
Un article de 10 000 mots pour clarifier le processus de développement du Text-to-SQL basé sur le LLM
OlaChat AI Digital Intelligence Assistant 10,000-word in-depth analysis, take you to understand the past and present of Text-to-SQL technology.
Thèse : Interfaces de base de données de nouvelle génération : une enquête sur les interfaces texte-SQL basées sur LLM
La génération d'un code SQL précis à partir de problèmes en langage naturel (text-to-SQL) est un défi de longue date en raison de la complexité de la compréhension du problème de l'utilisateur, de la compréhension du schéma de la base de données et de la génération du code SQL. Les systèmes traditionnels de conversion de texte en SQL, y comprisIngénierie artificielle et réseaux neuronaux profondsDes progrès substantiels ont été réalisés. Par la suite.Des modèles de langage pré-entraînés (PLM) ont été développés et utilisés pour les tâches de conversion de texte en SQL, avec des performances prometteuses. Les bases de données modernes étant devenues plus complexes, les problèmes des utilisateurs correspondants sont devenus plus difficiles à résoudre, ce qui a eu pour conséquence que les PLMs contraints par des paramètres (modèles pré-entraînés) ont généré des SQL incorrects, ce qui a nécessité des méthodes d'optimisation personnalisées plus sophistiquées, limitant ainsi l'application des systèmes basés sur les PLMs.
Récemment, les grands modèles de langage (LLM) ont démontré des capacités significatives dans la compréhension du langage naturel en raison de la croissance de la taille des modèles. Par conséquent, l'intégration d'implémentations basées sur les LLMLe LLM peut apporter des opportunités, des améliorations et des solutions uniques à la recherche sur la conversion de texte en SQL. Dans cette étude, le document présente une revue complète de la conversion de texte en SQL basée sur le LLM. En particulier, les auteurs présentent une brève vue d'ensemble des défis techniques et du processus d'évolution de la conversion de texte en SQL. Ensuite, les auteurs fournissent une description détaillée des ensembles de données et des mesures d'évaluation conçues pour évaluer les systèmes de conversion de texte en SQL. Ensuite, l'article analyse systématiquement les avancées récentes dans le domaine de la conversion de texte en SQL basée sur le LLM. Enfin, les défis restants dans le domaine sont discutés et les attentes concernant les orientations futures de la recherche sont présentées.
Les articles spécifiquement mentionnés par "[xx]" dans le texte peuvent être consultés dans la section des références de l'article original.
introductif
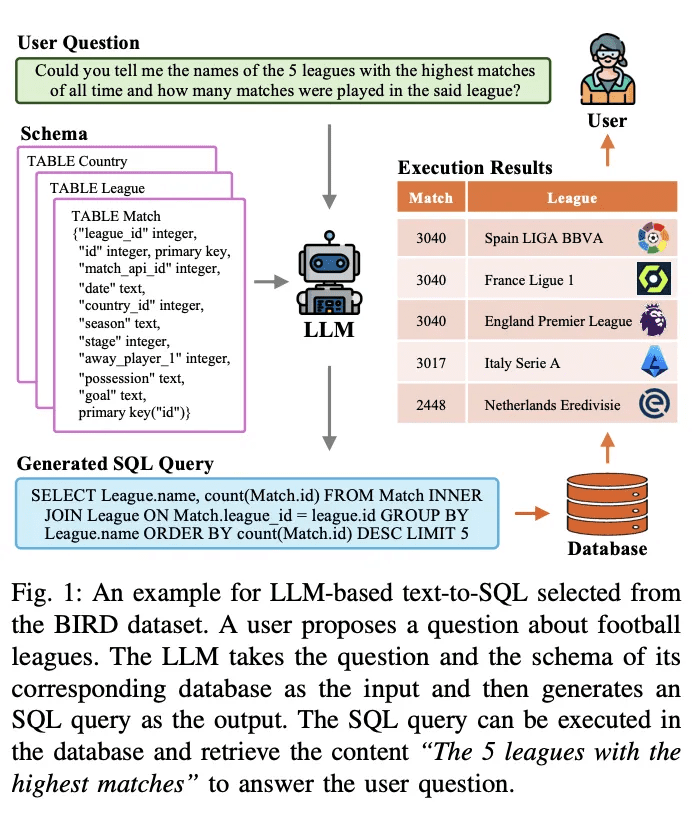
La conversion de texte en SQL est une tâche de longue date dans la recherche sur le traitement du langage naturel. Elle vise à convertir (traduire) des problèmes de langage naturel en requêtes SQL exécutables dans une base de données. La figure 1 présente un exemple de système de conversion de texte en SQL basé sur un modèle de langage à grande échelle (LLM). Étant donné une question d'utilisateur, par exemple "Pouvez-vous me donner les noms des 5 ligues les plus jouées dans l'histoire et combien de parties ont été jouées dans cette ligue ?", le LLM traduit la question et la requête correspondante en une requête SQL exécutable. Le LLM prend en entrée la question et le schéma de base de données correspondant et les analyse. Il génère ensuite une requête SQL en sortie. Cette requête SQL peut être exécutée dans la base de données afin d'extraire le contenu pertinent pour répondre à la question de l'utilisateur. Le système ci-dessus utilise LLM pour construire une interface en langage naturel avec la base de données (NLIDB).
Étant donné que SQL est toujours l'un des langages de programmation les plus utilisés, que la moitié (51,52%) des développeurs professionnels utilisent SQL dans leur travail et que, notamment, seul un tiers (35,29%) des développeurs sont formés au système, NLIDB permet aux utilisateurs non qualifiés d'accéder à des bases de données structurées comme le font les ingénieurs de bases de données professionnels [1, 2]. et accélère également l'interaction homme-machine [3]. En outre, parmi les points chauds de la recherche en LLM, le text-to-SQL peut combler le manque de connaissances en LLM en incorporant le contenu réel des bases de données, fournissant des solutions potentielles au problème omniprésent des illusions [4, 5] [6]. La grande valeur et le potentiel de la conversion de texte en SQL ont déclenché une série d'études sur son intégration et son optimisation avec les LLM [7-10] ; ainsi, la conversion de texte en SQL basée sur les LLM reste un domaine de recherche très discuté dans les communautés du TAL et des bases de données.
Les recherches antérieures ont permis de réaliser des progrès considérables dans la mise en œuvre de la conversion de texte en SQL et ont connu un long processus d'évolution. La plupart des premières recherches étaient basées sur des règles et des modèles bien conçus [11], qui étaient particulièrement adaptés à des scénarios de base de données simples. Ces dernières années, la conception de règles ou de modèles pour chaque scénario est devenue de plus en plus difficile et peu pratique en raison des coûts de main-d'œuvre élevés associés aux approches fondées sur des règles [12] et de la complexité croissante des environnements de bases de données [13 - 15]. Les progrès dans le domaine de la conversion de texte en SQL ont été alimentés par le développement de réseaux neuronaux profonds [16, 17], qui apprennent automatiquement les correspondances entre les questions des utilisateurs et le langage SQL correspondant [18, 19]. Par la suite, les modèles de langage pré-entraînés (PLM) dotés de puissantes capacités d'analyse sémantique sont devenus le nouveau paradigme des systèmes de conversion de texte en SQL [20], portant leurs performances à un niveau supérieur [21 - 23]. La recherche progressive sur les optimisations basées sur les PLM (par exemple, l'encodage du contenu des tables [ 19 , 24 , 25 ] et le pré-entraînement [ 20 , 26 ]) a fait progresser le domaine. Récemment.L'approche basée sur le LLM met en œuvre la transformation du texte en SQL à travers les paradigmes d'apprentissage contextuel (ICL) [8] et de réglage fin (FT) [10]L'entreprise atteint une précision de pointe grâce à un cadre bien conçu et à une meilleure compréhension de la gestion du cycle de vie des produits (PLM).
Les détails de l'implémentation globale de la conversion de texte en SQL basée sur le LLM peuvent être divisés en trois domaines :
1) Compréhension du problèmeLes questions NL sont des représentations sémantiques de l'intention de l'utilisateur, et les requêtes SQL générées correspondantes doivent être cohérentes avec elles ;
2) Compréhension des modèlesLe schéma fournit la structure des tables et des colonnes de la base de données, et le système text-to-SQL doit identifier le composant cible qui correspond au problème de l'utilisateur ;
3) Génération SQLDans le cas de la conversion de texte en SQL, il s'agit de combiner l'analyse ci-dessus et de prédire la syntaxe correcte pour générer une requête SQL exécutable afin de récupérer la réponse souhaitée. Il a été démontré que les LLM peuvent bien mettre en œuvre la fonctionnalité texte vers SQL [7, 27], grâce à des capacités d'analyse sémantique plus puissantes permises par des corpus d'apprentissage plus riches [28, 29]. D'autres recherches sur l'amélioration des LLM pour la compréhension des problèmes [8, 9], la compréhension des modèles [30, 31] et la génération de SQL [32] se développent.
Malgré les progrès significatifs de la recherche sur la conversion de texte en SQL, certains problèmes entravent encore le développement de systèmes robustes et polyvalents de conversion de texte en SQL [ 73 ]. Les recherches pertinentes menées ces dernières années ont permis d'étudier les systèmes de conversion de texte en SQL dans le cadre d'approches d'apprentissage profond et de donner un aperçu des approches d'apprentissage profond précédentes et des recherches basées sur le PLM. L'objectif de cette étude est de rattraper les dernières avancées et de fournir une revue complète des modèles et approches de pointe actuels pour la conversion de texte en SQL basée sur la PLM. Tout d'abord, les concepts de base et les défis associés à la conversion de texte en SQL sont introduits, soulignant l'importance de cette tâche dans divers domaines. Ensuite, un regard approfondi sur l'évolution des paradigmes de mise en œuvre pour les systèmes de conversion de texte en SQL est présenté, en discutant des principales avancées et percées dans le domaine. Cette vue d'ensemble est suivie d'une description et d'une analyse détaillées des dernières avancées dans le domaine de la conversion de texte en SQL pour l'intégration LLM. Plus précisément, ce document d'étude couvre une série de sujets liés à la conversion de texte en SQL basée sur LLM, y compris :
● Ensembles de données et critères de référenceDescription détaillée des ensembles de données et des points de référence couramment utilisés pour évaluer les systèmes de conversion de texte en SQL basés sur le LLM. Leurs caractéristiques, leur complexité et les défis qu'ils posent pour le développement et l'évaluation des systèmes texte-vers-SQL sont discutés.
