VideoChat : personne numérique interactive vocale en temps réel avec clonage d'images et de tonalités personnalisées, prenant en charge des solutions vocales de bout en bout et des solutions en cascade.

Introduction générale
VideoChat est un projet d'interaction vocale en temps réel avec un humain numérique basé sur une technologie open-source, prenant en charge des schémas vocaux de bout en bout (GLM-4-Voice - THG) et des schémas en cascade (ASR-LLM-TTS-THG). Le projet permet aux utilisateurs de personnaliser l'image et le timbre de l'humain numérique, et prend en charge le clonage du timbre et la synchronisation labiale, la sortie vidéo en continu, et une latence du premier paquet aussi faible que 3 secondes. Les utilisateurs peuvent découvrir ses fonctionnalités grâce à des démonstrations en ligne, ou le déployer et l'utiliser localement grâce à une documentation technique détaillée.
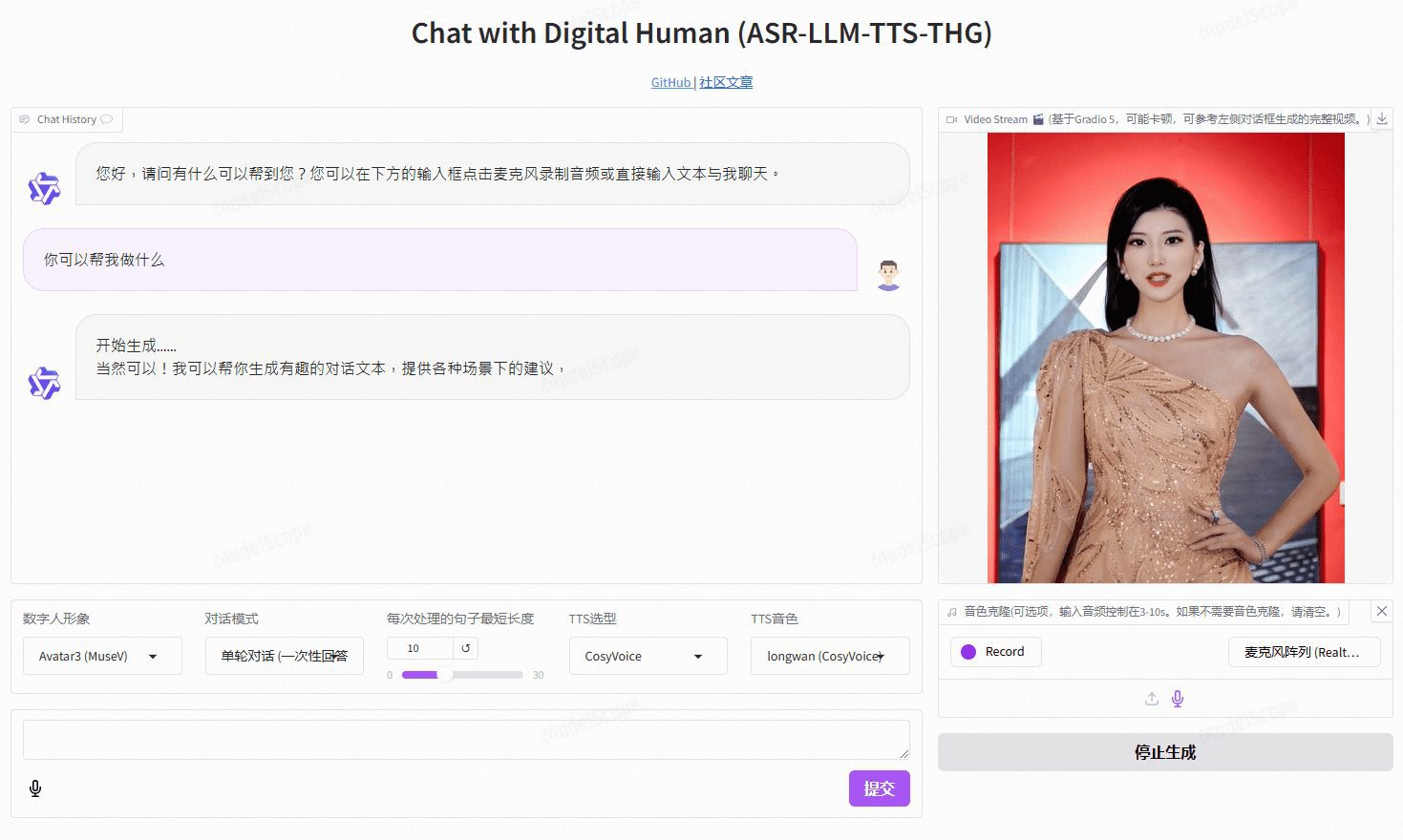
Adresse de démonstration : https://www.modelscope.cn/studios/AI-ModelScope/video_chat
Liste des fonctions
- Interaction vocale en temps réel : prise en charge des solutions vocales de bout en bout et des solutions en cascade
- Image et son personnalisés : les utilisateurs peuvent personnaliser l'apparence et le son de la personne numérique en fonction de leurs besoins.
