
Tongyi Wanxiang, mise à niveau vidéo, VBench en tête, support vidéo pour la génération de chinois, texture de l'objectif tirant vers le haut
La génération de vidéos d'IA est-elle sur le point de connaître une percée technologique alors que l'année 2025 ne fait que commencer ?
Ce matin, le modèle de génération vidéo Tongyi Wanphase d'Ali a annoncé une importante mise à niveau vers la version 2.1.
Il existe deux versions du nouveau modèle, à savoirTomix 2.1 Extreme et Professional, le premier se concentrant sur les hautes performances, le second visant une grande expressivité..
Selon l'introduction, Tongyi Wanxiang a considérablement amélioré les performances globales du modèle cette fois-ci, notamment en ce qui concerne le traitement des mouvements complexes, la restauration des lois physiques réelles, l'amélioration de la texture du film et l'optimisation des instructions à suivre, ce qui ouvre une nouvelle porte à la création artistique de l'IA.
Jetons un coup d'œil à l'effet de génération vidéo et voyons s'il peut vous surprendre.
Commençons par le classique "steak cut", par exemple, vous pouvez voir que le grain du steak est clairement visible, la surface est recouverte d'une fine couche de graisse, luisante, et la lame coupe lentement le long des fibres musculaires, la viande est Q-bon et pleine de détails. 
Prompt : Dans un restaurant, un homme découpe un steak fumant. Dans un gros plan aérien, l'homme tient un couteau tranchant dans sa main droite, place le couteau sur le steak et coupe le long du centre du steak. La personne est habillée en noir avec du vernis à ongles blanc sur les mains, l'arrière-plan est un bokeh avec une assiette blanche avec de la nourriture jaune et une table marron.
L'expression faciale de la petite fille, les mouvements de ses mains et de son corps sont très naturels et coordonnés, le vent qui balaie ses cheveux est également conforme aux lois du mouvement.

Prompt:Une jolie jeune fille se tient dans un buisson de fleurs, les mains comparant son cœur et toutes sortes de petits cœurs dansant autour d'elle. Elle porte une robe rose, ses longs cheveux flottent au vent et son sourire est doux. L'arrière-plan est un jardin de printemps avec des fleurs en pleine floraison et un soleil radieux. Photographie réaliste HD, gros plan, lumière naturelle douce.
Le modèle est-il suffisamment solide pour obtenir un autre score. Actuellement, sur le VBench Leaderboard, la liste de référence en matière de génération vidéo, leLe Tongyi Wanxiang amélioré a atteint le sommet de la liste avec un score total de 84,7%, surpassant les modèles de génération vidéo nationaux et internationaux tels que Gen3, Pika et CausVid... Il semble que le paysage concurrentiel de la génération de vidéos ait connu une nouvelle vague de changements.
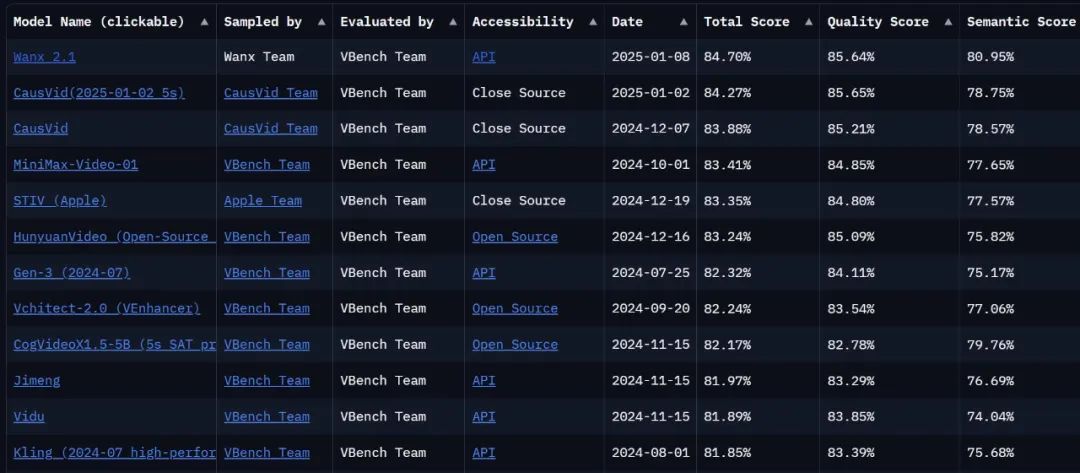
Lien vers la liste : https://huggingface.co/spaces/Vchitect/VBench_Leaderboard
Désormais, les utilisateurs pourront utiliser la dernière génération de modèles sur le site web de Tongyi Wanxiang. De même, les développeurs peuvent également appeler l'API des grands modèles dans AliCloud Bai Lian.
Adresse du site web officiel : https://tongyi.aliyun.com/wanxiang/
expérience de première mainUne plus grande expressivité et la possibilité de jouer avec des polices à effets spéciaux
La nouvelle version de Tongyi Wanxiang a-t-elle atteint un niveau d'amélioration de la génération ? Nous avons effectué des tests en conditions réelles.
Les vidéos d'IA peuvent désormais écrire.
Tout d'abord, les vidéos générées par l'IA peuvent enfin dire adieu au "ghostwriting".
Jusqu'à présent, le modèle de génération de vidéos par IA le plus répandu sur le marché était incapable de générer avec précision du chinois et de l'anglais, tant que l'endroit où le texte devait se trouver n'était qu'un amas de déchets illisibles. Ce problème industriel a été résolu par Tongyi Wanxiang 2.1.
Il est devenuLe premier modèle de génération vidéo capable de générer du texte chinois et de prendre en charge les effets de texte en anglais et en chinois..
Les utilisateurs peuvent désormais générer du texte et des animations avec des effets cinématiques en saisissant simplement une courte description.
Par exemple, un chaton tape devant un ordinateur et sept grands mots "Travailler ou manger" apparaissent à l'écran.

