bonnes performances sur des textes plus longs.
IV. stratégies et méthodes de formation
1. le concept de priorité à la qualité des données
La stratégie de formation pour Phi-4 est basée sur Qualité des données au cœur du modèle. Contrairement à d'autres modèles qui sont pré-entraînés en utilisant principalement des données organiques provenant de l'internet (par exemple, le contenu du web, le code, etc.), Phi-4 introduit stratégiquement tout au long du processus d'entraînement un modèle d'analyse de l'information. Données synthétiques.
2. la génération et l'application de données synthétiques
Données synthétiques a joué un rôle clé dans la préformation et la formation intermédiaire de Phi-4 :
- Techniques de génération de données multiples :
- Promesses multi-agents : La diversité des données est enrichie par l'utilisation de plusieurs modèles linguistiques ou d'agents pour co-générer les données.
- Flux de travail pour l'autorévision : Une fois que le modèle a généré le résultat initial, il procède à une auto-évaluation et à une correction afin d'améliorer de manière itérative la qualité du résultat.
- Inversion d'instruction : La génération d'instructions d'entrée correspondantes à partir des sorties existantes améliore la capacité du modèle à comprendre et à générer des instructions.
- Avantages des données synthétiques :
- Apprentissage structuré et progressif : Les données synthétiques permettent un contrôle précis de la difficulté et du contenu, guidant progressivement le modèle vers l'apprentissage de compétences complexes en matière de raisonnement et de résolution de problèmes.
- Améliorer l'efficacité de la formation : La génération de données synthétiques peut fournir des données d'entraînement ciblées pour les points faibles du modèle.
- Éviter la contamination des données : Comme les données synthétiques sont générées, le risque que les données d'apprentissage contiennent le contenu de l'ensemble d'examen est évité.
3. l'examen approfondi et le filtrage des données organiques
Outre les données synthétiques, Phi-4 se concentre sur la sélection et le filtrage minutieux de données de haute qualité provenant de sources multiples Données organiques: :
- Sources des données : Comprend du contenu Web, des livres, des bibliothèques de codes, des documents universitaires, et plus encore.
- Filtrage des données :
- Supprimer le contenu de mauvaise qualité : Utiliser des méthodes automatisées et manuelles pour filtrer les contenus inutiles, incorrects, dupliqués ou nuisibles.
- Prévenir la contamination des données : Un algorithme n-gram hybride (13-grammes et 7-grammes) a été utilisé pour la déduplication et la décontamination afin de s'assurer que les données d'entraînement ne contiennent pas de contenu provenant de l'ensemble des revues.
4. stratégie de mélange des données
Phi-4 a été optimisé dans la composition des données d'entraînement avec les ratios suivants :
- Données synthétiques : prendre possession de 40%.
- Réécritures Web : prendre possession de 15%Dans le cas d'un nouvel échantillon de formation, il est réécrit à partir d'un contenu Web de haute qualité pour générer un nouvel échantillon de formation.
- Données organiques sur le web : prendre possession de 15%Le contenu du site a été sélectionné pour sa valeur.
- Code Data : prendre possession de 20%y compris la base de code publique et les données de synthèse du code généré.
- Acquisitions ciblées : prendre possession de 10%y compris des articles universitaires, des livres professionnels et d'autres contenus de grande valeur.
5. processus de formation en plusieurs étapes
Phase de préformation :
- Objectif : Modélisation de la compréhension du langage de base et des compétences génératives.
- Volume de données : prendre un rendez-vous 10 000 milliards (10T) Jeton.
Phase de formation à moyen terme :
- Objectif : Extension de la longueur du contexte pour améliorer le traitement des textes longs.
- Volume de données : 250 milliards d'euros (250B) Jeton.
Phase de post-formation (mise au point) :
- L'ajustement fin supervisé (Supervised Fine Tuning - SFT) : La mise au point à l'aide de données multi-domaines de haute qualité améliore la capacité du modèle à suivre les instructions et la qualité des réponses.
