
Un article de 10 000 mots sur l'optimisation RAG dans les scénarios DB-GPT du monde réel.
avant-propos
Au cours des deux dernières années, la technologie RAG (Retrieval-Augmented Generation) est progressivement devenue une composante essentielle des intelligences augmentées. En combinant la double capacité de récupération et de génération, RAG est capable d'introduire des connaissances externes, offrant ainsi davantage de possibilités pour l'application de grands modèles dans des scénarios complexes. Cependant, dans les scénarios d'atterrissage pratiques, il y a souvent des problèmes de faible précision de récupération, d'interférence de bruit, d'exhaustivité de rappel et de professionnalisme insuffisant, ce qui conduit à de graves illusions LLM. Dans cet article, nous nous concentrerons sur le traitement des connaissances et les détails de la récupération du RAG dans des scénarios d'atterrissage réels, et sur la manière d'optimiser le lien Pineline du RAG pour améliorer en fin de compte la précision du rappel.
Il est facile de créer rapidement une application RAG smart Q&A, mais l'intégrer dans un scénario d'entreprise réel demande beaucoup de préparation.
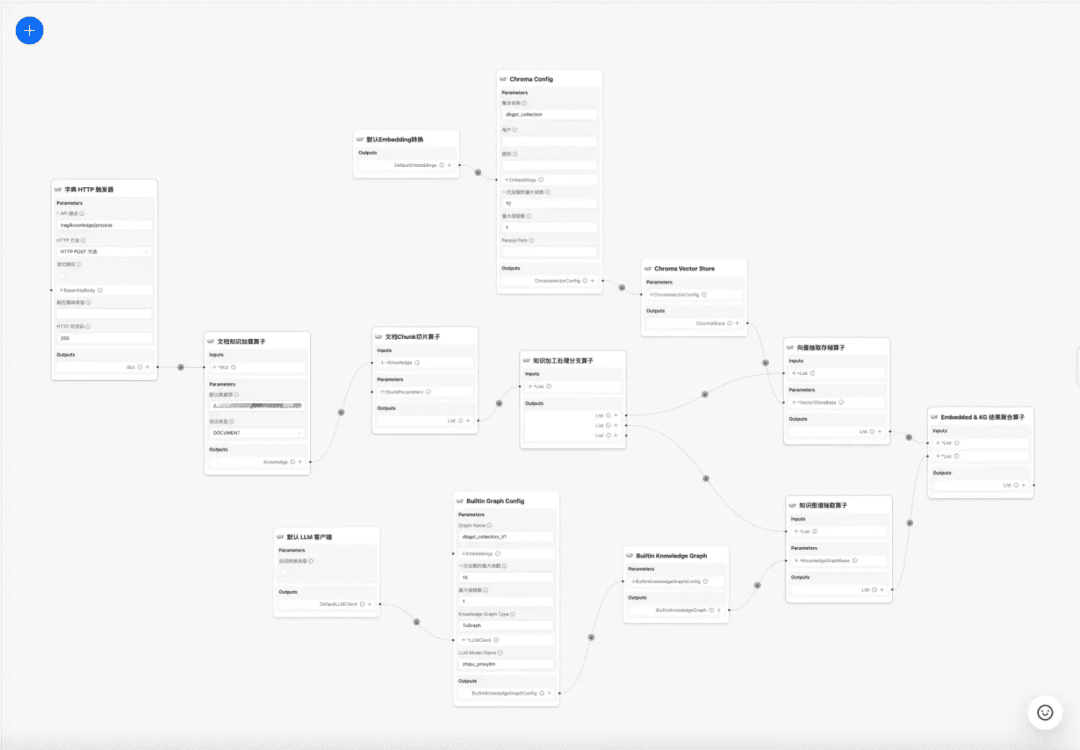
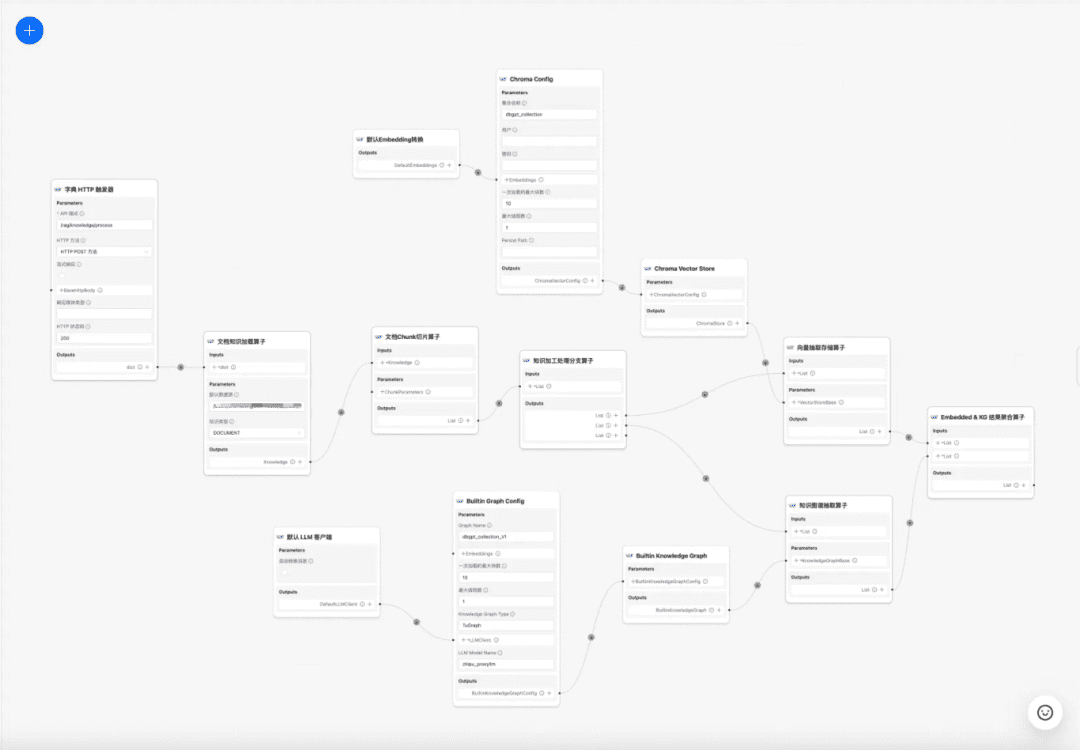
1.RAG Interprétation du code source du processus clé
centretraitement des connaissancesrépondre en chantantRAGQuelques-uns des processus clés :
1. le traitement des connaissances
Chargement des connaissances -> Découpage des connaissances -> Extraction des informations -> Traitement des connaissances (intégration/graphique/mots-clés) -> Stockage des connaissances
- Chargement des connaissances
# 知识工厂进行实例化 KnowledgeFactory -> create() -> load() -> Document - knowledge - markdown - pdf - docx - txt - html - pptx - url - ...
Comment l'étendre :
from abc import ABC from typing import List, Any class Knowledge(ABC): def load(self) -> List[Document]: """Load knowledge from data loader.""" pass @classmethod def document_type(cls) -> Any: """Get document type.""" pass @classmethod def support_chunk_strategy(cls) -> List[ChunkStrategy]: """Return supported chunk strategy.""" return [ ChunkStrategy.CHUNK_BY_SIZE, ChunkStrategy.CHUNK_BY_PAGE, ChunkStrategy.CHUNK_BY_PARAGRAPH, ChunkStrategy.CHUNK_BY_MARKDOWN_HEADER, ChunkStrategy.CHUNK_BY_SEPARATOR, ] @classmethod def default_chunk_strategy(cls) -> ChunkStrategy: """ Return default chunk strategy. Returns: ChunkStrategy: default chunk strategy """ return ChunkStrategy.CHUNK_BY_SIZE
- tranche de connaissances
ChunkManager : achemine les données de connaissance chargées vers le processeur de chunk correspondant pour une allocation basée sur la politique et les paramètres de chunking spécifiés par l'utilisateur.
class ChunkManager: """Manager for chunks.""" def __init__( self, knowledge: Knowledge, chunk_parameter: Optional[ChunkParameters] = None, extractor: Optional[Extractor] = None, ): """ Create a new ChunkManager with the given knowledge. Args: knowledge: (Knowledge) Knowledge datasource. chunk_parameter: (Optional[ChunkParameters]) Chunk parameter. extractor: (Optional[Extractor]) Extractor to use for summarization. """ self._knowledge = knowledge self._extractor = extractor self._chunk_parameters = chunk_parameter or ChunkParameters() self._chunk_strategy = ( chunk_parameter.chunk_strategy if chunk_parameter and chunk_parameter.chunk_strategy else self._knowledge.default_chunk_strategy().name ) self._text_splitter = self._chunk_parameters.text_splitter self._splitter_type = self._chunk_parameters.splitter_type
Comment l'étendre : si vous souhaitez personnaliser une nouvelle stratégie de découpage dans l'interface
- Nouvelle stratégie de découpage
- Nouvelle logique de mise en œuvre du séparateur
class ChunkStrategy(Enum):
"""Chunk Strategy Enum."""
CHUNK_BY_SIZE: _STRATEGY_ENUM_TYPE = (
RecursiveCharacterTextSplitter,
[
{
"param_name": "chunk_size",
"param_type": "int",
"default_value": 512,
"description": "The size of the data chunks used in processing.",
},
{
"param_name": "chunk_overlap",
"param_type": "int",
"default_value": 50,
"description": "The amount of overlap between adjacent data chunks.",
},
],
"chunk size",
"split document by chunk size",
)
CHUNK_BY_PAGE: _STRATEGY_ENUM_TYPE = (
PageTextSplitter,
[],
"page",
"split document by page",
)
CHUNK_BY_PARAGRAPH: _STRATEGY_ENUM_TYPE = (
ParagraphTextSplitter,
[
{
"param_name": "separator",
"param_type": "string",
"default_value": "\n",
"description": "paragraph separator",
}
],
"paragraph",
"split document by paragraph",
)
CHUNK_BY_SEPARATOR: _STRATEGY_ENUM_TYPE = (
SeparatorTextSplitter,
[
{
"param_name": "separator",
"param_type": "string",
"default_value": "\n",
"description": "chunk separator",
},
{
"param_name": "enable_merge",
"param_type": "boolean",
"default_value": False,
"description": (
"Whether to merge according to the chunk_size after "
"splitting by the separator."