Dans la vidéo créée par Tongyi Wanxiang, le chat est assis à son poste de travail et joue du clavier et de la souris de manière sérieuse, comme s'il s'agissait d'une machine à écrire contemporaine. Les sous-titres en incrustation, associés à la bande sonore générée automatiquement, confèrent à l'ensemble une touche plus spirituelle.
Ensuite, le mot anglais "Synced" (synchronisé) apparaît dans un petit carré orange.

Qu'il s'agisse de générer du chinois ou de l'anglais, Tongyi Wanxiang le fait correctement, sans fautes de frappe ni "écriture fantôme".
En outre, il prend en charge l'application des polices de caractères dans une variété de scénarios.Y compris les polices d'effets spéciaux, les polices d'affiches et les polices affichées dans des scénarios réels..
Par exemple, près de la Tour Eiffel, sur les rives de la Seine, des feux d'artifice brillants s'épanouissent dans l'air et, au fur et à mesure que la caméra se rapproche, le chiffre rose "2025" s'agrandit progressivement jusqu'à remplir l'ensemble du cadre.

Les mouvements vigoureux ne sont plus "effrayants"
复杂的人物运动一度是 AI 视频生成模型的「噩梦」,以往 AI 生成的视频要么手脚乱飞、大变活人,要么出现「只转身不转头」的诡异动作。 
Grâce à l'optimisation avancée des algorithmes et à l'entraînement des données, Tongyi Wanxiang est en mesure de générer des mouvements stables et complexes dans une variété de scénarios, notamment en termes de mouvements de membres à grande échelle et de rotation précise des membres.
Par ailleurs, dans la vidéo générée ci-dessous, les mouvements de l'homme sont fluides et naturels lorsqu'il court, sans que l'on puisse distinguer la jambe gauche de la jambe droite ou qu'elle soit tordue. Le logiciel est également très attentif aux détails : chaque fois que les orteils de l'homme touchent le sol, ils laissent une marque et soulèvent légèrement le sable fin.

Prompt : lumière dorée sur la mer scintillante au coucher du soleil, un beau jeune homme courant le long de la plage, travelling stable.
La cinématographie est celle d'un maître du cinéma.
Le grand réalisateur Spielberg a dit un jour que le secret d'un bon film réside dans le langage de la caméra. Pour produire des images étonnantes, les directeurs de la photographie détestent monter dans le ciel et voler au-dessus des murs. 
Mais à l'ère de l'IA, il est beaucoup plus facile de "faire" un film.
Il suffit de saisir une simple commande textuelle, telle que lentille à gauche, lentille plus éloignée, lentille en avance, etc.Produit automatiquement une vidéo raisonnable en fonction du contenu principal de la vidéo et des besoins de la caméra..
Nous tapons Prompt : groupe de rock jouant sur la pelouse, au fur et à mesure que la caméra avance, elle se concentre sur le guitariste, vêtu d'une veste en cuir, dont les longs cheveux en désordre se balancent au rythme de la musique. Les doigts du guitariste sautent rapidement sur les cordes tandis que le reste du groupe, à l'arrière-plan, se donne à fond.