● Évaluation des indicateursLes mesures d'évaluation utilisées pour évaluer la performance des systèmes texte-vers-SQL basés sur le LLM seront présentées, y compris les exemples basés sur l'appariement du contenu et sur l'exécution. Les caractéristiques de chaque mesure sont ensuite brièvement décrites.
● Méthodes et modèles: Cet article présente une analyse systématique des différentes approches et modèles utilisés pour la conversion de texte en SQL à l'aide de LLM, y compris des exemples basés sur l'apprentissage contextuel et le réglage fin. Les détails de leur mise en œuvre, leurs avantages et leurs adaptations aux tâches de conversion de texte en SQL sont discutés selon différentes perspectives de mise en œuvre.
● Attentes et orientations futures: Cet article examine les défis et les limites qui subsistent dans le domaine de la conversion de texte en SQL basée sur la méthode LLM, tels que la robustesse dans le monde réel, l'efficacité de calcul, la confidentialité des données et la mise à l'échelle. Les orientations potentielles de la recherche future et les possibilités d'amélioration et d'optimisation sont également soulignées.
esquissée
Text-to-SQL est une tâche qui vise à transformer des questions en langage naturel en requêtes SQL correspondantes qui peuvent être exécutées dans une base de données relationnelle. Formellement, étant donné une question d'utilisateur Q (également connue sous le nom de requête d'utilisateur, question en langage naturel, etc.) et un schéma de base de données S, l'objectif de la tâche est de générer une requête SQL Y qui récupère le contenu requis de la base de données pour répondre à la question de l'utilisateur. Le Text-to-SQL a le potentiel de démocratiser l'accès aux données en permettant aux utilisateurs d'interagir avec la base de données en utilisant le langage naturel sans avoir besoin d'une expertise en programmation SQL [75]. En permettant aux utilisateurs non qualifiés d'extraire facilement un contenu ciblé des bases de données et en facilitant une analyse plus efficace des données, cette approche peut bénéficier à des domaines aussi divers que la veille économique, l'assistance à la clientèle et la recherche scientifique.
A. Défis de la conversion de texte en SQL
Les défis techniques de la mise en œuvre de la conversion de texte en SQL peuvent être résumés comme suit :
1)Complexité et ambiguïté linguistiquesLes problèmes de langage naturel contiennent souvent des représentations linguistiques complexes telles que des clauses imbriquées, des coréférences et des ellipses, ce qui rend difficile leur mise en correspondance avec les parties correspondantes d'une requête SQL [41]. En outre, le langage naturel est intrinsèquement ambigu, avec de multiples représentations possibles pour un problème d'utilisateur donné [76, 77]. Résoudre ces ambiguïtés et comprendre l'intention derrière le problème de l'utilisateur nécessite une compréhension approfondie du langage naturel et la capacité d'intégrer la connaissance du contexte et du domaine [33].
2)Compréhension et représentation des formesLes systèmes de conversion de texte en SQL nécessitent une connaissance approfondie du schéma de la base de données, notamment des noms de tables et de colonnes et des relations entre les différentes tables, afin de pouvoir générer des requêtes SQL précises. Cependant, les schémas de base de données peuvent être complexes et varier considérablement d'un domaine à l'autre [13]. La représentation et l'encodage des informations de schéma d'une manière qui puisse être utilisée efficacement par les modèles de conversion de texte en SQL est une tâche difficile.
3)Opérations SQL rares et complexesLes requêtes SQL : Certaines requêtes SQL impliquent des opérations et une syntaxe rares ou complexes dans des scénarios difficiles, telles que les sous-requêtes imbriquées, les jointures externes et les fonctions de fenêtre. Ces opérations sont moins courantes dans les données d'apprentissage et constituent un défi pour la génération précise de systèmes de conversion de texte en SQL. Il est important de concevoir des modèles qui se généralisent à une variété d'opérations SQL, y compris des scénarios rares et complexes.
4)généralisation inter-domainesLes systèmes de conversion du texte en langage SQL sont souvent difficiles à généraliser dans divers scénarios et domaines de bases de données. En raison de la diversité des vocabulaires, des structures de schémas de base de données et des modèles de problèmes, les modèles formés dans un domaine spécifique peuvent ne pas bien gérer les problèmes posés dans d'autres domaines. Le développement de systèmes pouvant être généralisés efficacement à de nouveaux domaines en utilisant un minimum de données de formation spécifiques au domaine ou des adaptations fines est un défi majeur [78].
B. Processus d'évolution
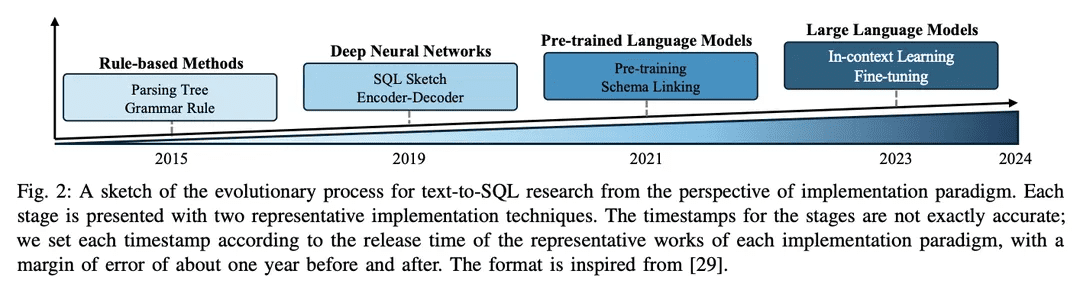
Le domaine de la recherche sur la conversion de texte en SQL a fait de grands progrès dans la communauté NLP au fil des ans, passant d'approches basées sur des règles à des approches basées sur l'apprentissage profond, et plus récemment à l'intégration de modèles de langage pré-entraînés (PLM) et de modèles de langage à grande échelle (LLM), avec une esquisse du processus d'évolution présentée dans la Figure 2.
1) Approche fondée sur des règlesLes premiers systèmes de conversion de texte en SQL s'appuyaient fortement sur des approches basées sur des règles [11, 12, 26], c'est-à-dire sur l'utilisation de règles et d'heuristiques formulées manuellement pour faire correspondre des problèmes de langage naturel à des requêtes SQL. Ces approches impliquent généralement une ingénierie des caractéristiques importante et des connaissances spécifiques au domaine. Bien que les approches basées sur des règles aient donné de bons résultats dans des domaines simples spécifiques, elles manquent de la flexibilité et des capacités de généralisation nécessaires pour traiter un large éventail de problèmes complexes.
2)Approche basée sur l'apprentissage profondLes réseaux neuronaux profonds : Avec l'essor des réseaux neuronaux profonds, les réseaux neuronaux profondsModélisation séquence à séquence et architecture du codeur-décodeur(par exemple, LSTM [ 79] et convertisseurs [17]) sont utilisés pour générer des requêtes SQL à partir d'entrées en langage naturel [ 19 , 80 ]. Typiquement, RYANSQL [19] introduit des techniques telles que les représentations intermédiaires et le remplissage de fentes à base de croquis pour traiter les problèmes complexes et améliorer la généralité inter-domaines. Récemment, des chercheurs ont utilisé des systèmes de requêtes SQL dépendant du schéma [ 19 , 80 ].Les graphiques permettent de saisir les relations entre les éléments de la base de donnéesLa première étape a consisté à introduire une nouvelle tâche de conversion de texte en SQL, la tâcheRéseaux neuronaux graphiques (GNN)[18,81].
3) Mise en œuvre basée sur le PLMLes premières applications des modèles de langage pré-entraînés (PLM) dans la conversion de texte à SQL se sont concentrées sur le réglage fin des PLM disponibles sur les ensembles de données standard de conversion de texte à SQL, tels que BERT [24] et RoBERTa [82] [13, 14]. Ces PLM sont pré-entraînés sur un large corpus de formation, capturant de riches représentations sémantiques et des capacités de compréhension de la langue. En les affinant dans des tâches de conversion de texte en SQL, les chercheurs visent à exploiter les capacités de compréhension sémantique et linguistique des PLM pour générer des requêtes SQL précises [ 20, 80, 83]. Une autre direction de recherche consiste à incorporer des informations de schéma dans les PLM afin d'améliorer la façon dont ces systèmes peuvent aider les utilisateurs à comprendre les structures des bases de données et à générer des requêtes SQL plus exécutables. Les PLM sensibles aux schémas sont conçus pour capturer les relations et les contraintes présentes dans la structure de la base de données [21].
4) Mise en œuvre basée sur le LLMLes grands modèles de langage (LLM), tels que la famille GPT [ 84 -86 ], ont fait l'objet d'une grande attention ces dernières années pour leur capacité à générer des textes cohérents et fluides. Les chercheurs ont commencé à explorer le potentiel de la conversion de texte en SQL en exploitant la base de connaissances étendue et les capacités de génération supérieures des LLM [7, 9]. Ces approches impliquent typiquement de diriger l'ingénierie des indices des LLMs propriétaires pendant la génération de SQL [47], ou d'affiner les LLMs open-source sur des ensembles de données text-to-SQL [9].
L'intégration de LLM dans la conversion de texte en SQL est encore un domaine de recherche émergent avec un grand potentiel d'exploration et d'amélioration. Les chercheurs étudient comment mieux utiliser les capacités de connaissance et de raisonnement de LLM, incorporer des connaissances spécifiques au domaine [31, 33 ], et développer des stratégies de réglage fin plus efficaces [ 10 ]. Au fur et à mesure que le domaine continue d'évoluer, on s'attend à ce que des implémentations plus avancées et supérieures basées sur le LLM soient développées, ce qui portera la performance et la généralisation de texte à SQL à de nouveaux sommets.
Critères de référence et évaluations
Dans cette section, le document présente des tests de conversion de texte en SQL, y compris des ensembles de données et des mesures d'évaluation bien connus.
