
V-JEPA 2 - Le grand modèle du monde le plus puissant de Meta AI
Qu'est-ce que V-JEPA 2
V-JEPA 2 Oui Meta AI Lancement d'un modèle de taille mondiale basé sur des données vidéo avec 1,2 milliard de paramètres. Le modèle est formé sur la base d'un apprentissage auto-supervisé à partir de plus d'un million d'heures de vidéo et d'un million d'images afin de comprendre les objets, les actions et les mouvements dans le monde physique et de prédire les états futurs. Le modèle utilise une architecture codeur-prédicteur, combinée à la prédiction des conditions d'action, pour prendre en charge la planification de robots à zéro échantillon, ce qui permet aux robots d'accomplir des tâches dans de nouveaux environnements. V-JEPA 2 excelle dans des tâches telles que la reconnaissance d'actions, la prédiction et les questions-réponses vidéo, fournissant un support technique puissant pour le contrôle des robots, la surveillance intelligente, l'éducation et les soins de santé, et constituant une étape importante vers l'intelligence artificielle avancée.
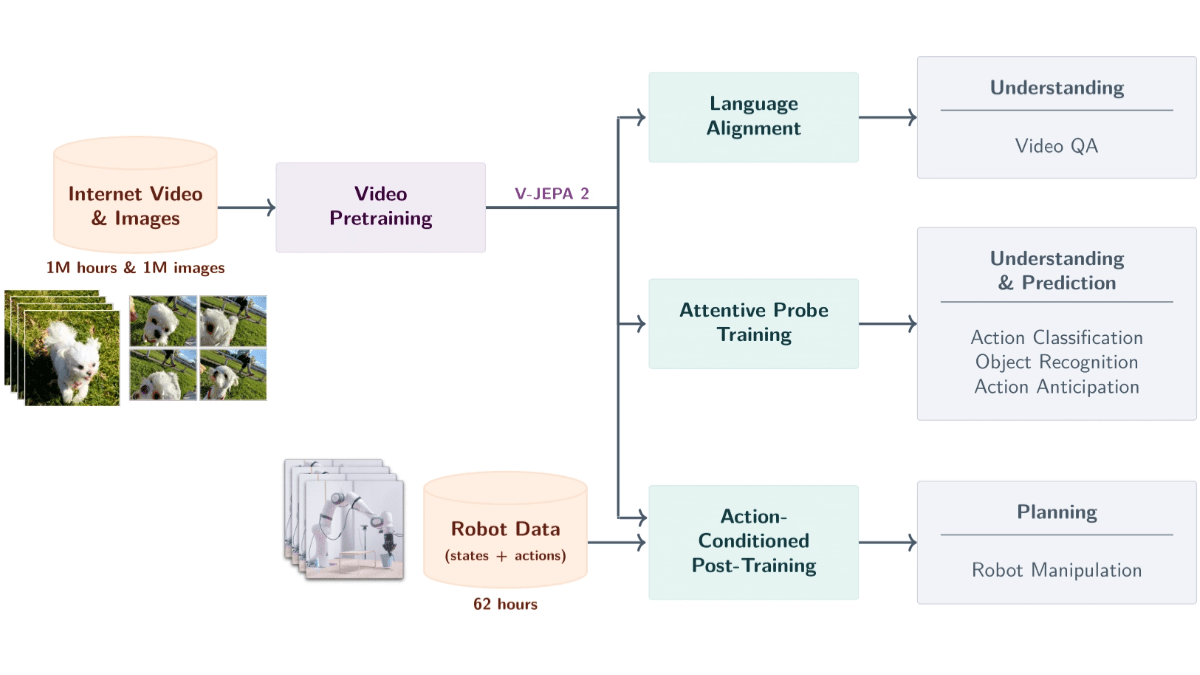
Caractéristiques principales de V-JEPA 2
- Analyse sémantique des vidéosLe projet de recherche sur la reconnaissance d'objets, d'actions et de mouvements à partir de vidéos et l'extraction précise d'informations sémantiques sur la scène.
- Prévision d'événements futursPrédiction d'images vidéo ou de résultats d'actions futures en fonction de l'état et des actions en cours, avec des prédictions à court et à long terme.
- Planification de l'échantillonnage du robot zéro: Planification de tâches pour les robots dans de nouveaux environnements, telles que la saisie et la manipulation d'objets, sur la base de capacités prédictives, sans données d'apprentissage supplémentaires.
- Interaction vidéo Q&RLes questions portent sur les causes physiques et la compréhension de la scène, et sont posées dans le cadre de la modélisation linguistique.
- Généralisation entre les scènesIl permet l'apprentissage à partir d'un échantillon zéro et l'adaptation à de nouvelles scènes.
Adresse du site web officiel de V-JEPA 2
- Site web du projet: :https://ai.meta.com/blog/v-jepa-2
- Dépôt GitHub: :https://github.com/facebookresearch/vjepa2
- Documents techniques: :https://scontent-lax3-2.xx.fbcdn.net/v/t39.2365-6
Comment utiliser V-JEPA 2
- Accès aux ressources du modèleTélécharger les fichiers du modèle pré-entraîné et le code associé à partir du dépôt GitHub. Les fichiers de modèle sont fournis au format .pth ou .ckpt.
