Déploiement rapide du RAG 3-Pack pour Dify avec GPUStack
GPUStack Il s'agit d'une plateforme open source de big model-as-a-service qui peut intégrer et utiliser efficacement diverses ressources GPU/NPU hétérogènes telles que Nvidia, Apple Metal, Huawei Rise et Moore Threads pour fournir un déploiement privé local de solutions de big model.
GPUStack peut prendre en charge RAG Les trois modèles clés nécessaires au système : le modèle de dialogue Chat (un grand modèle linguistique), le modèle d'incorporation de texte Embedding et le modèle de réorganisation Rerank sont disponibles dans une suite de trois pièces, et c'est une opération très simple et infaillible que de déployer les modèles privés locaux requis par le système RAG.
Voici comment installer GPUStack et Dify à l'aide de la commande Dify pour s'interfacer avec le modèle de dialogue, le modèle d'intégration et le modèle de reclassement déployés par GPUStack.
Installation de GPUStack
Installez-le en ligne sur Linux ou macOS avec la commande suivante, un mot de passe sudo est requis pendant le processus d'installation : curl -sfL https://get.gpustack.ai | sh -
Si vous ne pouvez pas vous connecter à GitHub pour télécharger des binaires, utilisez les commandes suivantes pour les installer à l'aide de la commande --tools-download-base-url Le paramètre spécifie le téléchargement à partir du stockage d'objets dans le nuage de Tencent :curl -sfL https://get.gpustack.ai | sh - --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
Exécutez Powershell en tant qu'administrateur sous Windows et installez-le en ligne à l'aide de la commande suivante :Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content
Si vous ne pouvez pas vous connecter à GitHub pour télécharger des binaires, utilisez les commandes suivantes pour les installer à l'aide de la commande --tools-download-base-url Le paramètre spécifie le téléchargement à partir du stockage d'objets dans le nuage de Tencent :Invoke-Expression "& { $((Invoke-WebRequest -Uri 'https://get.gpustack.ai' -UseBasicParsing).Content) } --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
Lorsque vous voyez la sortie suivante, le GPUStack a été déployé et démarré avec succès :
[INFO] Install complete. GPUStack UI is available at http://localhost. Default username is 'admin'. To get the default password, run 'cat /var/lib/gpustack/initial_admin_password'. CLI "gpustack" is available from the command line. (You may need to open a new terminal or re-login for the PATH changes to take effect.)
Ensuite, suivez les instructions de la sortie du script pour obtenir le mot de passe initial de connexion à GPUStack et exécutez la commande suivante :
sur Linux ou macOS :cat /var/lib/gpustack/initial_admin_password
Sous Windows :Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustackinitial_admin_password") -Raw
Accédez à l'interface utilisateur de GPUStack dans un navigateur avec le nom d'utilisateur admin et le mot de passe comme le mot de passe initial obtenu ci-dessus.
Après avoir réinitialisé le mot de passe, entrez GPUStack :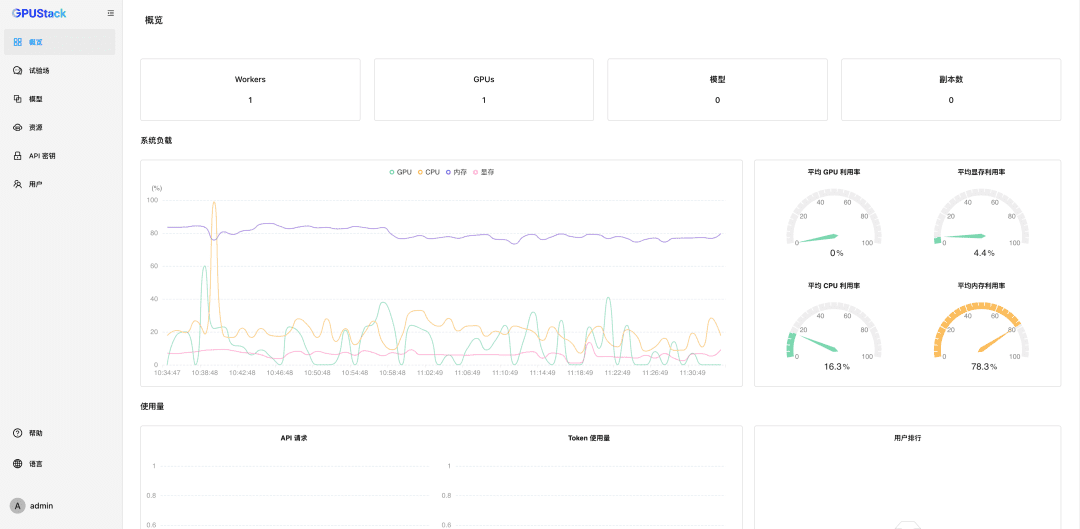
Nanomanagement des ressources GPU
GPUStack prend en charge les ressources GPU pour les appareils Linux, Windows et macOS, et gère ces ressources GPU en suivant les étapes suivantes.
Les autres nœuds doivent être authentifiés Jeton Rejoignez le cluster GPUStack et exécutez la commande suivante sur le nœud du serveur GPUStack pour obtenir un Token :
sur Linux ou macOS :cat /var/lib/gpustack/token
Sous Windows :Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustacktoken") -Raw
Une fois que vous avez le Token, exécutez la commande suivante sur les autres nœuds pour ajouter le Worker au GPUStack, et nanomanager les GPUs sur ces nœuds (remplacez http://YOUR_IP_ADDRESS par votre adresse d'accès au GPUStack et YOUR_TOKEN par le Token d'authentification utilisé pour ajouter le Worker) :
sur Linux ou macOS :curl -sfL https://get.gpustack.ai | sh - --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
Sous Windows :Invoke-Expression "& { $((Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content) } --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
Avec les étapes ci-dessus, nous avons créé un environnement GPUStack et géré plusieurs nœuds GPU, qui peuvent ensuite être utilisés pour déployer de grands modèles privés.