A. Ensembles de données
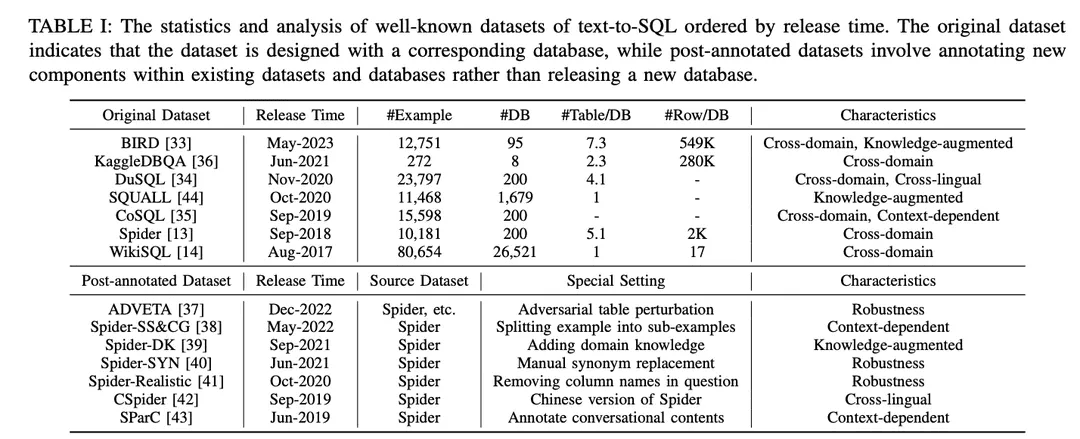
Comme le montre le tableau I, les ensembles de données sont classés en "ensembles de données originaux" et "ensembles de données post-annotation". Les ensembles de données sont classés en "ensembles de données originaux" et "ensembles de données post-annotation" selon que les ensembles de données sont publiés avec les ensembles de données et les bases de données originaux ou créés en apportant des modifications spéciales aux ensembles de données et aux bases de données existants. Pour l'ensemble de données original, une analyse détaillée est fournie, y compris le nombre d'exemples, le nombre de bases de données, le nombre de tables par base de données et le nombre de lignes par base de données. Pour les ensembles de données annotés, les ensembles de données sources sont identifiés et les paramètres particuliers qui leur sont appliqués sont décrits. Afin d'illustrer les possibilités offertes par chaque ensemble de données, celui-ci a été annoté en fonction de ses caractéristiques. Les annotations sont énumérées à l'extrême droite du tableau I. Elles sont examinées plus en détail ci-dessous. Elles sont examinées plus en détail ci-dessous.
1) Ensembles de données inter-domainesL'expression "données d'arrière-plan" : se réfère à des ensembles de données où les informations d'arrière-plan pour différentes bases de données proviennent de différents domaines. Étant donné que les applications réelles de conversion de texte en SQL impliquent généralement des bases de données provenant de plusieurs domaines, la plupart des ensembles de données originaux de conversion de texte en SQL [13,14,33 - 36] et des ensembles de données post-annotation [37 -43] se trouvent dans une configuration inter-domaines, ce qui est bien adapté aux applications inter-domaines.
2) Ensembles de données enrichis de connaissancesBIRD [ 33 ] utilise des experts de base de données humains pour annoter chaque échantillon de texte vers SQL avec des connaissances externes classées en tant que connaissances de raisonnement numérique, connaissances de domaine, connaissances de synonymes et déclarations de valeur. De même, Spider-DK [ 39 ] a édité manuellement une version de l'ensemble de données Spider [13] pour les éditeurs humains : la colonne SELECT a été omise, un raisonnement simple a été requis, des substitutions de synonymes dans les mots à valeur cellulaire, un mot sans valeur cellulaire génère une condition et est susceptible d'entrer en conflit avec d'autres domaines. Les deux études ont montré que les connaissances annotées manuellement amélioraient de manière significative les performances de la génération SQL pour les échantillons nécessitant des connaissances de domaine externes. En outre, SQUALL [44] annote manuellement l'alignement entre les mots dans les problèmes NL et les entités dans SQL, fournissant une supervision plus fine que dans d'autres ensembles de données.
3) Ensembles de données pertinentes sur le plan contextuelSParC [43] et CoSQL [35] explorent la génération de SQL sensible au contexte en construisant un système d'interrogation pour les bases de données de session. Contrairement aux ensembles de données texte-SQL traditionnels qui comportent une seule paire question-SQL avec un seul exemple, SParC décompose les exemples de questions SQL dans l'ensemble de données Spider en plusieurs paires sous-question-SQL pour construire des interactions simulées et significatives, y compris des sous-questions interdépendantes qui contribuent à la génération de SQL, et des sous-questions non reliées qui améliorent la diversité des données. En revanche, CoSQL implique des interactions de dialogue en langage naturel qui simulent des scénarios du monde réel afin d'accroître la complexité et la variété. En outre, Spider-SS&CG [38] divise le problème NL de l'ensemble de données Spider [13] en plusieurs sous-problèmes et sous-SQL, démontrant que l'entraînement sur ces sous-exemples améliore la distribution des échantillons des capacités de généralisation du système de conversion de texte en SQL.
4) Ensembles de données de robustesseSpider-Realistic [ 41] supprime les termes explicitement liés au schéma des problèmes NL, tandis que Spider-SYN [ 40] les remplace par des synonymes sélectionnés manuellement.ADVETA [ 37 ] a introduit la perturbation contradictoire de la table (ATP), qui perturbe la table en remplaçant les noms de colonnes originaux par des substitutions trompeuses et en insérant de nouvelles colonnes ayant une grande pertinence sémantique mais une faible équivalence sémantique. Ces perturbations peuvent entraîner une baisse significative de la précision, car les systèmes de conversion texte-SQL moins robustes peuvent être induits en erreur par des erreurs de correspondance entre les tokens et les entités de la base de données dans les problèmes de NL.
5) Ensembles de données inter-languesCSpider [ 42 ] traduit l'ensemble de données Spider en chinois et découvre de nouveaux défis en matière de segmentation des mots et de correspondance interlinguistique entre les questions chinoises et le contenu de la base de données en anglais.DuSQL [34] présente un ensemble de données text-to-SQL pratique avec des questions chinoises et des contenus de base de données en anglais et en chinois. DuSQL [34] présente un ensemble pratique de données texte-SQL avec des questions chinoises et des contenus de bases de données anglaises et chinoises.
B. Indicateurs d'évaluation
Les quatre mesures d'évaluation suivantes, largement utilisées, sont introduites pour les tâches de conversion de texte en SQL : "Correspondance des composants" et "Correspondance exacte" basées sur la correspondance du contenu SQL, et "Précision d'exécution" basée sur les résultats d'exécution. "et "Score d'efficacité effective".
1) Mesures basées sur l'adéquation du contenuLa métrique de correspondance du contenu SQL est principalement basée sur la similarité structurelle et syntaxique de la requête SQL prédite avec la requête SQL réelle sous-jacente.
Correspondance des composants (CM)[13] Les performances d'un système text-to-SQL sont évaluées en mesurant les correspondances exactes entre les composants SQL prédits (SELECT, WHERE, GROUP BY, ORDER BY et KEYWORDS) et les composants SQL réels (GROUP BY, ORDER BY et KEYWORDS) à l'aide des scores F1. Chaque composant est décomposé en ensembles de sous-composants et comparé pour les correspondances exactes en tenant compte des composants SQL sans contraintes d'ordre.
Correspondance exacte (EM)) [13] mesure le pourcentage d'exemples où la requête SQL prédite est exactement la même que la requête SQL de référence. Une requête SQL prédite est considérée comme correcte uniquement si tous ses composants (tels que décrits dans CM) correspondent exactement aux composants de la requête de vérité terrain.
2) Indicateurs basés sur la mise en œuvreRésultats d'exécution : La métrique Résultats d'exécution évalue l'exactitude de la requête SQL générée en comparant les résultats obtenus lors de l'exécution de la requête sur la base de données cible avec les résultats escomptés.
Précision d'exécution (EX)[L'exactitude d'une requête SQL prédite est mesurée en exécutant la requête dans la base de données correspondante et en comparant les résultats avec ceux obtenus à partir de la vraie requête de base.
Score d'efficacité (VES)La définition de [33] est de mesurer l'efficacité d'une requête SQL efficace. Une requête SQL efficace est une requête SQL prédite dont le résultat de l'exécution est identique au résultat réel sous-jacent. Plus précisément, VES évalue simultanémentPrévoir l'efficacité et la précision des requêtes SQL. Pour un ensemble de données textuelles contenant N exemples, la VES est calculée comme suit :

R(Y_n, Y_n) représente l'efficacité d'exécution relative de la requête SQL prédite par rapport à la requête réelle.
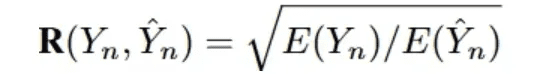
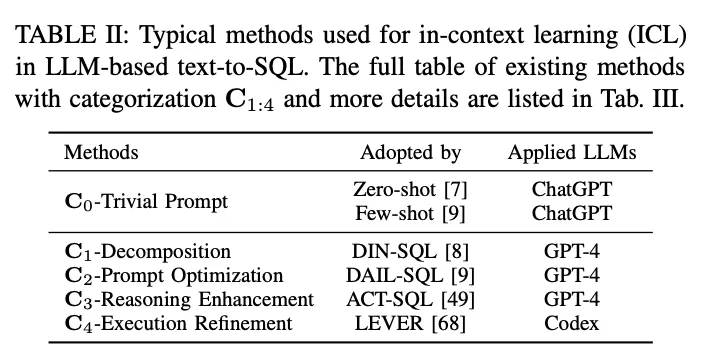
La plupart des recherches récentes basées sur le LLM se sont concentrées sur ces quatre ensembles de données, Spider [13], Spider-Realistic [41], Spider-SYN [40], et BIRD [33] ; et les trois méthodes d'évaluation, EM, EX, et VES, qui seront au centre de l'analyse suivante.
les méthodologies
Les implémentations actuelles des applications basées sur le LLM s'appuient fortement sur les paradigmes de l'apprentissage en contexte (ICL) (ingénierie juste à temps) [87-89] et du réglage fin (FT) [90,91], car des modèles propriétaires robustes et des modèles open-source bien architecturés sont publiés en grand nombre [45,86,92-95]. Les systèmes texte-vers-SQL basés sur le LLM suivent ces paradigmes pour l'implémentation. Dans cette étude, ils seront discutés en conséquence.
