Tifa-Deepsex-14b-CoT : un grand modèle spécialisé dans les jeux de rôle et la génération de fictions ultra-longues
Introduction générale
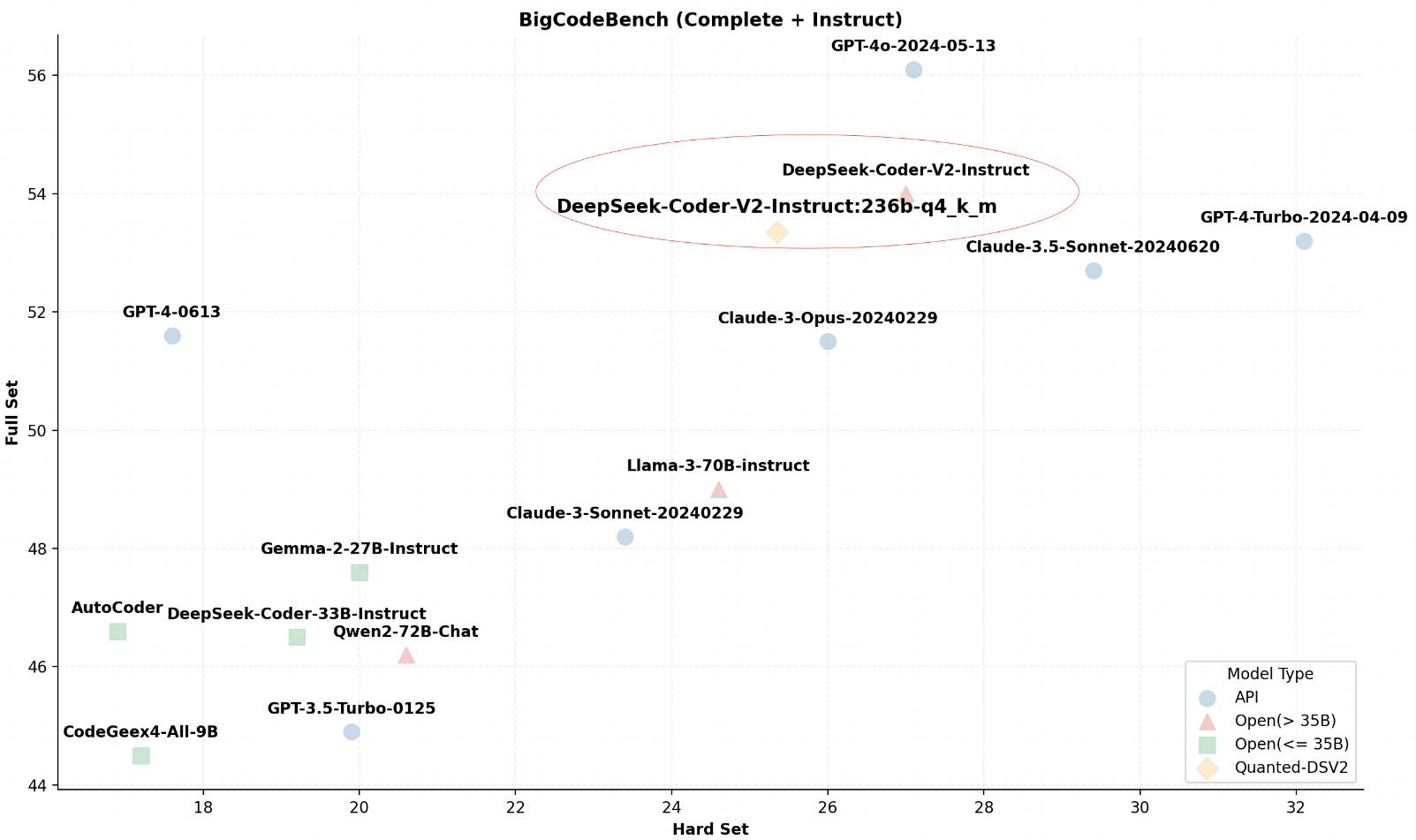
Tifa-Deepsex-14b-CoT est un grand modèle basé sur l'optimisation profonde de Deepseek-R1-14B, qui se concentre sur le jeu de rôle, la génération de texte fictif et la capacité de raisonnement de la chaîne de pensée (CoT). Grâce à une formation et une optimisation en plusieurs étapes, le modèle résout les problèmes de cohérence insuffisante dans la génération de textes longs et de faible capacité de jeu de rôle du modèle original, ce qui est particulièrement adapté aux scénarios créatifs nécessitant une corrélation contextuelle à longue portée. En fusionnant des ensembles de données de haute qualité et un pré-entraînement incrémental, le modèle améliore considérablement la pertinence contextuelle, réduit les non-réponses et élimine le mélange chinois-anglais, augmentant ainsi le vocabulaire spécifique au domaine pour de meilleures performances dans le jeu de rôle et la génération de nouvelles. En outre, le modèle prend en charge 128k contextes ultra-longs pour les scénarios nécessitant un dialogue approfondi et une rédaction complexe.
