Le premier grand modèle de raisonnement de l'industrie financière Regulus-FinX1 open source ! Du Xiaoman production lourde, axée sur l'analyse financière complexe et la prise de décision
Du Xiaoman met à disposition le premier grand modèle de raisonnement de l'industrie financière au monde - Regulus-FinX1 !
Ce modèle est le premier macromodèle d'inférence de type GPT-O1 dans le domaine financier."Chaîne de pensée + récompenses du processus + apprentissage par renforcement".Le paradigme de formation améliore considérablement le raisonnement logique et peut démontrer le processus de pensée complet qui n'est pas divulgué par le modèle O1, ce qui permet d'approfondir la prise de décision financière. Cibles de Regulus-FinX1Tâches d'analyse, de prise de décision et de traitement des données dans des scénarios financiersUne optimisation en profondeur a été réalisée.
Xuan Yuan-FinX1 est développé par Du Xiaoman AI-Lab, et cette version est une version preview, qui est maintenant ouverte à la communauté open source.Téléchargement gratuit. Les versions optimisées ultérieures continueront également à être ouvertes au téléchargement et à l'utilisation.
Adresse Github : https://github.com/Duxiaoman-DI/XuanYuan
Résultats de l'étalonnage
Le Regulus-FinX1 de première génération a démontré d'excellentes performances sur FinanceIQ, un benchmark financier. Sur leCPA, qualification bancaire10 types de qualifications financières, telles que les qualifications en matière de valeurs mobilières, etc.Dans la catégorie des actuaires, les scores de tous les grands modèles précédents sont généralement faibles, tandis que XuanYuan-FinX1 a considérablement amélioré son score de 37,5 à 65,7, ce qui montre qu'il peut être utilisé pour le raisonnement logique financier et le raisonnement mathématique, et qu'il peut être utilisé pour le raisonnement logique financier et le raisonnement mathématique. Dans la catégorie Actuaire en particulier, tous les grands modèles précédents ont généralement obtenu un score faible, tandis que XuanYuan-FinX1 a amélioré son score de 37,5 à 65,7, ce qui démontre de manière significative son fort avantage en matière de raisonnement logique financier et de calcul mathématique. 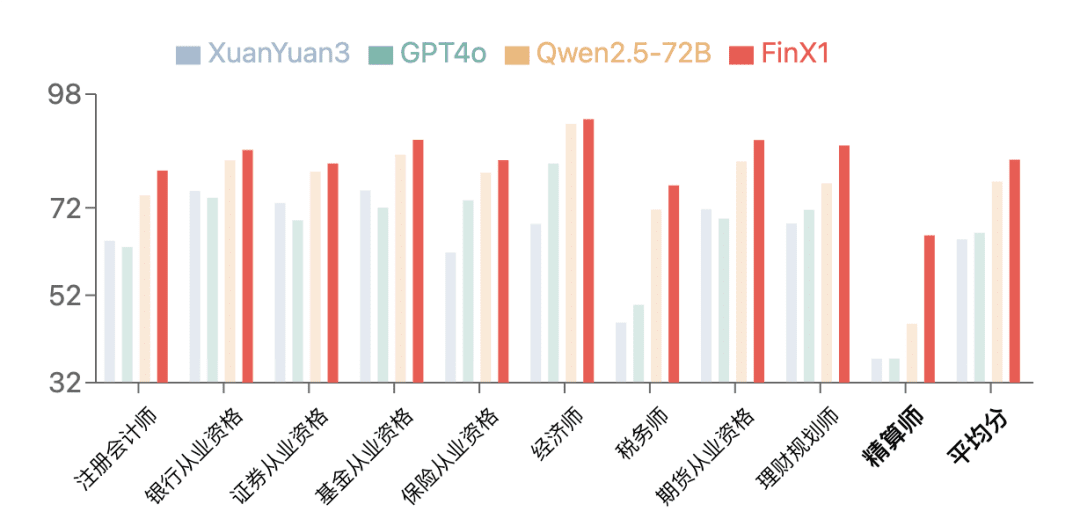
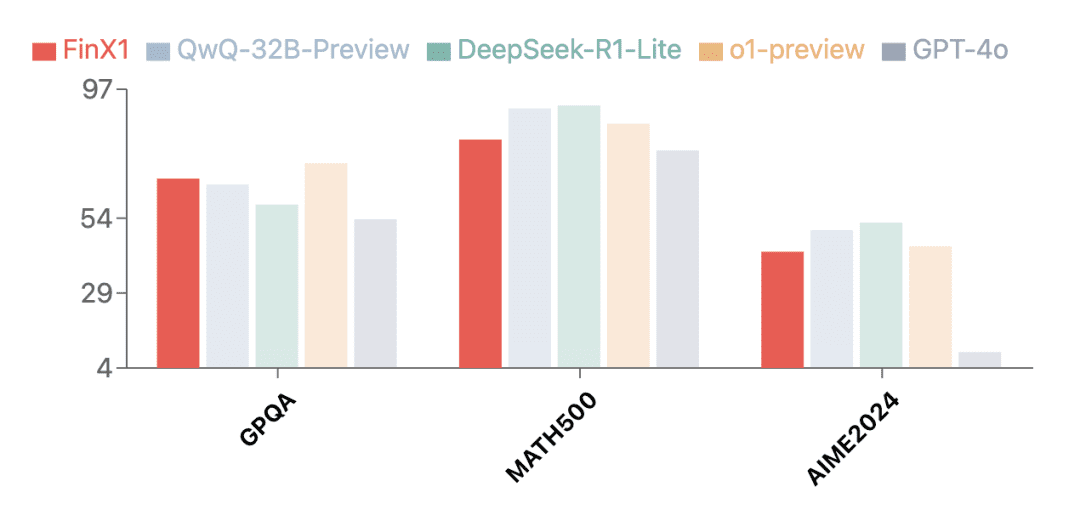
Outre le domaine financier, la première génération de Regulus-FinX1 a également démontré d'excellentes capacités d'utilisation générale. Les résultats des tests effectués sur plusieurs ensembles d'évaluation faisant autorité montrent que Regulus-FinX1 n'est pas seulement dans le peloton de tête de l'industrie financière.GPQA (raisonnement scientifique),MATH-500 (Mathématiques)répondre en chantantAIME2024 (Concours de mathématiques)Il a également dépassé le GPT-4o, se classant au premier échelon avec O1 et la nouvelle version d'inférence du Big Model en Chine, ce qui prouve sa forte capacité d'inférence de base.
Casser la "boîte noire" : présenter la chaîne complète de la pensée