une image complète de tout 2.1 Les instructions ont été suivies à la lettre. La vidéo commence avec le guitariste et le batteur jouant avec passion, et tandis que la caméra se rapproche lentement, l'arrière-plan se brouille et fait un zoom arrière pour mettre l'accent sur le comportement du guitariste et les mouvements de ses mains.
Les commandes de texte longues ne se perdent pas
Pour que les vidéos générées par l'IA soient époustouflantes, il est essentiel de disposer d'invites textuelles précises.
Cependant, le grand modèle a parfois une mémoire limitée et, lorsqu'il est confronté à des commandes textuelles contenant divers changements de scène, des interactions entre les personnages et des actions complexes, il a tendance à perdre le fil des détails ou à s'embrouiller dans l'ordre logique.
Le nouveau Tongyi Manxiang est un grand pas en avant en ce qui concerne les instructions à suivre pour les textes longs.
Prompt : Un motard roule à vive allure dans une rue étroite de la ville, évitant une explosion massive dans un bâtiment voisin, alors que les flammes rugissent violemment, projetant une vive lueur orange, et que des débris et des éclats de métal volent dans l'air, ajoutant au chaos de la scène. Le conducteur, vêtu d'une tenue sombre, penché en avant et tenant fermement le guidon, semble concentré alors qu'il fonce à toute allure, sans se laisser décourager par l'incendie qui fait rage derrière lui. L'épaisse fumée noire laissée par l'explosion remplit l'air, plongeant l'arrière-plan dans un chaos apocalyptique. Cependant, le coureur reste implacable, se faufilant à travers le chaos avec précision et une cinématographie extrême, des détails ultrafins, une 3D immersive et une action cohérente.

Dans la longue description ci-dessus, les rues étroites, les flammes vives, la fumée noire, les débris volants et les cavaliers en tenue sombre ...... sont autant de détails capturés par Tongyi Manxiang.
Tongyi Wanxiang a également une capacité plus puissante à combiner des concepts pour comprendre avec précision une variété d'idées, d'éléments ou de styles différents et les combiner pour créer un contenu vidéo entièrement nouveau.
L'image d'un vieil homme en costume sortant d'un œuf et regardant, les yeux écarquillés, le vieil homme aux cheveux blancs de la caméra est tout à fait hilarante, couplée au son d'un coq qui glousse.

Spécialisé dans les peintures à l'huile de bandes dessinées et autres styles
La nouvelle version de Tongyi Manphase génère également des images vidéo cinématiques et prend bien en charge différents styles artistiques, tels que le dessin animé, la couleur cinéma, le style 3D, la peinture à l'huile, le style classique, etc.
Regardez cet adorable petit monstre animé en 3D qui se tient sur une vigne et qui danse.