),
},
],
"separator",
"split document by separator",
)
CHUNK_BY_MARKDOWN_HEADER: _STRATEGY_ENUM_TYPE = (
MarkdownHeaderTextSplitter,
[],
"markdown header",
"split document by markdown header",
)
- Extraction de connaissances
- Extraction de vecteurs -> intégration, mise en œuvre
Embeddingsconnecteur
@abstractmethod def embed_documents(self, texts: List[str]) -> List[List[float]]: """Embed search docs.""" @abstractmethod def embed_query(self, text: str) -> List[float]: """Embed query text.""" async def aembed_documents(self, texts: List[str]) -> List[List[float]]: """Asynchronous Embed search docs.""" return await asyncio.get_running_loop().run_in_executor( None, self.embed_documents, texts ) async def aembed_query(self, text: str) -> List[float]: """Asynchronous Embed query text.""" return await asyncio.get_running_loop().run_in_executor( None, self.embed_query, text )
# EMBEDDING_MODEL=proxy_openai
# proxy_openai_proxy_server_url=https://api.openai.com/v1
# proxy_openai_proxy_api_key={your-openai-sk}
# proxy_openai_proxy_backend=text-embedding-ada-002
## qwen embedding model, See dbgpt/model/parameter.py
# EMBEDDING_MODEL=proxy_tongyi
# proxy_tongyi_proxy_backend=text-embedding-v1
# proxy_tongyi_proxy_api_key={your-api-key}
## qianfan embedding model, See dbgpt/model/parameter.py
# EMBEDDING_MODEL=proxy_qianfan
# proxy_qianfan_proxy_backend=bge-large-zh
# proxy_qianfan_proxy_api_key={your-api-key}
# proxy_qianfan_proxy_api_secret={your-secret-key}
- Extraction d'un graphe de connaissances -> graphe de connaissances
class TripletExtractor(LLMExtractor):
"""TripletExtractor class."""
def __init__(self, llm_client: LLMClient, model_name: str):
"""Initialize the TripletExtractor."""
super().__init__(llm_client, model_name, TRIPLET_EXTRACT_PT)
TRIPLET_EXTRACT_PT = (
"Some text is provided below. Given the text, "
"extract up to knowledge triplets as more as possible "
"in the form of (subject, predicate, object).\n"
"Avoid stopwords. The subject, predicate, object can not be none.\n"
"---------------------\n"
"Example:\n"
"Text: Alice is Bob's mother.\n"
"Triplets:\n(Alice, is mother of, Bob)\n"
"Text: Alice has 2 apples.\n"
"Triplets:\n(Alice, has 2, apple)\n"
"Text: Alice was given 1 apple by Bob.\n"
"Triplets:(Bob, gives 1 apple, Alice)\n"
"Text: Alice was pushed by Bob.\n"
"Triplets:(Bob, pushes, Alice)\n"
"Text: Bob's mother Alice has 2 apples.\n"
"Triplets:\n(Alice, is mother of, Bob)\n(Alice, has 2, apple)\n"
"Text: A Big monkey climbed up the tall fruit tree and picked 3 peaches.\n"
"Triplets:\n(monkey, climbed up, fruit tree)\n(monkey, picked 3, peach)\n"
"Text: Alice has 2 apples, she gives 1 to Bob.\n"
"Triplets:\n"
"(Alice, has 2, apple)\n(Alice, gives 1 apple, Bob)\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Triplets:\n"
"(Philz, is, coffee shop)\n(Philz, founded in, Berkeley)\n"
"(Philz, founded in, 1982)\n"
"---------------------\n"
"Text: {text}\n"
"Triplets:\n"
)
- Extraction d'index inversé -> segmentation des mots-clés
- Vous pouvez utiliser le lexique par défaut de es, ou vous pouvez personnaliser le lexique en utilisant le mode plugin de es.
- Extraction d'index inversé -> segmentation des mots-clés
- Stockage des connaissances
La persistance de l'ensemble des connaissances est assurée de manière uniformeIndexStoreBasefournit actuellement trois types d'implémentations : les bases de données vectorielles, les bases de données graphiques, l'indexation en texte intégral

- VectorStore, la logique principale de la base de données vectorielle se trouve dans load_document(), y compris la création d'un schéma d'index, l'écriture de données vectorielles par lots, etc.
# Base class hierarchy - VectorStoreBase - ChromaStore - MilvusStore - OceanbaseStore - ElasticsearchStore - PGVectorStore # Base class definition class VectorStoreBase(IndexStoreBase, ABC): """ Vector store base class. """ @abstractmethod def load_document(self, chunks: List[Chunk]) -> List[str]: """ Load document in index database. """ pass @abstractmethod async def aload_document(self, chunks: List[Chunk]) -> List[str]: """ Load document in index database asynchronously. """ pass @abstractmethod def similar_search_with_scores( self, text: str, topk: int, score_threshold: float, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Perform a similar search with scores in the index database. """ pass def similar_search( self, text: str, topk: int, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Perform a similar search in the index database. """ return self.similar_search_with_scores(text, topk, 1.0, filters)
- GraphStore , un magasin de graphes concret fournit une implémentation de l'écriture ternaire, ce qui est généralement fait en appelant le langage de requête d'une base de données de graphes concrète. Par exemple
TuGraphStoreUne instruction Cypher spécifique sera générée et exécutée en fonction du ternaire.
- L'interface de stockage de graphes GraphStoreBase fournit une abstraction unifiée pour le stockage de graphes et intègre actuellement les éléments suivants
MemoryGraphStorerépondre en chantantTuGraphStorenous fournissons également l'interface Neo4j aux développeurs pour qu'ils puissent y accéder.
- L'interface de stockage de graphes GraphStoreBase fournit une abstraction unifiée pour le stockage de graphes et intègre actuellement les éléments suivants
# GraphStoreBase -> TuGraphStore -> Neo4jStore
def insert_triplet(self, subj: str, rel: str, obj: str) -> None:
"""Add triplet."""
# Create queries to merge nodes and relationship
subj_query = f"MERGE (n1:{self._node_label} {{id:'{subj}'}})"
obj_query = f"MERGE (n2:{self._node_label} {{id:'{obj}'}})"
rel_query = (
f"MERGE (n1:{self._node_label} {{id:'{subj}'}})"
f"-[r:{self._edge_label} {{id:'{rel}'}}]->"
f"(n2:{self._node_label} {{id:'{obj}'}})"
)
# Execute queries
self.conn.run(query=subj_query)
self.conn.run(query=obj_query)
self.conn.run(query=rel_query)
- FullTextStore : en construisant l'index es, par l'intermédiaire de l'algorithme de découpage des mots intégré à es, puis en construisant l'index inversé mot-clé->doc_id.
{
"analysis": {
"analyzer": {
"default": {
"type": "standard"
}
}
},
"similarity": {
"custom_bm25": {
"type": "BM25",
"k1": self._k1,
"b": self._b
}
}
}
self._es_mappings = {
"properties": {
"content": {
"type": "text",
"similarity": "custom_bm25"
},
"metadata": {
"type": "keyword"
}
}
}
# FullTextStoreBase
# ElasticDocumentStore
# OpenSearchStore
2. recherche de connaissances
question -> réécriture -> recherche de similarité -> rerank -> candidats contextuels
Ensuite, il y a la récupération des connaissances, la logique actuelle de récupération de la communauté est principalement divisée en ces étapes, si vous définissez les paramètres de réécriture de la requête, vous obtiendrez actuellement un cycle de réécriture de la question par le biais du grand modèle, puis il sera acheminé vers le récupérateur correspondant en fonction de votre mode de traitement des connaissances, si vous êtes traité par les vecteurs, il sera récupéré par le récupérateur EmbeddingRetriever, si vous construisez un mode de construction par le biais du graphe de connaissances, il sera récupéré en fonction du graphe de connaissances. est construit à l'aide d'un graphe de connaissances, il sera récupéré selon la méthode du graphe de connaissances, et si vous mettez en place le modèle de classement, il donnera aux valeurs candidates après la sélection grossière une sélection fine pour rendre les valeurs candidates plus pertinentes par rapport à la question de l'utilisateur.
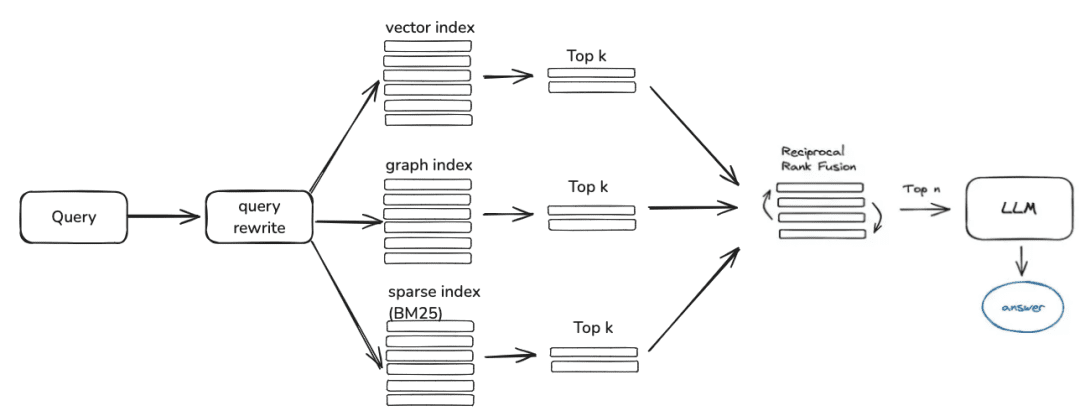
- EmbeddingRetriever
class EmbeddingRetriever(BaseRetriever): """Embedding retriever.""" def __init__( self, index_store: IndexStoreBase, top_k: int = 4, query_rewrite: Optional[QueryRewrite] = None, rerank: Optional[Ranker] = None, retrieve_strategy: Optional[RetrieverStrategy] = RetrieverStrategy.EMBEDDING, ): pass async def _aretrieve_with_score( self, query: str, score_threshold: float, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Retrieve knowledge chunks with score. Args: query (str): Query text. score_threshold (float): Score threshold. filters: Metadata filters. Returns: List[Chunk]: List of chunks with score. """ queries = [query] new_queries = await self._query_rewrite.rewrite( origin_query=query, context=context, nums=1 ) queries.extend(new_queries) candidates_with_score = [ self._similarity_search_with_score( query, score_threshold, filters, root_tracer.get_current_span_id() ) for query in queries ] new_candidates_with_score = await self._rerank.arank( new_candidates_with_score, query ) return new_candidates_with_score
- index_store : base de données vectorielle spécifique
- top_k : le nombre de blocs candidats spécifiques renvoyés
- query_rewrite : fonction de réécriture des requêtes
- rerank : fonction de réorganisation
- query:Requête originale
- score_threshold : score, par défaut nous filtrons les contextes dont le score de similarité est inférieur au seuil.