A. l'apprentissage contextuel
Grâce à des recherches approfondies et reconnues, il a été démontré que l'ingénierie des indices joue un rôle décisif dans la performance des LLM [28 , 96 ], et qu'elle influence la génération de SQL sous différents styles d'indices [9 , 46]. Par conséquent, le développement de méthodes de conversion texte-SQL dans le paradigme de l'apprentissage contextuel (ICL) est précieux pour obtenir des améliorations prometteuses. Une implémentation d'un processus texte-vers-SQL basé sur LLM qui génère une requête SQL exécutable Y peut être formulée comme suit :

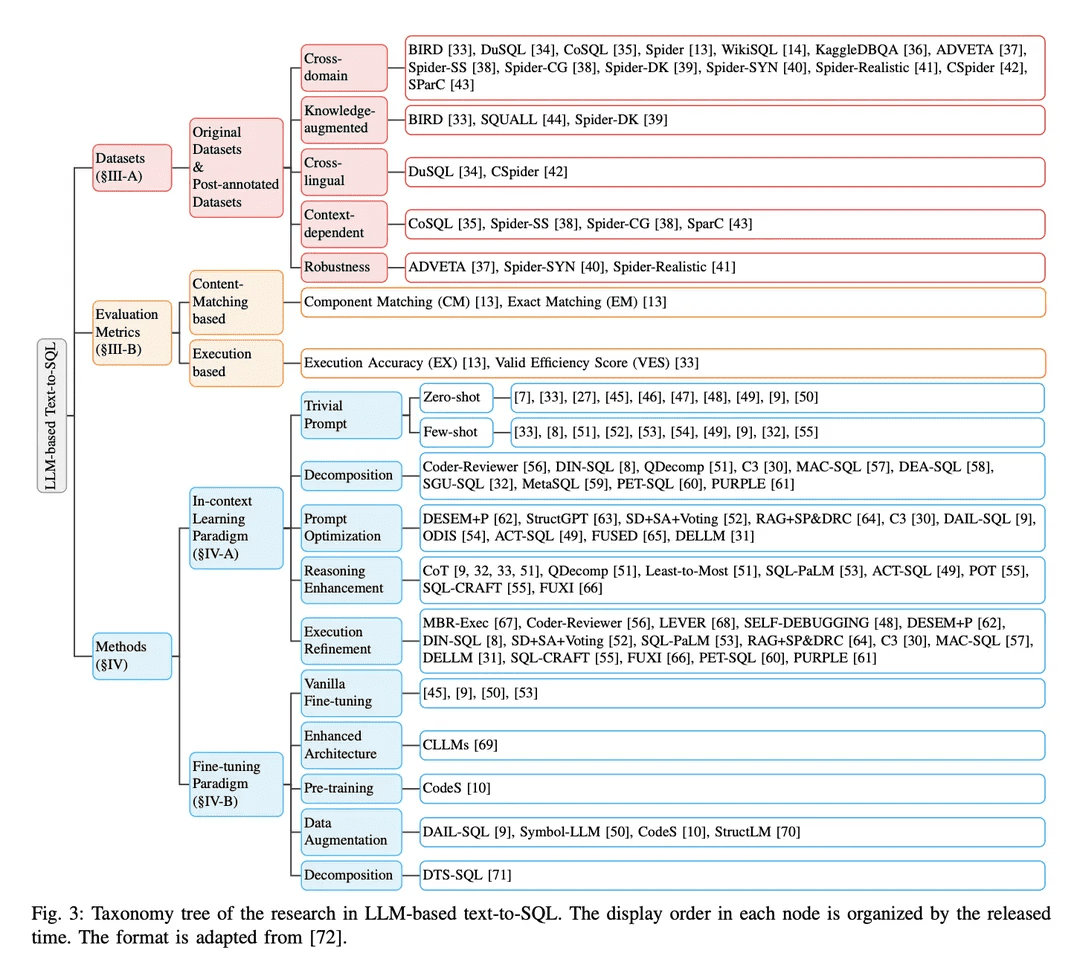
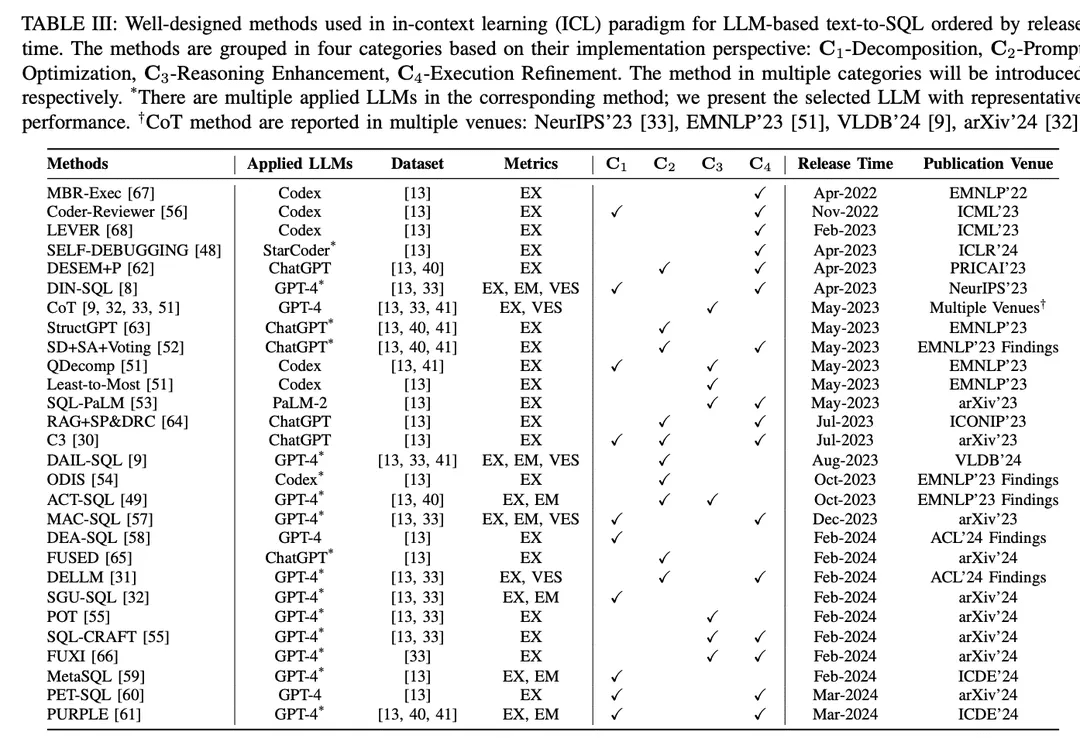
Dans le paradigme de l'apprentissage contextuel (ICL), un modèle texte-SQL prêt à l'emploi (c'est-à-dire que le paramètre θ du modèle est gelé) est utilisé pour générer des requêtes SQL prédites. Les tâches de conversion texte-SQL basées sur le LLM utilisent une variété de méthodes bien conçues dans le paradigme ICL. Elles sont classées en cinq catégories C0:4, y compris C0-Simple Hinting, C1-Decomposition, C2-Hint Optimisation, C3-Inference Enhancement et C4-Execution Refinement. Le tableau II énumère les représentants de chaque catégorie.
C0 - Promesse trivialeLe LLM, formé sur des données massives, a une forte compétence globale dans différentes tâches en aval avec un échantillon zéro et un petit nombre d'indices [90, 97, 98], ce qui est largement reconnu et appliqué dans les applications pratiques. Dans l'étude, les méthodes d'incitation susmentionnées sans cadrage élaboré ont été classées comme des incitations triviales (ingénierie des fausses incitations). Comme mentionné ci-dessus, l'Eq. 3 décrit le processus de conversion de texte en SQL basé sur le LLM, qui peut également désigner l'invite à échantillon zéro. L'entrée globale P0 est obtenue en concaténant I, S et Q. L'entrée P0 est la même que l'entrée globale P0 :
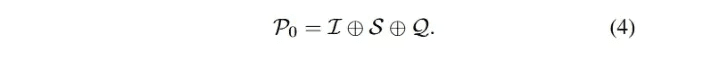
Pour normaliser le processus d'invite, OpenAI demo2 a été configuré comme une invite standard (simple) pour la conversion de texte en SQL [30].
échantillon zéroLes travaux de recherche [7,27,46] utilisent l'indication de l'échantillon zéro, en se concentrant sur l'impact des styles de construction d'indication et des différents LLM sur la performance de l'échantillon zéro de text-to-SQL. En tant qu'évaluation empirique, [7] a évalué la performance de différents LLM développés au début [85, 99, 100] pour la fonctionnalité de base text-to-SQL ainsi que pour différents styles d'indices. Les résultats montrent que la conception à la volée est essentielle pour la performance et, grâce à l'analyse des erreurs, [7] suggère qu'un contenu de base de données plus important peut nuire à la précision globale. Étant donné que le ChatGPT avec des capacités impressionnantes en matière de scénarios de dialogue et de génération de code [101], [27] a évalué ses performances en matière de conversion de texte en SQL. Avec un échantillon zéro, les résultats montrent que ChatGPT a une performance texte-SQL encourageante par rapport aux systèmes basés sur PLM les plus récents. Pour une comparabilité équitable, [47] a révélé des constructions de messages-guides efficaces pour la conversion de texte à SQL basée sur LLM ; ils ont étudié différents styles de constructions de messages-guides et ont conclu une conception de messages-guides à échantillon zéro basée sur la comparaison.
