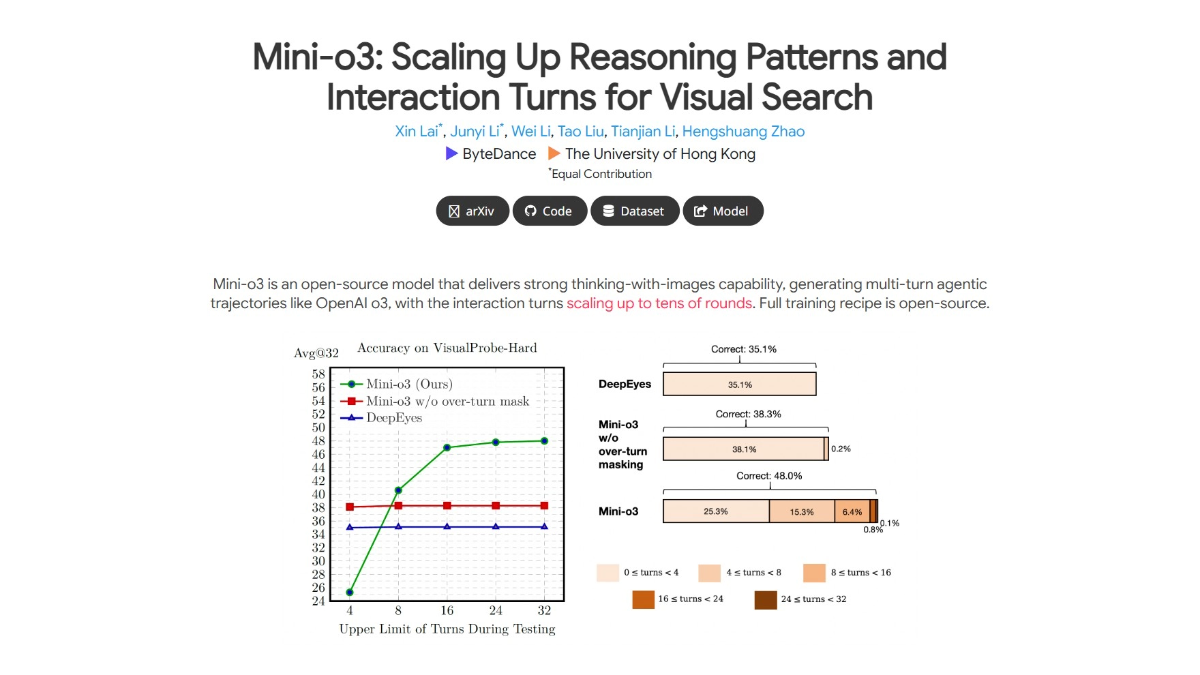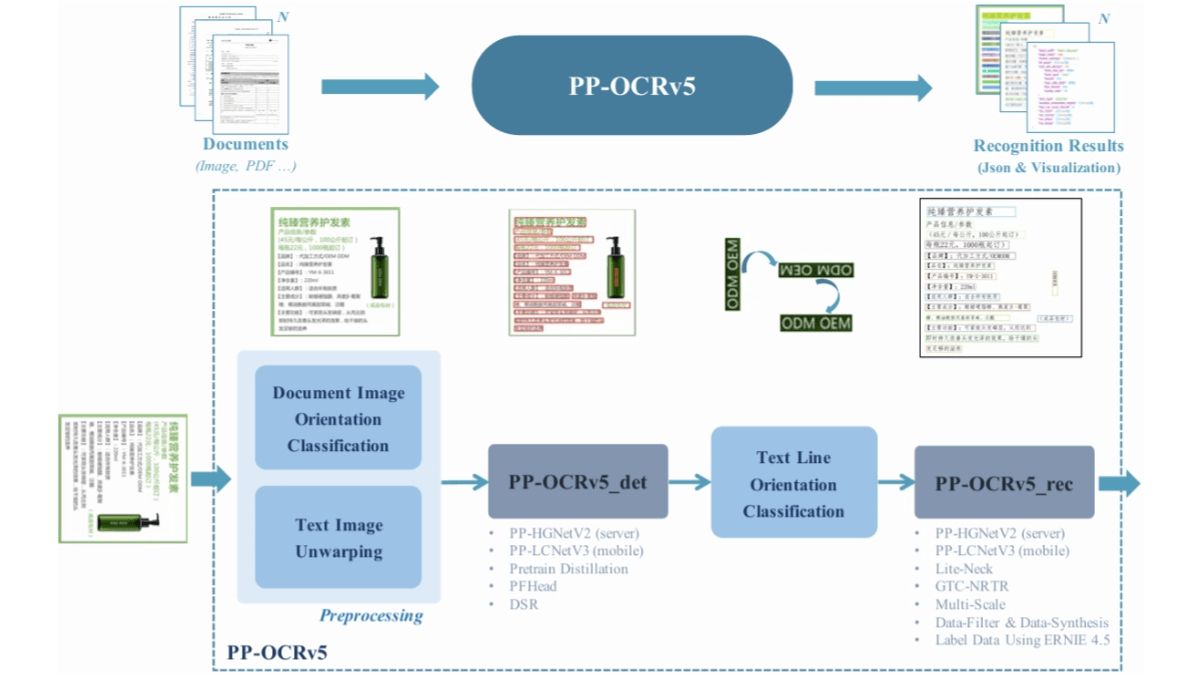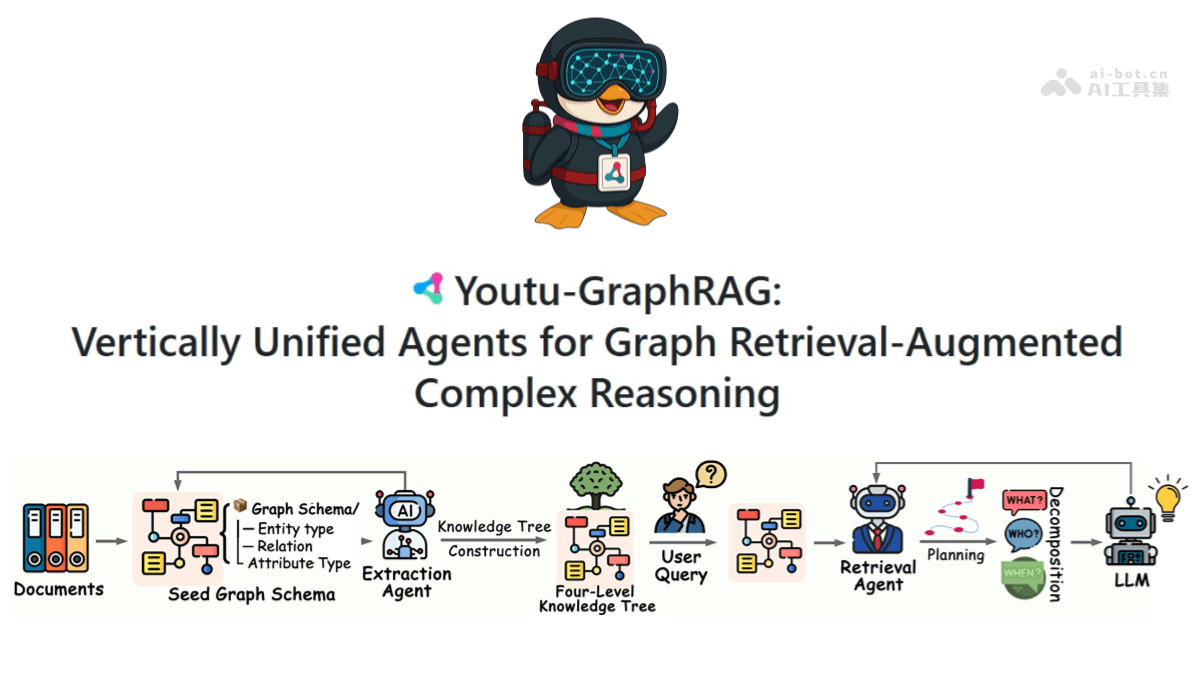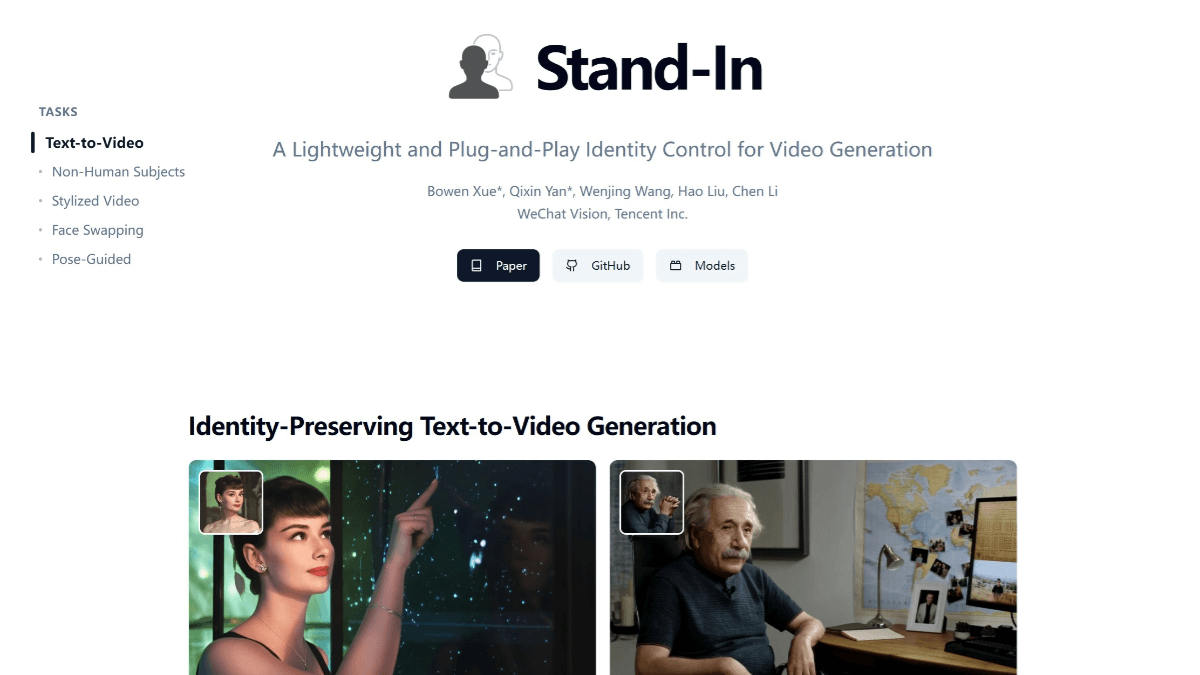