Déploiement de macromodèles privés
GPUStack permet de déployer des modèles à partir de HuggingFace, de la bibliothèque Ollama, de ModelScope et de dépôts de modèles privés ; ModelScope est recommandé pour les réseaux nationaux.
Soutien à GPUStack vLLM et llama-box, vLLM est optimisé pour l'inférence de production et est mieux adapté aux besoins de production en termes de concurrence et de performance, mais vLLM n'est pris en charge que sous Linux. llama-box est un moteur d'inférence flexible, compatible avec plusieurs plates-formes, qui est llama.cpp Il prend en charge les systèmes Linux, Windows et macOS, et supporte non seulement les environnements GPU, mais aussi les environnements CPU pour l'exécution de grands modèles, ce qui le rend plus adapté aux scénarios qui nécessitent une compatibilité multiplateforme.
GPUStack sélectionne automatiquement le backend d'inférence approprié en fonction du type de fichier de modèle lors du déploiement du modèle. GPUStack utilise llama-box comme backend pour exécuter le service de modèle si le modèle est au format GGUF, et vLLM comme backend pour exécuter le service de modèle s'il n'est pas au format GGUF.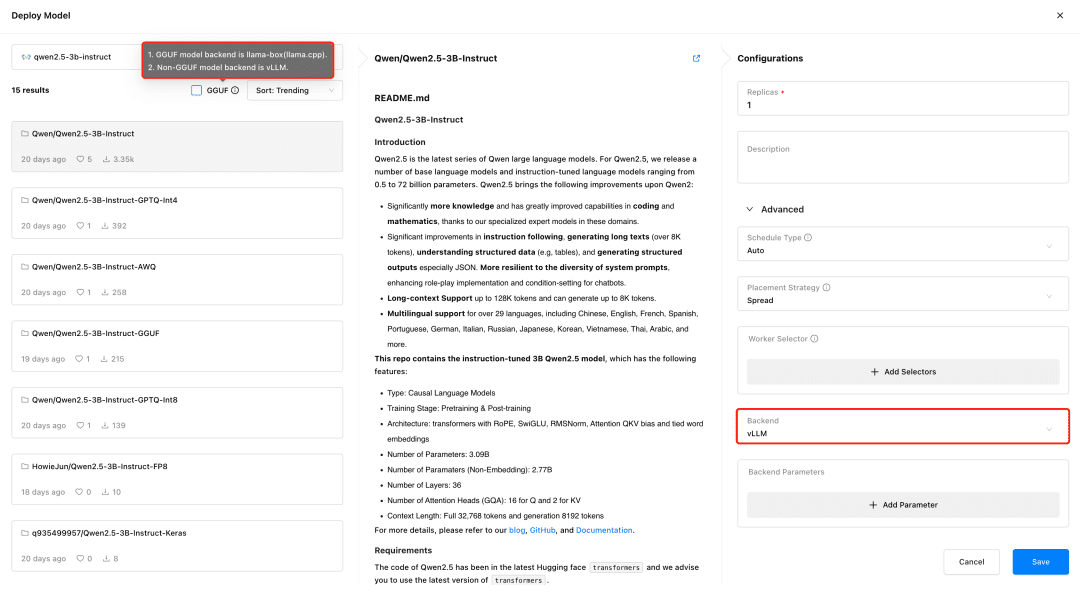
Déployez le modèle de dialogue textuel, le modèle d'incorporation de texte et le modèle Reranker requis pour l'ancrage de Dify, et n'oubliez pas de vérifier le format GGUF lors du déploiement :
- Qwen/Qwen2.5-7B-Instruct-GGUF
- gpustack/bge-m3-GGUF
- gpustack/bge-reranker-v2-m3-GGUF
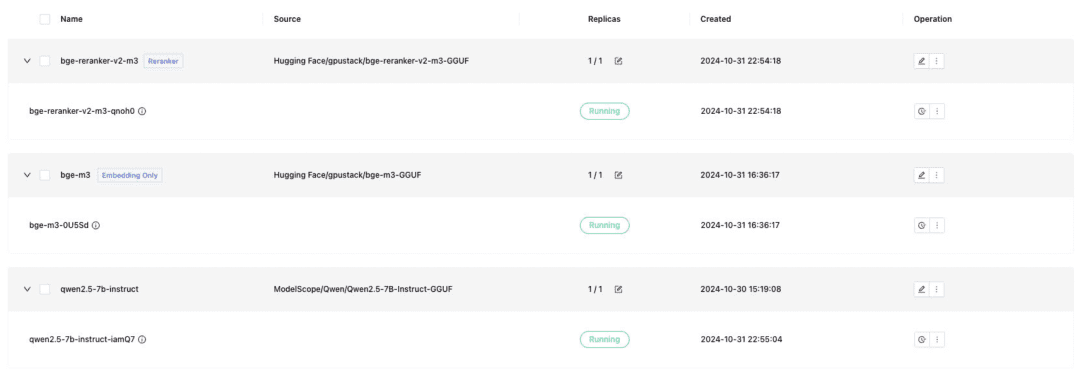
GPUStack prend également en charge les modèles multimodaux VLM, dont le déploiement nécessite l'utilisation d'un backend d'inférence vLLM :
Qwen2-VL-2B-Instruct 

Une fois le modèle déployé, un système RAG ou une autre application d'IA générative peut s'interfacer avec le modèle déployé par GPUStack via l'API compatible OpenAI / Jina fournie par GPUStack, suivi par Dify pour s'interfacer avec le modèle déployé par GPUStack.