Les clés primaires et étrangères véhiculent une connaissance continue des différentes tables. [49] a étudié leur impact en incorporant ces clés dans divers styles d'indices pour différents contenus de base de données et en analysant les résultats de l'indice à échantillon zéro. L'impact des clés étrangères a également été étudié dans le cadre d'une évaluation comparative [9], dans laquelle cinq styles différents de représentation des indices, chacun pouvant être considéré comme une permutation de directives, de significations de règles et de clés étrangères, ont été inclus. Outre les clés externes, cette étude a également exploré la combinaison d'indices à zéro échantillon et d'implications de règles "sans interprétation" pour collecter des résultats concis. S'appuyant sur l'annotation des connaissances externes d'experts humains, [33 ] a suivi les indications standard et a obtenu des améliorations en combinant les connaissances annotées de l'oracle.
Avec l'explosion des LLMs open-source, ces modèles sont également capables d'effectuer des tâches text-to-SQL à zéro échantillon selon des évaluations similaires [45, 46, 50], en particulier les modèles de génération de code [46, 48]. Pour l'optimisation de l'indication en échantillon zéro, [46] a présenté le défi de concevoir des modèles d'indication efficaces pour les LLM ; les constructions d'indication précédentes manquaient d'unité structurelle, ce qui rendait difficile l'identification d'éléments spécifiques dans les modèles de construction d'indication qui affectent la performance des LLM. Pour relever ce défi, ils ont étudié une série de modèles d'indices plus uniformes accordés avec différents préfixes, suffixes et préfixes-postfixes.
Quelques conseilsLa technique du petit nombre d'indices a été largement utilisée dans les applications pratiques et dans la recherche bien conçue, et il a été démontré qu'elle est efficace pour améliorer la performance de LLM [ 28 , 102 ]. L'indication d'entrée globale de la méthode d'indication texte vers SQL basée sur LLM pour un petit nombre d'indications peut être formulée comme une extension de l'équation 3 :

En tant qu'étude empirique, l'indication de quelques coups pour la conversion de texte en SQL a été évaluée sur plusieurs ensembles de données et divers LLM [8, 32], et a montré de bonnes performances par rapport à l'indication d'un échantillon zéro. [33] fournit un exemple détaillé d'un déclenchement unique d'un modèle texte-SQL pour générer un code SQL précis. [55] étudie l'impact d'un petit nombre d'exemples. [52] se concentre sur les stratégies d'échantillonnage en étudiant la similarité et la diversité entre différents exemples, en comparant l'échantillonnage aléatoire et en évaluant différentes stratégies8 et leurs combinaisons à des fins de comparaison. En outre, en plus de la sélection basée sur la similarité, [9] évalue les limites supérieures de la sélection par similarité pour les problèmes de masquage et les méthodes de similarité avec différents nombres d'exemples d'échantillons moins nombreux. Une étude de la sélection d'échantillons à des niveaux de difficulté [51] a comparé les performances du Codex à petit échantillon [100] avec la sélection aléatoire et basée sur la difficulté d'exemples à petit échantillon sur l'ensemble de données classées par difficulté [13, 41]. Trois stratégies de sélection basées sur la difficulté ont été conçues sur la base du nombre d'échantillons sélectionnés à différents niveaux de difficulté. Les auteurs [49] ont utilisé une stratégie hybride pour sélectionner des échantillons combinant des exemples statiques et des exemples dynamiques basés sur la similarité pour un petit nombre d'indices. Dans leur configuration, ils évaluent également les effets de différents styles de motifs d'entrée et de différentes tailles d'échantillons statiques et dynamiques.
L'impact d'un petit nombre d'exemples dans les différents domaines est également étudié [54 ]. Lorsque différents nombres d'exemples dans le domaine et hors du domaine ont été inclus, les exemples dans le domaine ont été plus performants que les exemples d'ordre zéro et hors du domaine, les exemples dans le domaine ont été plus performants que les exemples hors du domaine, les exemples hors du domaine ont été plus performants que les exemples d'ordre zéro et hors du domaine.Au fur et à mesure que le nombre d'exemples augmente, les performances des exemples internes au domaine s'améliorent.. Afin d'explorer la construction détaillée des indications d'entrée, [53] a comparé les approches de conception des indications concises et verbeuses. La première divise le schéma, les noms de colonnes, les clés primaires et étrangères par entrées, tandis que la seconde les organise en descriptions en langage naturel.
C1-DécompositionLes méthodes de décomposition de texte vers SQL basées sur LLM se répartissent en deux paradigmes : la décomposition de problèmes difficiles en sous-problèmes plus simples ou leur mise en œuvre à l'aide de composants multiples peut réduire la complexité de la tâche globale de conversion du texte vers le SQL [8, 51]. En traitant des problèmes moins complexes, LLM a le potentiel de générer une SQL plus précise. Les méthodes de décomposition texte-SQL basées sur LLM relèvent de deux paradigmes :(1) Répartition des sous-tâchesEn outre, en décomposant l'ensemble de la tâche de conversion du texte en SQL en sous-tâches plus faciles à gérer et plus efficaces (par exemple, la liaison des schémas [71], la classification des domaines [54]), une analyse syntaxique supplémentaire est fournie pour faciliter la génération finale de SQL.(2) Décomposition du sous-problèmeDécomposer le problème de l'utilisateur en sous-problèmes afin de réduire la complexité et la difficulté du problème, puis dériver la requête SQL finale en résolvant ces problèmes afin de générer des sous-SQL.
DIN-SQL[DIN-SQL génère d'abord le lien de schéma entre le problème de l'utilisateur et la base de données cible ; le module suivant décompose le problème de l'utilisateur en sous-problèmes connexes et classifie la difficulté. Sur la base de ces informations, le module de génération SQL génère le SQL correspondant, et le module d'autocorrection identifie et corrige les erreurs potentielles dans le SQL prédit. Le cadre Coder-Reviewer [56] propose une approche de réorganisation qui combine un modèle de codeur pour générer des instructions et un modèle de réviseur pour évaluer la probabilité des instructions.
En se référant à la chaîne de pensée [103] et aux conseils du plus petit au plus grand [104], l'équipe d'experts de la Commission européenne est en train de mettre au point un système de gestion de la chaîne de pensée.QDecomp[51] ont introduit l'indice de décomposition du problème, qui suit la phase de réduction du problème à partir de l'indice le plus récent et demande au LLM d'effectuer la décomposition du problème complexe d'origine en tant qu'étape de raisonnement intermédiaire.
C3 [ 30 ] se compose de trois éléments clés : les indices de clarté, les indices de biais d'étalonnage et la cohérence ; ces éléments sont mis en œuvre en assignant différentes tâches à ChatGPT. Tout d'abord, le composant de clarté génère des liens de schéma et des schémas affinés liés à la question en tant qu'indices de clarté. Ensuite, plusieurs tours de dialogue sur les indices texte vers SQL sont utilisés comme indices de biais de calibration, qui, en combinaison avec les indices de clarté, guident la génération SQL. Les requêtes SQL générées sont filtrées par un vote basé sur la cohérence et l'exécution pour obtenir le SQL final.
MAC-SQL[57] ont proposé un cadre collaboratif multi-agents ; le processus de conversion du texte en SQL est réalisé en collaboration avec des agents tels que des sélecteurs, des décomposeurs et des raffineurs. Le sélecteur conserve les tables pertinentes pour le problème de l'utilisateur ; le décomposeur décompose le problème de l'utilisateur en sous-problèmes et fournit des solutions ; enfin, le raffineur valide et optimise le SQL défectueux.
DEA- SQL [58] introduit un paradigme de flux de travail qui vise à améliorer l'attention et la portée de la résolution de problèmes de la conversion de texte en SQL basée sur le LLM par le biais de la décomposition. L'approche décompose la tâche globale de manière à ce que le module de génération SQL ait des sous-tâches préalables (détermination de l'information, classification du problème) et ultérieures (autocorrection, apprentissage actif) correspondantes. Le paradigme du flux de travail permet à LLM de générer des requêtes SQL plus précises
SGU-SQL [ 32 ] est un cadre structure-to-SQL qui utilise des informations structurelles inhérentes pour aider à la génération de SQL. Plus précisément, le cadre construit des structures de graphe pour les questions des utilisateurs et les bases de données correspondantes, respectivement, et utilise ensuite des graphes encodés pour construire des liens structurels [105 , 106]. Les méta-opérateurs sont utilisés pour décomposer les problèmes des utilisateurs à l'aide d'arbres syntaxiques et, enfin, les méta-opérateurs SQL sont utilisés pour concevoir des invites de saisie.
MetaSQL [59 ] présente une approche en trois phases de la génération SQL : décomposition, génération et tri. La phase de décomposition utilise une combinaison de décomposition sémantique et de métadonnées pour traiter les problèmes de l'utilisateur. En utilisant les données précédemment traitées comme entrée, certaines requêtes SQL candidates sont générées à l'aide du modèle texte-SQL généré à partir des conditions des métadonnées. Enfin, un pipeline de tri en deux étapes est appliqué pour obtenir la requête SQL optimale globale.
PET-SQL [ 60 ] présente un cadre en deux étapes renforcé par des indices. Tout d'abord, des indices bien conçus indiquent au LLM de générer une SQL préliminaire (PreSQL), où quelques petites démonstrations sont sélectionnées sur la base de la similarité. Ensuite, des liens de schéma sont trouvés sur la base de PreSQL et combinés pour inciter le LLM à générer une SQL finale (FinSQL). Enfin, FinSQL est généré à l'aide de plusieurs LLM afin d'assurer la cohérence des résultats d'exécution.
Optimisation du C2-PromptL'apprentissage de quelques minutes : Comme décrit précédemment, l'apprentissage de quelques ordres pour l'indication de LLMs a été largement étudié [85]. Pour l'apprentissage texte-à-SQL (texte-à-SQL) et l'apprentissage contextuel basés sur les LLM, les méthodes triviales de quelques minutes ont donné des résultats prometteurs [8, 9, 33], et une optimisation plus poussée des indices de quelques minutes a le potentiel d'améliorer les performances. Étant donné que la précision de la génération de SQL dans les LLM prêts à l'emploi dépend fortement de la qualité des indices d'entrée correspondants [107], de nombreux déterminants affectant la qualité des indices ont fait l'objet de recherches actuelles [9] (par exemple, la qualité et la quantité de l'organisation des oligo-indices, la similarité entre le problème de l'utilisateur et les instances des oligo-indices, ainsi que les connaissances/indices externes).
