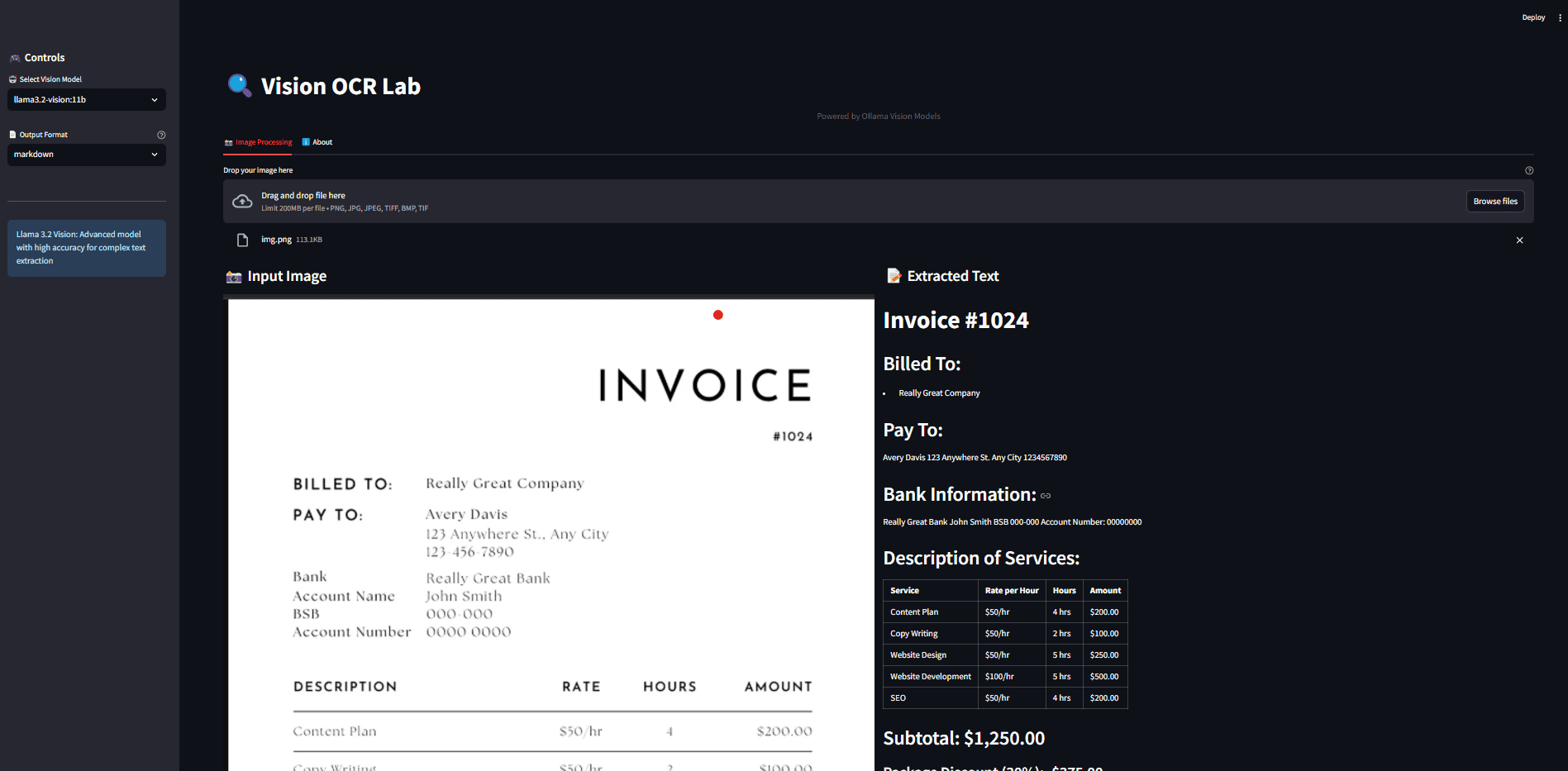
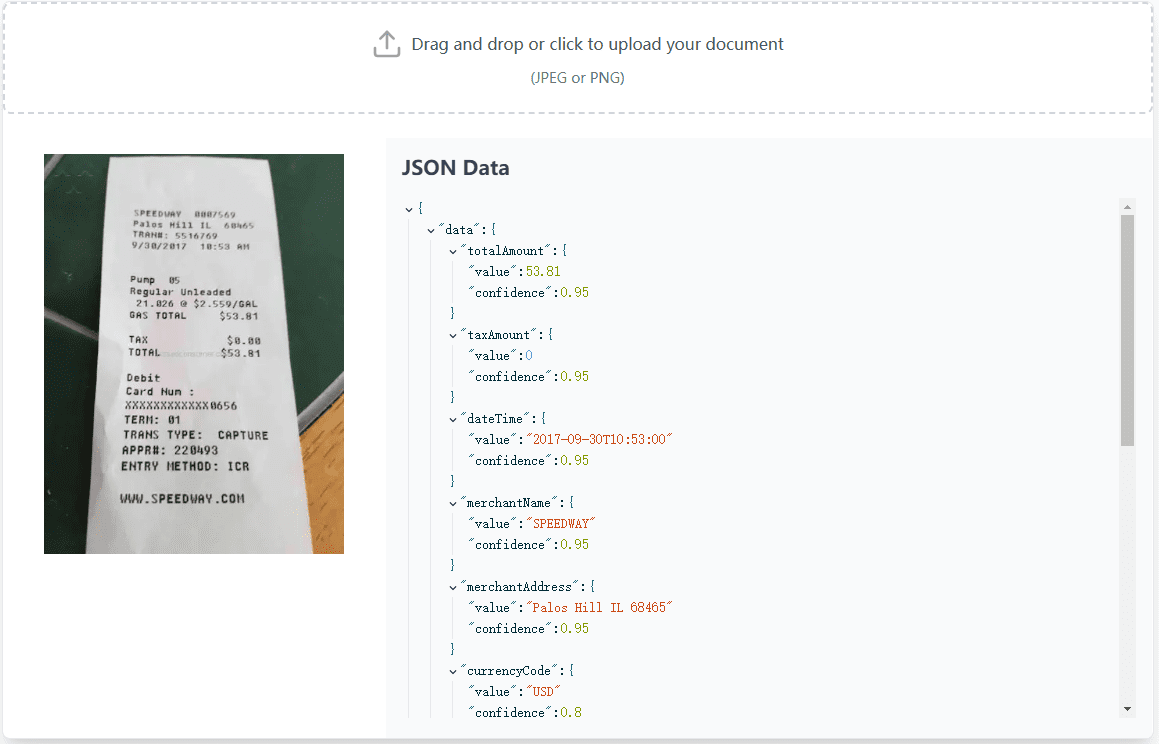
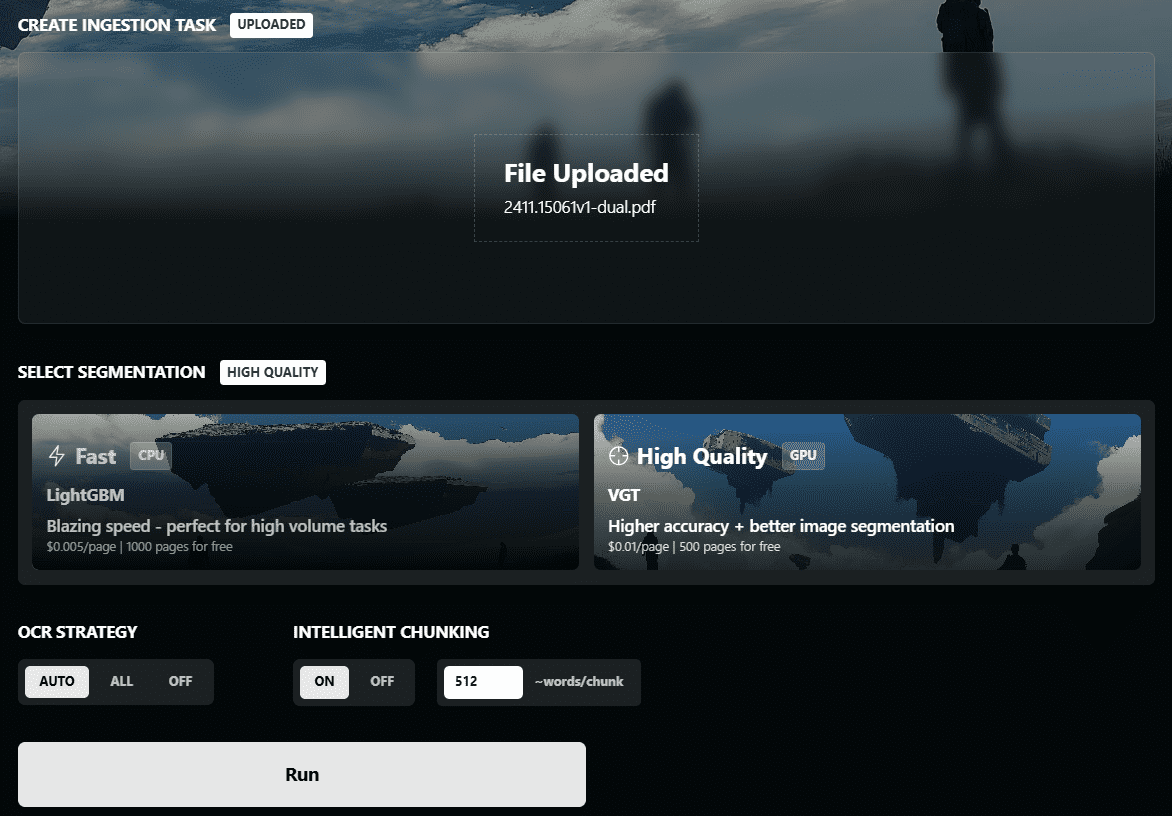