- Optimisation directe des préférences (DPO) : utiliser Recherche de jetons Pivotal (PTS) et d'autres méthodes pour optimiser davantage les résultats du modèle.
V. Techniques de formation innovantes
1) Pivotal Token Search (PTS)
Méthodologie du STP est une innovation majeure dans le processus de formation Phi-4 :
- Principe : En identifiant les jetons clés qui ont un impact significatif sur l'exactitude de la réponse au cours du processus de génération, le modèle est ciblé pour optimiser la prédiction sur ces jetons.
- Avantage :
- Améliorer l'efficacité de la formation : En concentrant votre optimisation sur les parties qui ont le plus d'impact sur les résultats, vous êtes deux fois plus efficace.
- Amélioration des performances du modèle : Aide le modèle à faire les bons choix aux points de décision clés et améliore la qualité globale du résultat.
2. l'amélioration de l'optimisation des préférences directes (OPD)
- Méthode DPO : L'optimisation est effectuée directement à l'aide des données relatives aux préférences afin de rendre les résultats du modèle plus cohérents avec les préférences humaines.
- Points d'innovation :
- Combiné avec PTS : L'introduction de paires de données de formation générées par le STP dans le DPO améliore l'optimisation.
- Évaluation des indicateurs : Mesurer l'optimisation avec plus de précision en évaluant la performance du modèle sur des tokens clés.
VI. caractéristiques et avantages du modèle
1. d'excellentes performances
- Petits modèles, grandes capacités : Bien que l'échelle des paramètres ne soit que de 14BCependant, Phi-4 obtient de bons résultats dans plusieurs tests de référence, en particulier dans les tâches de raisonnement et de résolution de problèmes.
2. d'excellentes capacités de raisonnement
- Résolution de problèmes en mathématiques et en sciences : existent GPQA,MATH Dans les tests de référence tels que celui-ci, Phi-4 obtient des résultats encore meilleurs que ceux de son modèle enseignant. GPT-4o.
3. de longues capacités de traitement contextuel
- Extension de la longueur du contexte : En augmentant la durée du contexte à mi-parcours de la formation à 16,000 Token, Phi-4 est capable de traiter plus efficacement les textes longs et les dépendances à longue distance.
4. support multilingue
- Couverture de plusieurs langues : Les données d'apprentissage sont constituées des Allemand, espagnol, français, portugais, italien, hindi, japonais et de nombreuses autres langues.
- Compétence interlinguistique : Il excelle dans des tâches telles que la traduction et l'interrogation interlangues.
5. la sécurité et la conformité
- Principes de l'IA responsable : Le processus de développement suit strictement les principes de l'IA responsable de Microsoft, en se concentrant sur la sécurité et l'éthique du modèle.
- Décontamination des données et protection de la vie privée : Des stratégies strictes de déduplication et de filtrage des données sont utilisées pour éviter que des contenus sensibles ne soient inclus dans les données d'apprentissage.
