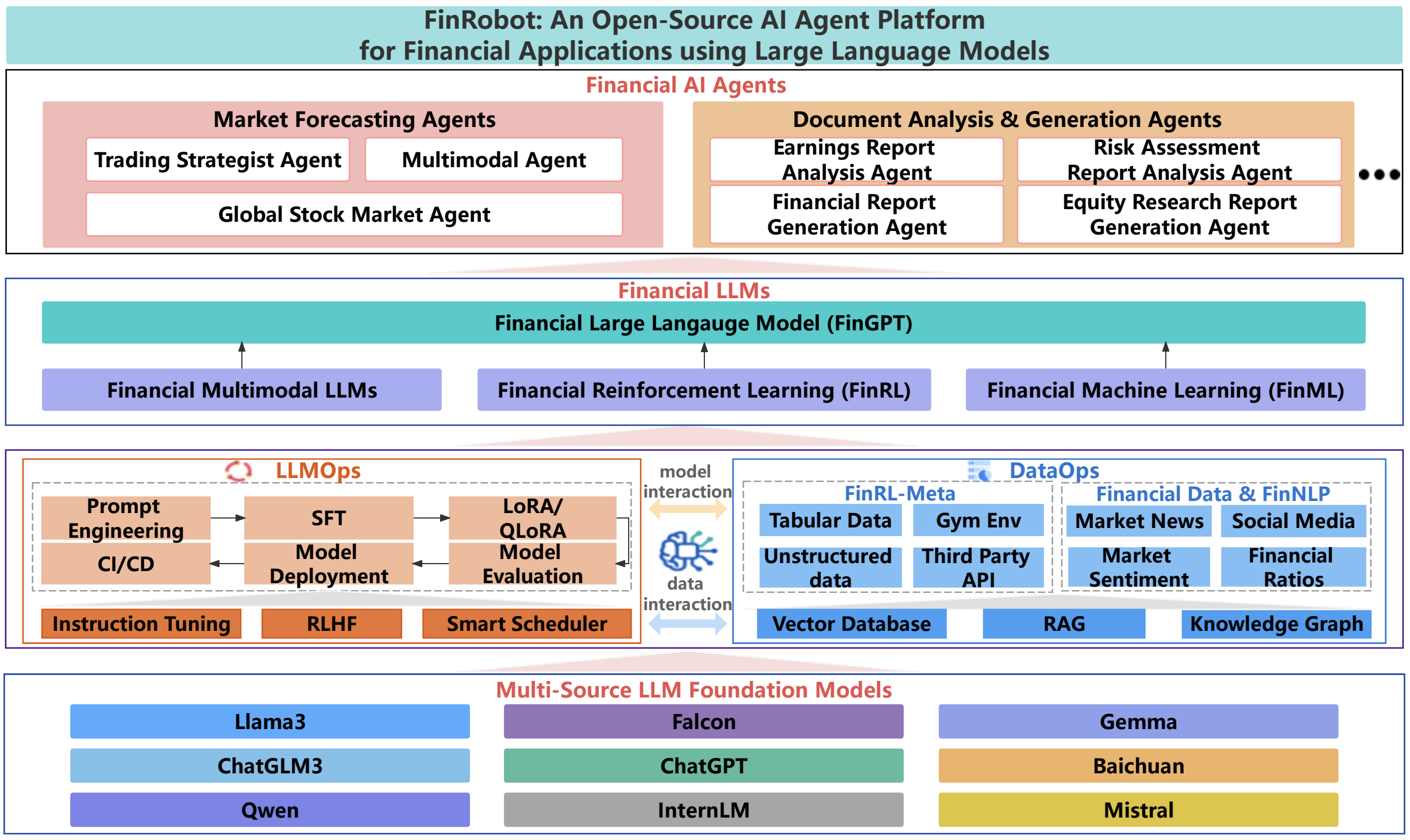
n8n Self-hosted AI Starter Kit : un modèle open source pour créer rapidement un environnement d'IA local
Introduction générale
Le kit de démarrage n8n Self-Hosted AI Starter Kit est un modèle Docker Compose open source conçu pour initialiser rapidement un environnement de développement local complet en matière d'IA et de low-code. Conçue par l'équipe n8n, la suite combine la plateforme auto-hébergée n8n avec une gamme de produits et de composants d'IA compatibles pour aider les utilisateurs à créer rapidement des flux de travail d'IA auto-hébergés. La suite comprend la plateforme low-code n8n, la plateforme LLM multiplateforme Ollama, le stockage vectoriel haute performance Qdrant et une base de données PostgreSQL pour une variété de scénarios d'application d'IA tels que les agents intelligents, le résumé de documents, les chatbots intelligents et l'analyse de documents financiers privés.

Liste des fonctions
- plate-forme n8n à code basLe système de gestion de l'information : Il fournit plus de 400 composants d'IA intégrés et avancés pour prendre en charge les flux de travail de construction rapide.