Il s'agit d'une version de Deepseek-R1-14B qui est profondément optimisée pour les fictions de longue durée et les scénarios de jeu de rôle, et qui dispose d'un client Android simple à télécharger. Mises à jour actuelles Deepsex2 Édition.

Liste des fonctions
- Permet un dialogue approfondi pour les scénarios de jeux de rôle, en générant des réponses qui correspondent à la personnalité et à l'histoire du personnage.
- Fournir des compétences en matière de production de textes fictifs afin de pouvoir créer des histoires ou des intrigues longues et cohérentes.
- Compétences de raisonnement en chaîne de pensée (CoT) pour les scénarios nécessitant des déductions logiques et la résolution de problèmes complexes.
- Prise en charge d'un contexte ultra-long de 128k pour garantir la cohérence et l'homogénéité de la génération de textes longs.
- Le modèle optimisé réduit le phénomène de rejet des réponses et la sécurité est modérément préservée pour les divers besoins de rédaction.
- Fournir une variété de versions de quantification (par exemple F16, Q8, Q4) pour s'adapter à différents environnements matériels afin de faciliter le déploiement et l'utilisation.
Utiliser l'aide
Installation et déploiement
Le modèle Tifa-Deepsex-14b-CoT est hébergé sur la plateforme Hugging Face, et les utilisateurs doivent sélectionner la version appropriée du modèle (par exemple, F16, Q8, Q4) en fonction de leur environnement matériel et de leurs besoins. Le processus d'installation et de déploiement est détaillé ci-dessous :
1. télécharger le modèle
- Visitez la page du modèle Hugging Face à l'adresse https://huggingface.co/ValueFX9507/Tifa-Deepsex-14b-CoT.
- Sélectionnez la version de quantification appropriée (par exemple Q4_K_M.gguf) en fonction du support matériel. Cliquez sur le fichier correspondant pour télécharger les poids du modèle.
- Si vous avez besoin d'utiliser l'APK de démonstration, vous pouvez télécharger directement l'application de démonstration officiellement fournie (vous devez importer manuellement la carte de personnage et sélectionner l'API personnalisée).
2. préparation à l'environnement
- Assurez-vous que l'environnement Python est installé (Python 3.8 ou supérieur est recommandé).
- Installez les bibliothèques de dépendances nécessaires, telles que transformers, huggingface_hub, etc. Elles peuvent être installées à l'aide des commandes suivantes :
pip install transformers huggingface-hub - Si vous utilisez un modèle au format GGUF, il est recommandé d'installer le fichier llama.cpp ou des bibliothèques de support associées. peut être cloné et compilé à l'aide de la commande suivante :
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp make
3. chargement du modèle
- Utiliser des transformateurs pour charger le modèle :
from transformers import AutoModelForCausalLM, AutoTokenizer model_name = "ValueFX9507/Tifa-Deepsex-14b-CoT" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) - Si vous utilisez le format GGUF, il peut être exécuté via llama.cpp :
./main -m Tifa-Deepsex-14b-CoT-Q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "你的提示词"où -c 4096 peut être ajusté à une longueur de contexte plus grande (par exemple 128k) si nécessaire, mais attention aux limitations matérielles.
4. configuration et optimisation
- Veillez à ce que le contexte renvoyé soit dépouillé des étiquettes de pensée (par exemple) afin d'éviter d'affecter la sortie du modèle. Ceci peut être réalisé avec le code suivant :
content = msg.content.replace(/<think>[\s\S]*?<\/think>/gi, '') - Si vous utilisez l'interface frontale, vous devez modifier manuellement le code de l'interface frontale pour adapter le traitement du contexte, en vous référant au modèle officiel.