L'une des caractéristiques de Regulus FinX1 est qu'il peut présenter l'ensemble du processus de réflexion avant de générer une réponse, construisant ainsi une chaîne de pensée totalement transparente, du démontage du problème à la conclusion finale. Grâce à ce mécanisme, Regulus FinX1 améliore non seulement l'interprétabilité du raisonnement, mais résout également le problème de la "boîte noire" des grands modèles traditionnels, offrant ainsi aux institutions financières un outil d'aide à la décision plus crédible.

Regulus Exemple de génération d'une chaîne de pensée pour FinX1
Accent mis sur la complexité financière et la prise de décision analytique
Lorsque le GPT-O1 d'OpenAI a attiré l'attention de l'industrie grâce à son "pouvoir de réflexion" supérieur, une proposition clé a émergé :Comment cette capacité de raisonnement approfondi peut-elle créer une valeur substantielle dans les scénarios professionnels financiers ?Du Xiaoman Regulus FinX1 apporte des réponses innovantes -Pour la première fois, la capacité de raisonnement profond des grands modèles a été injectée dans le domaine financier, ce qui a permis de promouvoir l'application des grands modèles au secteur financier.Permet d'approfondir les scénarios génériques jusqu'aux niveaux fondamentaux de l'entreprise, tels que les décisions de contrôle des risques.
Dans la vague de transformation de l'intelligence numérique dans le secteur financier, la"Capacités de prise de décision et de contrôle des risques", "capacités de recherche et d'analyse" et "capacités de renseignement sur les données".constituent les dimensions clés de l'innovation commerciale et de l'amélioration de la valeur. Ces capacités apportent une croissance soutenue de la valeur à l'institution grâce à une identification et un contrôle précis des risques, à des études de marché approfondies et à la découverte de valeur, ainsi qu'à une modélisation et une analyse efficaces des données, respectivement.
Regulus FinX1 intègre profondément les capacités de raisonnement profond et l'expertise financière grâce à un paradigme de formation innovant, permettant à ces trois capacités d'être pleinement exploitées dans des scénarios spécifiques et apportant de nouvelles solutions intelligentes à l'industrie financière.

01 Capacité de prise de décision et de contrôle des risques
La capacité de prise de décision et de contrôle des risques est la ligne de vie des institutions financières, qui est liée à leur bon fonctionnement et à leur développement durable. Dans les tâches essentielles d'identification et de prévision des risques, de construction de modèles de contrôle des risques et de formulation de stratégies, Regulus FinX1 peut analyser systématiquement les corrélations et les chemins de conduction entre les facteurs de risque grâce à sa puissante capacité de raisonnement et à son mécanisme complet de chaîne de l'esprit, fournissant aux institutions des informations complètes et approfondies sur les risques. Par exemple, sur la base de l'eau bancaire téléchargée par l'autorisation de l'utilisateur, Regulus FinX1 est capable d'identifier avec précision les signaux de risque tels que la consommation de loterie à haute fréquence, la consommation de jeux, etc. à partir de milliers d'enregistrements de transactions, et d'évaluer scientifiquement la capacité de remboursement de l'utilisateur et le risque de crédit en conjonction avec le niveau de revenu et le fardeau de la dette.