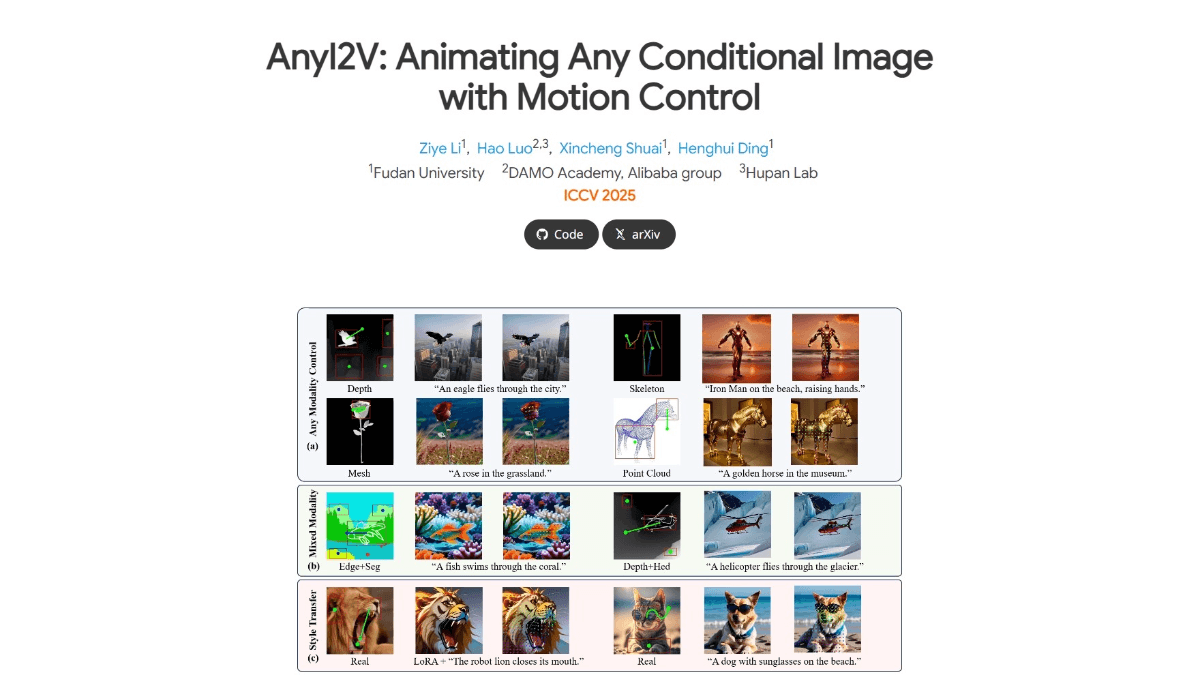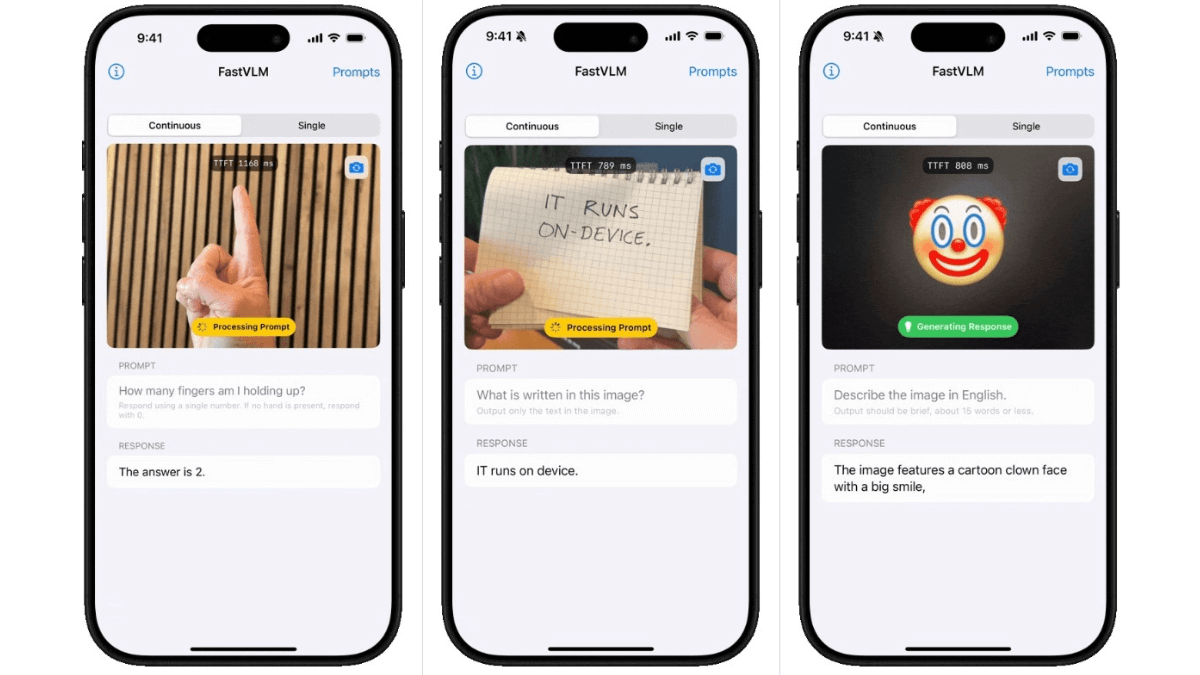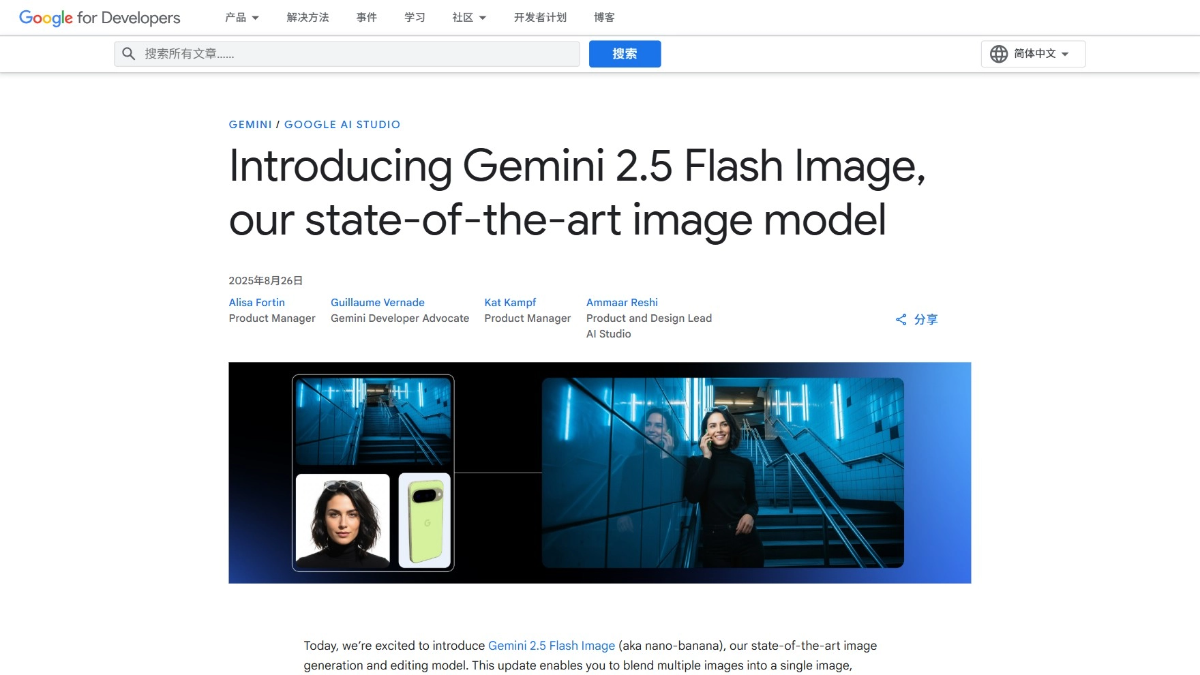