- des filtres :
Optional[MetadataFilters]Le filtre d'informations sur les métadonnées peut être utilisé principalement pour passer au crible les informations sur les attributs afin d'éliminer certaines informations candidates qui ne correspondent pas.
from enum import Enum from typing import Union, List from pydantic import BaseModel, Field class FilterCondition(str, Enum): """Vector Store Meta data filter conditions.""" AND = "and" OR = "or" class MetadataFilter(BaseModel): """Meta data filter.""" key: str = Field( ..., description="The key of metadata to filter." ) operator: FilterOperator = Field( default=FilterOperator.EQ, description="The operator of metadata filter." ) value: Union[str, int, float, List[str], List[int], List[float]] = Field( ..., description="The value of metadata to filter." )
- Graphique RAG
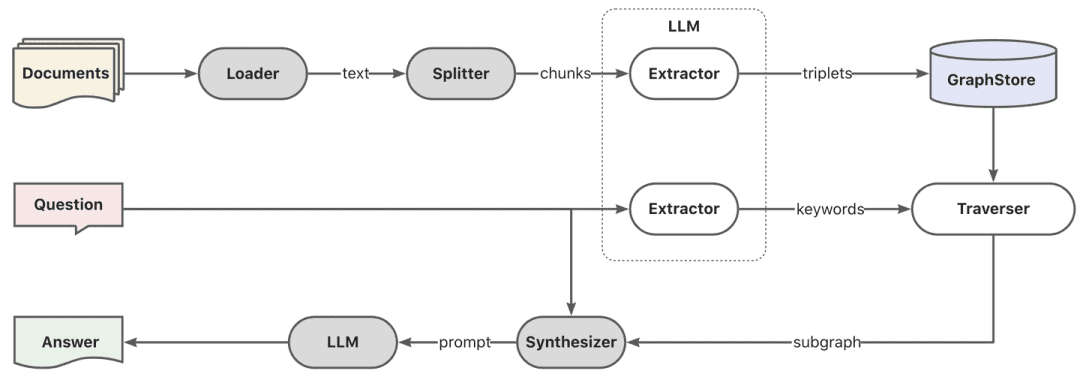
Tout d'abord, l'extraction des mots-clés est effectuée à l'aide du modèle, qui peut être réalisé par la technique nlp traditionnelle pour le découpage des mots, ou par le grand modèle pour le découpage des mots, puis les mots-clés sont utilisés conformément aux synonymes pour effectuer l'expansion, afin de trouver la liste des mots-clés candidats, et il est préférable d'appeler la méthode d'exploration pour rappeler les sous-graphes locaux en fonction de la liste des mots-clés candidats.
KEYWORD_EXTRACT_PT = (
"A question is provided below. Given the question, extract up to "
"keywords from the text. Focus on extracting the keywords that we can use "
"to best lookup answers to the question.\n"
"Generate as more as possible synonyms or alias of the keywords "
"considering possible cases of capitalization, pluralization, "
"common expressions, etc.\n"
"Avoid stopwords.\n"
"Provide the keywords and synonyms in comma-separated format."
"Formatted keywords and synonyms text should be separated by a semicolon.\n"
"---------------------\n"
"Example:\n"
"Text: Alice is Bob's mother.\n"
"Keywords:\nAlice,mother,Bob;mummy\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Keywords:\nPhilz,coffee shop,Berkeley,1982;coffee bar,coffee house\n"
"---------------------\n"
"Text: {text}\n"
"Keywords:\n"
)
def explore(
self,
subs: List[str],
direct: Direction = Direction.BOTH,
depth: Optional[int] = None,
fan: Optional[int] = None,
limit: Optional[int] = None,
) -> Graph:
"""Explore on graph."""
DBSchemaRetrieverIl s'agit en partie d'une recherche de liens de schémas pour les scénarios ChatDataIl s'agit principalement d'une méthode de recherche de similarités en deux étapes, qui consiste à trouver d'abord la table la plus pertinente, puis l'information la plus pertinente sur le champ.
Avantages : cette recherche en deux étapes vise également à répondre aux commentaires de la communauté concernant l'expérience de la grande table large.
def _similarity_search(self, query, filters: Optional[MetadataFilters] = None) -> List[Chunk]:
"""Similar search."""
# Perform similarity search with scores
table_chunks = self._table_vector_store_connector.similar_search_with_scores(
query, self._top_k, 0, filters
)
# Filter out chunks with 'separated' metadata
not_sep_chunks = [
chunk for chunk in table_chunks if not chunk.metadata.get("separated")
]
separated_chunks = [
chunk for chunk in table_chunks if chunk.metadata.get("separated")
]
# If no separated chunks, return the non-separated chunks
if not separated_chunks:
return not_sep_chunks
# Create tasks list for retrieving fields from separated chunks
tasks = [
lambda c=chunk: self._retrieve_field(c, query) for chunk in separated_chunks
]
# Run tasks concurrently with a concurrency limit of 3
separated_result = run_tasks(tasks, concurrency_limit=3)
# Combine and return results
return not_sep_chunks + separated_result
- table_vector_store_connector : responsable de la récupération de la table la plus pertinente.
- field_vector_store_connector : responsable de la récupération des champs les plus pertinents.
2. traitement des connaissances, idées d'optimisation de l'extraction des connaissances
Actuellement, les applications RAG smart quiz présentent plusieurs points faibles :
- Lorsque la base de connaissances contient de plus en plus de documents, la recherche est bruyante et la précision du rappel n'est pas élevée.
- Rappels incomplets et manque d'exhaustivité
- Les rappels et l'intention de la question de l'utilisateur sont peu pertinents
- Le fait de ne pouvoir répondre qu'à des données statiques et de ne pas pouvoir accéder à des connaissances de manière dynamique conduit à une application de réponse ennuyeuse et stupide.
1. Optimisation du traitement des connaissances
Le traitement des données non structurées/semi-structurées/structurées est prêt à déterminer la limite supérieure de l'application RAG, il faut donc tout d'abord effectuer un travail ETL très fin dans le traitement des connaissances, l'étape d'indexation, l'optimisation principale de l'orientation de l'idée :
- Non structuré -> Structuré : organiser les informations sur les connaissances de manière structurée.
- Extraire des informations sémantiques plus riches et plus diversifiées.
1.1 Chargement des connaissances
Objectif : Une analyse précise des documents est nécessaire pour identifier les différents types de données de manière plus diversifiée.
Recommandations d'optimisation :
- Il est recommandé de traiter les textes docx, txt ou autres avant de les convertir en format pdf ou markdown, afin de pouvoir utiliser certains outils de reconnaissance pour mieux extraire le contenu du texte.
- Extrait des informations sur les tableaux à partir d'un texte.
- Préserver les informations sur la hiérarchie des titres markdown et pdf, pour le prochain arbre hiérarchique et les autres méthodes d'indexation à préparer.
- Conserver les liens vers les images, les formules et d'autres informations, également traitées de manière uniforme au format markdown.
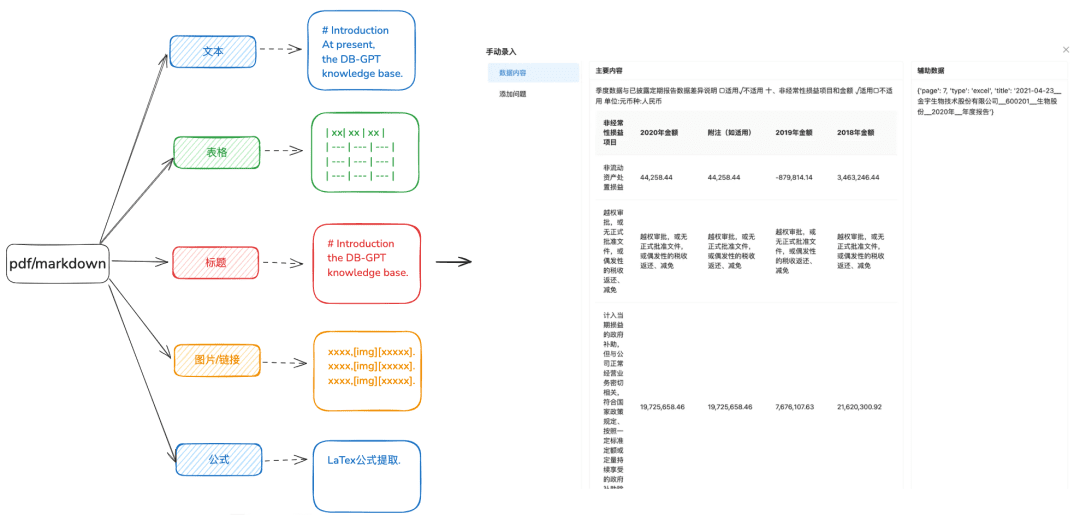
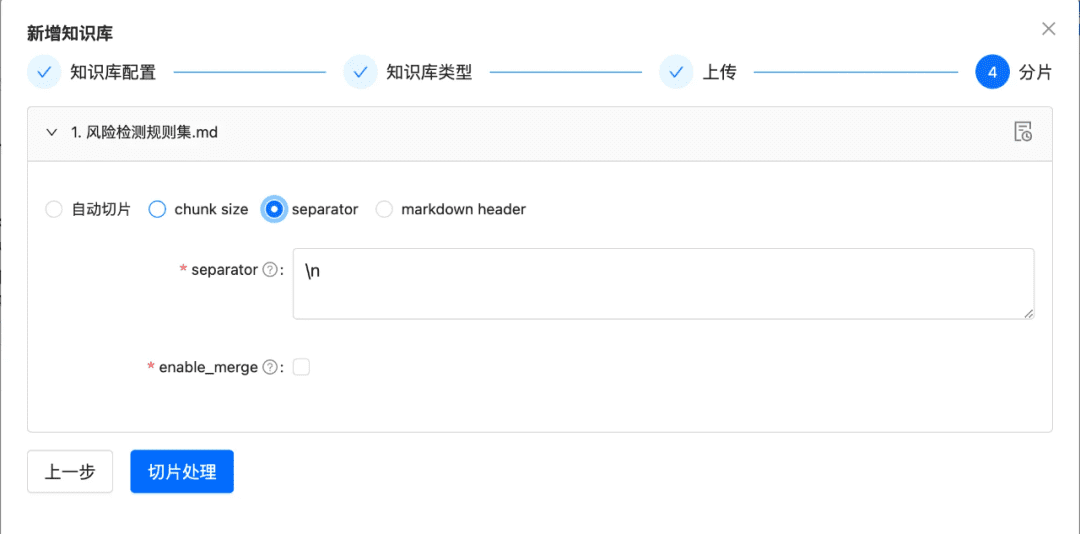
1.2 Trancher le morceau le plus intact possible
Objectif : préserver l'intégrité et la pertinence du contexte, qui sont directement liées à la précision des réponses.