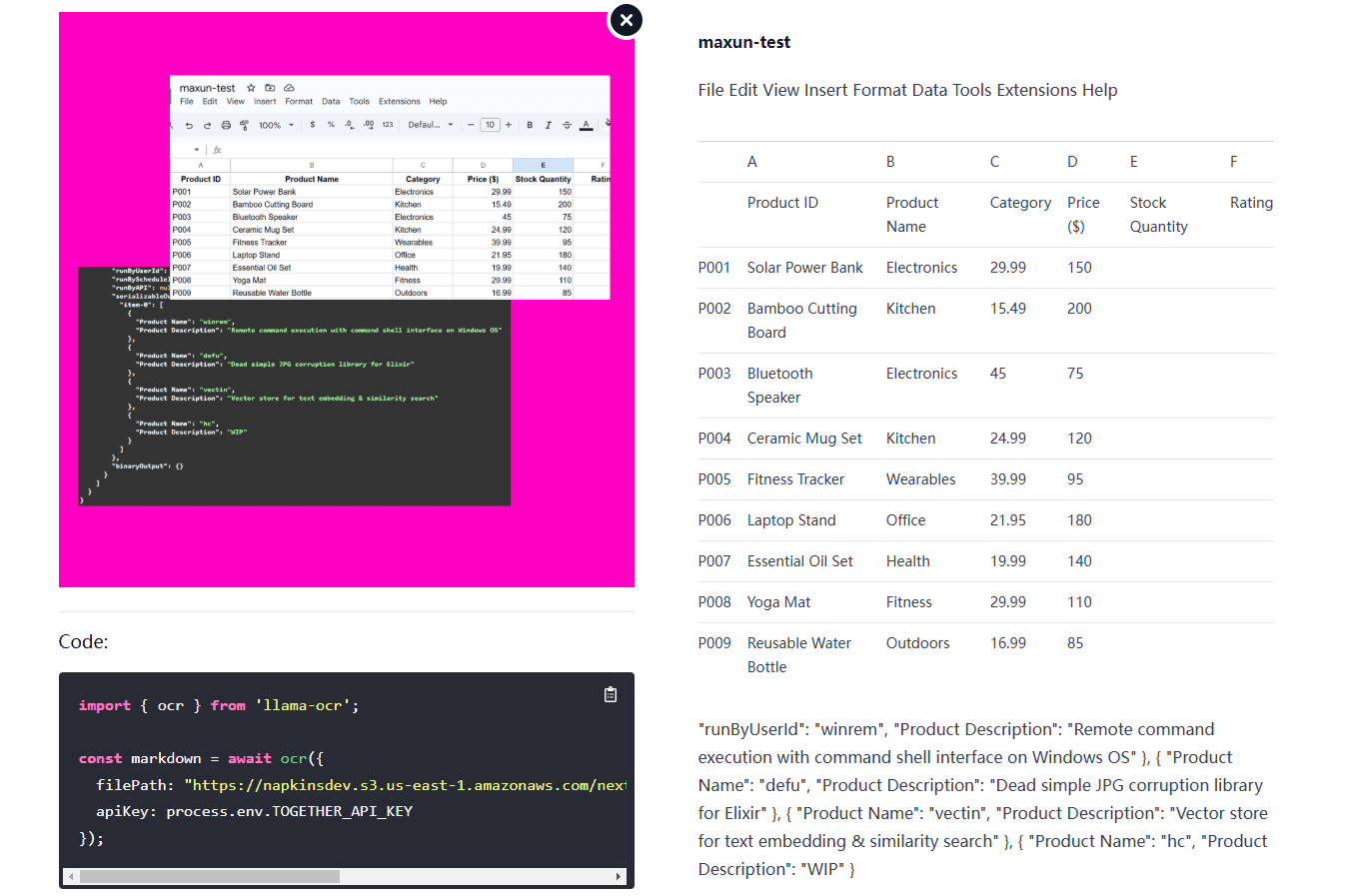
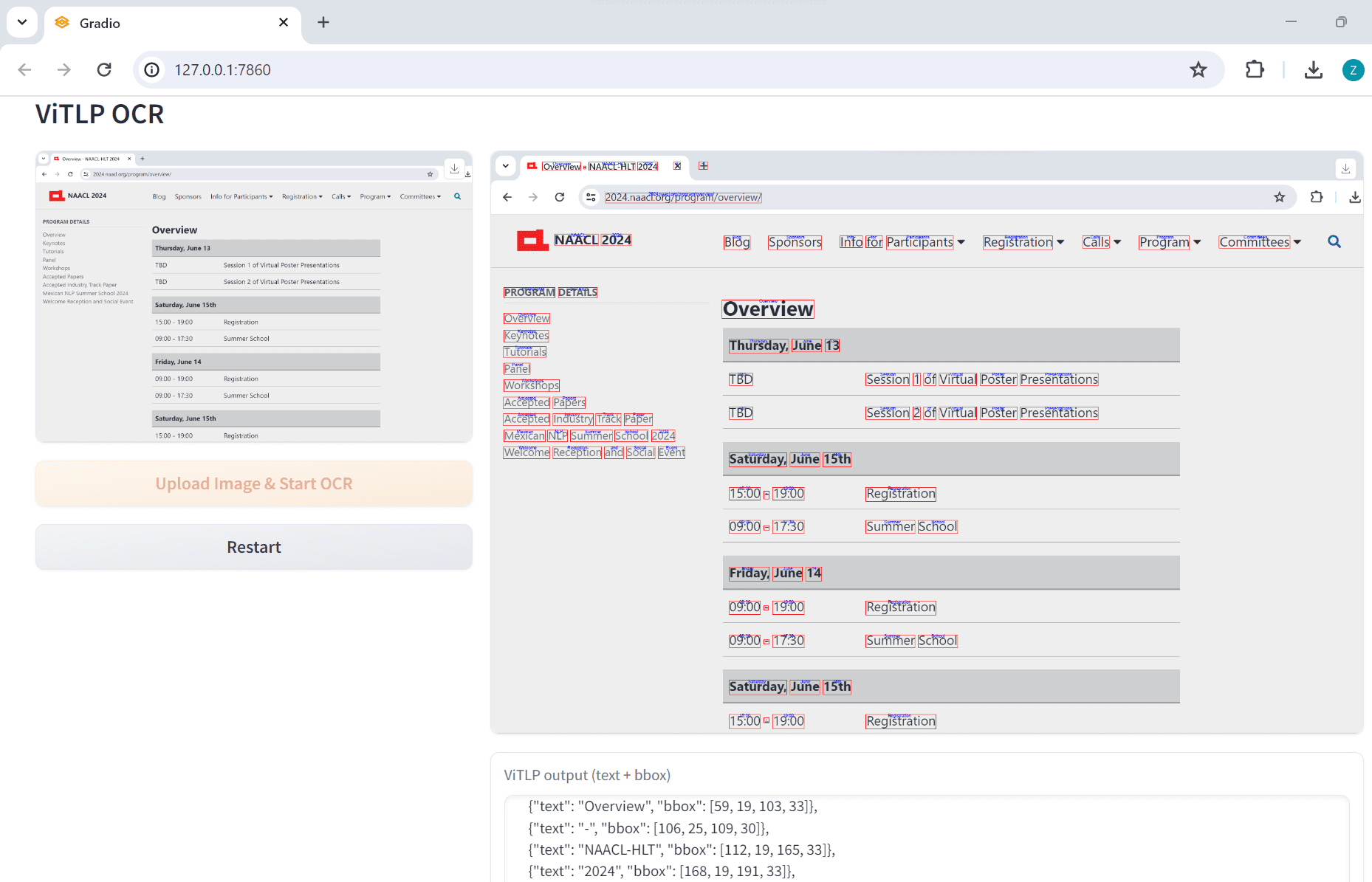