- Plate-forme OllamaLLM : plate-forme LLM multiplateforme avec prise en charge de l'installation et de l'exécution des dernières versions natives de LLM.
- Stockage vectoriel QdrantStockage vectoriel : Stockage vectoriel haute performance open source avec une API complète.
- Base de données PostgreSQLLe système de gestion des données est une base de données fiable qui permet de traiter de grandes quantités de données.
- Agents intelligentsLes agents d'intelligence artificielle pour la planification des réunions et des tâches.
- résumé du documentLes documents PDF de l'entreprise peuvent être résumés en toute sécurité, ce qui permet d'éviter les fuites de données.
- Chatbots intelligentsSlack : des bots intelligents qui améliorent les communications et les opérations informatiques de l'entreprise.
- Analyse de documents financiers privésAnalyse de documents financiers privés au moindre coût.
Utiliser l'aide
Processus d'installation
- entrepôt de clones: :
bash
git clone https://github.com/n8n-io/self-hosted-ai-starter-kit.git
cd self-hosted-ai-starter-kit
- Exécuter n8n avec Docker Compose: :
- Pour les utilisateurs de GPU Nvidia :
docker compose --profile gpu-nvidia upRemarque : si vous n'avez jamais utilisé un GPU Nvidia avec Docker, suivez les instructions pour Ollama Docker.
- Pour les utilisateurs de Mac/Apple Silicon :
- Option 1 : fonctionne entièrement sur l'unité centrale :
docker compose --profile cpu up - Option 2 : Lancez Ollama sur votre Mac et connectez-vous à l'instance n8n :
docker compose upModifiez ensuite les informations d'identification d'Ollama, en utilisant
http://host.docker.internal:11434/En tant qu'hôte.
- Option 1 : fonctionne entièrement sur l'unité centrale :
- Pour les autres utilisateurs :
docker compose --profile cpu up
- Pour les utilisateurs de GPU Nvidia :
Lignes directrices pour l'utilisation
- Démarrer n8n: :
- entretiens
http://localhost:5678, entrez dans l'interface n8n. - Connectez-vous avec votre compte par défaut ou créez-en un nouveau.
- entretiens
- Création de flux de travail: :
- Dans l'interface n8n, cliquez sur "Nouveau flux de travail".
- Faites glisser le nœud souhaité depuis le menu de gauche vers l'espace de travail.
- Configurez les paramètres et les connexions pour chaque nœud.
- Exécution de flux de travail: :
- Une fois la configuration terminée, cliquez sur le bouton Exécuter pour exécuter le flux de travail.
- Visualiser les résultats de l'exécution du flux de travail et les journaux.
Démarrage et utilisation rapides
Au cœur du kit de démarrage AI auto-hébergé se trouve un fichier Docker Compose avec des paramètres de réseau et de stockage préconfigurés, ce qui réduit la nécessité d'une installation supplémentaire. Une fois les étapes d'installation terminées, il vous suffit de suivre les étapes ci-dessous pour commencer :
- Ouvrez http://localhost:5678/设置n8n. Cette opération ne doit être effectuée qu'une seule fois.
- Ouvrez le flux de travail inclus : http://localhost:5678/workflow/srOnR8PAY3u4RSwb.
- optionProcessus de testCommencez à exécuter le flux de travail.
- Si c'est la première fois que vous exécutez ce workflow, vous devrez peut-être attendre que le téléchargement de Llama 3.2 par Ollama soit terminé. Vous pouvez vérifier les logs de la console docker pour connaître la progression.
N'hésitez pas à le faire en visitant le site http://localhost:5678/来打开n8n.
Avec votre instance n8n, vous aurez accès à plus de 400 intégrations ainsi qu'à un ensemble de nœuds d'IA de base et avancés, tels que les nœuds d'agent d'IA, de classificateur de texte et d'extracteur d'informations. Assurez-vous que l'exécution locale utilise le nœud Ollama comme modèle de langage et Qdrant comme magasin de vecteurs.
"prendre noteCe kit de démarrage est conçu pour vous aider à démarrer avec des flux de travail d'IA auto-hébergés. Bien qu'il ne soit pas entièrement optimisé pour les environnements de production, il combine des composants puissants qui collaborent de manière transparente, ce qui le rend idéal pour les projets de validation de concept. Vous pouvez le personnaliser en fonction de vos besoins.
"
Instructions de mise à niveau
Pour les paramètres du GPU Nvidia :
docker compose --profile gpu-nvidia pull
docker compose create && docker compose --profile gpu-nvidia up
Pour les utilisateurs de Mac / Apple Silicon
docker compose pull
docker compose create && docker compose up
Pour les paramètres non-GPU :
docker compose --profile cpu pull
docker compose create && docker compose --profile cpu up© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes

Pas de commentaires...