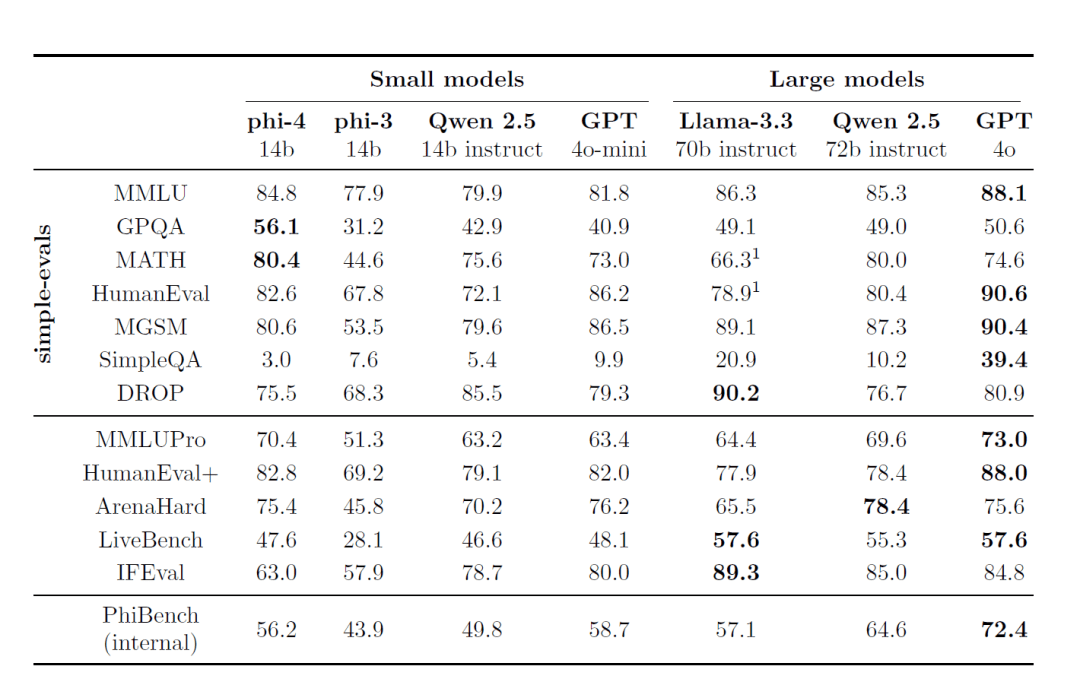
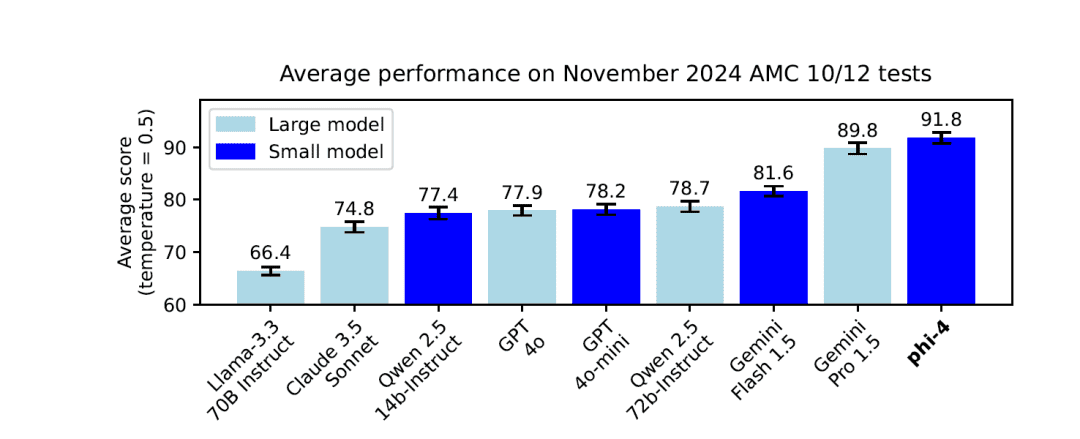
VII - Critères de référence et performances
1. l'étalonnage externe
Phi-4 démontre une performance de premier plan sur plusieurs critères d'évaluation accessibles au public :
- MMLU (Multitasking Language Understanding) : A obtenu d'excellents résultats dans des tests de compréhension complexes et multitâches.
- GPQA (Graduate level STEM quiz) : a excellé dans le difficile quiz STEM, obtenant un score plus élevé que certains des modèles à plus grande échelle.
- MATH (concours de mathématiques) : Dans la résolution de problèmes mathématiques, Phi-4 fait preuve d'une grande capacité de raisonnement et de calcul.
- HumanEval / HumanEval+ (génération de code) : Dans les tâches de génération et de compréhension de code, Phi-4 surpasse les modèles de sa taille et s'approche même des modèles plus grands.
2. suite d'évaluation interne (PhiBench)
Pour se faire une idée des capacités et des lacunes du modèle, l'équipe a mis au point une série d'évaluations internes spécialisées. PhiBench: :
- La tâche de la diversification : Comprend le débogage du code, l'achèvement du code, le raisonnement mathématique et l'identification des erreurs.