DESEM [ 62 ] est un cadre d'ingénierie des indices avec désémantisation et récupération du squelette. Le cadre utilise d'abord un module de masquage de mots spécifique au domaine pour supprimer les jetons sémantiques qui préservent l'intention dans les questions de l'utilisateur. Il utilise ensuite un module d'indication réglable pour récupérer un petit nombre d'exemples ayant la même intention que la question, et combine cela avec un filtrage de la pertinence des motifs pour guider la génération SQL pour le LLM.
QDecomp [Le cadre introduit un mécanisme InterCOL qui combine de manière incrémentielle les sous-problèmes décomposés avec les noms de tableaux et de colonnes associés. Grâce à une sélection basée sur la difficulté, un petit nombre d'exemples de QDecomp sont échantillonnés en fonction de la difficulté. Outre l'échantillonnage par similarité et diversité, [ 52 ] a proposé la stratégie d'échantillonnage SD+SA+Voting (similarité-diversité+augmentation du modèle+vote). Ils ont d'abord échantillonné un petit nombre d'exemples en utilisant la similarité sémantique et la diversité du regroupement k-Means, puis ont augmenté les indices en utilisant la connaissance des modèles (augmentation sémantique ou structurelle).
C3 Le cadre [ 30 ] se compose d'un composant d'indices clairs, qui prend les questions et les schémas en entrée des LLM, et d'un composant d'étalonnage qui fournit des indices, qui génère un indice clair comprenant un schéma qui supprime les informations redondantes sans rapport avec la question de l'utilisateur, ainsi qu'un lien vers le schéma. Le cadre d'amélioration de la recherche introduit des indices sensibles à l'échantillon [64], qui simplifient le problème original et extraient le squelette du problème simplifié, puis complètent la recherche d'échantillons dans le référentiel sur la base de la similarité des squelettes. Les échantillons récupérés sont combinés avec le problème original pour un petit nombre d'indices.
ODIS [54] introduit la sélection d'échantillons à l'aide de présentations hors domaine et de données synthétiques dans le domaine, qui récupère un petit nombre de présentations à partir d'un mélange de sources afin d'améliorer la caractérisation des indices.
DAIL- SQL[DAIL Selection masque d'abord le vocabulaire spécifique au domaine des utilisateurs et un petit nombre d'exemples de problèmes, puis classe les exemples candidats sur la base de la distance euclidienne intégrée. Parallèlement, la similarité entre les requêtes SQL prédites est calculée. Enfin, le mécanisme de sélection obtient des exemples candidats triés par similarité sur la base de critères prédéfinis. Cette approche permet de s'assurer qu'un petit nombre d'exemples présentent une bonne similarité à la fois avec le problème et avec la requête SQL.
ACT-SQL[49] ont présenté des exemples dynamiques de sélection basée sur des scores de similarité.
FUSÉE[Le pipeline de FUSED échantillonne des présentations à fusionner par regroupement, puis fusionne les présentations échantillonnées pour construire un pool de présentations, améliorant ainsi l'efficacité de l'apprentissage à quelques coups.
Connaissances en SQL [31] Le cadre vise à construire des LLM experts en données (DELLM) afin de fournir des connaissances pour la génération de SQL.
DELLM DELLM génère quatre types de connaissances et des méthodes bien conçues (par exemple, DAIL-SQL [9], MAC-SQL [57 ]) intègrent les connaissances générées pour obtenir de meilleures performances pour la conversion de texte en SQL basée sur le LLM grâce à l'apprentissage contextuel.
C3 - Amélioration du raisonnement :Les LLM ont montré de bonnes capacités dans les tâches impliquant le raisonnement de bon sens, le raisonnement symbolique et le raisonnement arithmétique [108]. Dans les tâches de conversion de texte en SQL, le raisonnement numérique et le raisonnement synonymique apparaissent souvent dans des scénarios réalistes [ 33 , 41 ].Les stratégies d'indices pour le raisonnement avec les LLM ont le potentiel d'améliorer la génération SQL. La recherche récente s'est concentrée sur l'intégration de méthodes d'amélioration du raisonnement bien conçues pour l'adaptation texte-SQL, l'amélioration des LLM pour faire face aux défis des problèmes complexes nécessitant un raisonnement sophistiqué3 , et l'autoconsistance dans la génération SQL.
La technique d'indication de la chaîne de pensée (CoT) [103] consiste en un processus de raisonnement complet qui guide le LLM vers un raisonnement précis et stimule la capacité de raisonnement du LLM. Les études basées sur le LLM text-to-SQL utilisent les indices CoT comme indices de règles [9], avec des instructions "réfléchissons étape par étape" dans la construction de l'indice [9, 32, 33, 51]. Cependant, la stratégie CoT simple (primitive) pour les tâches texte-SQL n'a pas montré le potentiel qu'elle a pour d'autres tâches de raisonnement ; la recherche sur l'adaptation de la CoT est toujours en cours [51]. Étant donné que les astuces CoT sont toujours démontrées à l'aide d'exemples statiques avec des annotations manuelles, un jugement empirique est nécessaire pour sélectionner efficacement un petit nombre d'exemples pour lesquels les annotations manuelles sont essentielles.
En guise de solution.ACT-SQL [49] propose une méthode de génération automatique d'exemples CoT. Plus précisément, ACT-SQL, étant donné un problème, tronque l'ensemble des tranches du problème et énumère ensuite chaque colonne qui apparaît dans la requête SQL correspondante. Chaque colonne sera associée à la tranche la plus pertinente par le biais d'une fonction de similarité et jointe à un indice CoT.
QDecomp [Grâce à une étude systématique de l'amélioration de la génération SQL pour les LLM en conjonction avec les indices CoT, un nouveau cadre est proposé pour relever le défi de la manière dont CoT propose des étapes de raisonnement pour prédire les requêtes SQL. Le cadre utilise chaque fragment d'une requête SQL pour construire les étapes logiques du raisonnement CoT, puis utilise des modèles de langage naturel pour élaborer chaque fragment d'une requête SQL et les organiser dans un ordre logique d'exécution.
Du plus petit au plus grand [104 ] est une autre technique d'indication qui décompose le problème en sous-problèmes et les résout ensuite de manière séquentielle. En tant qu'indice itératif, les expériences pilotes [51] suggèrent que cette approche n'est peut-être pas nécessaire pour l'analyse syntaxique texte-SQL. L'utilisation d'étapes de raisonnement détaillées tend à créer davantage de problèmes de propagation d'erreurs.
En tant que variante de CoT, leProgramme de réflexion (PoT)Des stratégies d'indication [109] ont été proposées pour améliorer le raisonnement arithmétique du LLM.
En évaluant [55], PoT améliore les LLM générés par SQL, en particulier dans les ensembles de données complexes [33].
SQL-CRAFT [La stratégie PoT exige que le modèle génère à la fois du code Python et des requêtes SQL, ce qui oblige le modèle à incorporer du code Python dans son processus de raisonnement.
Cohérence personnelle[110] est une stratégie d'indication pour améliorer le raisonnement LLM qui exploite l'intuition qu'un problème de raisonnement complexe permet typiquement de multiples façons différentes de penser pour arriver à une réponse uniquement correcte. Dans les tâches texte-SQL, l'autoconsistance s'applique à l'échantillonnage d'un ensemble de différentes SQL et au vote pour des SQL cohérentes par le biais du retour d'exécution [30 , 53 ].
De même.SD+SA+Voting [Le cadre rejette les erreurs d'exécution identifiées par un système de gestion de base de données (SGBD) déterministe et sélectionne la prédiction qui reçoit la majorité des votes.
En outre, grâce à des recherches récentes sur l'utilisation d'outils permettant d'étendre la fonctionnalité du LLM, leFUXI [66] est proposé pour améliorer la génération SQL pour LLM en invoquant efficacement des outils bien conçus.
C4-Raffinement de l'exécutionLors de la conception de normes pour la génération d'un code SQL précis, la priorité est toujours de savoir si le code SQL généré peut être exécuté avec succès et récupérer le contenu pour répondre correctement à la question de l'utilisateur [13]. En tant que tâche de programmation complexe, la génération d'un code SQL correct en une seule fois est un véritable défi. Intuitivement, la prise en compte du feedback/des résultats d'exécution pendant la génération de SQL aide à s'aligner sur l'environnement de base de données correspondant, permettant ainsi au LLM de collecter les erreurs d'exécution potentielles et les résultats afin d'affiner le SQL généré ou de prendre un vote à la majorité [30]. Les approches conscientes de l'exécution Text-to-SQL intègrent le retour d'information sur l'exécution de deux manières principales :
1) Générer à nouveau un retour d'information avec une deuxième série de messages-guidesChaque requête SQL générée dans la réponse initiale sera exécutée dans la base de données appropriée afin d'obtenir un retour d'information de la part de la base de données. Ce retour peut être des erreurs ou des résultats qui seront ajoutés à la deuxième série d'invites. En apprenant ce retour d'information dans le contexte, LLM est en mesure d'affiner ou de régénérer la requête SQL originale pour en améliorer la précision.
2) Utiliser une politique de sélection basée sur l'exécution pour le code SQL généréPour ce faire, on échantillonne plusieurs requêtes SQL générées à partir du LLM et on exécute chaque requête dans la base de données. Sur la base du résultat de l'exécution de chaque requête SQL, une stratégie de sélection (par exemple, autoconsistance, vote majoritaire [60]) est utilisée pour définir une requête SQL à partir de l'ensemble SQL qui satisfait aux conditions en tant que requête SQL prédite finale.
MRC-EXEC [67 ] a proposé un cadre de traduction du langage naturel vers le code (NL2Code) avec une exécution qui classe chaque requête SQL échantillonnée et sélectionne l'exemple avec le plus petit résultat d'exécution basé sur le risque de Bayes [111].LEVIER [68] propose une méthode de validation de NL2Code par exécution, en utilisant les modules de génération et d'exécution pour collecter des échantillons de l'ensemble SQL et de ses résultats d'exécution, respectivement, et en utilisant ensuite un validateur d'apprentissage pour produire la probabilité d'exactitude.