En restant dans les limites contextuelles du modèle plus large, le découpage en morceaux garantit que l'entrée de texte dans les LLM ne dépasse pas leurs limites de jetons.
Recommandations d'optimisation :
- Images + tableaux extraits en tant que morceaux séparés, en conservant les légendes des tableaux et des images dans les métadonnées.
- Le contenu du document est divisé autant que possible en fonction de la hiérarchie des en-têtes ou de l'en-tête Markdown, en préservant autant que possible l'intégrité du morceau.
- S'il existe un séparateur personnalisé, vous pouvez découper en fonction de ce séparateur.
1.3 Extraction d'informations diversifiées
En plus de l'extraction du vecteur d'intégration des documents, d'autres extractions d'informations diversifiées peuvent renforcer les données des documents et améliorer de manière significative l'effet de rappel du RAG.
- carte des connaissances
- Avantages : 1. le manque d'exhaustivité de NativeRAG pose toujours le problème de l'illusion, et la précision des connaissances, y compris l'exhaustivité des limites des connaissances, la clarté de la structure des connaissances et de la sémantique, est un complément sémantique à la capacité de recherche de similarités.
- Scénarios : pour des domaines professionnels rigoureux (soins de santé, O&M, etc.) où la préparation des connaissances doit être limitée et où les relations hiérarchiques entre les connaissances peuvent être clairement établies.
- Comment y parvenir ?
1. dépendre du grand modèle pour extraire la relation ternaire (entité, relation, entité).
2. en s'appuyant sur la préparation, le nettoyage et l'extraction de connaissances structurées de qualité préalable, par le biais de règles de gestion manuelles ou d'un processus SOP personnalisé, afin de construire le graphe de connaissances.
- Doc Tree
- Scénarios applicables : résout le problème du manque d'intégrité contextuelle, mais aussi les correspondances basées uniquement sur la sémantique et les mots-clés, et peut réduire le bruit.
- Comment y parvenir : construire un nœud arborescent de morceaux au niveau du titre pour former une structure arborescente multinomiale, où chaque nœud de niveau ne doit stocker que le titre du document et les nœuds de feuille le contenu textuel spécifique. De cette manière, en utilisant l'algorithme de traversée de l'arbre, si une question d'utilisateur tombe sur un nœud de titre non feuille pertinent, les données du nœud enfant pertinent peuvent être rappelées. Il n'y a donc pas de problème de manque d'intégrité des morceaux.
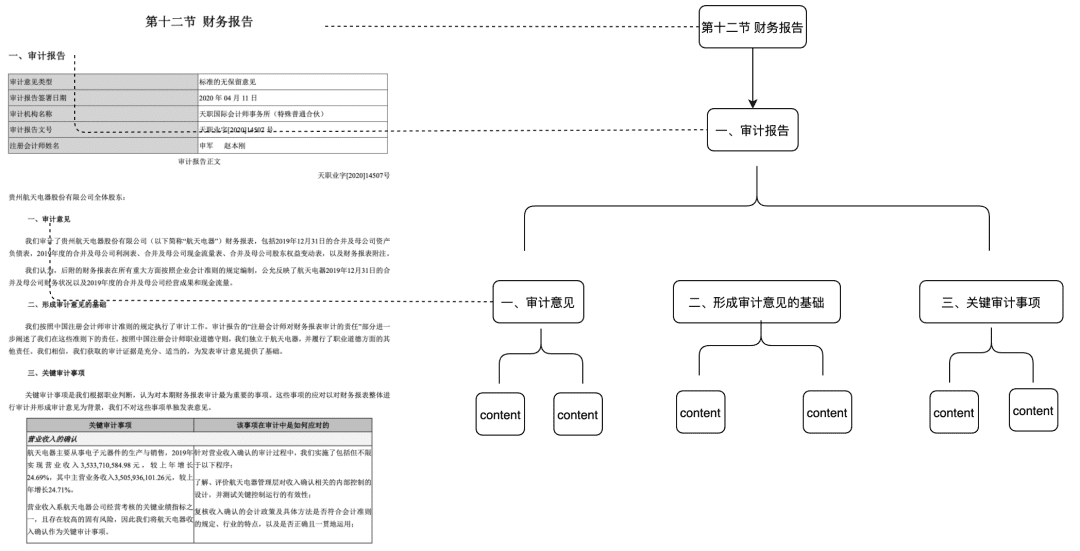
Cette partie du dispositif sera également mise à la disposition de la communauté au début de l'année prochaine.
- L'extraction des paires d'AQ nécessite l'extraction en amont des informations relatives aux paires d'AQ au moyen de méthodes d'extraction prédéfinies ou modélisées.
- Scénarios applicables :
- La capacité d'atteindre la question dans la récupération et le rappel direct, de récupérer directement la réponse souhaitée par l'utilisateur, s'applique à certains scénarios de FAQ, l'intégrité du rappel n'est pas suffisante.
- Comment y parvenir ?
- Prédéfini : ajouter à l'avance des questions pour chaque élément.
- Extraction du modèle : étant donné un contexte, le modèle doit effectuer l'extraction des paires d'AQ.
- Extraction des métadonnées
- Comment y parvenir : en fonction des caractéristiques des données de l'entreprise, extraire les caractéristiques des données à conserver, telles que les balises, les catégories, l'heure, la version et d'autres attributs de métadonnées.
- Scénarios applicables : la recherche peut être pré-filtrée sur la base des attributs des métadonnées afin d'éliminer la plus grande partie du bruit.
- Résumer et extraire
- Scénarios applicables : résolution
这篇文章讲了个啥(math.) genre总结一下et d'autres scénarios de problèmes mondiaux. - Comment mettre en œuvre : extraction segmentée via mapreduce etc., extraction d'informations sommaires pour chaque morceau via un modèle.
- Scénarios applicables : résolution
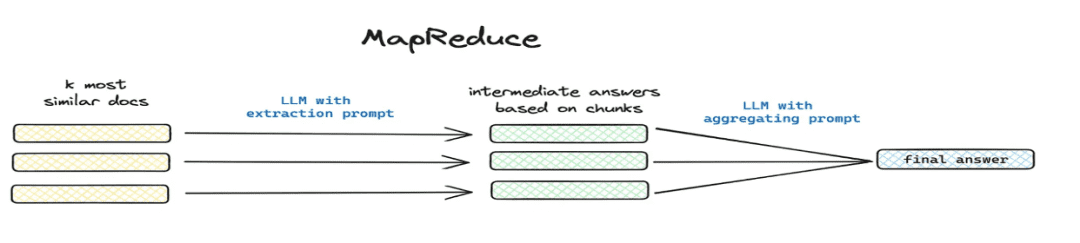
1.4 Processus de traitement des connaissances
à l'heure actuelle DB-GPT La base de connaissances offre des capacités de traitement des connaissances telles que le téléchargement de documents -> l'analyse -> le découpage -> l'intégration -> l'extraction de triades de graphes de connaissances -> le stockage de bases de données vectorielles -> le stockage de bases de données de graphes, etc., mais elle n'a pas la capacité d'extraire des informations complexes et personnalisées à partir de documents. Par conséquent, nous espérons construire un modèle de flux de travail pour le traitement des connaissances afin de compléter les processus d'extraction, de conversion et de traitement des connaissances complexes, visuels et définissables par l'utilisateur.
Processus de traitement des connaissances :
https://www.yuque.com/eosphoros/dbgpt-docs/vg2gsfyf3x9fuglf
2. optimisation du processus de GCR L'optimisation du processus de GCR se subdivise en GCR de documents statiques et en GCR d'acquisition de données dynamiques ; la plupart des GCR actuels ne couvrent que les actifs statiques de documents non structurés, mais l'activité réelle de nombreux scénarios de questions et réponses passe par l'outil pour obtenir des données dynamiques + des données de connaissances statiques afin de répondre au scénario ; il faut non seulement récupérer les connaissances statiques, mais aussi être GCR. récupérer les informations relatives aux outils dans la bibliothèque d'outils et procéder à l'acquisition de données dynamiques.