Modèles de Dify Integration GPUStack
Installer Dify
Pour exécuter Dify à l'aide de Docker, vous devez préparer un environnement Docker et veiller à éviter tout conflit entre Dify et le port 80 de GPUStack, à utiliser d'autres hôtes ou à modifier le port. Exécutez la commande suivante pour installer Dify :git clone -b 0.10.1 https://github.com/langgenius/dify.gitVisitez l'interface utilisateur de Dify à l'adresse http://localhost pour initialiser le compte administrateur et vous connecter.
cd dify/docker/
cp .env.example .env
docker compose up -d
Pour intégrer un modèle GPUStack, ajoutez d'abord un modèle de dialogue Chat. Dans le coin supérieur droit de Dify, sélectionnez "Settings - Model Providers", trouvez le type GPUStack dans la liste et sélectionnez Add Model :
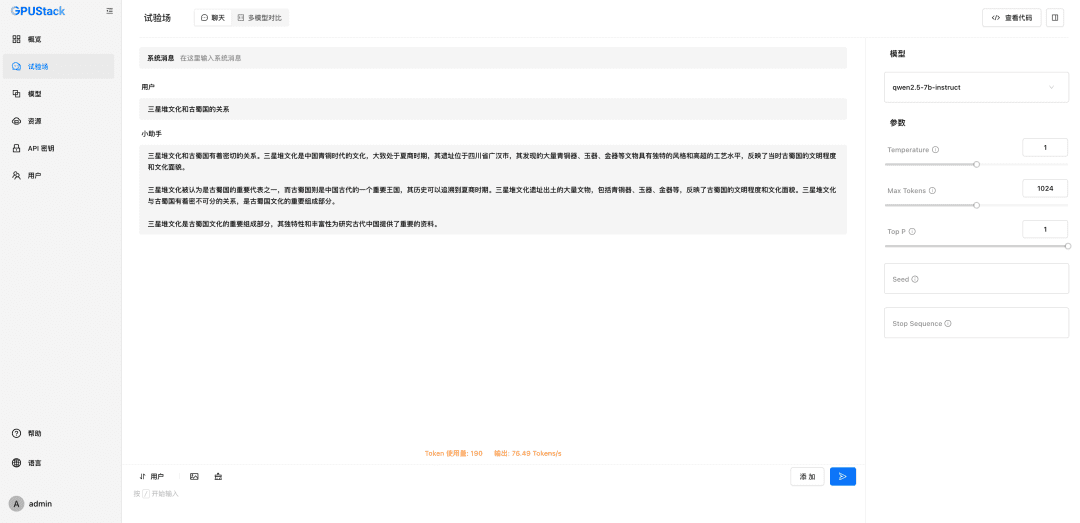
Remplir le nom du modèle LLM déployé sur le GPUStack (par exemple, qwen2.5-7b-instruct), l'adresse d'accès du GPUStack (par exemple, http://192.168.0.111) et la clé API générée, ainsi que les longueurs de contexte des paramètres du modèle 8192 et max. jetons 2048 :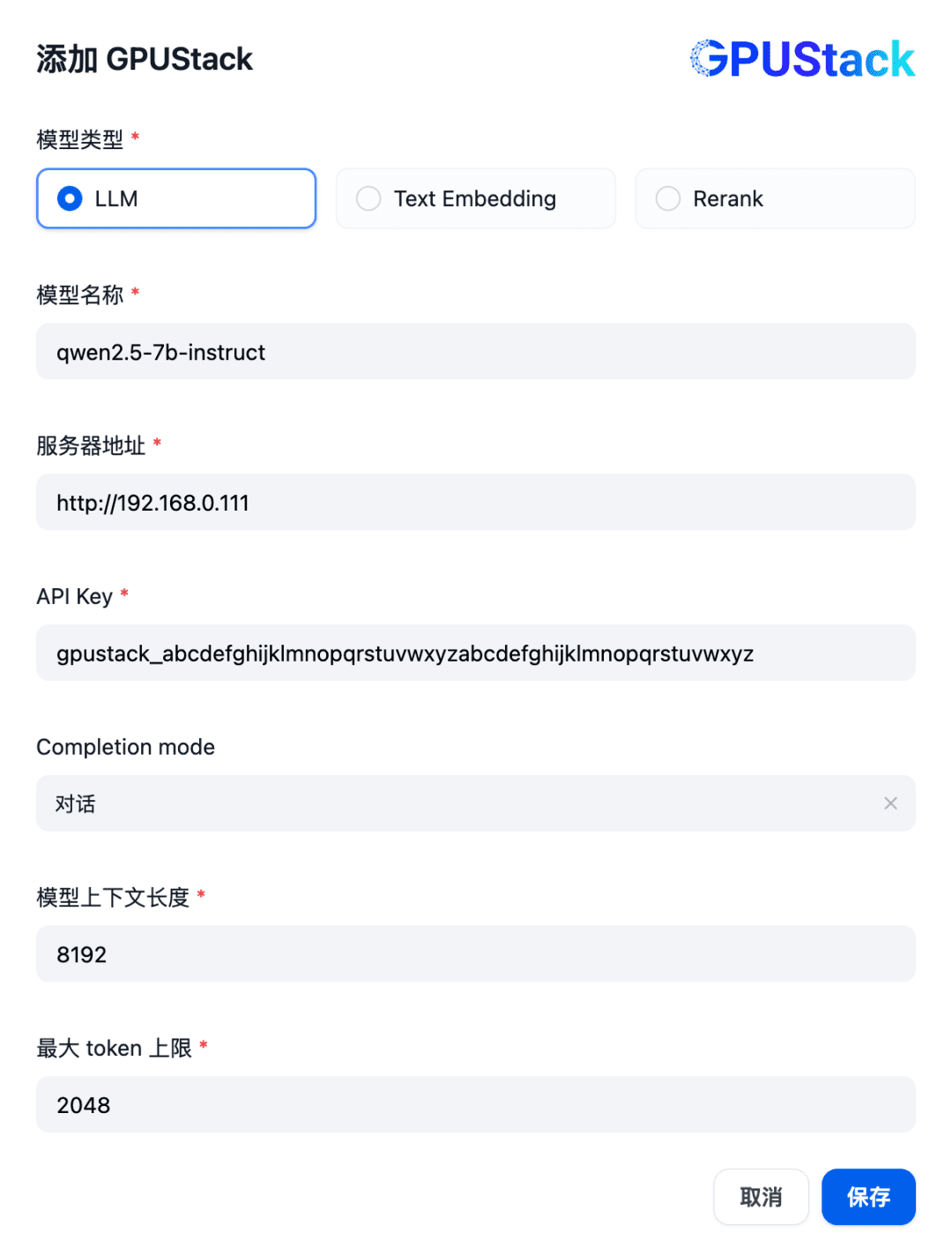
Ensuite, ajoutez le modèle Embedding, en haut du Model Provider, sélectionnez le type GPUStack et sélectionnez Add Model :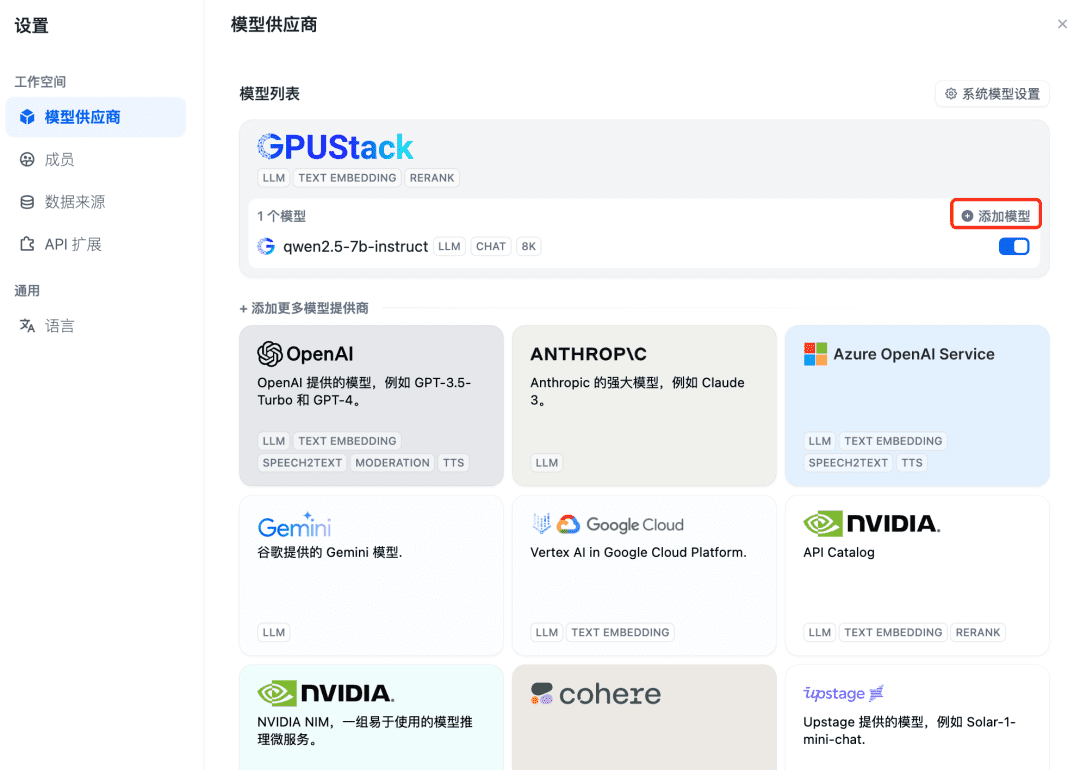