Proposition : un petit monstre titi vert, duveteux et heureux, se tient sur une branche de vigne et chante joyeusement. Faites tourner la caméra dans le sens inverse des aiguilles d'une montre.
En outre, il prend en charge différents rapports d'aspect, notamment 1:1, 3:4, 4:3, 16:9 et 9:16, ce qui permet de mieux s'adapter aux différents appareils finaux tels que les téléviseurs, les ordinateurs et les téléphones portables. 
D'après le spectacle ci-dessus, nous pouvons déjà effectuer un travail créatif en utilisant le Tongyi Mansei pour transformer l'inspiration en "réalité".
Bien entendu, cette série de progrès est également attribuée aux améliorations apportées par AliCloud au modèle de base de la génération de vidéos.
Le modèle de base a été considérablement optimiséStructure, formation, évaluation et "transformation" générale.
Le 19 septembre dernier, AliCloud a présenté le modèle de génération vidéo Tongyi Wanphase lors de la conférence Yunqi, qui permet de générer des vidéos HD de qualité cinématographique et télévisuelle. En tant que modèle de génération visuelle entièrement développé par AliCloud, il utilise la méthode Diffusion +. Transformateur L'architecture prend en charge les tâches de classe de génération d'images et de vidéos et offre des capacités de génération visuelle de pointe grâce à de nombreuses innovations dans les cadres de modèles, les données d'entraînement, les méthodes d'annotation et la conception des produits.
Dans ce modèle amélioré, l'équipe de Tongyi Wanxiang (ci-après dénommée "l'équipe") a en outreArchitectures VAE et DiT efficaces développées par l'entreprise elle-mêmeLa génération est ainsi considérablement optimisée grâce à l'amélioration de la modélisation des relations contextuelles spatio-temporelles.
L'appariement de flux est un cadre émergent pour l'apprentissage de modèles génératifs ces dernières années. Il est plus simple à apprendre, permet d'obtenir une qualité comparable, voire supérieure, à celle des modèles de diffusion grâce au flux de normalisation continu et offre des vitesses d'inférence plus rapides ; il est progressivement appliqué au domaine de la génération de vidéos. Par exemple, le modèle vidéo Movie Gen publié précédemment par Meta utilise l'appariement des flux.
Pour la sélection des méthodes de formation, Tongyi Wanxiang 2.1 utilise la méthode desSchéma de correspondance des flux basé sur des trajectoires de bruit linéaireset a été conçu en profondeur pour le cadre, ce qui a permis d'améliorer la convergence du modèle, la qualité de la génération et l'efficacité.