2.1 Optimisation du RAG des connaissances statiques
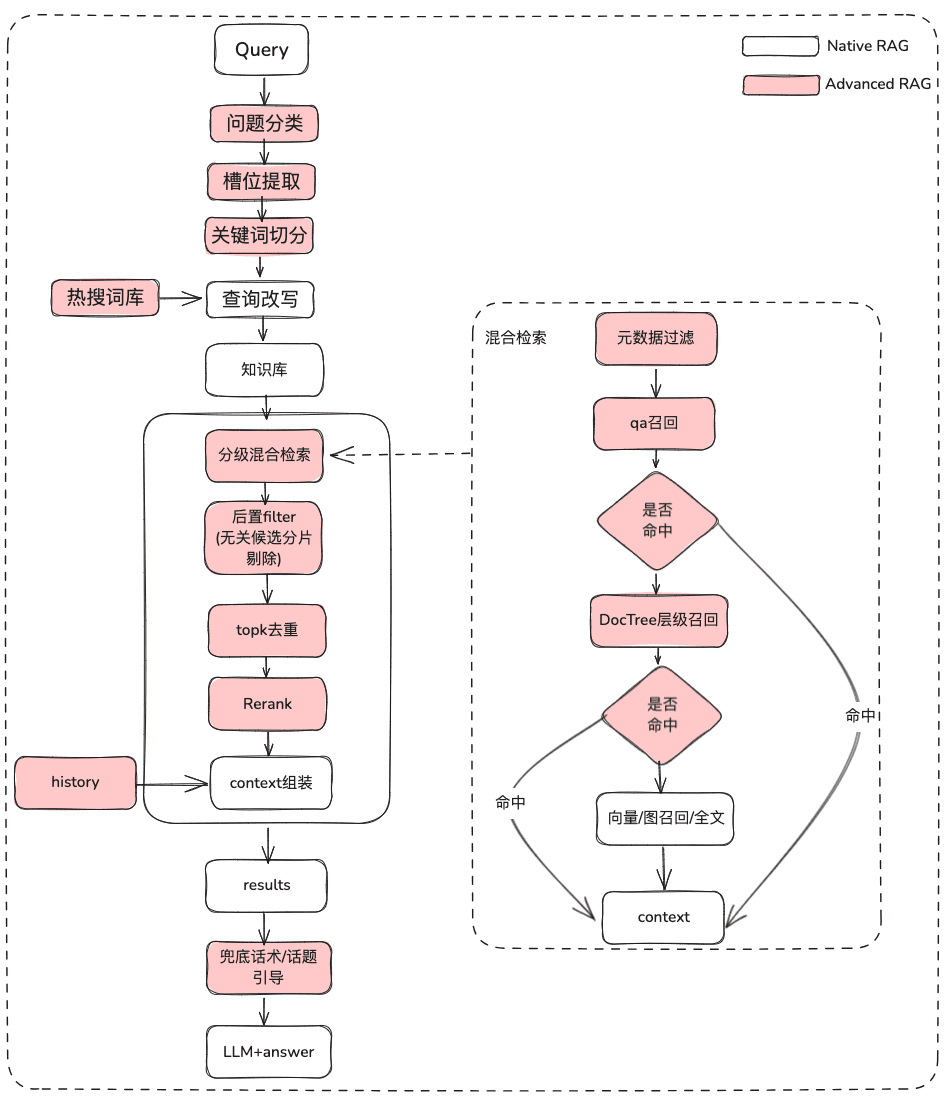
(1) Traitement du problème initial
Objectif : clarifier la sémantique de l'utilisateur et optimiser la question initiale de l'utilisateur en la transformant d'une requête floue et mal intentionnée en une requête récupérable plus riche de sens.
- La classification des problèmes bruts, qui permet de les
- Classification LLM (
LLMExtractor) - Construction de l'intégration + régression logistique pour implémenter un modèle à deux tours, text2nlu DB-GPT-Hub/src/dbgpt-hub-nlu/README.zh.md at main - eosphoros-ai/DB-GPT-Hub
- Classification LLM (
- Conseil : si vous avez besoin d'un modèle d'intégration de haute qualité, nous vous recommandons le modèle bge-v1.5-large.
- Demander à l'utilisateur de répondre et, si la sémantique n'est pas claire, lui renvoyer la question pour qu'il la clarifie, par le biais de plusieurs cycles d'interaction.
- Suggère à l'utilisateur une liste restreinte de questions basées sur la pertinence sémantique à l'aide d'un thésaurus consultable.
- L'extraction de créneaux, qui vise à obtenir des informations clés dans la question de l'utilisateur, telles que l'intention, les attributs de l'entreprise, etc.
- Extraction LLM (
LLMExtractor)
- Extraction LLM (
- Réécrire la question
- Réécriture du thésaurus Hot Search
- interaction à plusieurs niveaux
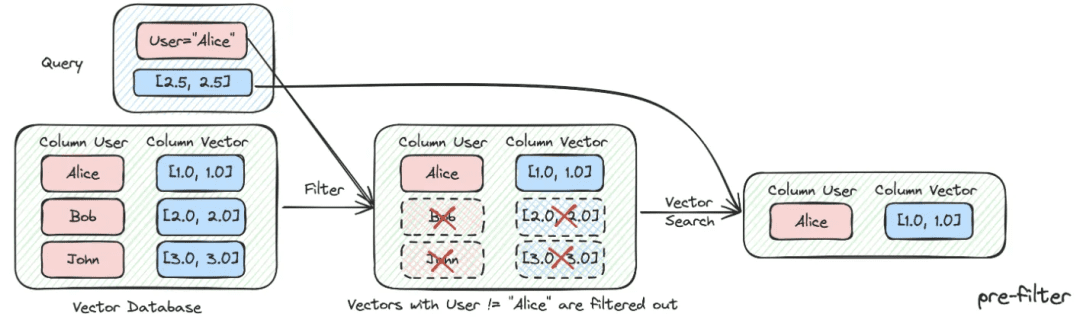
(2) Filtrage des métadonnées
Lorsque l'index est divisé en plusieurs parties et qu'il est stocké dans le même espace de connaissances, l'efficacité de la recherche devient problématique. Par exemple, lorsque les utilisateurs demandent des informations sur "Zhejiang I Wu Technology Company", ils ne veulent pas se rappeler des informations sur d'autres entreprises. Par conséquent, si vous pouvez filtrer d'abord par l'attribut de métadonnées du nom de l'entreprise, l'efficacité et la pertinence s'en trouveront grandement améliorées.
async def aretrieve( self, query: str, filters: Optional[MetadataFilters] = None ) -> List[Chunk]: """ Retrieve knowledge chunks. Args: query (str): async query text. filters (Optional[MetadataFilters]): metadata filters. Returns: List[Chunk]: list of chunks """ return await self._aretrieve(query, filters)
(3) Rappel hybride multi-stratégies
- Définir des priorités pour les différents récupérateurs en fonction de la priorité de rappel, et renvoyer le contenu dès qu'il est récupéré.
- Définir différentes extractions telles que qa_retriever, doc_tree_retriever à écrire dans la file d'attente, et obtenir un rappel prioritaire grâce à la propriété "premier entré-premier sorti" de la file d'attente.
class RetrieverChain(BaseRetriever): """Retriever chain class.""" def __init__( self, retrievers: Optional[List[BaseRetriever]] = None, executor: Optional[Executor] = None, ): """Create retriever chain instance.""" self._retrievers = retrievers or [] self._executor = executor or ThreadPoolExecutor() async def retrieve(self, query: str, score_threshold: float, filters: Optional[dict] = None): """Perform retrieval with the given query, score threshold, and filters.""" for retriever in self._retrievers: candidates_with_scores = await retriever.aretrieve_with_scores( query=query, score_threshold=score_threshold, filters=filters ) if candidates_with_scores: return candidates_with_scores
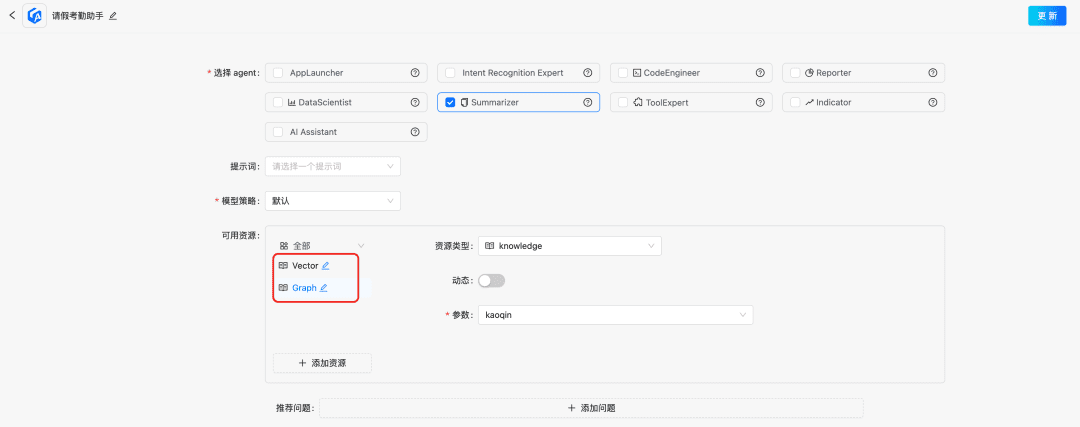
- Indexation des connaissances multiples/rappel parallèle spatial
- Obtenir des listes de candidats par rappel parallèle à travers différentes formes d'indexation des connaissances afin de garantir l'exhaustivité du rappel.
(4) Post-filtrage
Après avoir passé en revue la liste des candidats, comment filtrer le bruit par le biais d'une sélection fine ?
- Elimination des tranches de candidats non pertinents
- Rejet de la demande en temps voulu
- Les attributs commerciaux ne satisfont pas aux critères de sélection
- déduplication topk
- Réorganisation Il ne suffit pas de s'appuyer sur le rappel de la sélection grossière, à ce stade, nous devons disposer de stratégies pour réorganiser les résultats récupérés, par exemple en réajustant des facteurs tels que la pertinence de la combinaison, la correspondance, etc. pour obtenir une classification plus conforme à nos scénarios commerciaux. Parce qu'après cette étape, nous enverrons les résultats au LLM pour le traitement final, les résultats de cette partie sont donc très importants.
- Sélection fine à l'aide de modèles de réorganisation pertinents, qu'il s'agisse de modèles à code source ouvert ou de modèles à sémantique commerciale affinée.