Ajouter un modèle de type Text Embedding, en renseignant le nom du modèle Embedding déployé sur la GPUStack (par exemple, bge-m3), l'adresse d'accès à la GPUStack (par exemple, http://192.168.0.111) et la clé API générée, ainsi qu'une longueur de contexte de 8192 pour les paramètres du modèle :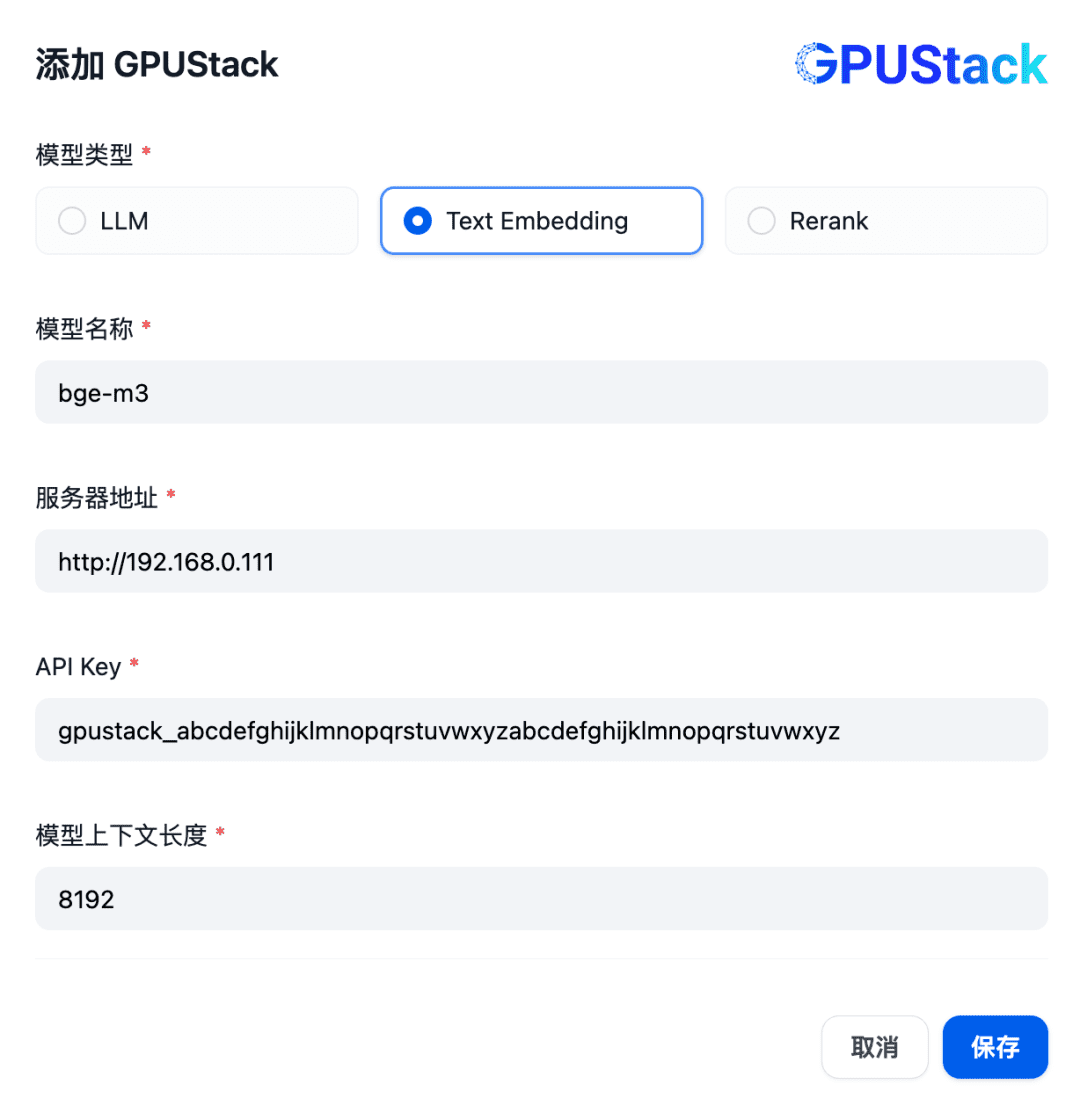
Ensuite, pour ajouter un modèle de Rerank, sélectionnez le type de GPUStack, sélectionnez Add Model, ajoutez un modèle de type Rerank, renseignez le nom du modèle de Rerank déployé sur le GPUStack (par exemple, bge-reranker-v2-m3), l'adresse d'accès du GPUStack (par exemple, http://192.168. 0.111) et la clé API générée, ainsi que la longueur de contexte 8192 pour les paramètres du modèle :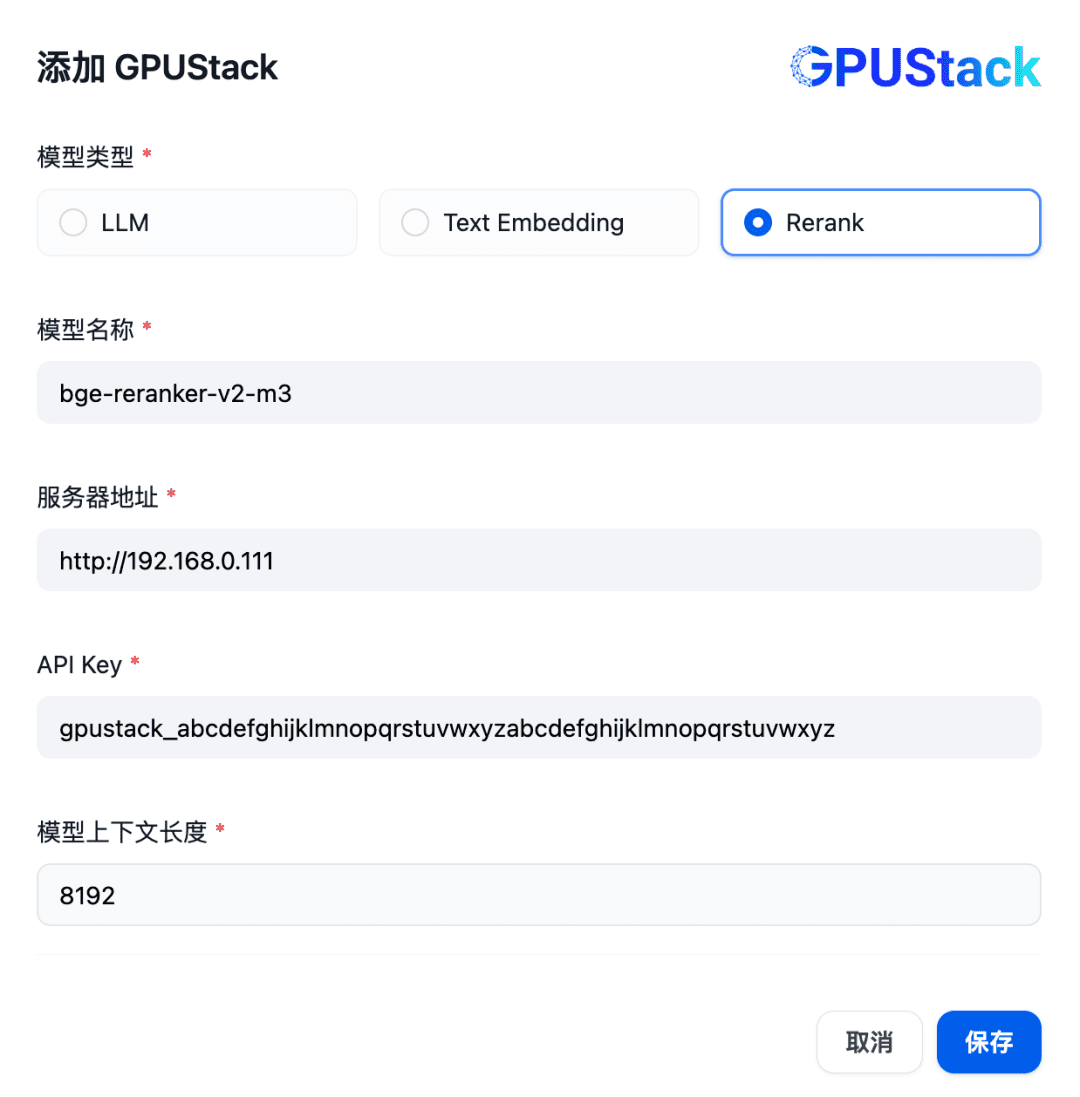
Actualisez après l'ajout, puis confirmez au fournisseur de modèles que les modèles du système sont configurés pour les trois modèles ajoutés ci-dessus :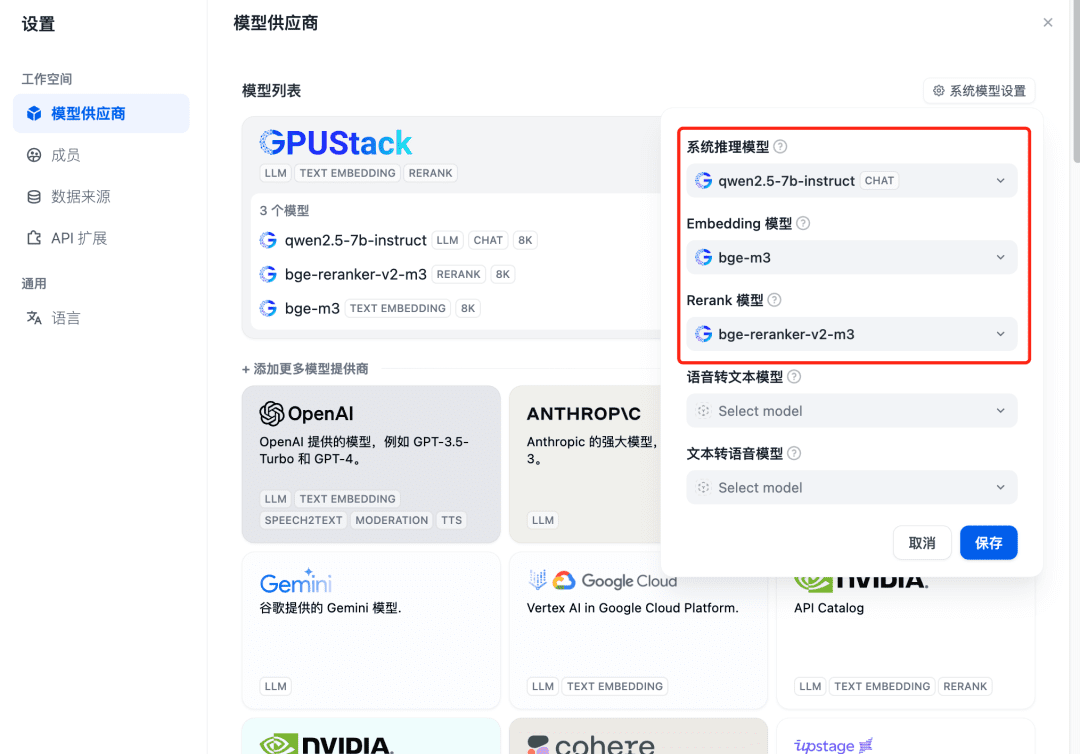
Utilisation de modèles dans le système RAG Sélectionnez la base de connaissances de Dfiy, sélectionnez Créer une base de connaissances, importez un fichier texte, confirmez l'option Modèle d'intégration, utilisez la recherche hybride recommandée pour les paramètres de recherche et activez le modèle Rerank :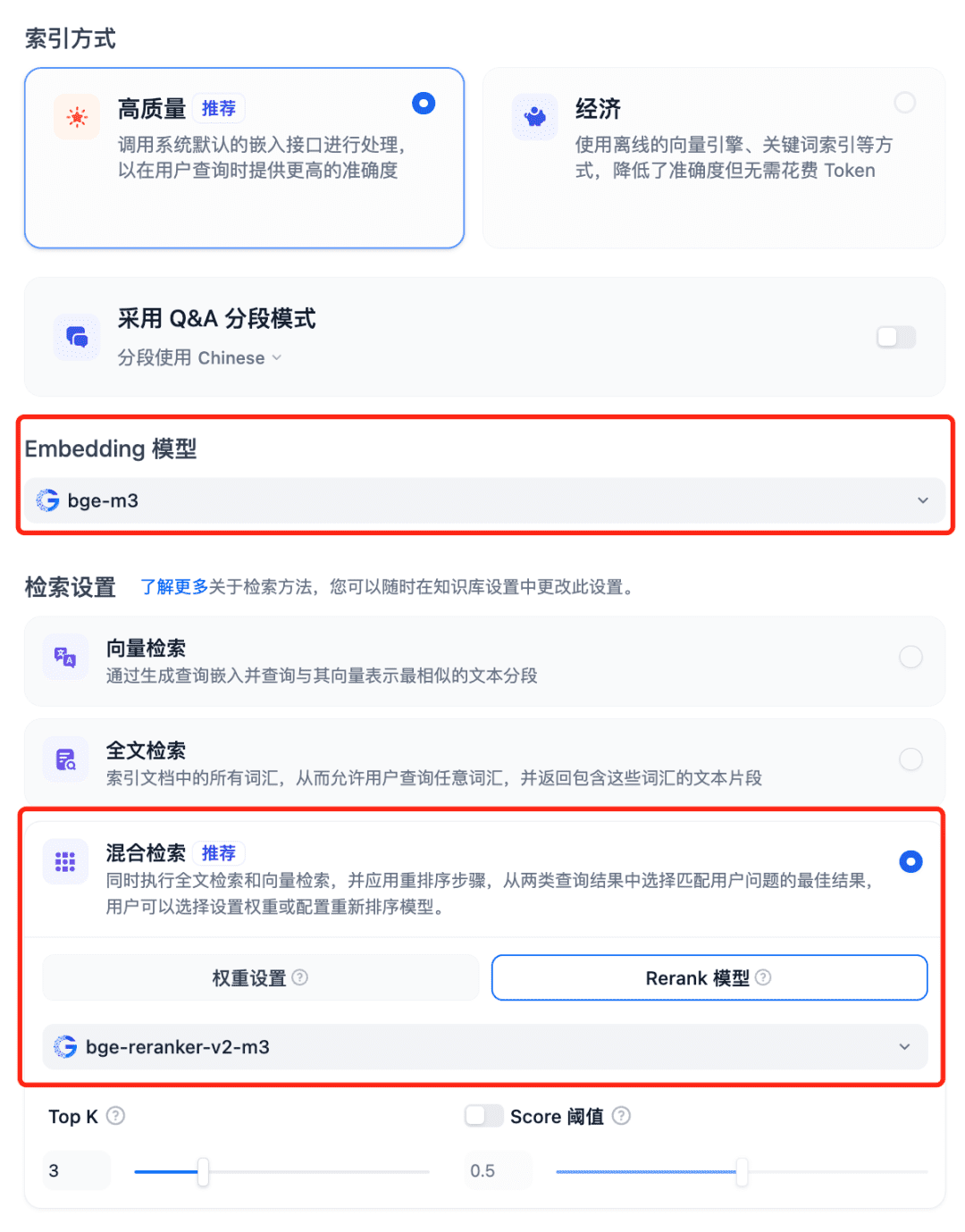