- Mise en place de l'environnement de développement: :
- Installation de PythonPython : Assurez-vous que Python est installé (Python 3.8 ou supérieur est recommandé).
- Installation des bibliothèques dépendantesPip : Utilisez pip pour installer les dépendances requises par le projet. Généralement, les projets fournissent un fichier requirements.txt pour installer les dépendances basées sur les commandes suivantes :
pip install -r requirements.txt- Installation de cadres d'apprentissage profondV-JEPA 2 est basé sur PyTorch et nécessite l'installation de PyTorch, en fonction de la configuration du système et du GP, obtenez les commandes d'installation sur le site web de PyTorch.
- Modèles de chargement: :
- Chargement de modèles pré-entraînésChargement de fichiers de modèles pré-entraînés avec PyTorch.
import torch
from vjepa2.model import VJEPA2 # 假设模型类名为 VJEPA2
# 加载模型
model = VJEPA2()
model.load_state_dict(torch.load("path/to/model.pth"))
model.eval() # 设置为评估模式- Préparation de la saisie des données: :
- Prétraitement des données vidéoV-JEPA 2 requiert des données vidéo en entrée. Les données vidéo sont converties au format (généralement tensoriel) requis par le modèle. Voici un exemple simple de prétraitement :
from torchvision import transforms
from PIL import Image
import cv2
# 定义视频帧的预处理
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整帧大小
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
# 读取视频帧
cap = cv2.VideoCapture("path/to/video.mp4")
frames = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = Image.fromarray(frame)
frame = transform(frame)
frames.append(frame)
cap.release()
# 将帧堆叠为一个张量
video_tensor = torch.stack(frames, dim=0).unsqueeze(0) # 添加批次维度- Prévisions à l'aide de modèles: :
- Projections de mise en œuvreLe modèle de prédiction est basé sur les données vidéo prétraitées, qui sont entrées dans le modèle pour obtenir les résultats de la prédiction. Voici un exemple de code :
with torch.no_grad(): # 禁用梯度计算
predictions = model(video_tensor)- Analyse et application des résultats des prévisions: :
- Analyse des résultats des prévisionsL'analyse des données de sortie du modèle en fonction des exigences de la tâche.
- Application à des scénarios du monde réelLes prédictions peuvent être appliquées à des tâches réelles telles que le contrôle de robots, les questionnaires vidéo ou la détection d'anomalies.
Principaux avantages de V-JEPA 2
- Forte compréhension du monde physiqueV-JEPA 2 est capable de reconnaître avec précision les actions et les mouvements des objets à partir d'entrées vidéo, de capturer des informations sémantiques sur la scène et de fournir une assistance de base pour des tâches complexes.
- Prédiction efficace de l'état futurEn fonction de l'état et des actions en cours, le modèle peut prédire les images vidéo ou les résultats des actions à venir, ce qui permet des prédictions à court et à long terme et alimente des applications telles que la planification de robots et la surveillance intelligente.
- Capacités d'apprentissage et de généralisation à partir d'un échantillon zéroV-JEPA 2 est performant pour les environnements et les objets non vus, prend en charge l'apprentissage et l'adaptation sans échantillon et ne nécessite pas de données d'apprentissage supplémentaires pour accomplir de nouvelles tâches.
- Capacité de questions-réponses vidéo combinée à la modélisation linguistiqueV-JEPA 2 : Associé à un modèle linguistique, V-JEPA 2 est capable de répondre à des questions liées au contenu vidéo, couvrant la causalité physique et la compréhension de la scène, ce qui élargit les applications dans des domaines tels que l'éducation et les soins de santé.
- Formation efficace basée sur l'apprentissage auto-superviséLe projet : Apprentissage de représentations visuelles génériques à partir de données vidéo à grande échelle basé sur l'apprentissage auto-supervisé sans étiquetage manuel des données, ce qui permet de réduire les coûts et d'améliorer la généralisation.
- Entraînement en plusieurs étapes et prédiction des conditions de mouvementV-JEPA 2 : Basé sur un apprentissage en plusieurs étapes, V-JEPA 2 pré-entraîne le codeur et entraîne ensuite le prédicteur des conditions de mouvement, en combinant les informations visuelles et les informations sur le mouvement afin de permettre un contrôle prédictif précis.
Personnes auxquelles V-JEPA 2 est destiné
- Chercheurs en intelligence artificielleLe projet V-JEPA 2 : recherche universitaire et innovation technologique avec la technologie de pointe de V-JEPA 2 pour promouvoir l'intelligence des machines.
- Ingénieur en robotiqueDéveloppement de systèmes robotiques adaptés à de nouveaux environnements et à des tâches complexes à l'aide de capacités de planification de modèles à zéro échantillon.
- Développeur en vision artificielleV-JEPA 2 : Améliorez l'efficacité de l'analyse vidéo avec V-JEPA 2, utilisé dans la sécurité intelligente, l'automatisation industrielle et d'autres domaines.
- expert en traitement du langage naturel (NLP): Combiner la modélisation visuelle et linguistique pour développer des systèmes d'interaction intelligents tels que les assistants virtuels et les services clients intelligents.
- éducateurDéveloppement d'outils éducatifs immersifs basés sur des fonctions de quiz vidéo afin d'améliorer l'enseignement et l'apprentissage.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...