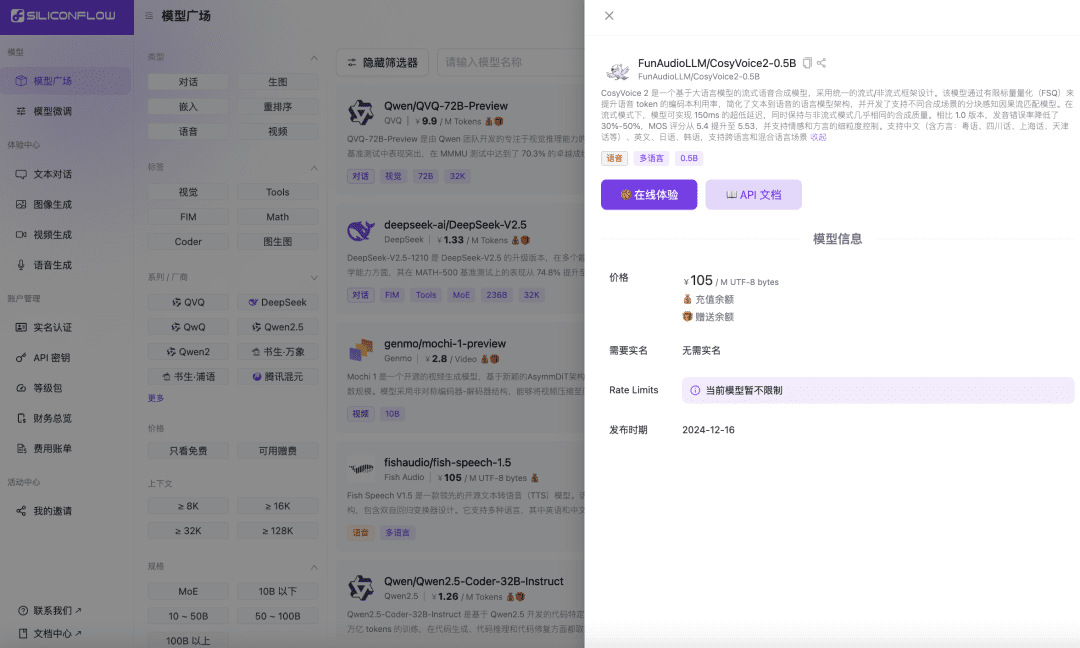
Siliconcloud lance CosyVoice2 accéléré : synthèse vocale en temps réel de 150 ms, prise en charge des langues et dialectes mixtes

Récemment, l'équipe chargée de la synthèse vocale au sein du laboratoire Ali Tongyi a officiellement publié le modèle de synthèse vocale.CosyVoice2. Le modèle prend en charge le flux bidirectionnel de texte et de parole, le multilinguisme, les langues mixtes et les dialectes, et offre des capacités de génération de parole plus précises, plus stables, plus rapides et de meilleure qualité. Aujourd'hui, Siliconcloud, le flux basé sur le silicium, est officiellement en ligne avec la version d'accélération de l'inférence CosyVoice2-0.5B (prix ¥105/ M UTF-8 octets, chaque caractère occupe 1 à 4 octets), qui comprend le temps de transmission du réseau, ce qui rend la latence de sortie du modèle aussi faible que 150 ms, apportant une expérience utilisateur plus efficace à vos applications d'IA générative. Comme d'autres modèles de synthèse linguistique sur SiliconCloud, CosyVoice2 prend en charge 8 tonalités prédéfinies, des tonalités prédéfinies par l'utilisateur ainsi que des tonalités dynamiques, et un taux de parole, un gain audio et une fréquence d'échantillonnage de sortie personnalisables.
Expérience en ligne
https://cloud.siliconflow.cn/playground/text-to-speech/17885302679
Documentation de l'API
https://docs.siliconflow.cn/api-reference/audio/create-speech
Découvrez la version accélérée par inférence de CosyVoice 2.0 de SiliconCloud.
Combiné avec les services de SiliconCloud, déjà en directModèle de reconnaissance vocale Ali SenseVoice-Small (disponible gratuitement)Grâce à l'API modèle, les développeurs peuvent mettre au point des applications d'interaction vocale de bout en bout, notamment des livres audio, des sorties audio en continu, des assistants virtuels et d'autres applications.
Caractéristiques et performances du modèle
CosyVoice2 est un modèle de synthèse vocale en continu basé sur un grand modèle de langage, conçu à l'aide d'un cadre unifié de streaming/non-streaming. Le modèle améliore l'utilisation du codebook des jetons de parole grâce à la quantification scalaire finie (FSQ), simplifie l'architecture du modèle de langage texte-parole et développe un modèle de correspondance de flux causal tenant compte des morceaux, qui prend en charge différents scénarios de synthèse. En mode streaming, le modèle permet d'obtenir une latence ultra-faible de 150 ms tout en conservant une qualité de synthèse quasiment identique à celle obtenue en mode non-streaming.
En outre, CosyVoice2 a fait des progrès significatifs dans l'intégration du modèle de base et du modèle de commande, non seulement en continuant à prendre en charge les émotions, les styles de parole et les commandes de contrôle à grain fin, mais aussi en ajoutant la capacité de gérer les commandes chinoises.