Enregistrez et commencez le processus de vectorisation du document. Lorsque la vectorisation est terminée, la base de connaissances est prête à être utilisée.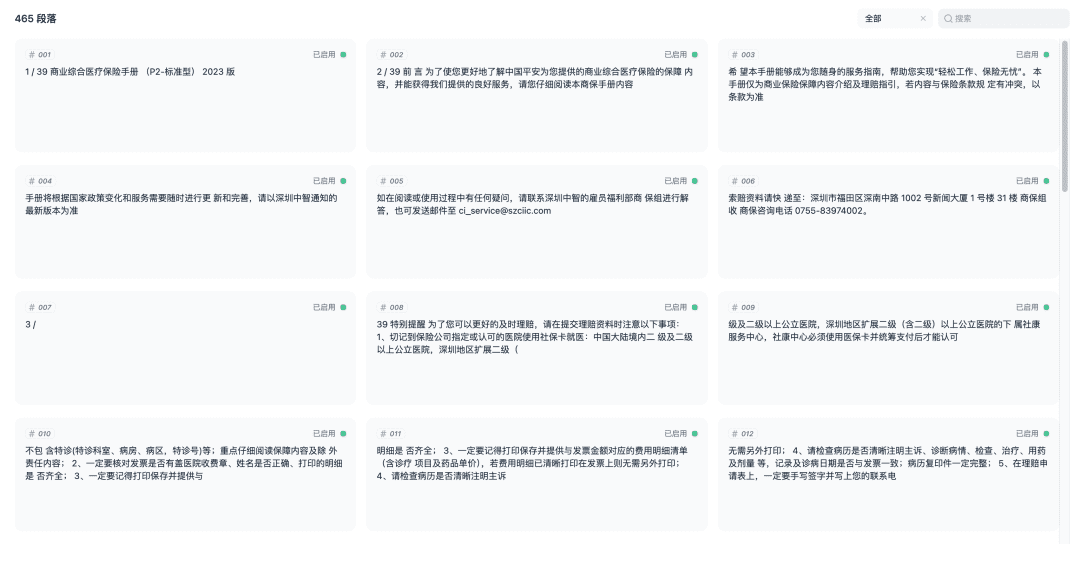
Le test de rappel peut être utilisé pour confirmer l'efficacité du rappel de la base de connaissances, et le modèle Rerank sera affiné pour rappeler des documents plus pertinents afin d'obtenir de meilleurs résultats en matière de rappel :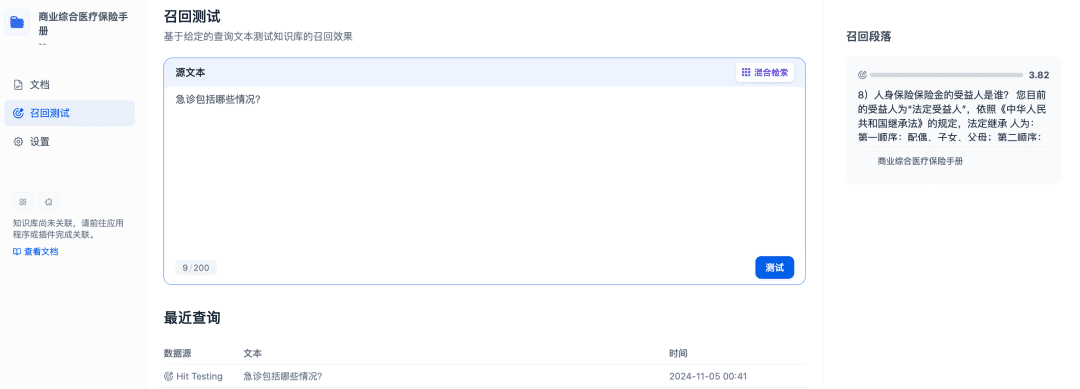
Créez ensuite une application d'assistant de chat dans l'espace de discussion :
La base de connaissances pertinente est ajoutée au contexte à utiliser, et c'est à ce moment-là que le modèle de dialogue en ligne, le modèle d'intégration et le modèle de reclassement travailleront ensemble pour soutenir l'application RAG, le modèle d'intégration étant responsable de la vectorisation, le modèle de reclassement étant responsable de l'affinement du contenu du rappel, et le modèle de dialogue en ligne étant responsable de la réponse basée sur le contenu de la question et le contexte du rappel :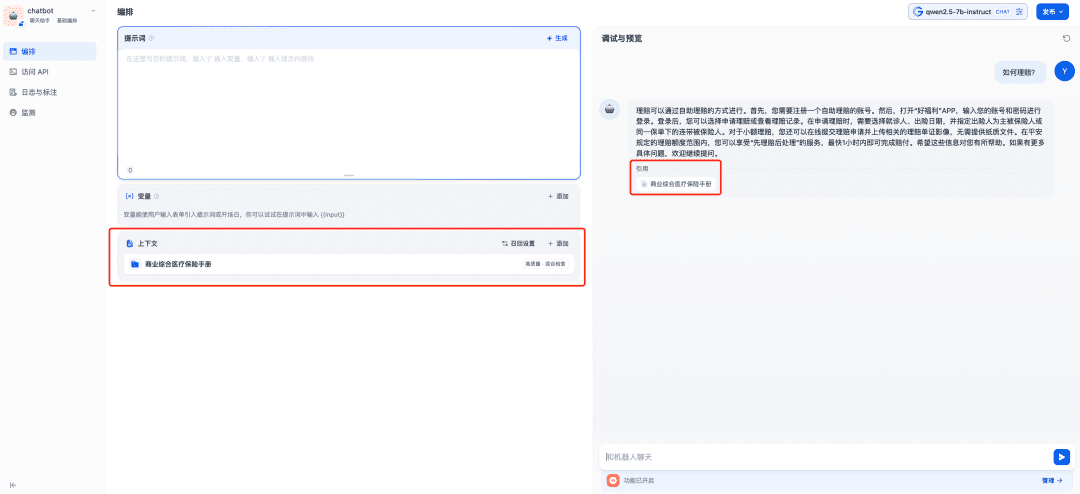