Tongyi Wanxiang 2.1 Schéma de l'architecture de la génération vidéo
Pour la VAE vidéo, l'équipe a conçu un schéma de codec vidéo innovant en combinant le mécanisme de mise en cache et la convolution causale.. Parmi eux, le mécanisme de mise en cache peut conserver les informations nécessaires au traitement vidéo, réduisant ainsi les calculs répétés et améliorant l'efficacité des calculs ; la convolution causale peut capturer les caractéristiques temporelles de la vidéo et s'adapter aux changements progressifs du contenu vidéo.
L'implémentation remplace le processus de décodage E2E direct pour les vidéos longues en divisant la vidéo en morceaux et en mettant en cache les caractéristiques intermédiaires, de sorte que l'utilisation de la carte graphique n'est liée qu'à la taille des morceaux, quelle que soit la longueur de la vidéo originale, ce qui permet au modèle d'encoder et de décoder efficacement des vidéos 1080P d'une longueur illimitée. L'équipe affirme que cette technologie clé offre une voie viable pour l'apprentissage de vidéos de longueur arbitraire.
La figure suivante montre la comparaison des résultats des différents modèles de VAE. En termes d'efficacité de calcul du modèle (trame/délai) et de reconstruction de la compression vidéo (rapport signal/bruit de crête, PSNR), la VAE adoptée par Tongyi Wanxiang obtient toujours les résultats suivants sans paramètres dominantsQualité de compression et de reconstruction vidéo à la pointe de l'industrie.
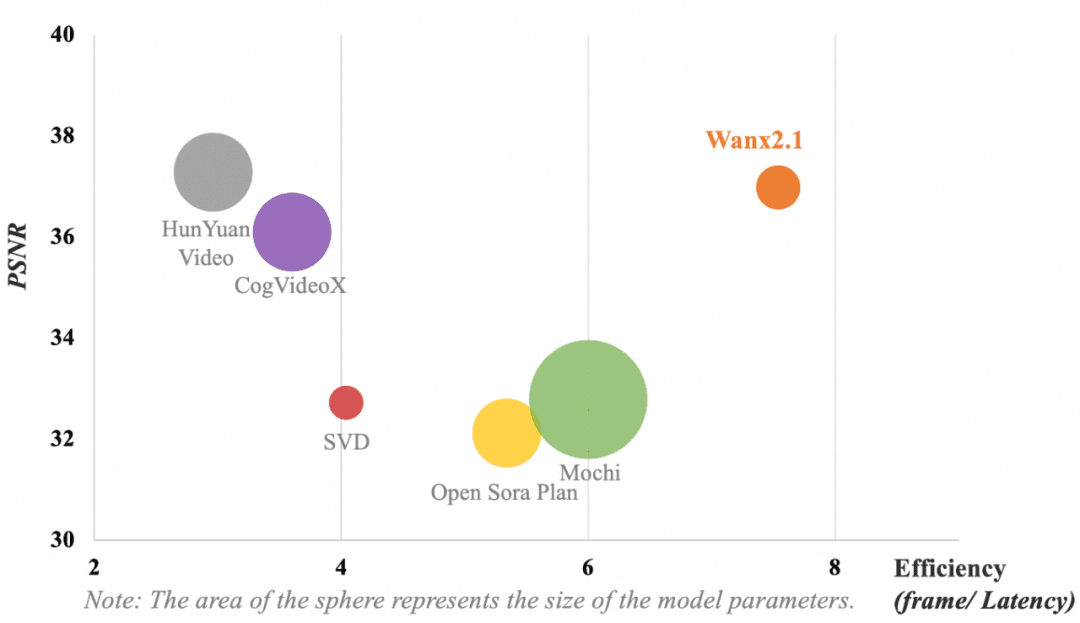
Note : Le cercle représente la taille des paramètres du modèle.
L'objectif principal de l'équipe pour la conception de DiT (Diffusion Transformer) était d'obtenir de puissantes capacités de modélisation spatio-temporelle tout en maintenant un processus de formation efficace. Pour ce faire, un certain nombre de changements innovants ont été nécessaires.
Premièrement, afin d'améliorer la capacité de modélisation des relations spatio-temporelles, l'équipe adopte un mécanisme d'attention complète spatio-temporelle, qui permet au modèle de simuler plus précisément la dynamique complexe du monde réel. Deuxièmement, l'introduction du mécanisme de partage des paramètres réduit efficacement le coût de la formation tout en améliorant les performances. En outre, l'équipe a optimisé les performances de l'intégration de texte en utilisant le mécanisme d'attention croisée pour intégrer les caractéristiques du texte, ce qui permet d'obtenir une meilleure contrôlabilité du texte et de réduire les besoins de calcul.
Grâce à ces améliorations et à ces tentatives, la structure DiT de la phase universelle généralisée atteint une supériorité de convergence plus prononcée au même coût de calcul.
Outre les innovations en matière d'architecture des modèles, l'équipeCertaines optimisations ont été réalisées dans les domaines de l'apprentissage et de l'inférence des séquences ultra-longues, du pipeline de construction des données et de l'évaluation des modèles, ainsi que dans les domaines suivantsce qui permet au modèle de traiter efficacement des tâches génératives complexes avec des avantages d'efficacité accrus.
Comment s'entraîner efficacement avec des millions de séquences ultra-longues ?
Lorsqu'ils traitent des séquences visuelles très longues, les grands modèles sont souvent confrontés à des défis à plusieurs niveaux, tels que le calcul, la mémoire, la stabilité de l'apprentissage, le temps de latence de l'inférence, et donc à des solutions efficaces pour y faire face.
À cette fin, l'équipe a combiné les caractéristiques de la charge de travail du nouveau modèle et les performances matérielles du cluster de formation pour développer une stratégie de formation distribuée et optimisée en termes de mémoire afin d'optimiser les performances de formation tout en garantissant le temps d'itération du modèle.Une UPM à la pointe de l'industrie et une formation efficace pour 1 million de séquences ultra-longues..
D'une part, l'équipe innove dans la stratégie distribuée en adoptant l'entraînement parallèle 4D avec DP, FSDP, RingAttention et Ulysses, ce qui améliore à la fois les performances de l'entraînement et l'évolutivité distribuée. D'autre part, afin d'optimiser la mémoire, l'équipe adopte une stratégie d'optimisation hiérarchique de la mémoire pour optimiser la mémoire d'activation et résoudre le problème de fragmentation de la mémoire sur la base du volume de calcul et de communication causé par la longueur de la séquence.
C'est pourquoi l'équipe adopte FlashAttention3 pour le calcul spatio-temporel de l'attention complète et choisit la stratégie CP appropriée pour le découpage, en tenant compte des performances de calcul des grappes d'entraînement de différentes tailles. Dans le même temps, l'équipe a supprimé la redondance de calcul pour certains modules clés, et a réduit la surcharge d'accès et amélioré l'efficacité de calcul grâce à une mise en œuvre efficace du noyau. En ce qui concerne le système de fichiers, l'équipe exploite pleinement les caractéristiques de lecture/écriture du système de fichiers haute performance du cluster de formation AliCloud et améliore les performances de lecture/écriture grâce au découpage Save/Load.