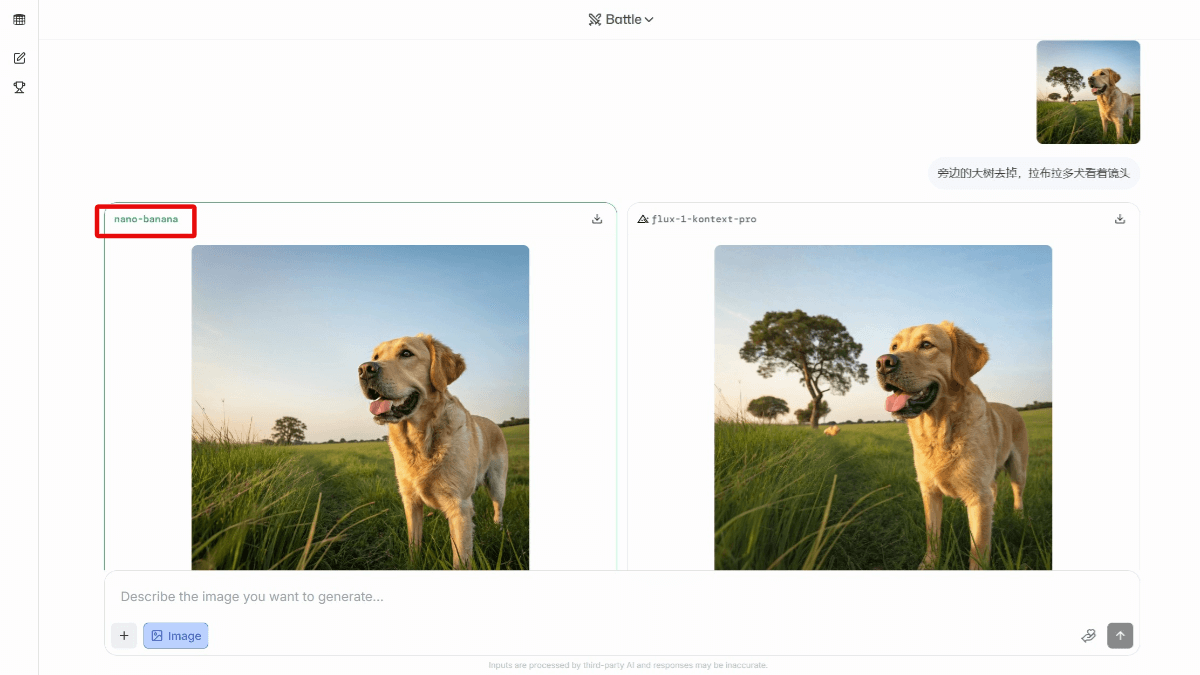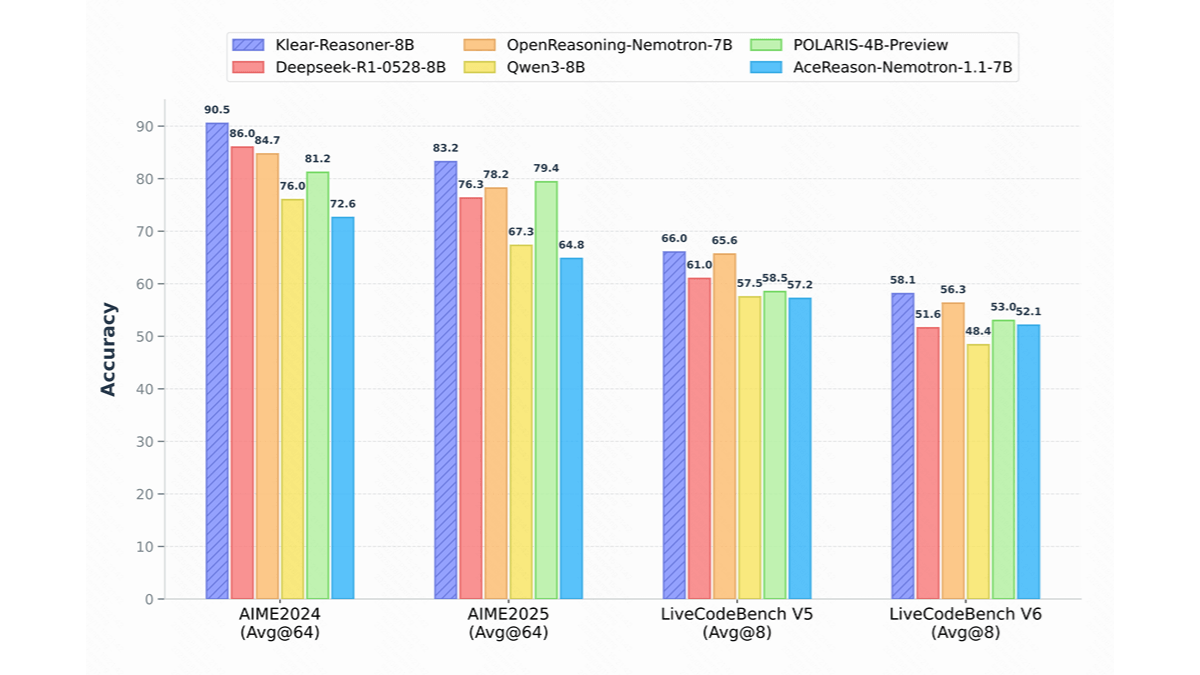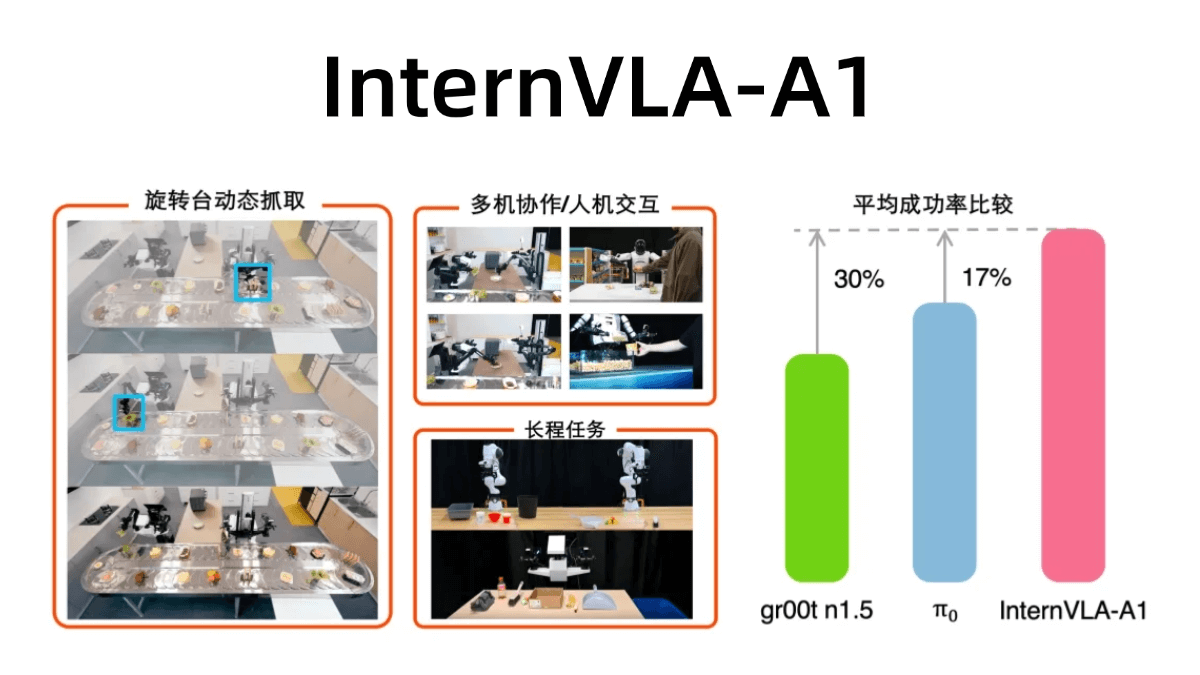
méso (chimie)InternVLA-A1 - Shanghai AI Lab Open Source Integration of Operational Capabilities for Embodied Large Models (Intégration des capacités opérationnelles pour les grands modèles incarnés)
InternVLA-A1 est un grand modèle d'opération incarnée mis à disposition par le laboratoire d'intelligence artificielle de Shanghai. Il est capable de comprendre, d'imaginer et d'exécuter l'intégration, et peut accomplir la tâche avec précision. Le modèle fusionne les données d'opérations réelles et simulées, et automatise la construction d'actifs hybrides virtuels-réels multimodaux à grande échelle...