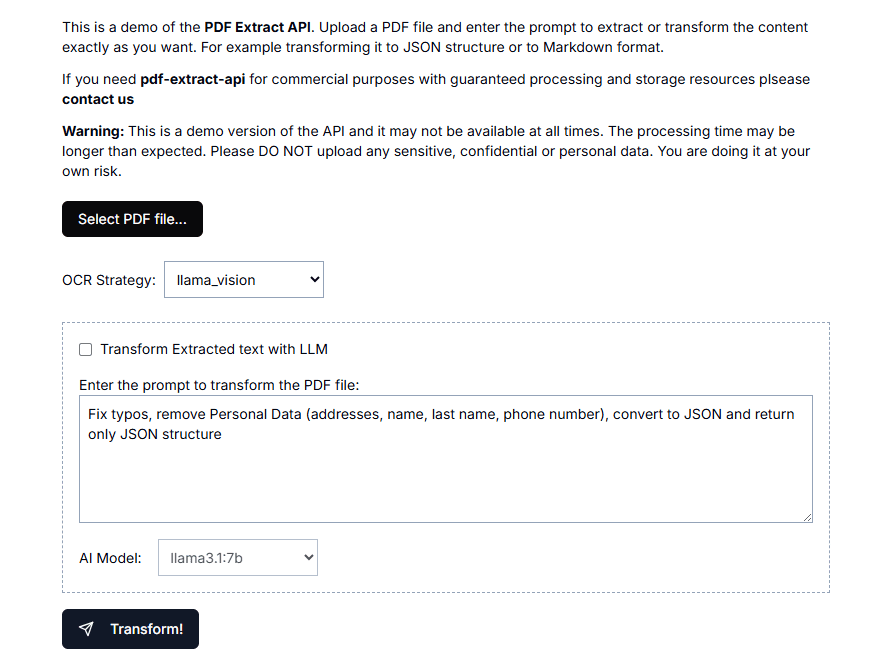
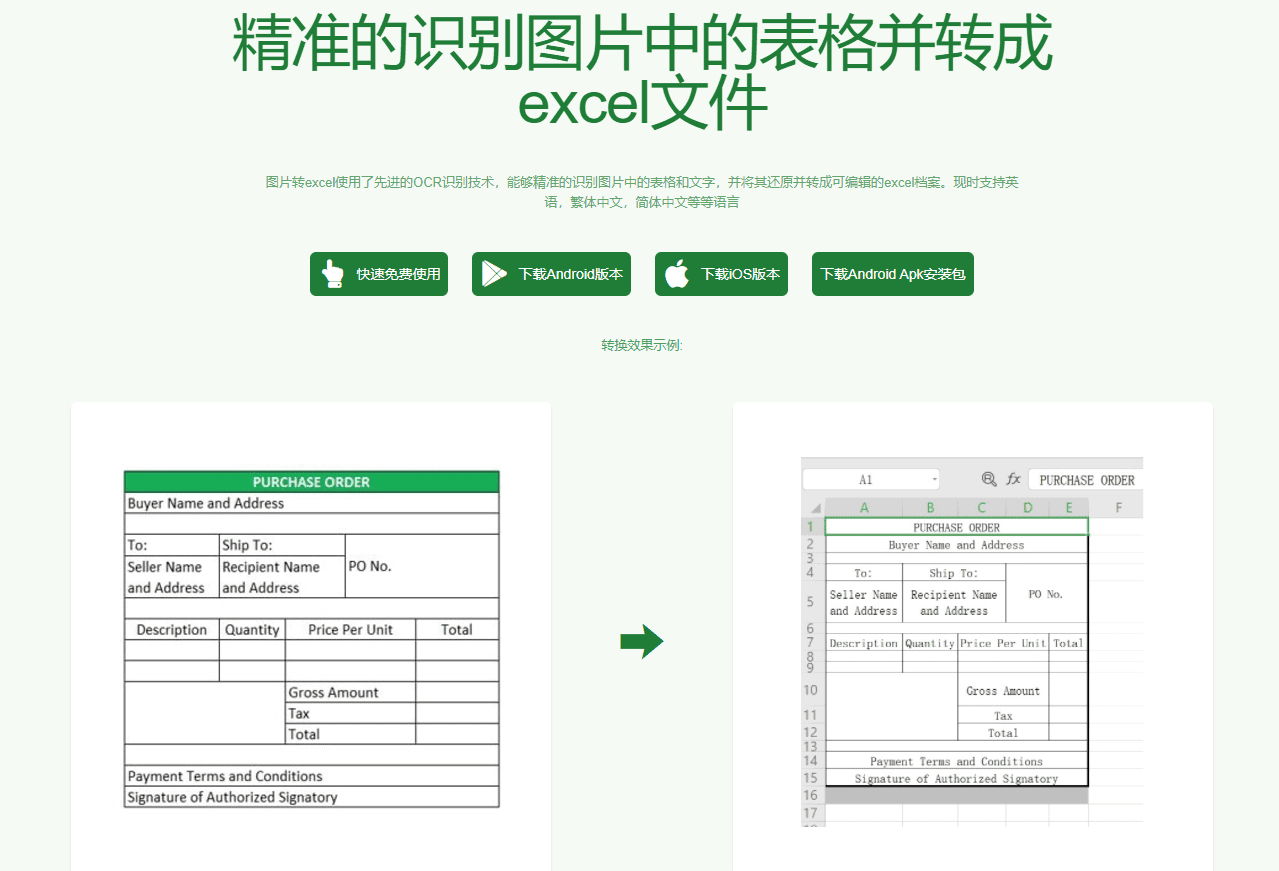
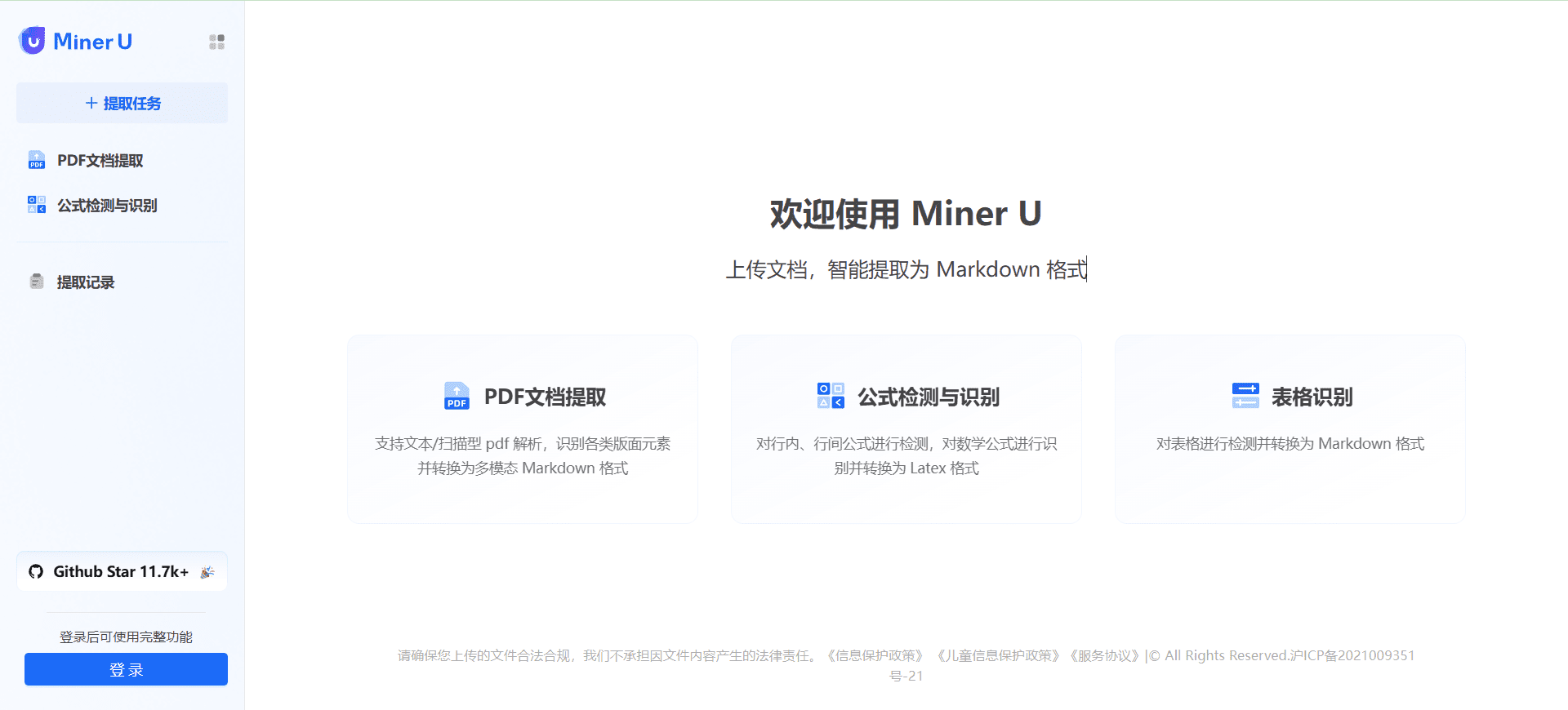
VOP : outil d'OCR pour l'extraction de diagrammes complexes et de formules mathématiques
Introduction complète Versatile OCR Program est un outil de reconnaissance optique de caractères (OCR) open source conçu pour travailler avec des documents académiques et éducatifs complexes. Il peut extraire du texte, des tableaux, des formules mathématiques, des diagrammes et des schémas à partir de PDF, d'images et d'autres documents et générer...