Plus précisément, la version 2.0 présente les avantages suivants par rapport à la version 1.0 de CosyVoice :
Prise en charge multilingue
- Langues prises en charge : chinois, anglais, japonais, coréen, dialectes chinois (cantonais, sichuanais, shanghaïen, tianjin, wuhan, etc.)
- Langues croisées et langues mixtes : prise en charge du clonage de la parole sans échantillon dans les scénarios de langues croisées et de changement de code.
très faible latence
- Prise en charge du streaming bidirectionnel : CosyVoice 2.0 intègre les technologies de modélisation hors ligne et en streaming.
- Synthèse rapide des premiers paquets : permet d'obtenir des délais aussi faibles que 150 ms tout en conservant une sortie audio de haute qualité.
très précis
- Amélioration de la prononciation : les erreurs de prononciation ont été réduites de 30% à 50% par rapport à CosyVoice 1.0.
- Objectif de référence : obtenir le taux d'erreur de caractère le plus bas sur l'ensemble de test difficile de l'ensemble d'évaluation Seed-TTS.
grande stabilité
- Cohérence des tons : assure une cohérence fiable des tons pour la synthèse vocale à zéro échantillon et multilingue.
- Synthèse inter-langues : améliorations significatives par rapport à la version 1.0.
la fluidité naturelle
- Amélioration rythmique et tonale : augmentation du score d'évaluation MOS de 5,4 à 5,53.
- Flexibilité des émotions et du dialecte : permet un contrôle plus fin des émotions et un ajustement de l'accent dialectal.
Évaluation du développeur
Lorsque CosyVoice 2.0 a été publié, certains développeurs l'ont expérimenté en premier. Certains d'entre eux ont déclaré qu'il prenait en charge des fonctions de contrôle ultrafines et une synthèse vocale plus réaliste et plus naturelle. 
 Cependant, certains utilisateurs ont déclaré que, bien qu'ils aient été attirés par ses excellentes performances en matière de génération vocale, le déploiement est devenu un défi majeur.
Cependant, certains utilisateurs ont déclaré que, bien qu'ils aient été attirés par ses excellentes performances en matière de génération vocale, le déploiement est devenu un défi majeur. 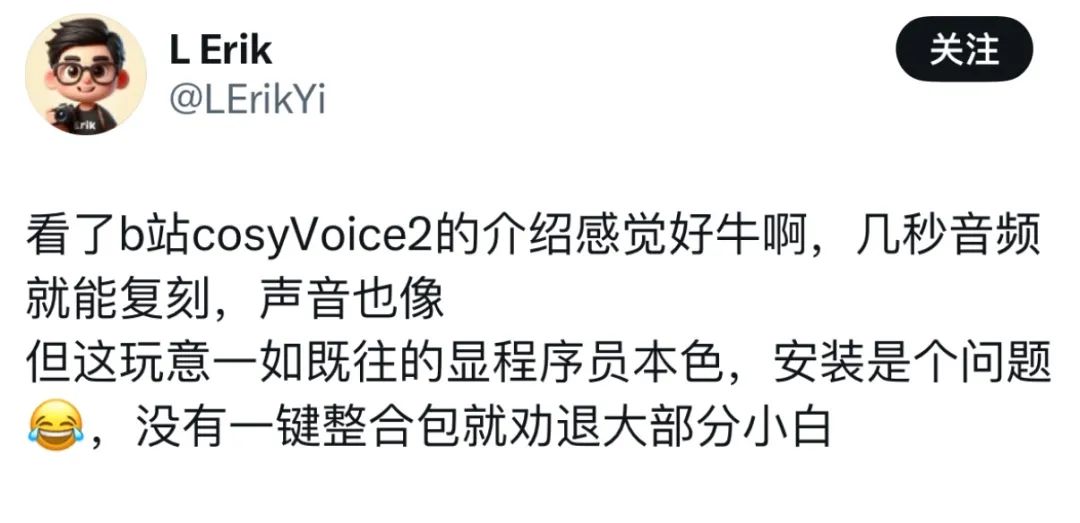 Maintenant que Siliconcloud a lancé CosyVoice 2.0, éliminant le besoin de déploiements complexes, vous pouvez simplement appeler l'API et accéder à vos propres applications.
Maintenant que Siliconcloud a lancé CosyVoice 2.0, éliminant le besoin de déploiements complexes, vous pouvez simplement appeler l'API et accéder à vos propres applications.
Token Factory SiliconCloud Qwen 2.5 (7B) et plus de 20 autres modèles gratuits !