Regulus FinX1 a répondu au clip
02 Capacité de recherche et d'analyse
La capacité de recherche et d'analyse est le support de base de la prise de décision financière, qui améliore la science de l'allocation du capital grâce à des informations approfondies au niveau macroéconomique, sectoriel et de l'entreprise. Regulus FinX1 est capable de mener des analyses multidimensionnelles des données macroéconomiques, du sentiment du marché, de l'impact des politiques, etc. et de démanteler progressivement des questions complexes grâce à une chaîne logique claire. Par exemple, lorsqu'il prédit la baisse des taux d'intérêt de la Fed en 2025 sur la base de données économiques, le modèle explore un large éventail de possibilités en analysant une variété de facteurs économiques et en se basant sur différents scénarios hypothétiques, démontrant de manière complète et objective la perspective d'une baisse des taux d'intérêt de la Fed en 2025, ce qui est actuellement conforme aux opinions analytiques prédictives d'un certain nombre d'institutions. 
03 Capacités d'intelligence des données
La capacité d'intelligence des données est un support important pour les institutions financières afin d'obtenir une prise de décision précise, dont le cœur est une capacité de traitement des données efficace et une capacité d'analyse approfondie. Regulus FinX1 peut aider les institutions financières à explorer rapidement la logique commerciale et la valeur qui se cachent derrière les données. Par exemple, si les données financières trimestrielles d'une entreprise sont entrées dans Regulus FinX1, le modèle peut extraire avec précision les informations essentielles et afficher visuellement la qualité des actifs, la liquidité et la dynamique de l'entreprise. En analysant des indicateurs clés tels que la "pression sur les liquidités" et la "dynamique d'expansion des actifs", Regulus FinX1 ajoute des explications qualitatives basées sur des comparaisons quantitatives, révélant les risques potentiels et les opportunités de croissance qui se cachent derrière les données financières et aidant les entreprises à optimiser leur prise de décision. 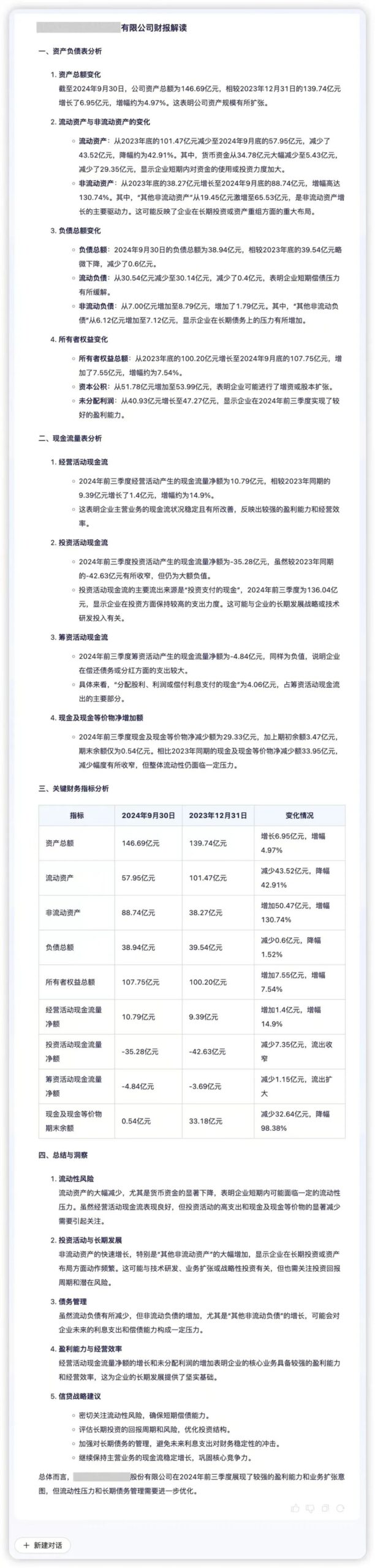
Mise en œuvre technique de Regulus-FinX1
Afin d'obtenir de grands modèles dotés de capacités de raisonnement de type O1, en particulier dans des scénarios d'analyse décisionnelle complexes dans le domaine financier, nous proposons une solution technique comportant trois étapes clés après une exploration et une validation approfondies :Vers un modèle stable de génération de chaînes de pensée, un modèle à double récompense pour l'amélioration des décisions financières, et un réglage fin de l'apprentissage par renforcement sous la double direction du PRM et de l'ORM.