Dans le même ordre d'idées.AUTODÉBOGAGE [Le modèle est capable de corriger les erreurs sans intervention humaine en examinant les résultats de l'exécution et en interprétant le code SQL généré en langage naturel.
Comme indiqué précédemment, l'implication en deux étapes a été largement utilisée afin de combiner un cadre bien conçu avec un retour d'information sur la mise en œuvre :1. échantillonnage d'un ensemble de requêtes SQL. 2. vote à la majorité (autoconsistant).En particulier.C3[Le cadre élimine les erreurs et identifie le code SQL le plus cohérent ;Le cadre d'amélioration de la recherche [64] introduit des chaînes de révision dynamiquesLa bibliothèque SQL a été conçue pour être un module autocorrectif qui combine des messages d'exécution fins avec le contenu de la base de données pour inciter les LLM à convertir les requêtes SQL générées en interprétations en langage naturel ; les LLM ont été invités à identifier les lacunes sémantiques et à modifier leur propre SQL généré.Bien que les méthodes de filtrage des schémas améliorent la génération SQL, le SQL généré peut être inexécutable.DESEM [62] a fusionné une révision de repli pour traiter ce problème ; il modifie et régénère les bibliothèques SQL en fonction de différents types d'erreurs et définit des conditions de terminaison pour éviter les boucles. DIN-SQL [8] a conçu des astuces génériques et douces dans son module d'autocorrection ; les astuces génériques demandent au LLM d'identifier et de corriger les erreurs, et les astuces douces demandent au modèle de vérifier les problèmes potentiels.
cadre multi-agentsMAC-SQL[57] comprend un agent de raffinement qui détecte et corrige automatiquement les erreurs SQL, utilise les classes d'erreurs et d'exceptions SQLite pour régénérer le code SQL corrigé.SQL-CRAFT [Le cadre introduit un calibrage interactif et un contrôle automatique du processus de détermination afin d'éviter une surcorrection ou une sous-correction. FUXI [66] prend en compte le retour d'erreur dans le raisonnement basé sur les outils pour la génération SQL. Connaissances en SQL [31] ont introduit un cadre d'apprentissage des préférences qui combine le retour d'information sur l'exécution de la base de données et l'optimisation directe des préférences [112] afin d'améliorer le DELLM proposé.PET-SQL[60] ont proposé la cohérence croisée, qui consiste en deux variantes : 1) le vote simple : plusieurs LLM sont chargés de générer une requête SQL, puis un vote majoritaire est utilisé pour décider du SQL final sur la base des différents résultats d'exécution, et 2) le vote à grain fin : le vote simple est affiné sur la base du niveau de difficulté afin d'atténuer le biais de vote.
B. Mise au point
Puisque le réglage fin supervisé (SFT) est l'approche dominante pour la formation des LLMs [29, 91], pour les LLMs open-source (par exemple, LLaMA-2 [94 ], Gemma [113]), la façon la plus directe d'adapter rapidement le modèle à un domaine spécifique est d'effectuer le SFT sur le modèle en utilisant des étiquettes de domaine collectées.La phase SFT est généralement la phase initiale d'un cadre de formation bien conçu [112, 114], et la phase de réglage fin de texte à SQL. La phase SFT est généralement la phase initiale d'un cadre de formation bien conçu [112, 114], ainsi que la phase de mise au point texte-SQL.Le processus de génération d'auto-régression pour la requête SQL Y peut être formulé comme suit :

L'approche SFT est également une méthode fictive de réglage fin pour la conversion de texte en SQL et a été largement adoptée par divers LLMs open-source dans la recherche sur la conversion de texte en SQL [9, 10 , 46 ]. Le paradigme du réglage fin préfère les points de départ de la conversion de texte en SQL basés sur le LLM aux approches d'apprentissage contextuel (ICL). Plusieurs études explorant de meilleures méthodes de réglage fin ont été publiées. Les méthodes de réglage fin bien conçues sont classées en différents groupes en fonction de leurs mécanismes, comme le montre le tableau IV :
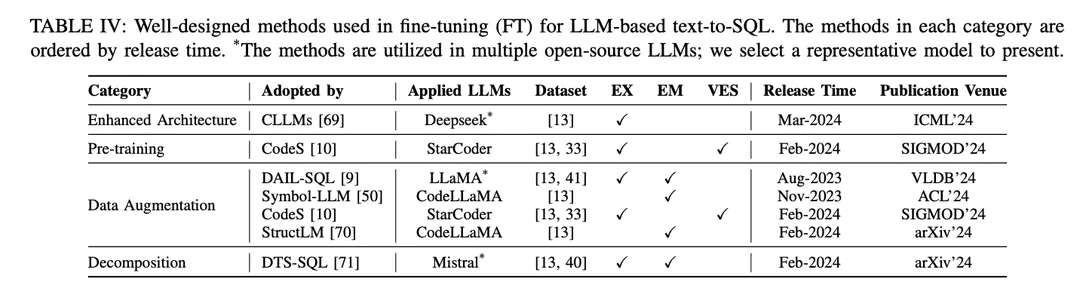
Architecture amélioréeLe cadre largement utilisé du transformateur génératif préformé (GPT) utilise une architecture de transformateur de décodeur uniquement et un désencodage autorégressif traditionnel pour générer du texte. Des études récentes sur l'efficacité des LLM ont révélé un défi commun : la latence des LLM est élevée en raison de la nécessité d'incorporer un mécanisme d'attention lors de la génération de longues séquences à l'aide de modèles autorégressifs [115 , 116 ]. Dans la conversion de texte en SQL basée sur les LLM, la génération de requêtes SQL est nettement plus lente que la modélisation linguistique traditionnelle [21 , 28 ], ce qui constitue un défi pour la construction de bases de données locales NLIDB efficaces. L'une des solutions, CLLM [ 69 ], vise à relever les défis susmentionnés et à accélérer la génération de requêtes SQL grâce à une architecture de modèle améliorée.
Amélioration des donnéesDans le processus de réglage fin, le facteur qui affecte le plus directement les performances du modèle est la qualité des étiquettes d'apprentissage [117]. Le réglage fin avec des étiquettes d'entraînement de faible qualité ou manquantes est une "évidence", et le réglage fin avec des données de haute qualité ou augmentées surpasse toujours les méthodes de réglage fin bien conçues sur des données brutes ou de faible qualité [29, 74]. Des progrès considérables ont été réalisés dans le domaine de la mise au point assistée par les données, du texte au langage SQL, en mettant l'accent sur l'amélioration de la qualité des données dans le cadre du processus SFT.
[117] "Learning from noisy labels with deep neural networks : a survey", [117] "Learning from noisy labels with deep neural networks : a survey".[74] Avancées récentes dans le domaine du text-to-SQL : un aperçu de ce que nous avons et de ce que nous attendons[29] "A survey of large language models" (Enquête sur les grands modèles de langage)DAIL-SQL [9] est conçu comme un cadre d'apprentissage contextuel qui utilise une stratégie d'échantillonnage pour obtenir de meilleures instances d'échantillons moins nombreux. L'incorporation d'instances échantillonnées dans le processus SFT améliore les performances du LLM open source.Symbol-LLM [50] propose des instructions d'augmentation des données adaptées aux phases d'injection et d'infusion.CodeS [10] améliore les données d'entraînement par génération bidirectionnelle à l'aide de ChatGPT.StructLM [70] est entraîné sur plusieurs tâches de connaissance structurelle pour améliorer la capacité globale.
préformationPré-entraînement : Le pré-entraînement est l'étape fondamentale de l'ensemble du processus de mise au point, visant à obtenir des capacités de génération de texte par l'entraînement automatique à la régression sur une grande quantité de données [118]. Traditionnellement, les puissants LLM propriétaires actuels (par exemple, ChatGPT [119], GPT-4 [86], Claude [120]) sont pré-entraînés sur des corpus hybrides, qui bénéficient principalement de scénarios de dialogue affichant des capacités de génération de texte [85]. Les LLM spécifiques au code (par exemple, CodeLLaMA [ 121 ], StarCoder [ 122 ]) sont pré-entraînés sur des données de code [100 ], et le mélange de divers langages de programmation permet aux LLM de générer du code conforme aux instructions de l'utilisateur [123 ]. Le principal défi pour les techniques de pré-entraînement ciblant le langage SQL en tant que sous-tâche de la génération de code est que le contenu lié au langage SQL/à la base de données ne représente qu'une petite partie de l'ensemble du corpus pré-entraîné.
Par conséquent, les LLM open-source avec des capacités de synthèse relativement limitées (par rapport à ChatGPT, GPT-4) ne comprennent pas bien comment transformer les problèmes NL en SQL pendant la préformation. La phase de préformation du modèle CodeS [10] consiste en trois étapes de préformation incrémentale. En partant du LLM de base spécifique au code [122 ], CodeS effectue un pré-entraînement incrémental sur un corpus d'entraînement mixte (comprenant des données liées à SQL, des données de NL à code et des données liées à NL). La compréhension et la performance du texte vers SQL sont améliorées de manière significative.
décompositionLa décomposition d'une tâche en plusieurs étapes ou l'utilisation de plusieurs modèles pour résoudre la tâche est une solution intuitive pour résoudre des scénarios complexes, comme décrit précédemment dans le paradigme ICL au chapitre IV-A. Les modèles propriétaires utilisés dans les approches basées sur l'ICL ont un grand nombre de paramètres, qui se situent à un niveau différent de celui des modèles libres utilisés dans les approches de réglage fin. Ces modèles sont intrinsèquement capables de bien exécuter les sous-tâches assignées (grâce à des mécanismes tels que l'apprentissage avec moins d'échantillons) [30, 57]. Par conséquent, pour reproduire le succès de ce paradigme dans une approche ICL, il est important d'assigner rationnellement les sous-tâches appropriées (par exemple, générer des connaissances externes, lier des schémas et affiner des schémas) aux modèles à source ouverte afin de les affiner pour les sous-tâches spécifiques, et de construire les données appropriées à utiliser dans l'affinage pour aider à la génération du SQL final.