En tant que plateforme unique de services en nuage pour les grands modèles, SiliconCloud s'engage à fournir aux développeurs des API de modèles extrêmement réactives, abordables, complètes et fluides. Outre CosyVoice2, SiliconCloud a déjà mis de côté une variété d'API de modèles, notamment QVQ-72B-Preview, DeepSeek-VL2, DeepSeek- V2.5-1210, mochi-1-preview, Llama-3.3-70B-Instruct, HunyuanVideo, fish-speech-1.5, QwQ-32B-Preview, Qwen2.5-Coder-32B-Instruct, InternVL2 Qwen2.5-7B/14B/32B/72B, FLUX.1, InternLM2.5-20B-Chat, BCE, BGE, SenseVoice-Small, GLM-4-9B-Chat, et des dizaines de grands modèles linguistiques, de modèles de génération d'images/vidéos, de modèles vocaux, de modèles de codes/mathématiques, et de modèles vectoriels et de réordonnancement. modèles vectoriels et de réorganisation. 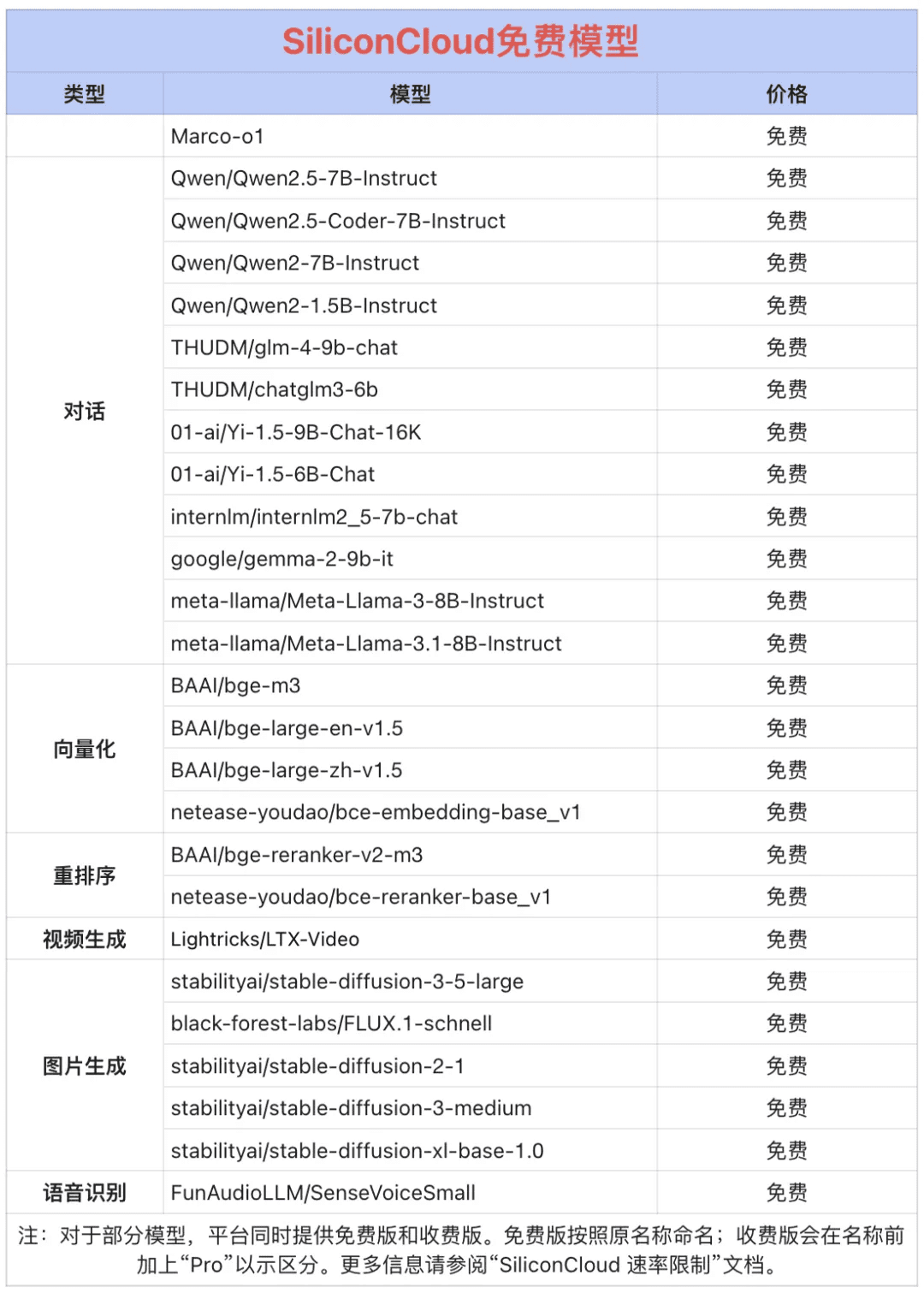 Parmi eux, Qwen2.5 (7B), Llama3.1 (8B) et d'autres API de plus de 20 grands modèles sont gratuits, de sorte que les développeurs et les gestionnaires de produits n'ont pas à s'inquiéter du coût arithmétique de la phase de recherche et de développement et de la promotion à grande échelle, et réalisent la "liberté des jetons".
Parmi eux, Qwen2.5 (7B), Llama3.1 (8B) et d'autres API de plus de 20 grands modèles sont gratuits, de sorte que les développeurs et les gestionnaires de produits n'ont pas à s'inquiéter du coût arithmétique de la phase de recherche et de développement et de la promotion à grande échelle, et réalisent la "liberté des jetons".
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes

Pas de commentaires...