## Rerank model # RERANK_MODEL = bce-reranker-base #### If you do not set RERANK_MODEL_PATH, DB-GPT will read the model path from EMBEDDING_MODEL_CONFIG based on the RERANK_MODEL. # RERANK_MODEL_PATH = /Users/chenketing/Desktop/project/DB-GPT-NEW/DB-GPT/models/bce-reranker-base_v1 #### The number of rerank results to return # RERANK_TOP_K = 5
- L'élimination des scores composites pondérés par le RRF des entreprises sur la base de différents rappels indexés
score = 0.0 for q in queries: if d in result(q): score += 1.0 / (k + rank(result(q), d)) return score # where: # k is a ranking constant # q is a query in the set of queries # d is a document in the result set of q # result(q) is the result set of q # rank(result(q), d) is d's rank within the result(q) starting from 1
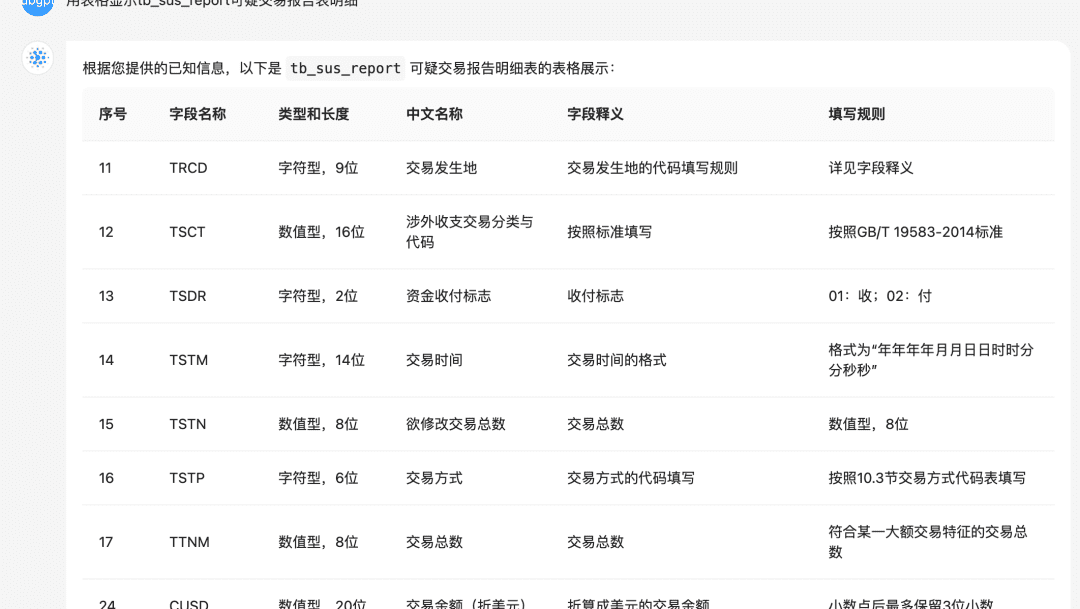
(5) Optimisation de l'affichage + Touting / Topic Leadership
- Obtenir le modèle en sortie en utilisant le formatage markdown
基于以下给出的已知信息,遵守规范约束,专业、简要回答用户的问题。 规范约束: 1. 如果已知信息包含的图片、链接、表格、代码块等特殊 markdown 标签格式的信息,确保在答案中包含原文这些图片、链接、表格和代码标签,不要丢弃不要修改,例如: - 图片格式:`` - 链接格式:`[xxx](xxx)` - 表格格式:`|xxx|xxx|xxx|` - 代码格式:```xxx```。 2. 如果无法从提供的内容中获取答案,请说:“知识库中提供的内容不足以回答此问题”,禁止胡乱编造。 3. 回答的时候最好按照 1.2.3. 点进行总结,并以 Markdown 格式显示。
2.2 Optimisation dynamique des connaissances RAG
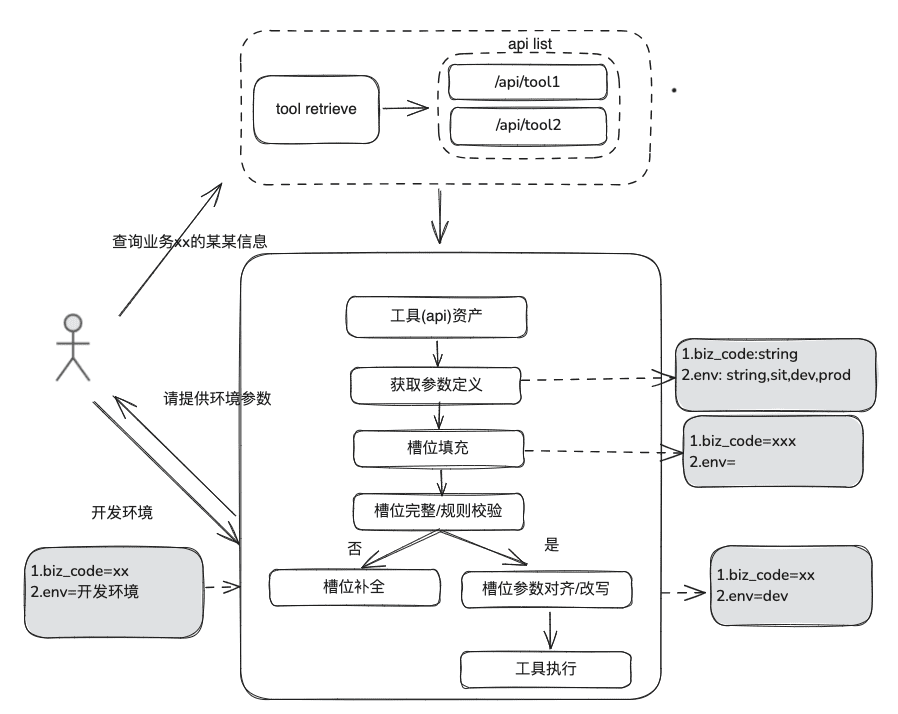
La connaissance de la documentation est relativement statique, elle ne peut pas répondre à des informations personnalisées et dynamiques, elle doit s'appuyer sur des outils de plates-formes tierces pour répondre, sur la base de cette situation, nous avons besoin de certaines méthodes dynamiques de RAG, à travers la définition des actifs de l'outil -> la sélection de l'outil -> la validation de l'outil -> l'exécution de l'outil pour obtenir des données dynamiques.
(1) Bibliothèque d'outils
Construire une bibliothèque d'outils dans le domaine de l'entreprise pour intégrer les API d'outils, les scripts d'outils dispersés sur diverses plates-formes, et fournir ainsi des capacités d'utilisation de bout en bout pour les intelligences. Par exemple, en plus de la base de connaissances statique, nous pouvons traiter des outils en important des bibliothèques d'outils.

(2) Rappel d'outils
Le rappel d'outil suit l'idée du rappel RAG pour les connaissances statiques, puis le cycle de vie complet de l'exécution de l'outil est utilisé pour obtenir les résultats de l'exécution de l'outil.
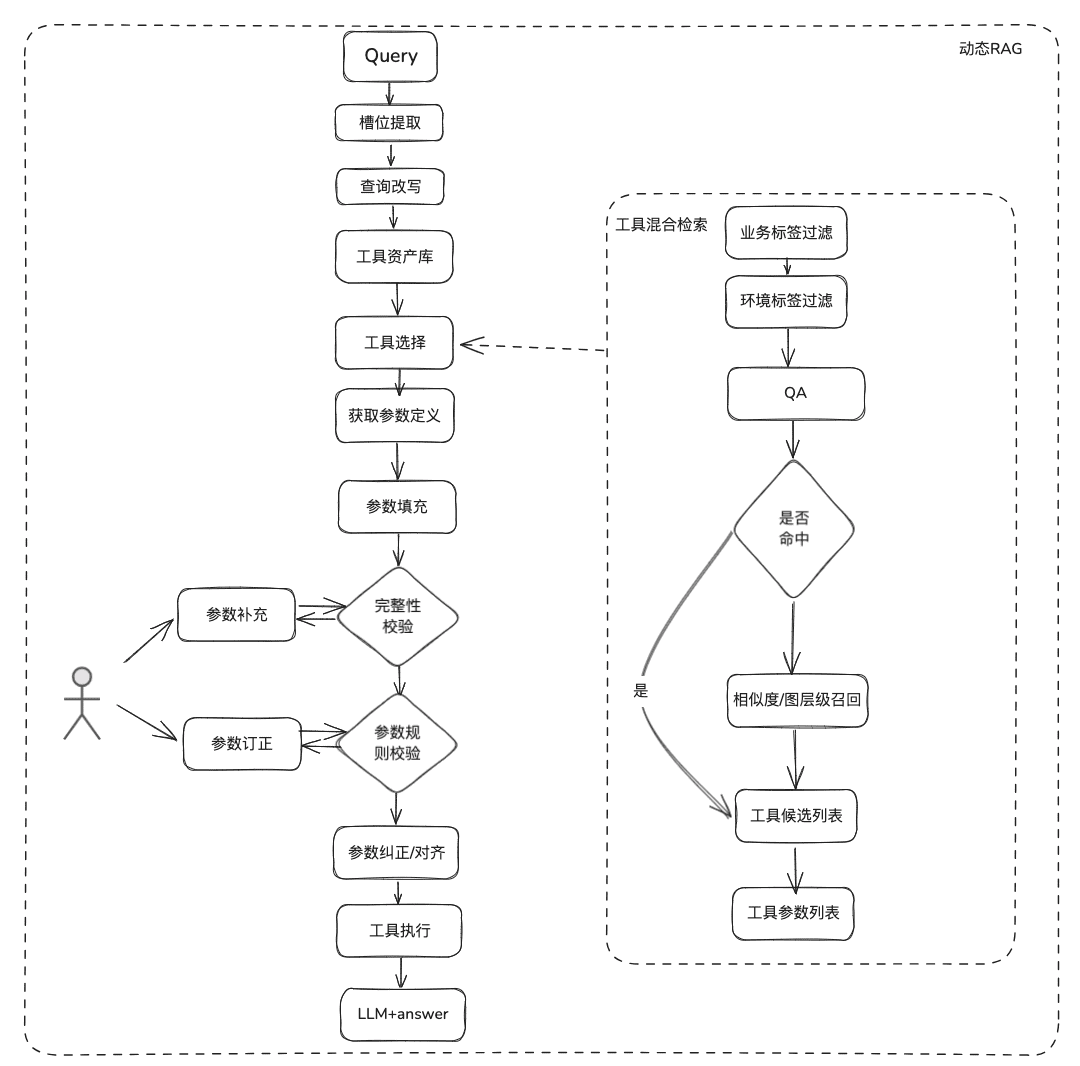
- Extraction de créneaux : Obtenir des LLM par le biais de la PNL traditionnelle pour analyser le problème de l'utilisateur, y compris les types d'activités courantes, les marqueurs d'environnement, les paramètres du modèle de domaine, etc.
- Sélection d'outils : rappel selon les lignes du RAG statique avec deux couches principales, le rappel du nom de l'outil et le rappel des paramètres de l'outil.
- Le rappel des paramètres de l'outil, similaire à l'idée de TableRAG, rappelle d'abord le nom de la table, puis celui du champ.
