
Step-Video-T2V : un modèle vidéo de Vincennes prenant en charge l'entrée multilingue et la génération de vidéos de longue durée
Introduction générale
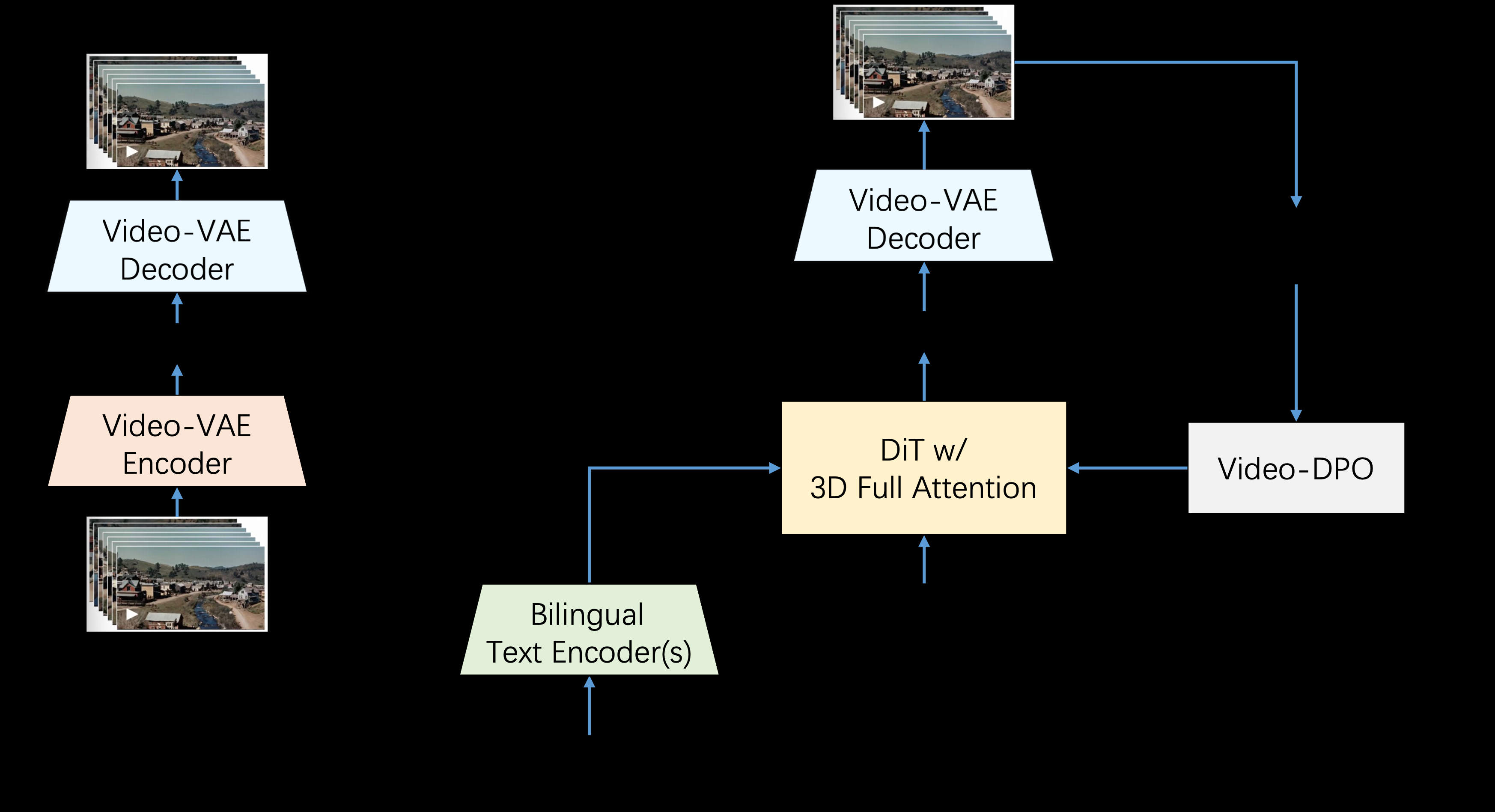
Step-Video-T2V est un modèle avancé de conversion texte-vidéo de StepFun AI (Step Star). Le modèle a 3 milliards de paramètres et est capable de générer des vidéos jusqu'à 204 fps. Grâce à un autoencodeur variable (VAE) profondément compressé, le modèle atteint une compression spatiale de 16x16 et une compression temporelle de 8x, ce qui améliore l'efficacité de l'entraînement et de l'inférence.Step-Video-T2V obtient de bons résultats dans le domaine de la génération vidéo, notamment en termes de mouvement et d'efficacité. Cependant, il reste des défis à relever pour traiter les mouvements complexes. Le modèle est open source et les utilisateurs peuvent accéder et contribuer au code sur GitHub.