Stratégie de formation distribuée en parallèle 4D
Dans le même temps, l'équipe a choisi un schéma d'utilisation de la mémoire échelonné pour résoudre les problèmes OOM causés par le Dataloader Prefetch, le CPU Offloading et le Save Checkpoint pendant la formation. En outre, pour garantir la stabilité de la formation, l'équipe s'est appuyée sur la planification intelligente, la détection des machines lentes et les capacités d'autoréparation du cluster de formation d'AliCloud pour identifier automatiquement les nœuds défectueux et redémarrer rapidement la tâche.
Introduction de l'automatisation dans la construction des données et l'évaluation des modèles
Il n'est pas possible de former de grands modèles de génération vidéo sans disposer de données de haute qualité à grande échelle et sans une évaluation efficace des modèles.Le premier garantit que le modèle apprend divers scénarios, des dépendances spatio-temporelles complexes et améliore la généralisation, ce qui constitue la pierre angulaire de l'apprentissage du modèle ; le second permet de surveiller les performances du modèle afin qu'il atteigne mieux les résultats escomptés et devient la girouette de l'apprentissage du modèle.
En ce qui concerne la construction des données, l'équipe a mis au point un pipeline de construction de données automatisé avec pour critère la haute qualité, qui correspond parfaitement à la distribution des préférences humaines en termes de qualité visuelle, de qualité de mouvement, etc., de sorte que des données vidéo de haute qualité peuvent être automatiquement construites avec une grande diversité, une distribution équilibrée, et d'autres caractéristiques.
Pour l'évaluation des modèles, l'équipe a également conçu un ensemble complet de mesures automatisées, incorporant plus de deux douzaines de dimensions telles que la notation esthétique, l'analyse des mouvements et le respect des commandes, et a ciblé et formé des évaluateurs professionnels capables de s'aligner sur les préférences humaines. Grâce au retour d'information efficace de ces mesures, le processus d'itération et d'optimisation du modèle a été considérablement accéléré.
On peut dire que les innovations synergiques dans plusieurs domaines, tels que l'architecture, la formation et l'évaluation, ont permis au modèle de génération vidéo Tongyi Wanphase mis à jour de récolter des améliorations générationnelles significatives dans l'expérience réelle.
Moments GPT-3 pour la génération de vidéosCombien de temps encore ?
Depuis février dernier, l'équipe d'OpenAI Sora Depuis son introduction, le modèle de génération de vidéos est devenu le domaine le plus compétitif du monde de la technologie. Du pays à l'étranger, des startups aux géants de la technologie lancent leurs propres outils de génération de vidéos. Toutefois, par rapport à la génération de texte, l'IA vidéo présente plus d'un niveau de difficulté pour atteindre le degré d'acceptabilité.
Si, comme le dit Sam Altman, PDG d'OpenAI, Sora représente le moment GPT-1 dans le grand modèle de la génération vidéo, alors nous pouvons nous appuyer sur cette base pour parvenir à un contrôle précis des commandes textuelles et à la capacité d'ajuster les angles et les positions de la caméra pour assurer la cohérence des personnages. Si nous nous appuyons sur cette base pour parvenir à un contrôle précis de l'IA avec des commandes textuelles, des angles et des positions de caméra réglables, une caractérisation cohérente et d'autres capacités de génération vidéo, et si nous ajoutons la capacité unique de l'IA à changer rapidement de style et de scène, nous pourrions bientôt assister à un nouveau "moment GPT-3".
Du point de vue du développement technologique, le modèle de génération vidéo est un processus de vérification des lois d'échelle. Au fur et à mesure que la capacité du modèle de base s'améliore, l'IA comprendra de plus en plus de commandes humaines et sera capable de créer des environnements de plus en plus réalistes et raisonnables.
D'un point de vue pratique, nous sommes en fait impatients : depuis l'année dernière, les professionnels de la vidéo courte, de l'animation et même du cinéma et de la télévision ont commencé à utiliser l'IA de génération vidéo à des fins d'exploration créative. Si nous parvenons à dépasser les limites de la réalité et à réaliser des choses inimaginables avec l'IA de génération vidéo, un nouveau cycle de changements dans l'industrie est à nos portes.
Il semble maintenant que Tongyi Manxiang ait fait le premier pas.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...