D'autres systèmes RAG peuvent également s'interfacer avec GPUStack via des API compatibles OpenAI / Jina, et peuvent tirer parti des différents modèles de Chat, d'Embedding et de Reranker déployés par la plateforme GPUStack pour soutenir les systèmes RAG.
Voici une brève description de la fonction GPUStack.
Caractéristiques de GPUStack
- Prise en charge des GPU hétérogènes : prise en charge des ressources GPU hétérogènes, actuellement prise en charge de Nvidia, Apple Metal, Huawei Rise et Moore Threads et d'autres types de GPU/NPU.
- Prise en charge de backends d'inférence multiples : les backends d'inférence vLLM et llama-box (llama.cpp) sont pris en charge, en tenant compte à la fois des performances de production et des exigences de compatibilité multiplateforme.
- Prise en charge multiplateforme : prise en charge des plateformes Linux, Windows et macOS, couvrant les architectures amd64 et arm64.
- Prise en charge de plusieurs types de modèles : prise en charge de plusieurs types de modèles tels que le modèle de texte LLM, le modèle multimodal VLM, le modèle d'intégration de texte Embedding et le modèle de réorganisation Reranker.
- Prise en charge de référentiels multi-modèles : Prise en charge du déploiement de modèles à partir de HuggingFace, Ollama Library, ModelScope et de référentiels de modèles privés.
- Politiques d'ordonnancement automatiques/manuelles riches : elles prennent en charge diverses politiques d'ordonnancement telles que l'ordonnancement compact, l'ordonnancement décentralisé, l'ordonnancement par étiquette de travailleur spécifié, l'ordonnancement GPU spécifié, etc.
- Inférence distribuée : si un seul GPU ne peut pas exécuter un modèle volumineux, la fonction d'inférence distribuée de GPUStack peut être utilisée pour exécuter automatiquement le modèle sur plusieurs GPU à travers les hôtes.
- Raisonnement CPU : En l'absence de GPU ou en cas de ressources GPU insuffisantes, GPUStack peut utiliser les ressources CPU pour exécuter des modèles de grande taille, en supportant deux modes de raisonnement CPU : le raisonnement hybride GPU&CPU et le raisonnement CPU pur.
- Comparaison de plusieurs modèles : GPUStack en Terrain de jeux Une vue de comparaison multi-modèle est fournie pour comparer le contenu des questions-réponses et les données de performance de plusieurs modèles en même temps afin d'évaluer l'effet de service des différents modèles, des différentes pondérations, des différents paramètres de l'invite, de la quantification, des différents GPU et des différents backends d'inférence.
- Observables GPU et LLM : fournit des mesures complètes de performance, d'utilisation, de surveillance de l'état et des données d'utilisation pour évaluer l'utilisation des GPU et des LLM.
GPUStack fournit toutes les fonctionnalités de classe entreprise nécessaires à la construction d'une grande plateforme privée de modèle-as-a-service. En tant que projet open source, il ne nécessite qu'une installation et une configuration très simples, et peut être utilisé pour construire une grande plateforme privée de modèle-as-a-service dès sa sortie de l'emballage.
résumés
Ce qui précède est un tutoriel de configuration pour l'installation de GPUStack et l'intégration des modèles GPUStack à l'aide de Dify, l'adresse du projet open source est : https://github.com/gpustack/gpustack.
GPUStack est une solution simple, facile à utiliser et prête à l'emploi.plateforme open sourceIl peut aider les entreprises à intégrer et à exploiter rapidement des ressources GPU hétérogènes et à mettre en place rapidement une plateforme privée de type "big model-as-a-service" de niveau professionnel.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...