01 Construction initiale d'un modèle génératif stable de la chaîne de pensée
Pour les scénarios d'analyse décisionnelle complexes dans le domaine financier, nous avons construit un modèle de base doté d'une capacité stable de génération de chaînes de pensée. La première étape est la synthèse des données d'une COT/réponse de haute qualité, qui génère d'abord le processus de réflexion basé sur la question, puis la réponse finale basée sur la question et le processus de réflexion. Grâce à cette stratégie, le modèle peut se concentrer sur chaque étape de la tâche et générer des chaînes de raisonnement et des réponses plus cohérentes.
Pour différents domaines (par exemple, les mathématiques, le raisonnement logique, l'analyse financière, etc.), nous avons conçu des méthodes spéciales de synthèse des données, par exemple, pour les tâches d'analyse financière, nous avons conçu une méthode de synthèse itérative pour garantir l'exhaustivité du processus analytique, suivie d'une formation basée sur le modèle XuanYuan 3.0 utilisant l'affinement des commandes, et adoptant un format de sortie unifié thinking process answer (nous exposerons également les données de texte long à grain grossier cette fois-ci pour améliorer le modèle). En même temps, nous nous concentrons sur la construction d'un plus grand nombre de données de texte long afin d'améliorer la capacité du modèle à traiter des contextes longs, de manière à ce qu'il puisse "générer un processus de réflexion détaillé avant de générer une réponse". Cela permet de poser des bases solides pour la formation supervisée par processus et l'optimisation de l'apprentissage par renforcement.
02 Un modèle de double récompense pour l'amélioration des décisions financières
Afin d'évaluer la performance du modèle dans des scénarios de prise de décision financière, nous avons conçu l'outil d'évaluation de la performance du modèle.Deux modèles de récompense complémentaires, l'un axé sur les résultats (ORM) et l'autre sur les processus (PRM). Parmi eux, l'ORM poursuit la solution technique du XuanYuan 3.0, qui est formé par l'apprentissage par contraste et l'apprentissage par renforcement inverse ; le PRM est notre innovation pour le processus de raisonnement, qui se concentre sur la résolution de la difficulté d'évaluer les problèmes financiers ouverts (par exemple, l'analyse du marché, les décisions d'investissement, etc.)
Pour la construction des données d'entraînement de la MPR, nous adoptons différentes stratégies pour différents scénarios : pour les questions avec des réponses définies telles que les évaluations de risque, nous utilisons une méthode de validation inverse basée sur le MCTS ; pour les questions d'analyse financière ouvertes, nous les annotons en termes de dimensions telles que l'exactitude, la nécessité et la logique par le biais de plusieurs grands modèles, et nous résolvons le problème de déséquilibre des données par le biais du sous-échantillonnage et de l'apprentissage actif. Pendant la formation, le PRM utilise un réglage fin supervisé pour optimiser le modèle en notant chaque étape de réflexion.03 Réglage fin par apprentissage par renforcement avec double guidage du PRM et de l'ORMDans la phase d'apprentissage par renforcement, nous utilisons l'algorithme PPO pour l'optimisation du modèle, qui utilise le PRM et l'ORM en tant que signaux de récompense. Pour le processus de réflexion entre et , le MRP est utilisé pour noter chaque étape de la réflexion, de sorte que les erreurs dans le cheminement de la réflexion puissent être détectées et corrigées en temps utile ; pour la partie réponse, différentes stratégies d'évaluation sont utilisées pour différents types de questions : la correspondance des règles est utilisée pour calculer les récompenses pour les questions financières avec une réponse définie (par exemple, l'évaluation du niveau de risque), et la correspondance des règles est utilisée pour calculer les récompenses pour les questions ouvertes ( les analyses de marché) sont notées de manière holistique à l'aide de la méthode ORM. Des techniques telles que les coefficients KL dynamiques et la normalisation de la fonction de dominance sont simultanément introduites pour stabiliser le processus de formation. Cette méthodeMécanismes de formation basés sur la double récompensequi permet non seulement de surmonter les limites d'un modèle à récompense unique, mais aussi d'améliorer considérablement la capacité de raisonnement du modèle dans les scénarios de prise de décision financière grâce à une formation stable d'apprentissage par renforcement.
Comme on peut le voir, la clé de l'itinéraire ci-dessus est la construction des données de la chaîne de pensée et l'évaluation des modèles de récompense pour les problèmes ouverts de l'analyse financière qui sont différents des mathématiques ou de la logique, et nous sommes encore en train d'optimiser et d'itérer, et nous continuerons à explorer des itinéraires techniques plus efficaces.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Postes connexes



Pas de commentaires...