DTS-SQL [71] propose un cadre d'affinage décomposé en deux étapes du texte vers SQL et conçoit une tâche de pré-génération du lien avec le schéma avant la génération finale de SQL.
compter
Malgré les progrès significatifs de la recherche sur la conversion de texte en SQL, certains défis doivent encore être relevés. Cette section aborde les défis restants qui devraient être relevés dans les travaux futurs.
A. Robustesse dans les applications pratiques
La conversion de texte en SQL, mise en œuvre par les LLM, est prometteuse en termes de généralité et de robustesse dans les scénarios d'application complexes du monde réel. Malgré les récents progrès substantiels dans les ensembles de données spécifiques à la robustesse [ 37 , 41], leur performance n'est toujours pas suffisante pour les applications du monde réel [ 33]. Il reste encore quelques défis à relever dans les recherches futures. Du côté de l'utilisateur, il existe un phénomène selon lequel l'utilisateur n'est pas toujours un poseur de question explicite, ce qui signifie que la question de l'utilisateur peut ne pas avoir les valeurs exactes de la base de données ou peut être différente de l'ensemble de données standard, où des synonymes, des fautes d'orthographe et des expressions floues peuvent être inclus [40].
Par exemple, dans le paradigme du réglage fin, le modèle est formé sur des problèmes explicitement indicatifs avec des représentations concrètes. Étant donné que le modèle n'apprend pas la correspondance entre les problèmes du monde réel et les bases de données correspondantes, il existe un manque de connaissances lorsqu'il est appliqué à des scénarios du monde réel [33]. Comme indiqué dans les évaluations correspondantes sur des ensembles de données avec des synonymes et des instructions incomplètes [7 , 51], les requêtes SQL générées par ChatGPT contiennent environ 40% d'exécutions incorrectes, soit 10% de moins que l'évaluation originale [51]. Dans le même temps, le réglage fin à l'aide de textes natifs pour les ensembles de données SQL peut contenir des échantillons et des étiquettes non standardisés. Par exemple, les noms des tables ou des colonnes ne sont pas toujours des représentations exactes de leur contenu, ce qui entraîne des incohérences dans la construction des données d'entraînement.
B. Efficacité informatique
L'efficacité informatique est déterminée par la vitesse de raisonnement et le coût des ressources informatiques, ce qui vaut la peine d'être pris en compte dans les applications et les efforts de recherche [49, 69]. Avec la complexité croissante des bases de données dans les derniers tests de conversion texte-SQL [15, 33], les bases de données contiendront plus d'informations (y compris plus de tables et de colonnes) et la longueur des jetons du schéma de la base de données augmentera en conséquence, ce qui posera un certain nombre de problèmes. Lorsque l'on traite des bases de données ultra-complexes, l'utilisation du schéma correspondant en tant qu'entrée peut se heurter au défi que le coût de l'invocation des LLM propriétaires augmentera de manière significative, dépassant potentiellement la longueur de jeton maximale du modèle, en particulier lors de la mise en œuvre de modèles open-source avec des longueurs de contexte courtes.
En même temps, un autre défi évident est que la plupart des études utilisent des modèles complets comme entrées de modèle, ce qui introduit une grande quantité de redondance [57]. Fournir au LLM les modèles filtrés exacts pertinents au problème directement du côté de l'utilisateur pour réduire le coût et la redondance est une solution potentielle pour améliorer l'efficacité de calcul [30]. La conception d'une méthode précise de filtrage des motifs reste une orientation future. Bien que le paradigme de l'apprentissage contextuel ait atteint une précision prometteuse, des cadres à plusieurs étapes bien conçus ou des méthodes contextuelles étendues augmentent le nombre d'appels API, ce qui améliore les performances du point de vue de l'efficacité du calcul, mais entraîne également une augmentation significative des coûts [8].
Dans les approches connexes [49], le compromis entre la performance et l'efficacité informatique doit être soigneusement pris en compte, et la conception d'une approche d'apprentissage contextuel comparable (ou même meilleure) avec un coût d'interface de programmation d'application inférieur serait une mise en œuvre pratique qui est encore à l'étude. Comparées aux approches basées sur le PLM, les approches basées sur le LLM ont un raisonnement significativement plus lent [ 21, 28]. Accélérer le raisonnement en réduisant la longueur de l'entrée et le nombre d'étapes dans le processus de mise en œuvre est intuitif pour le paradigme de l'apprentissage contextuel. Pour le LLM local, à partir du point de départ [69], d'autres stratégies d'accélération peuvent être étudiées pour améliorer l'architecture du modèle dans les explorations futures.
Pour relever ce défi, l'ajustement du LLM aux biais intentionnels et la conception de stratégies de formation pour les scénarios bruyants bénéficieraient des progrès récents. Par ailleurs, la quantité de données dans les applications du monde réel est relativement plus faible que les références basées sur la recherche. Étant donné que la mise à l'échelle d'une grande quantité de données par le biais de l'annotation manuelle entraîne des coûts de main-d'œuvre élevés, la conception de méthodes d'expansion des données pour obtenir davantage de paires question-SQL apportera un soutien aux LLM lorsque les données sont rares. En outre, le réglage fin des LLM open-source pour les études d'adaptation locale sur des ensembles de données à petite échelle est potentiellement bénéfique. En outre, les extensions pour les scénarios multilingues [ 42 , 124 ] et multimodaux [ 125 ] devraient être étudiées en détail dans les recherches futures, ce qui profiterait à un plus grand nombre de communautés linguistiques et aiderait à construire des interfaces de base de données plus générales.
C. Confidentialité et interprétabilité des données
En tant que partie de la recherche LLM, le texte-vers-SQL basé sur LLM fait également face à des défis généraux qui existent dans la recherche LLM [4 , 126 , 127 ]. D'un point de vue text-to-SQL, ces défis conduisent également à des améliorations potentielles qui peuvent grandement bénéficier à la recherche LLM. Comme mentionné plus tôt dans le chapitre IV-A, les paradigmes d'apprentissage contextuel ont dominé la recherche récente en termes de volume et de performance, avec la plupart des travaux mis en œuvre en utilisant des modèles propriétaires [8, 9]. Un défi immédiat se pose en termes de confidentialité des données, car l'utilisation d'API propriétaires pour gérer la confidentialité des bases de données locales peut présenter un risque de fuite de données. L'utilisation de paradigmes locaux de réglage fin peut partiellement résoudre ce problème.
Néanmoins, la performance du réglage fin vanille est actuellement sous-optimale [9], et les cadres de réglage fin avancés peuvent s'appuyer sur des LLM propriétaires pour l'augmentation des données [10]. Dans l'état actuel des choses, des cadres plus adaptés dans le paradigme de réglage fin local de texte à SQL méritent une attention particulière. Globalement, le développement de l'apprentissage profond a toujours été confronté à des défis en termes d'interprétabilité [127 , 128 ].
Comme il s'agit d'un défi de longue date, de nombreuses recherches ont été menées pour résoudre ce problème [ 129 , 130 ]. Cependant, l'interprétabilité des implémentations basées sur le LLM n'est pas abordée dans la recherche sur la conversion de texte en SQL, que ce soit dans les paradigmes d'apprentissage contextuel ou de réglage fin. Les approches avec des phases de décomposition expliquent les implémentations text-to-SQL d'une perspective de génération par étapes [8, 51]. Sur cette base, l'intégration de recherches avancées sur l'interprétabilité [131, 132] pour améliorer les performances de la conversion texte-SQL, ainsi que l'explication des architectures de modèles locaux en termes de connaissance de la base de données, restent des pistes d'avenir.
D. Expansion
En tant que sous-domaine de la recherche en LLM et en compréhension du langage naturel, une grande partie de la recherche dans ces domaines a été alimentée par l'utilisation de tâches de conversion de texte en SQL [103 , 110 ]. Cependant, la recherche sur la conversion de texte en SQL peut également être étendue à une recherche plus large dans ces domaines. Par exemple, la génération SQL fait partie de la génération de code. Des méthodes de génération de code bien conçues peuvent également atteindre de bonnes performances dans la conversion de texte en SQL [48, 68] et peuvent être généralisées à un large éventail de langages de programmation. La possibilité d'étendre certains cadres personnalisés de conversion de texte en SQL aux études de conversion de NL en code peut également être discutée.
Par exemple, les cadres qui intègrent la sortie d'exécution dans NL-to-code obtiennent également d'excellentes performances dans la génération SQL [8]. Les tentatives d'extension de l'approche consciente de l'exécution dans text-to-SQL avec d'autres modules d'avancement [30, 31] à la génération de code méritent d'être discutées. D'un autre point de vue, il a été discuté précédemment que la conversion de texte en SQL peut améliorer la réponse aux questions (QA) basée sur LLM en fournissant des informations factuelles. Les bases de données peuvent stocker des connaissances relationnelles sous forme d'informations structurelles, et l'AQ basée sur la structure peut potentiellement bénéficier de la conversion de texte en SQL (par exemple, la réponse aux questions basée sur les connaissances, KBQA [ 133 , 134 ]). L'utilisation des structures de base de données pour construire des connaissances factuelles, puis leur combinaison avec un système de conversion de texte en SQL pour permettre la recherche d'informations, peut aider l'AQ à obtenir des connaissances factuelles plus précises [ 135 ]. On s'attend à ce que des recherches plus approfondies sur la conversion de texte en SQL soient menées à l'avenir.
Présentation du produit OlaChat Digital Intelligence Assistant

OlaChat Digital Intelligence Assistant est un nouveau produit d'analyse intelligente des données lancé par le département PCG Big Data Platform de Tencent, qui utilise de grands modèles dans le domaine de l'analyse des données dans la pratique de l'atterrissage. Il a été intégré dans DataTalk, OlaIDE et d'autres plateformes de données internes de Tencent, afin de fournir un soutien intelligent pour l'ensemble du processus d'analyse des scénarios de données. Il contient une série de fonctionnalités telles que text2sql, l'analyse des indicateurs, l'optimisation intelligente de SQL, etc. De l'analyse des données (analyse par glisser-déposer, requête SQL) à la visualisation des données, en passant par l'interprétation et l'attribution des résultats, OlaChat apporte une aide complète pour rendre le travail d'analyse des données plus simple et plus efficace !
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...