- Conseils sur l'optimisation des modèles : En analysant les scores de PhiBench, l'équipe a pu cibler les améliorations à apporter au modèle.
VIII. sécurité et responsabilité
1. stratégie d'alignement strict de la sécurité
Le développement de Phi-4 s'inscrit dans le cadre de la politique de Microsoft en matière de sécurité. Principes pour une IA responsableLa sécurité et l'éthique du modèle au cours de la formation et de la mise au point :
- Protection contre les contenus préjudiciables : Réduisez la probabilité que le modèle génère un contenu inapproprié en incluant des données de mise au point de la sécurité dans la phase de post-formation.
- Tests en équipe rouge et évaluation automatisée : Des tests approfondis en équipe rouge et des évaluations automatisées de la sécurité ont été réalisés, couvrant des dizaines de catégories de risques potentiels.
2. la décontamination des données et la prévention de l'ajustement excessif
- Amélioration des stratégies de décontamination des données : Un algorithme hybride de 13 et 7 grammes est utilisé pour éliminer tout chevauchement possible des données d'apprentissage avec les données de référence de l'examen et pour empêcher l'ajustement excessif du modèle.
IX. les ressources et le temps consacrés à la formation
1. le temps de formation
Bien que le rapport officiel ne précise pas la durée totale de l'entraînement pour le Phi-4, il faut tenir compte de ce qui suit :
- Échelle du modèle : 14B Paramètres.
- Volume des données de formation : Phase de préformation : jeton de 10T, phase de mi-formation : jeton de 250B.
On peut supposer que l'ensemble du processus de formation a pris un temps considérable.
2. la consommation de ressources du GPU
| GPU | 1920 H100-80G |
| Temps de formation | 21 jours |
| Données d'entraînement | 9.8T jetons |
X. Applications et limitations
1) Scénarios d'application
- Système de questions-réponses : Phi-4 est performant dans les tâches complexes de quiz et convient à toutes sortes d'applications de quiz intelligent.
- Génération et compréhension du code : Excellent dans les tâches de programmation et peut être utilisé dans des scénarios tels que le tutorat de code, la génération automatique et le débogage.
- Traduction et traitement multilingues : Soutien multilingue pour des services linguistiques mondialisés.
2. les limites potentielles
- Critères d'évaluation des connaissances : Les connaissances du modèle s'arrêtent aux données d'apprentissage et peuvent ne rien savoir des événements qui se produisent après l'apprentissage.
- Défi des longues séquences : Bien que la longueur du contexte soit étendue à 16K, des difficultés peuvent subsister lorsque l'on traite des séquences plus longues.
- Contrôle des risques : Malgré des mesures de sécurité rigoureuses, les modèles peuvent toujours faire l'objet d'attaques adverses ou de la génération par inadvertance de contenus inappropriés.
Le succès de Phi-4 démontre l'importance de la qualité des données et de la stratégie d'entraînement dans le développement de modèles linguistiques à grande échelle. Grâce à des méthodes innovantes de génération de données synthétiques, à des stratégies minutieuses de mélange de données d'entraînement et à des techniques d'entraînement avancées, Phi-4 atteint d'excellentes performances tout en conservant une taille de paramètres réduite :
- Les capacités de raisonnement sont remarquables : Excelle dans les domaines des mathématiques, des sciences et de la programmation.
- Traitement des textes longs : La longueur étendue du contexte confère au modèle un avantage dans les tâches de traitement de textes longs.
- Sécurité et responsabilité : Le strict respect des principes de l'IA responsable garantit que les modèles sont sûrs et éthiques.
Phi-4 établit une nouvelle référence dans le développement de petits modèles quantitatifs paramétriques, démontrant qu'en se concentrant sur la qualité des données et les stratégies de formation, des performances supérieures peuvent être obtenues même à des échelles de paramètres plus petites.
Références : /https://www.microsoft.com/en-us/research/uploads/prod/2024/12/P4TechReport.pdf
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...