Liste des fonctions
- Génération de vidéos de haute qualité : générez des vidéos jusqu'à 204 images par seconde en utilisant 3 milliards de paramètres.
- Technique de compression profonde : compression spatiale 16x16 et compression temporelle 8x à l'aide d'un auto-encodeur variationnel à compression profonde.
- Prise en charge bilingue : prend en charge les alertes textuelles en anglais et en chinois.
- Source ouverte et soutien de la communauté : les modèles et les ensembles de données de référence sont en source ouverte afin de favoriser l'innovation et de donner aux créateurs les moyens d'agir.
Utiliser l'aide
Processus d'installation
- Clonage des dépôts GitHub :
git clone https://github.com/stepfun-ai/Step-Video-T2V.git - Accédez au catalogue de projets :
cd Step-Video-T2V - Créer et activer un environnement virtuel :
conda create -n stepvideo python=3.10 conda activate stepvideo - Installer la dépendance :
pip install -e . pip install flash-attn --no-build-isolation ## flash-attn是可选的
Lignes directrices pour l'utilisation
Générer une vidéo
- Préparer des invites textuelles à enregistrer dans un fichier, par exemple
prompt.txt: :飞机在蓝天中飞翔 - Exécutez le script de génération de vidéo :
python generate_video.py --input prompt.txt --output video.mp4
Fonction détaillée du déroulement des opérations
- Générer des vidéos de haute qualité: :
- Saisie de texte : l'utilisateur saisit un texte décrivant le contenu de la vidéo.
- Traitement du modèle : le modèle Step-Video-T2V analyse le texte et génère de la vidéo.
- Sortie vidéo : la vidéo générée est enregistrée au format MP4, qui peut être visionné et partagé par les utilisateurs à tout moment.
- Technologie de compression profonde: :
- Compression spatiale : améliore l'efficacité de la génération vidéo grâce à la technologie de compression spatiale 16x16.
- Compression temporelle : la vitesse et la qualité de la génération vidéo sont encore optimisées grâce à la technologie de compression temporelle 8x.
- Soutien bilingue: :
- Prise en charge de l'anglais : les utilisateurs peuvent saisir un texte en anglais, et le modèle analyse et génère automatiquement la vidéo correspondante.
- Prise en charge du chinois : les utilisateurs peuvent saisir un texte en chinois, le modèle peut également générer la vidéo correspondante, afin de répondre aux besoins des utilisateurs multilingues.
- Source ouverte et soutien de la communauté: :
- Code source ouvert : les utilisateurs peuvent accéder au code complet du modèle sur GitHub pour le déployer et le modifier eux-mêmes.
- Contribution de la communauté : les utilisateurs peuvent soumettre des contributions de code pour participer à l'amélioration et à l'optimisation du modèle.
Inférence et quantification à l'aide d'un seul GPU
Le projet Step-Video-T2V prend en charge l'inférence et la quantification sur une seule GPU, ce qui réduit considérablement la quantité de mémoire graphique requise. Veuillez vous référer àExemples connexesPlus d'informations.
Paramètres de raisonnement des meilleures pratiques
Step-Video-T2V donne de bons résultats dans le cadre de l'inférence, générant régulièrement des vidéos dynamiques et de haute fidélité. Cependant, nos expériences montrent que les variations des hyperparamètres d'inférence affectent la qualité de la génération.
| Modèles | pas_inférés | cfg_scale | décalage horaire | nombre d'images |
|---|---|---|---|---|
| Step-Video-T2V | 30-50 | 9.0 | 13.0 | 204 |
| Step-Video-T2V-Turbo (étape d'inférence) Distillation) | 10-15 | 5.0 | 17.0 | 204 |
Modèle à télécharger
| modélisation | 🤗 Huggingface | 🤖 Modelscope |
|---|---|---|
| Step-Video-T2V | téléchargement | téléchargement |
| Step-Video-T2V-Turbo (Distillation par étapes de l'inférence) | téléchargement | téléchargement |
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Postes connexes

Pas de commentaires...