- Clonage de la voix : permet de cloner la voix de l'utilisateur afin d'offrir une expérience vocale personnalisée.
- Faible latence : la latence des premiers paquets n'est que de 3 secondes, ce qui garantit une interaction fluide.
- Projet open source : basé sur la technologie open source, les utilisateurs peuvent librement modifier et étendre la fonction.
Utiliser l'aide
Processus d'installation
- Configuration de l'environnement
- Système d'exploitation : Ubuntu 22.04
- Version de Python : 3.10
- Version CUDA : 12.2
- Version de Torch : 2.1.2
- projet de clonage
git lfs install git clone https://github.com/Henry-23/VideoChat.git cd video_chat - Création d'un environnement virtuel et installation des dépendances
conda create -n metahuman python=3.10 conda activate metahuman pip install -r requirements.txt pip install --upgrade gradio - Télécharger le fichier de poids
- Il est recommandé d'utiliser CreateSpace pour le téléchargement, et d'installer git lfs pour suivre les fichiers de poids.
git clone https://www.modelscope.cn/studios/AI-ModelScope/video_chat.git - Démarrage des services
python app.py
Processus d'utilisation
- Configuration de la clé API: :
- Si les performances de la machine locale sont limitées, vous pouvez utiliser l'API Qwen et l'API CosyVoice fournies par la plateforme de services de grands modèles d'Aliyun, Hundred Refine, sur le réseau de l'entreprise.
app.pyConfigurez la clé API dans le champ
- Si les performances de la machine locale sont limitées, vous pouvez utiliser l'API Qwen et l'API CosyVoice fournies par la plateforme de services de grands modèles d'Aliyun, Hundred Refine, sur le réseau de l'entreprise.
- inférence locale: :
- Si vous n'utilisez pas la clé API, vous pouvez l'utiliser dans le champ
src/llm.pyrépondre en chantantsrc/tts.pyConfigurer la méthode d'inférence locale afin de supprimer le code d'appel d'API inutile.
- Si vous n'utilisez pas la clé API, vous pouvez l'utiliser dans le champ
- Démarrage des services: :
- être en mouvement
python app.pyDémarrer le service.
- être en mouvement
- Personnalisation de la personnalité numérique: :
- existent
/data/video/Catalogue pour ajouter une vidéo enregistrée de l'image humaine numérique. - modifications
/src/thg.pydans la liste des avatars de la classe Muse_Talk, en ajoutant le nom de l'image et bbox_shift. - existent
app.pyAprès avoir ajouté le nom de la persona numérique au nom de l'avatar dans Gradio, redémarrez le service et attendez que l'initialisation soit terminée.
- existent
Procédure d'utilisation détaillée
- Image et ton personnalisés: en
/data/video/pour ajouter une vidéo enregistrée de l'image numérique de l'homme à l'annuaire.src/thg.pymodificationMuse_Talkclasseavatar_listajoutez le nom de l'image etbbox_shiftParamètres. - clonage de la parole: en
app.pyConfiguration moyenneCosyVoice APIou en utilisantEdge_TTSEffectuer un raisonnement local. - Solutions vocales de bout en bout: Utilisation
GLM-4-Voiceafin de permettre une génération et une reconnaissance efficaces de la parole.
- Visitez l'adresse du service déployé localement et accédez à l'interface Gradio.
- Sélectionnez ou téléchargez une vidéo personnalisée de la personnalité numérique.
- Configurer la fonction de clone vocal pour télécharger l'échantillon de voix d'un utilisateur.
- Lancez une interaction vocale en temps réel et découvrez des capacités de dialogue à faible latence.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...