- Remplissage des paramètres : nécessité de faire correspondre les paramètres extraits des fentes avec les définitions des paramètres de l'outil des rappels.
- Vous pouvez coder pour le remplir, ou vous pouvez demander au modèle de le remplir.
- Idées d'optimisation : étant donné que les noms des mêmes paramètres des différents outils de la plate-forme ne sont pas unifiés et qu'il n'est pas pratique d'aller à la gouvernance, il est suggéré de procéder d'abord à une expansion des données du modèle de domaine et, après avoir obtenu l'ensemble du modèle de domaine, les paramètres requis seront présents.
- étalonnage des paramètres
- Contrôle d'intégrité : contrôle de l'intégrité du nombre de paramètres.
- Contrôle des règles relatives aux paramètres : contrôle des règles relatives au type de nom de paramètre, à la valeur de paramètre, à l'énumération, etc.
- Correction/alignement des paramètres, cette partie vise principalement à réduire le nombre d'interactions avec l'utilisateur, en automatisant la correction des erreurs de paramètres de l'utilisateur, y compris les règles de cas, les règles d'énumération, etc.
2.3 Revue RAG
Lors de l'évaluation du processus Smart Q&A, la précision de la pertinence du rappel ainsi que la pertinence du modèle de Q&A doivent être évaluées séparément, puis prises en compte ensemble pour déterminer les points sur lesquels le processus RAG doit encore être amélioré.
Évaluation des indicateurs :
EvaluationMetric ├── LLMEvaluationMetric │ ├── AnswerRelevancyMetric ├── RetrieverEvaluationMetric │ ├── RetrieverSimilarityMetric │ ├── RetrieverMRRMetric │ └── RetrieverHitRateMetric
RAGRetrieverEvaluationMetric :RetrieverHitRateMetric: Le taux de réussite mesure le taux de réussite (RAG)retrieverLa proportion de rappels apparaissant dans les documents les plus importants des résultats recherchés.RetrieverMRRMetric:Mean Reciprocal RankLa précision de chaque requête est calculée en analysant le classement des documents les plus pertinents dans les résultats de la recherche. Plus précisément, il s'agit de la moyenne du rang inverse des documents pertinents pour toutes les requêtes. Par exemple, si le document le plus pertinent est classé premier, son rang inverse est de 1 ; s'il est classé deuxième, il est de 1/2 ; et ainsi de suite.RetrieverSimilarityMetricLes métriques de similarité sont calculées pour déterminer la similarité entre le contenu rappelé et le contenu prédit.
模型生成Indicateur de réponse.
AnswerRelevancyMetric: métrique de pertinence de la réponse du corps intelligent, en fonction du degré de correspondance entre la réponse du corps intelligent et la question de l'utilisateur. Une réponse très pertinente exige non seulement que le modèle comprenne la question de l'utilisateur, mais aussi qu'il génère une réponse étroitement liée à la question. Cela affecte directement la satisfaction de l'utilisateur et l'utilité du modèle.
3.RAG Landing Partage des cas
1. le RAG dans le domaine de l'infrastructure de données
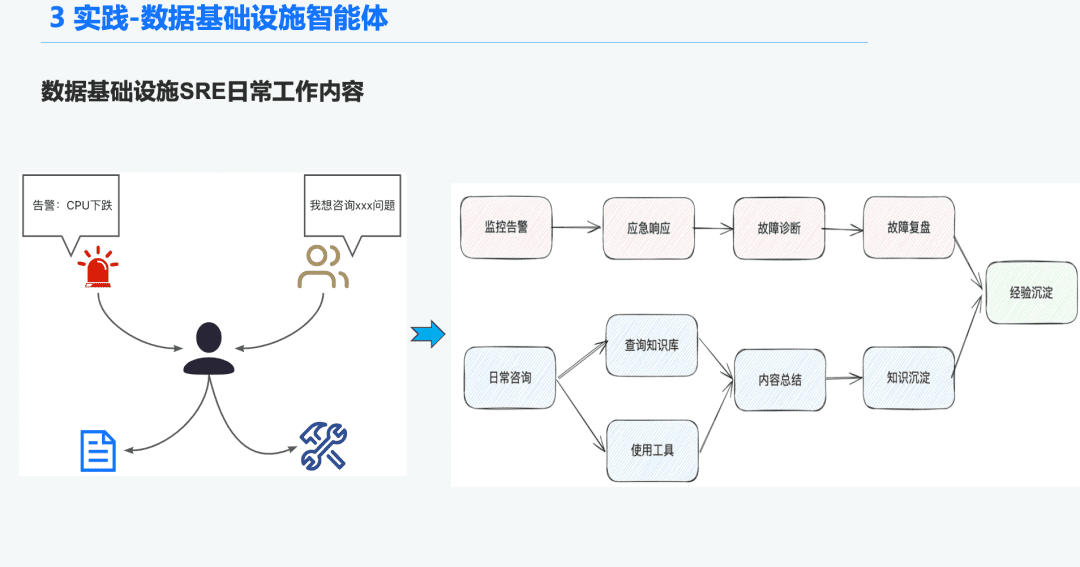
1.1 Historique de l'organe de renseignement O&M
Dans le domaine de l'infrastructure de données, de nombreux SRE d'exploitation reçoivent un grand nombre d'alertes chaque jour, et passent donc beaucoup de temps à répondre aux urgences, ce qui les amène à dépanner, puis à examiner les problèmes, ce qui leur permet d'acquérir de l'expérience. Une autre partie du temps est consacrée à répondre aux demandes des utilisateurs, ce qui les oblige à utiliser leurs connaissances et leur expérience dans l'utilisation des outils pour répondre aux questions.
Nous espérons donc résoudre ces problèmes de diagnostic des alarmes et de réponse aux questions en créant une intelligence générale pour l'infrastructure de données.
1.2 Rigueur et professionnalisme du RAG
La technologie traditionnelle RAG + Agent peut résoudre des scénarios de tâches générales, moins déterministes et à une seule étape. Cependant, face à des scénarios professionnels dans le domaine de l'infrastructure de données, l'ensemble du processus de recherche doit être déterministe, professionnel et réaliste, et nécessite un raisonnement étape par étape.
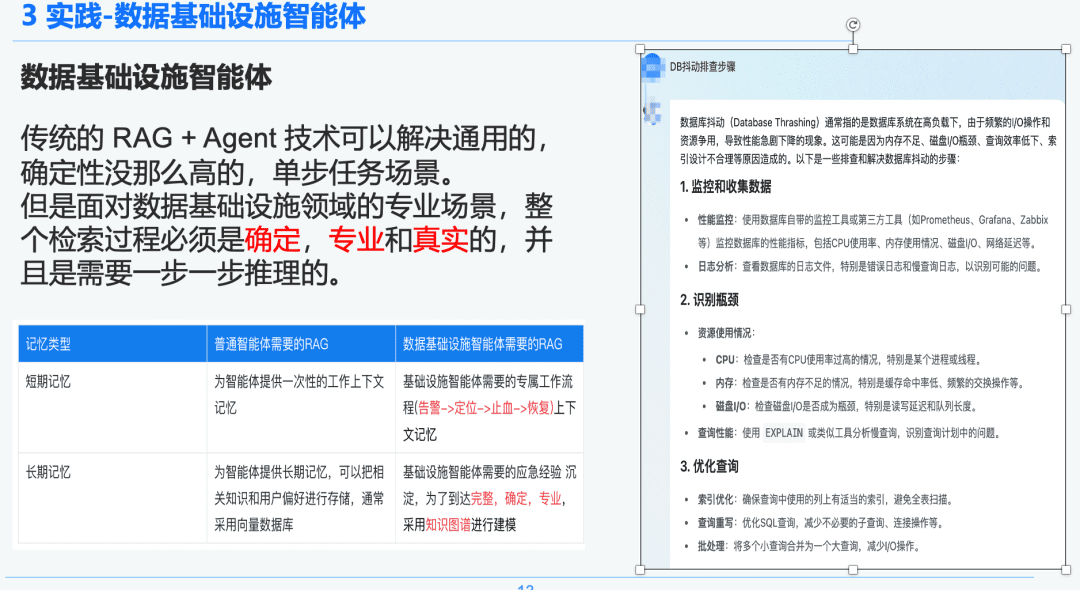
À droite se trouve un résumé généralisé via NativeRAG, qui peut être une information utile pour un utilisateur de la suite C qui n'a pas beaucoup de connaissances dans le domaine, mais pour un professionnel, cette partie de la réponse n'aura pas beaucoup de sens.
Nous comparons donc la différence entre les intelligences génériques et les intelligences liées à l'infrastructure de données par rapport au RAG :
- Intelligences polyvalentes : les RAG traditionnels ne requièrent pas autant de rigueur intellectuelle et d'expertise, et conviennent à certains scénarios commerciaux tels que le service à la clientèle, le tourisme et les robots de questions-réponses.
- Data Infrastructure Intelligence Body : Le processus RAG est rigoureux et professionnel, exigeant des flux de travail RAG exclusifs avec des contextes qui incluent (Alert -> Locate -> Stop the Bleeding -> Recover) et une extraction structurée des questions-réponses et de l'expérience en matière d'intervention d'urgence précipitée par les experts afin d'établir des relations hiérarchiques. C'est pourquoi nous avons choisi le Knowledge Graph comme support de données.
1.3 Traitement des connaissances
Compte tenu du déterminisme et de la spécificité de l'infrastructure de données, nous avons choisi de l'utiliser comme support de connaissances pour diagnostiquer les expériences d'intervention d'urgence en combinant les graphes de connaissances. Notre expérience des événements de dépannage d'urgence précipités par le SRE Combinés au processus d'examen des urgences, nous avons établi un graphe de connaissances axé sur les événements d'urgence de la BD, nous avons pris la gigue de la BD comme exemple, plusieurs événements affectant la gigue de la BD, y compris les problèmes de lenteur de SQL, les problèmes de capacité, nous avons établi des relations entre chaque événement d'urgence.
Enfin, nous avons mis en place un système normalisé de traitement des connaissances provenant de sources multiples -> extraction structurée des connaissances -> extraction des relations d'urgence -> examen par des experts -> stockage des connaissances, étape par étape, en normalisant les règles relatives aux événements d'urgence.