Fonction Opération Déroulement
jeu de rôle
- Saisir les paramètres du personnage : spécifier le contexte, la personnalité, les scènes de dialogue, etc. du personnage dans l'invite. Exemple :
你是一个勇敢的冒险者,名叫蒂法,正在探索一座神秘的古城。请描述你的冒险经历,并与遇到的 NPC 进行对话。 - Générer des réponses : le modèle génère des dialogues ou des récits qui correspondent au personnage en fonction des paramètres de ce dernier. L'utilisateur peut continuer à saisir des données et le modèle maintient la cohérence contextuelle.
- Ajustement des paramètres : optimisez le résultat en ajustant la température (pour contrôler le caractère aléatoire du texte généré) et repeat_penalty (pour contrôler le contenu répété).
Nouvelle fonction de génération
- Définir le contexte de l'histoire : fournir le début ou les grandes lignes de l'histoire, par exemple :
在一个遥远的王国,有一位年轻的法师试图解开时间的秘密。请续写这个故事。 - Générer une histoire : le modèle génère des histoires longues et cohérentes à partir de messages-guides, ce qui permet de produire plusieurs paragraphes.
- Prise en charge des contextes longs : grâce à la prise en charge des contextes de 128k, les utilisateurs peuvent saisir des contextes d'histoire plus longs et le modèle conserve la cohérence de l'intrigue.
le raisonnement en chaîne de pensée (CoT)
- Saisir des problèmes complexes : par exemple
如果一个城市每天产生100吨垃圾,其中60%可回收,40%不可回收,但回收设施每天只能处理30吨可回收垃圾,剩余的可回收垃圾如何处理? - Générer un processus de raisonnement : le modèle analyse le problème étape par étape, fournit des réponses logiques et claires et soutient un raisonnement à long terme.
mise en garde
- Matériel requis : Le modèle nécessite un niveau élevé de mémoire graphique pour fonctionner. Il est recommandé d'utiliser un GPU ou un processeur haute performance avec au moins 16 Go de mémoire graphique.
- Sécurité et conformité : le modèle conserve certains paramètres de sécurité pendant la formation, et les utilisateurs doivent s'assurer que le scénario d'utilisation est conforme aux lois et réglementations en vigueur.
- Gestion des contextes : lors de l'utilisation de contextes très longs, il est recommandé de saisir les mots d'invite par segments afin d'éviter de dépasser les limites matérielles.
Grâce à ces étapes, les utilisateurs peuvent facilement commencer à utiliser le modèle Tifa-Deepsex-14b-CoT, que ce soit pour un jeu de rôle, la création d'un roman ou un raisonnement complexe, et obtenir des résultats de grande qualité.
Tifa-Deepsex-14b-CoT Différence de version
Tifa-Deepsex-14b-CoT
- Validation du modèle pour tester l'impact de l'algorithme de récompense RL sur les données des jeux de rôle, la version initiale a une sortie flexible mais non contrôlée et est destinée à un usage de recherche uniquement.
Tifa-Deepsex-14b-CoT-Chat
- Entraîné avec des données standard, en utilisant des stratégies RL éprouvées avec un apprentissage par renforcement antirépétition supplémentaire, adapté à une utilisation normale. La qualité du texte de sortie est normale, avec une pensée divergente dans quelques cas.
- Formation incrémentale de 0,4T de contenu nouveau, 100K données SFT générées par TifaMax, 10K données SFT générées par DeepseekR1, et 2K données manuelles de haute qualité.
- 30K données d'apprentissage par renforcement des OPH générées par TifaMax pour éviter les doublons, renforcer les associations contextuelles et améliorer la sécurité politique.
Tifa-Deepsex-14b-CoT-Crazy
- Un grand nombre de stratégies RL sont utilisées, principalement à partir des données distillées par 671B full-blooded R1, avec une grande dispersion de sortie, héritant des avantages de R1 ainsi que des dangers de R1, et de bonnes performances littéraires.
- Formation incrémentale de 0,4T de contenu nouveau, 40K données SFT générées par TifaMax, 60K données SFT générées par DeepseekR1, et 2K données manuelles de haute qualité.
- 30 000 données d'apprentissage par renforcement générées par TifaMax pour éviter les doublons, améliorer la pertinence contextuelle et la sécurité politique. 10 000 données d'OPP générées par TifaMax et 10 000 données d'OPP générées par DeepseekR1.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...