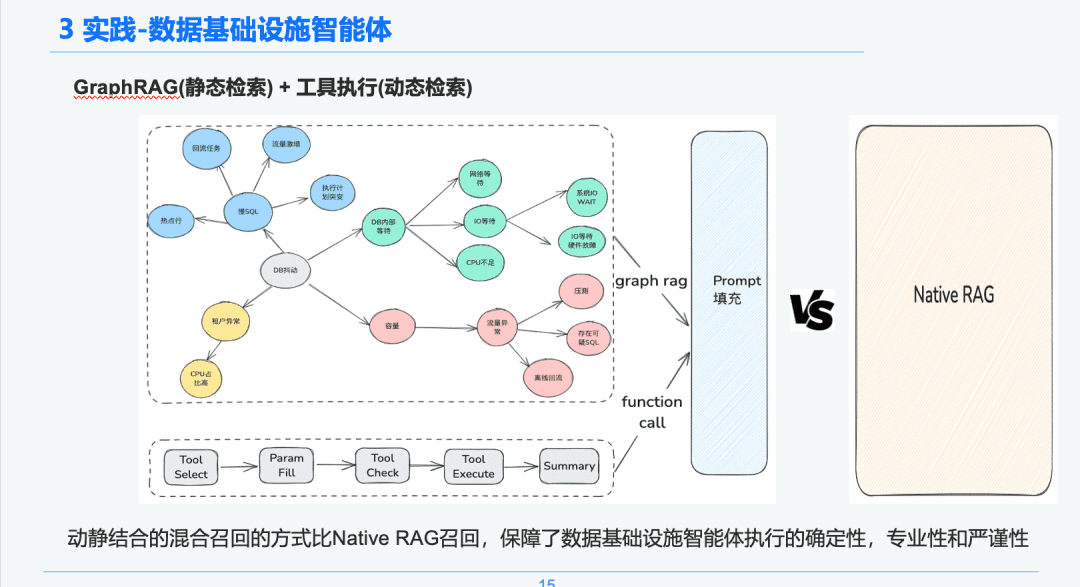
1.4 Recherche de connaissances
Dans la phase d'extraction intelligente du corps, nous utilisons GraphRAG comme support d'extraction de connaissances statiques. Ainsi, après avoir identifié l'anomalie de gigue de la DB, nous trouvons les nœuds liés au nœud d'anomalie de gigue de la DB comme base de notre analyse, car chaque nœud conserve également certaines informations de métadonnées sur chaque événement pendant la phase d'extraction des connaissances, y compris le nom de l'événement, la description de l'événement, les outils connexes, les paramètres de l'outil, etc.
Par conséquent, nous pouvons obtenir les résultats du retour par le biais du lien du cycle de vie de l'exécution de l'outil d'exécution pour obtenir les données dynamiques à utiliser comme base du diagnostic d'urgence pour le dépannage. Grâce à cette approche de rappel hybride dynamique et statique, la certitude, le professionnalisme et la rigueur de l'exécution des intelligences de l'infrastructure de données sont garantis par rapport au rappel RAG pur et simple.
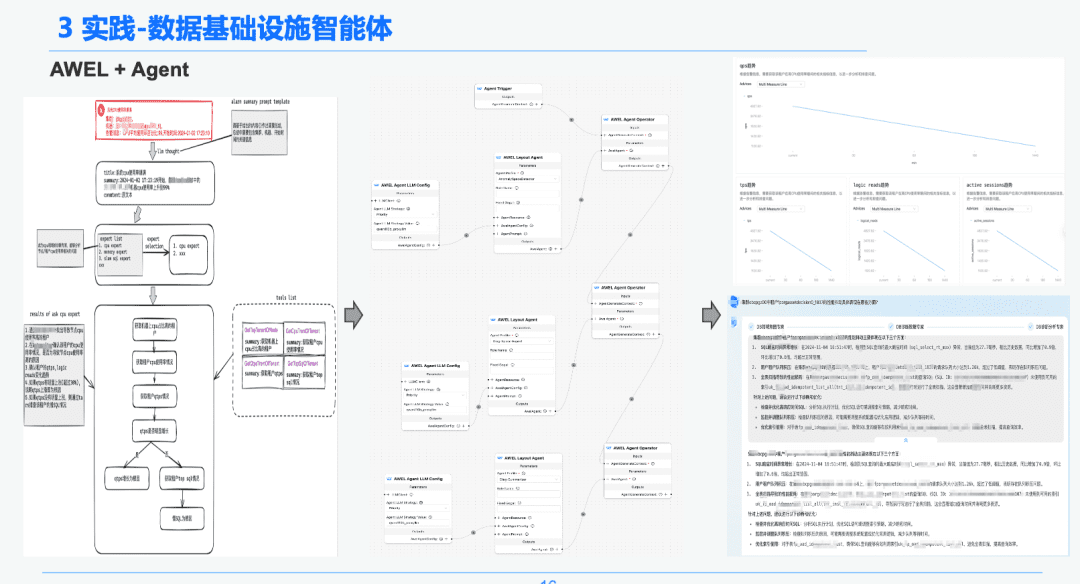
1,5 AWEL + Agent
Enfin, grâce à la technologie communautaire AWEL+AGENT, le paradigme de l'orchestration AGENT a été utilisé pour créer un expert de l'intention -> expert en diagnostic d'urgence -> expert en analyse des causes profondes.
Chaque agent a une fonction différente. L'expert en intention est chargé d'identifier et d'analyser l'intention de l'utilisateur et d'identifier les messages d'alerte. L'expert en diagnostic doit localiser le nœud de cause première à analyser par le biais du GraphRAG et obtenir des informations spécifiques sur la cause première. L'expert en analyse doit combiner les données de chaque nœud de cause fondamentale + le rapport d'analyse historique pour générer un rapport d'analyse diagnostique.
2. le RAG dans le domaine de l'analyse des rapports financiers
Dernière pratique ! Comment construire un assistant d'analyse de rapports financiers basé sur DB-GPT ?
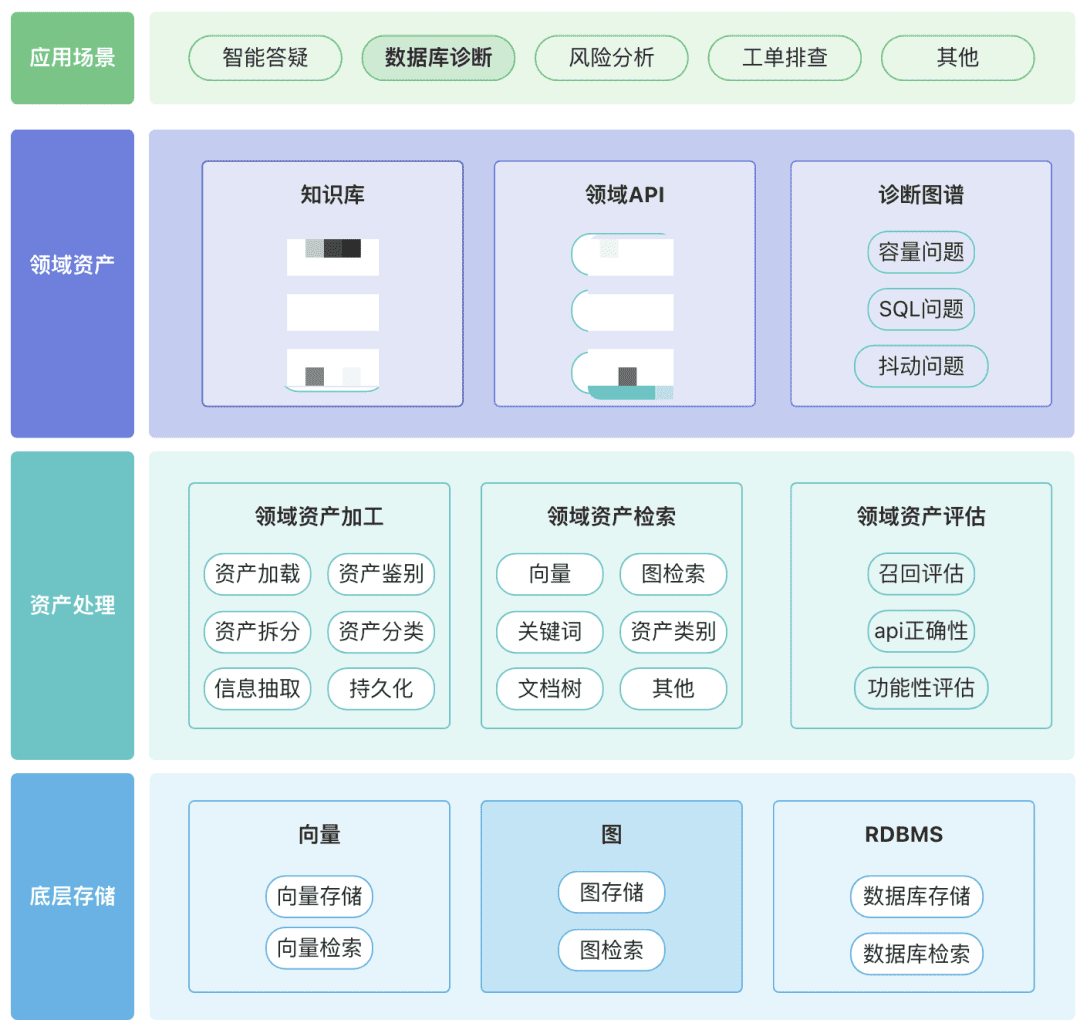
Vous pouvez créer votre propre référentiel d'actifs de domaine, y compris des actifs de connaissances, des actifs d'outils et des actifs de graphes de connaissances autour de votre domaine.
- Actifs du domaine : les actifs du domaine comprennent les bases de connaissances, les API et les scripts d'outils.
- Traitement des biens, l'ensemble de la liaison de données sur les biens implique le traitement des biens du domaine, la recherche des biens du domaine et l'évaluation des biens du domaine.
- Non structuré -> Structuré : catégorisé de manière structurée, information de connaissance correctement organisée.
- Extraire des informations sémantiques plus riches.
- Recherche d'actifs :
- Espérons qu'il s'agit d'une recherche hiérarchisée et priorisée plutôt que d'une recherche unique.
- Le post-filtrage est important, de préférence par le biais de la sémantique commerciale de certaines règles.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...